
Large language models (LLM) are now a dominant force in natural language processing and understanding, thanks to their effectiveness and versatility. LLMs such as Llama 3.1 405B and NVIDIA Nemotron-4 340B excel in many challenging tasks, including coding, reasoning, and math. They are, however, resource-intensive to deploy. As such, there is another trend in the industry to develop small language models (SLMs), which are sufficiently proficient in many language tasks but much cheaper to deploy to the masses.
Recently, NVIDIA researchers showed that structured weight pruning combined with knowledge distillation forms an effective and efficient strategy for obtaining progressively smaller language models from an initial larger sibling. NVIDIA Minitron 8B and 4B are such small models, obtained by pruning and distilling their larger 15B sibling in the NVIDIA Nemotron family.
Pruning and distillation lead to several benefits:
- Improvement in MMLU scores by 16% compared to training from scratch.
- Fewer training tokens are required for each additional model, ~100B tokens with an up to 40x reduction.
- Compute cost saving to train a family of models, up to 1.8x compared to training all models from scratch.
- Performance is comparable to Mistral 7B, Gemma 7B, and Llama-3 8B trained on many more tokens, up to 15T.
The paper also presents a set of practical and effective structured compression best practices for LLMs that combine depth, width, attention, and MLP pruning with knowledge distillation-based retraining.
In this post, we first discuss these best practices and then show their effectiveness when applied to the Llama 3.1 8B model to obtain a Llama-3.1-Minitron 4B model. Llama-3.1-Minitron 4B performs favorably against state-of-the-art open-source models of similar size, including Minitron 4B, Phi-2 2.7B, Gemma2 2.6B, and Qwen2-1.5B. Llama-3.1-Minitron 4B will be released to the NVIDIA HuggingFace collection soon, pending approvals.
Pruning and distillation
Pruning is the process of making the model smaller and leaner, either by dropping layers (depth pruning) or dropping neurons and attention heads and embedding channels (width pruning). Pruning is often accompanied by some amount of retraining for accuracy recovery.
Model distillation is a technique used to transfer knowledge from a large, complex model, often called the teacher model, to a smaller, simpler student model. The goal is to create a more efficient model that retains much of the predictive power of the original, larger model while being faster and less resource-intensive to run.
Classical knowledge distillation vs. SDG finetuning
There are two main styles of distillation:
- SDG finetuning: The synthetic data generated from a larger teacher model is used to further fine-tune a smaller, pretrained student model. Here, the student mimics only the final token predicted by the teacher. This is exemplified by the Llama 3.1 Azure Distillation in Azure AI Studio and AWS Use Llama 3.1 405B for synthetic data generation and distillation to fine-tune smaller models tutorials.
- Classical knowledge distillation: The student mimics the logits and other intermediate states of the teacher on the training dataset rather than just learning the token that has to be predicted. This can be viewed as providing better labels (a distribution compared to a one-shot label). Even with the same data, the gradient contains richer feedback, improving the training accuracy and efficiency. However, there must be training framework support for this style of distillation as the logits are too large to store.
These two styles of distillation are complementary to one another, rather than mutually exclusive. This post primarily focuses on the classical knowledge distillation approach.
Pruning and distillation procedure
We proposed combining pruning with classical knowledge distillation as a resource-efficient retraining technique (Figure 1).
- We started from a 15B model. We estimated the importance of each component (layer, neuron, head, and embedding channel) and then ranked and trimmed the model to the target size: an 8B model.
- We performed a light retraining procedure using model distillation with the original model as the teacher and the pruned model as the student.
- After training, the small model (8B) served as a starting point to trim and distill to a smaller 4B model.
