
Model pruning and knowledge distillation are powerful cost-effective strategies for obtaining smaller language models from an initial larger sibling.
- Pruning: Either drop layers (depth-pruning) or drop neurons, attention heads, and embedding channels (width-pruning).
- Knowledge distillation: Transfer knowledge from a large teacher model to a smaller student model, with the goal of creating a more efficient, smaller model that is faster and less resource-intensive to run.
The How to Prune and Distill Llama-3.1 8B to an NVIDIA Llama-3.1-Minitron 4B Model post discussed the best practices of using large language models (LLMs) that combine depth, width, attention, and MLP pruning with knowledge distillation–based retraining.
In this post, we provide a walk-through tutorial of the pruning and distillation pipeline in the NVIDIA NeMo framework on a simple dataset. This tutorial uses Meta-Llama-3.1-8B as the teacher model, with 4B being the target model size. We also visualize and discuss the training results.
Overview
This tutorial focuses on creating a simple pipeline that can prepare the dataset, fine-tune the teacher on the WikiText-103-v1 dataset, and then prune and distill the model to create the 4B model. The WikiText-103-v1 dataset is a collection of over 100M tokens extracted from a set of verified ‘Good’ and ‘Featured’ articles on Wikipedia. It is publicly available on Hugging Face.
In this tutorial, you are defining the pruning and distillation pipeline that involves the following high-level steps (Figure 1).
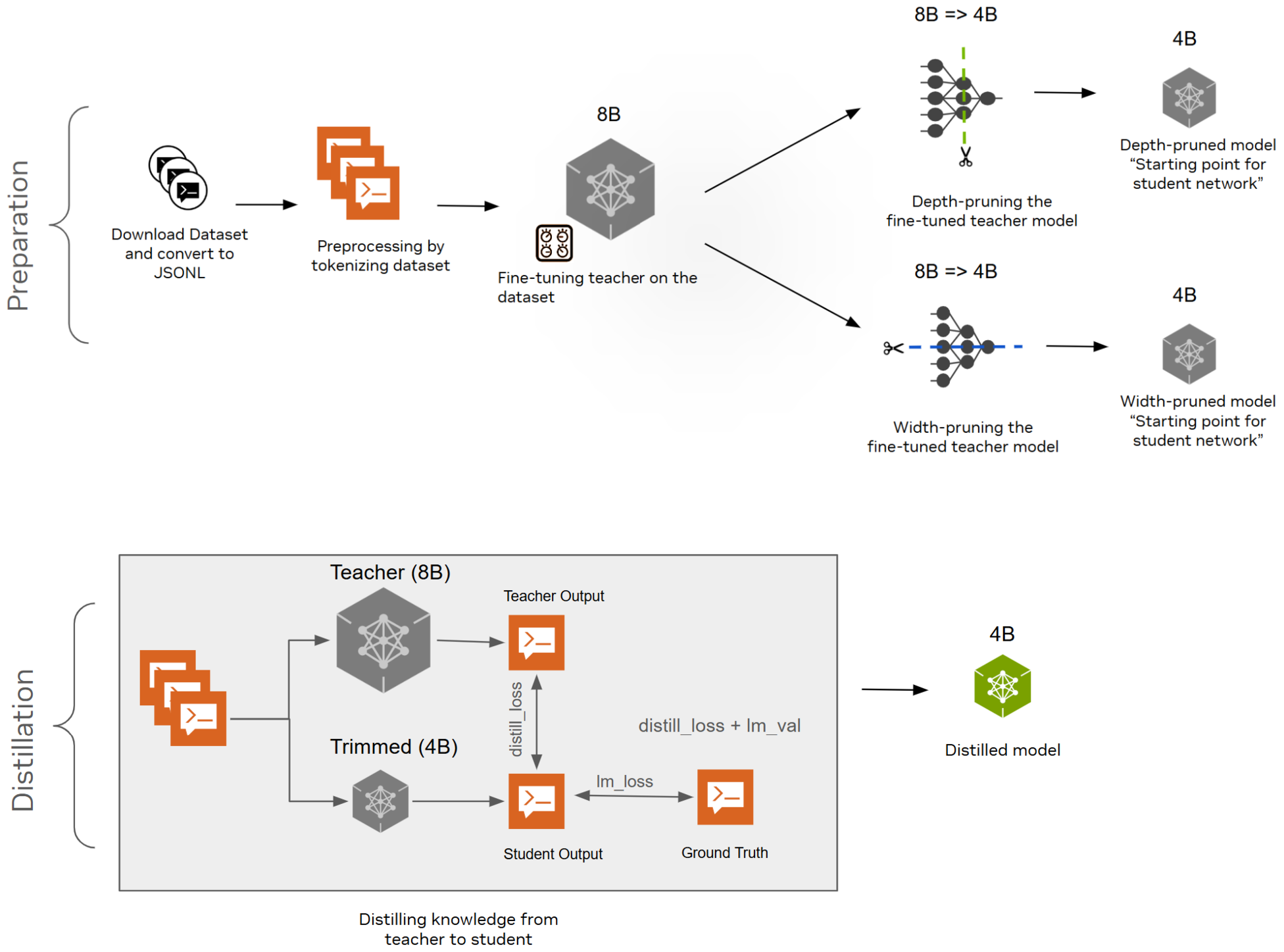
- Preparation:
- Download the dataset and convert to JSONL.
- Preprocess by tokenizing the dataset.
- Fine-tune the teacher model on the dataset.
- Depth-prune the fine-tuned teacher model. The depth-pruned model is the starting point for the student network.
- Width-prune the fine-tuned teacher model. The width-pruned model is the starting point for the student network.
- Distilling knowledge from teacher to student by using the 8B model as the teacher and the 4B pruned model as the student.
To access the Jupyter notebooks for this tutorial, see the /NVIDIA/NeMo GitHub repo.
Prerequisites
You require access to at least eight NVIDIA GPUs with an individual memory of 80 GB, for example, eight H100-80GB or A100-80GB GPUs, and a Docker-enabled environment.