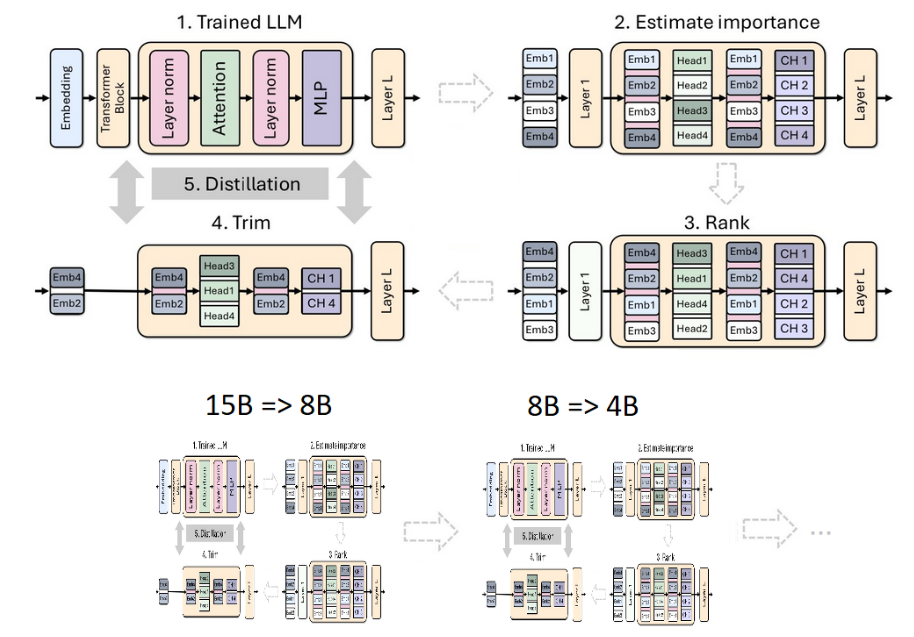
Figure 1 shows the pruning and distillation process of a single model (top) and the chain of model pruning and distillation (bottom). In the latter, the output model of a previous stage serves as the input model for the next stage.
Importance analysis
To prune a model, it is critical to understand which parts of the model are important. We propose using a purely activation-based importance estimation strategy that simultaneously computes sensitivity information for all the axes considered (depth, neuron, head, and embedding channel) using a small (1024 samples) calibration dataset and only forward propagation passes. This strategy is more straightforward and cost-effective to implement compared to strategies that rely on gradient information and require a backward propagation pass.
While pruning, you can iteratively alternate between pruning and importance estimation for a given axis or combination of axes. However, our empirical work shows that it is sufficient to use single-shot importance estimation and iterative estimation provides no benefit.
Retraining with classical knowledge distillation
Figure 2 shows the distillation process with a student model (pruned model) with N layers distilled from a teacher model (original unpruned model) with M layers. The student learns by minimizing a combination of embedding output loss, logit loss, and transformer encoder-specific losses mapped across student block S and teacher block T.

Pruning and distillation best practices
Based on the extensive ablation studies carried out in Compact Language Models via Pruning and Knowledge Distillation, we summarized our learnings into several structured compression best practices:
- Sizing:
- To train a family of LLMs, first train the largest one, then prune and distill iteratively to obtain smaller LLMs.
- If the largest model is trained using a multi-phase training strategy, it is best to prune and retrain the model obtained from the final stage of training.
- Prune an available source model closest to the target size.
- Pruning:
- Prefer width over depth pruning. This worked well for the model scales considered (≤ 15B).
- Use single-shot importance estimation. Iterative importance estimation provided no benefit.
- Retraining:
- Retrain exclusively with distillation loss instead of conventional training.
- Use logit plus intermediate state plus embedding distillation when the depth is reduced significantly.
- Use logit-only distillation when depth isn’t reduced significantly.
Llama-3.1-Minitron: putting best practices to work
Meta recently introduced the powerful Llama 3.1 model family, a first wave of open-source models that are comparable with closed-source models across many benchmarks. Llama 3.1 ranges from the gigantic 405B model to the 70B and 8B.
Equipped with experience of Nemotron distillation, we set out to distill the Llama 3.1 8B model to a smaller and more efficient 4B sibling:
- Teacher fine-tuning
- Depth-only pruning
- Width-only pruning
- Accuracy benchmarks
- Performance benchmarks
Teacher fine-tuning
To correct for the distribution shift across the original dataset the model was trained on, we first fine-tuned the unpruned 8B model on our dataset (94B tokens). Experiments showed that, without correcting for the distribution shift, the teacher provides suboptimal guidance on the dataset when being distilled.
Depth-only pruning
To go from an 8B to a 4B, we pruned 16 layers (50%). We first evaluated the importance of each layer or continuous subgroup of layers by dropping them from the model and observing the increase in LM loss or accuracy reduction on a downstream task.
Figure 5 shows the LM loss value on the validation set after removing 1, 2, 8, or 16 layers. For example, the red plot at layer 16 indicates the LM loss if we dropped the first 16 layers. Layer 17 indicates the LM loss if we leave the first layer and drop layers 2 to 17. We observed that the layers at the beginning and end are the most important.

However, we observed that this LM loss is not necessarily directly correlated with downstream performance.
Figure 6 shows the Winogrande accuracy for each pruned model. It indicates that it is best to remove layers 16 to 31, with 31 being the second-to-last layer, where the pruned model 5-shot accuracy is significantly greater than random (0.5). We adopted this insight and removed layers 16 to 31.

Width-only pruning
We pruned both the embedding (hidden) and MLP intermediate dimensions along the width axis to compress Llama 3.1 8B. Specifically, we computed importance scores for each attention head, embedding channel, and MLP hidden dimension using the activation-based strategy described earlier. Following importance estimation, we:
- Pruned (trim) the MLP intermediate dimension from 14336 to 9216.
- Pruned the hidden size from 4096 to 3072.
- Retrained the attention headcount and number of layers.
It is worth mentioning that immediately after one-shot pruning, the LM loss of width pruning is higher than that of depth pruning. However, after a short retraining, the trend reverses.
Accuracy benchmarks
We distilled the model with the following parameters:
- Peak learning rate=1e-4
- Minimum learning rate=1e-5
- Linear warm-up of 40 steps
- Cosine decay schedule
- Global batch size=1152
Table 1 shows the comparative performance of Llama-3.1-Minitron 4B model variants (width-pruned and depth-pruned) when compared with the original Llama 3.1 8B models and other models of similar size on benchmarks spanning several domains.
Overall, we reconfirmed the effectiveness of a width-pruning strategy compared to depth pruning, which follows the best practices.
| Benchmark | No. of shots | Metric | Llama-3.1 8B | Minitron 4B | Llama-3.1-Minitron 4B | Phi-2 2.7B | Gemma2 2.6B† | Qwen2-1.5B† | |
| Width-pruned | Depth-pruned | Width-pruned | |||||||
| winogrande | 5 | acc | 0.7727 | 0.7403* | 0.7214 | 0.7348 | 0.7400** | 0.709 | 0.662 |
| arc_challenge | 25 | acc_norm | 0.5794 | 0.5085 | 0.5256 | 0.5555** | 0.6100* | 0.554 | 0.439 |
| MMLU | 5 | acc | 0.6528 | 0.5860** | 0.5871 | 0.6053* | 0.5749 | 0.513 | 0.565 |
| hellaswag | 10 | acc_norm | 0.8180 | 0.7496 | 0.7321 | 0.7606* | 0.7524** | 0.73 | 0.666 |
| gsm8k | 5 | acc | 0.4860 | 0.2411 | 0.1676 | 0.4124 | 0.5500** | 0.239 | 0.585* |
| truthfulqa | 0 | mc2 | 0.4506 | 0.4288 | 0.3817 | 0.4289 | 0.4400** | – | 0.459* |
| XLSum en (20%) | 3 | rougeL | 0.3005 | 0.2954* | 0.2722 | 0.2867** | 0.0100 | – | – |
| MBPP | 0 | pass@1 | 0.4227 | 0.2817 | 0.3067 | 0.324 | 0.4700* | 0.29 | 0.374** |
| Training Tokens | 15T | 94B | 1.4T | 3T | 7T | ||||
* Best model
** Second-best model
– Unavailable results
† Results as reported in the model report by the model publisher.