Follow the instructions in the project’s README file to install the NeMo framework, download the Meta-Llama-3.1-8B teacher model and get access to your Hugging Face access token.
Download the dataset
Download the WikiText-103-v1 dataset and convert the train, test, and validation splits into JSONL files using the following code or by running the introduction notebook:
# Split into train, test and val files
import json
import os
from datasets import load_dataset
# Load the WikiText-103 dataset
dataset = load_dataset("wikitext", "wikitext-103-v1")
# Define the destination folder
data_folder = 'wikitext-data'
os.makedirs(data_folder, exist_ok=True)
# Define file paths and destination paths
file_paths = {
'train': os.path.join(data_folder, 'wikitext-train.jsonl'),
'validation': os.path.join(data_folder, 'wikitext-val.jsonl'),
'test': os.path.join(data_folder, 'wikitext-test.jsonl')
}
# Function to save dataset split to a JSONL file
def save_to_jsonl(file_path, data):
with open(file_path, 'w') as file:
for item in data:
file.write(json.dumps(item) + '\n')
# Define splits
splits = ["train", "validation", "test"]
# Save splits to JSONL files and calculate their sizes
for split in splits:
if split in dataset:
save_to_jsonl(file_paths[split], dataset[split])
else:
print(f"Split {split} not found in the dataset.")
Prepare the dataset
The pruning and the distillation scripts requires the data files to be preprocessed by tokenizing them using the meta-llama/Meta-Llama-3.1-8B tokenizer model to convert the data into a memory-map format. This can be done with the preprocessing script, preprocess_data_for_megatron.py in the NeMo framework.
Run the following script on the train split to prepare the dataset for pruning and distillation:
!python /opt/NeMo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py \
--input="./wikitext-data/wikitext-train.jsonl" \
--tokenizer-library='huggingface' \
--tokenizer-type='meta-llama/Meta-Llama-3.1-8B' \
--output-prefix=wikitext_tokenized_train \
--append-eod \
--workers=32
Run the script on the test and the validation split as well. The data preparation notebook contains all the scripts to create the tokenized wikitext_tokenized_{train/val/test}_text_document.{idx/bin} files that can be used to fine-tune the teacher model.
Fine-tune the teacher model on the dataset
With the prepared dataset, perform a light fine-tuning procedure on the unpruned teacher model. This section shows the usage of the scripts rather than focusing on performance, so the fine-tuning setup is run with GLOBAL_BATCH_SIZE set to 128 and STEPS set to 30 to ensure a low training time.
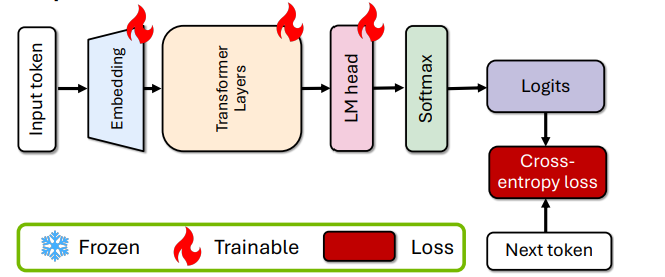
Run the megatron_gpt_pretraining.py script to correct the distribution shift across the original dataset on which the model was trained. Without correcting for the distribution shift, the teacher provides suboptimal guidance on the dataset when being distilled.
%%bash
export CUDA_DEVICE_MAX_CONNECTIONS=1
# Set path(s) if different:
MODEL="/workspace/llama-3_1-8b-nemo_v1.0/llama3_1_8b.nemo"
# Can change these to accommodate resources:
TENSOR_PARALLEL_SIZE=8
NODES=1
MICRO_BATCH_SIZE=4
# Don't change the following:
EXPERIMENT_DIR="distill_trainings"
EXPERIMENT_NAME="megatron_llama_ft"
DATA_TRAIN='wikitext_tokenized_train_text_document'
DATA_VAL='wikitext_tokenized_test_text_document'
DATA_TEST='wikitext_tokenized_val_text_document'
STEPS=30
GLOBAL_BATCH_SIZE=128
LOG_INTERVAL=1
VAL_INTERVAL=10
NUM_VAL_BATCHES=5
LR=1e-4
MIN_LR=1e-5
WARMUP_STEPS=2
cmd="torchrun --nproc-per-node=${TENSOR_PARALLEL_SIZE}"
${cmd} /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_pretraining.py \
--config-path /opt/NeMo/examples/nlp/language_modeling/conf/ \
--config-name megatron_llama_distill.yaml \
\
name=${EXPERIMENT_NAME} \
\
exp_manager.exp_dir=${EXPERIMENT_DIR} \
exp_manager.checkpoint_callback_params.save_top_k=1 \
exp_manager.checkpoint_callback_params.save_nemo_on_train_end=True \
\
trainer.max_steps=${STEPS} \
trainer.log_every_n_steps=${LOG_INTERVAL} \
Running the script or executing the teacher fine-tuning notebook creates a fine-tuned teacher model.
Prune the fine-tuned teacher model to create a student
You can use two methods to prune the fine-tuned teacher model: depth-pruning and width-pruning.
Per the technology report, you can see that width-pruning generally outperforms depth-pruning in accuracy, but at the cost of increased inference latency. Choose to perform depth-pruning, width-pruning, or both methods based on these considerations.

Depth-prune the fine-tuned teacher model to create a student
In the first method, you depth-prune the model. To go from an 8B to a 4B model, prune the last 16 layers (layers 16-31). Run the megatron_gpt_drop_layers.py script to depth-prune the fine-tuned teacher model:
!python -m torch.distributed.launch --nproc_per_node=8 \
/opt/NeMo/examples/nlp/language_modeling/megatron_gpt_drop_layers.py \
--path_to_nemo "./distill_trainings/megatron_llama_ft/checkpoints/megatron_llama_ft.nemo" \
--path_to_save "/workspace/4b_depth_pruned_model.nemo" \
--tensor_model_parallel_size 8 \
--pipeline_model_parallel_size 1 \
--gpus_per_node 8 \
--drop_layers 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
Running this script or executing the depth pruning notebook results in the creation of a smaller checkpoint with the last 16 layers removed: 4b_depth_pruned_model.nemo.
Width-prune the fine-tuned teacher model to create a student
In the second method, you width-prune the model. To go from an 8B to a 4B model, prune the model by reducing the MLP intermediate dimension and hidden size and by retraining the attention headcount and number of layers.
Run the megatron_gpt_prune.py script to width-prune the fine-tuned teacher model:
!torchrun --nproc-per-node=8 /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_prune.py \
model.restore_from_path="./distill_trainings/megatron_llama_ft/checkpoints/megatron_llama_ft.nemo" \
model.tensor_model_parallel_size=1 \
model.pipeline_model_parallel_size=8 \
+model.dist_ckpt_load_strictness=log_all \
inference.batch_size=64 \
trainer.num_nodes=1 \
trainer.precision=bf16 \
trainer.devices=8 \
prune.ffn_hidden_size=9216 \
prune.num_attention_heads=null \
prune.num_query_groups=null \
prune.hidden_size=3072 \
export.save_path="/workspace/4b_width_pruned_model.nemo"
Running this script or executing the width pruning notebook results in the creation of a smaller width-pruned checkpoint: 4b_width_pruned_model.nemo.
Distill knowledge from teacher into the student
The distillation process uses the fine-tuned model (8B) as the teacher model and the pruned model as the student model (4B) to distill to a smaller 4B model. Only logit loss is currently available in NeMo.
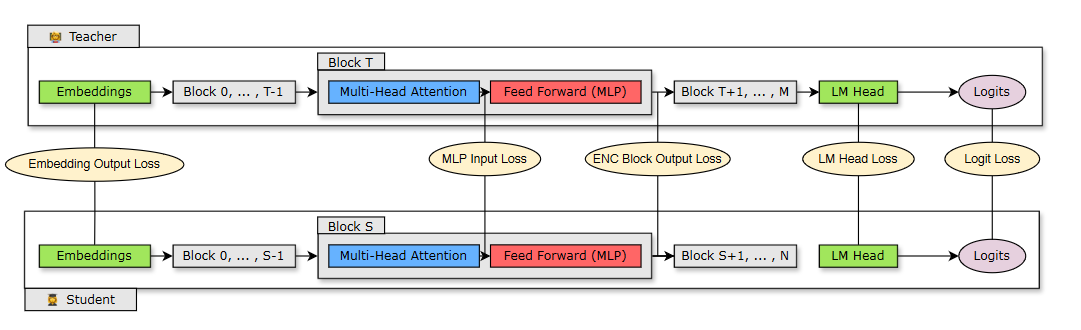
In this section, you distill the knowledge from the teacher model into both student models and compare them:
- Distill the knowledge from the fine-tuned teacher to the depth-pruned student
- Distill the knowledge from the fine-tuned teacher to the width-pruned student
Distill knowledge from the fine-tuned teacher into the depth-pruned student
Run the megatron_gpt_distillation.py script to distill knowledge from the teacher to the depth-pruned student model.
%%bash
export CUDA_DEVICE_MAX_CONNECTIONS=1
# Can change these to accommodate resources:
TENSOR_PARALLEL_SIZE=8
NODES=1
MICRO_BATCH_SIZE=4
# Don't change the following:
EXPERIMENT_DIR="distill_trainings"
EXPERIMENT_NAME="megatron_llama_distill_depth_pruned_student"
TEACHER="${EXPERIMENT_DIR}/megatron_llama_ft/checkpoints/megatron_llama_ft.nemo"
STUDENT="/workspace/4b_depth_pruned_model.nemo"
FINAL_MODEL_PATH="${EXPERIMENT_DIR}/${EXPERIMENT_NAME}/checkpoints/depth_pruned_distilled_4b_model.nemo"
DATA_TRAIN='wikitext_tokenized_train_text_document'
DATA_VAL='wikitext_tokenized_test_text_document'
DATA_TEST='wikitext_tokenized_val_text_document'
STEPS=30
GLOBAL_BATCH_SIZE=128
LOG_INTERVAL=1
VAL_INTERVAL=10
NUM_VAL_BATCHES=5
LR=1e-4
MIN_LR=1e-5
WARMUP_STEPS=2
cmd="torchrun --nproc-per-node=${TENSOR_PARALLEL_SIZE}"
${cmd} /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_distillation.py \
name=${EXPERIMENT_NAME} \
\
exp_manager.exp_dir=${EXPERIMENT_DIR} \
exp_manager.checkpoint_callback_params.save_top_k=1 \
\
trainer.max_steps=${STEPS} \
trainer.log_every_n_steps=${LOG_INTERVAL} \
trainer.val_check_interval=${VAL_INTERVAL} \
trainer.limit_val_batches=${NUM_VAL_BATCHES} \
+trainer.num_sanity_val_steps=0 \
\
trainer.precision=bf16 \
trainer.devices=${TENSOR_PARALLEL_SIZE} \
trainer.num_nodes=${NODES} \
\
"model.data.data_prefix={train:[1.0,$DATA_TRAIN],validation:[$DATA_VAL],test:[$DATA_TEST]}" \
\
model.restore_from_path=${STUDENT} \
model.kd_teacher_restore_from_path=${TEACHER} \
model.nemo_path=${FINAL_MODEL_PATH} \
\
model.tensor_model_parallel_size=${TENSOR_PARALLEL_SIZE} \
model.sequence_parallel=True \
model.micro_batch_size=${MICRO_BATCH_SIZE} \
model.global_batch_size=${GLOBAL_BATCH_SIZE} \
\
model.optim.name=distributed_fused_adam \
model.optim.lr=${LR} \
model.optim.sched.min_lr=${MIN_LR} \
model.optim.sched.warmup_steps=${WARMUP_STEPS}
Running this script or the distilling depth-pruned student notebook results in the creation of a distilled model: depth_pruned_distilled_4b_model.nemo.
Distill knowledge from the fine-tuned teacher into the width-pruned student
Run the megatron_gpt_distillation.py script to distill knowledge from the teacher to the width-pruned student model. Change the student model (STUDENT) and the directory where the distilled model will be saved (FINAL_MODEL_PATH) before running the script.
Running the distilling width-pruned student notebook results in the creation of a distilled model, width_pruned_distilled_4b_model.nemo.
Display the validation loss
Run the following code command or execute the results notebook to visualize the validation loss. Modify the path to the checkpoint before running the code example:
%load_ext tensorboard
%tensorboard --logdir "distill_trainings/megatron_llama_distill/" --port=6007
You can see the validation loss after running the distillation script over a STEPS value of 30, with the depth-pruned student and the width-pruned student in Figures 5 and 6, respectively.


To configure this pipeline for your use case, run the scripts on a multi-node cluster with larger GLOBAL_BATCH_SIZE, STEPS and VAL_INTERVAL values to see an improvement in the validation loss.
Figures 7 and 8 show the validation loss decreasing when you run the training step in the distillation script over a STEPS value of 880 and a GLOBAL_BATCH_SIZE value of 2048 with the depth-pruned and width-pruned students, respectively.


Conclusion
Pruning and distillation represent a significant advancement in the field of language model optimization. The ability to create smaller, more efficient models like the Llama-3.1-Minitron-4B in resource-constrained environments while preserving performance and without sacrificing substantial accuracy is a game changer for the AI industry.
The Mistral-NeMo-Minitron-8B model is developed using this approach and outperforms the Llama-3.1-8B model on a variety of benchmarks.
This approach reduces computational costs and energy consumption at inference time and also democratizes access to advanced NLP capabilities. This could revolutionize real-world applications in mobile devices, edge computing, and constrained resource settings. As these techniques continue to evolve, you can expect to see even more compact yet powerful language models, further expanding the reach of this technology across various industries.
For more information, see the following resources:
- Jupyter notebooks with pruning and distillation recipes
- Compact Language Models via Pruning and Knowledge Distillation research paper
- LLM Pruning and Distillation in Practice: The Minitron Approach with a discussion on performance metrics
- How to Prune and Distill Llama-3.1 8B to an NVIDIA Llama-3.1-Minitron 4B Model post introducing good practices surrounding pruning and distillation techniques
- Mistral-NeMo-Minitron 8B Model Delivers Unparalleled Accuracy post showing the performance benchmarks of the Mistral-NeMo-Minitron-8B model