To verify that the distilled models can be strong instruct models, we fine-tuned the Llama-3.1-Minitron 4B models using NeMo-Aligner. We used training data used for Nemotron-4 340B and evaluated the models on IFEval, MT-Bench, ChatRAG-Bench, and Berkeley Function Calling Leaderboard (BFCL) to test instruction-following, roleplay, RAG, and function-calling capabilities. We confirmed that Llama-3.1-Minitron 4B models can be solid instruct models, which outperform other baseline SLMs (Table 2).
| Minitron 4B | Llama-3.1-Minitron 4B | Gemma 2B | Phi-2 2.7B | Gemma2 2.6B | Qwen2-1.5B | ||
| Benchmark | Width-pruned | Depth-pruned | Width-pruned | ||||
| IFEval | 0.4484 | 0.4257 | 0.5239** | 0.4050 | 0.4400 | 0.6451* | 0.3981 |
| MT-Bench | 5.61 | 5.64 | 6.34** | 5.19 | 4.29 | 7.73* | 5.22 |
| ChatRAG† | 0.4111** | 0.4013 | 0.4399* | 0.3331 | 0.3760 | 0.3745 | 0.2908 |
| BFCL | 0.6423 | 0.6680* | 0.6493** | 0.4700 | 0.2305 | 0.3562 | 0.3275 |
| Training Tokens | 94B | 3T | 1.4T | 2T | 7T | ||
* Best model
** Second-best model
† Based on a representative subset of ChatRAG, not the whole benchmark.
Performance benchmarks
We optimized the Llama 3.1 8B and Llama-3.1-Minitron 4B models with NVIDIA
TensorRT-LLM, an open-source toolkit for optimized LLM inference.
Figures 7 and 8 show the throughput requests per second of different models in FP8 and FP16 precision on different use cases, represented as input sequence length/output sequence length (ISL/OSL) combinations at batch size 32 for the 8B model and batch size 64 for the 4B models, thanks to the smaller weights allowing for larger batches, on one NVIDIA H100 80GB GPU.
The Llama-3.1-Minitron-4B-Depth-Base variant is the fastest, at an average of ~2.7x throughput of Llama 3.1 8B, while the Llama-3.1-Minitron-4B-Width-Base variant is at an average of ~1.8x throughput of Llama 3.1 8B. Deployment in FP8 also delivers a performance boost of ~1.3x across all three models compared to BF16.


Combinations: BS=32 for Llama 3.1 8B and BS=64 for Llama-3.1-Minitron 4B models. 1x H100 80GB GPU.
Conclusion
Pruning and classical knowledge distillation is a highly cost-effective method to progressively obtain LLMs of smaller size, achieving superior accuracy compared to training from scratch across all domains. It serves as a more effective and data-efficient approach compared to either synthetic-data-style finetuning or pretraining from scratch.
Llama-3.1-Minitron 4B is our first work with the state-of-the-art open-source Llama 3.1 family. To use SDG finetuning of Llama-3.1 in NVIDIA NeMo, see the /sdg-law-title-generation notebook on GitHub.
For more information, see the following resources:
- Compact Language Models via Pruning and Knowledge Distillation
- /NVlabs/Minitron GitHub repo
- Llama-3.1-Minitron models on Hugging Face:
Acknowledgments
This work would not have been possible without contributions from many people at NVIDIA. To mention a few of them: Core Team: Sharath Turuvekere Sreenivas, Saurav Muralidharan, Marcin Chochowski, Raviraj Joshi; Advisors: Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, Pavlo Molchanov; Instruction-tuning: Ameya Sunil Mahabaleshwarkar, Hayley Ross, Brandon Rowlett, Oluwatobi Olabiyi, Shizhe Diao, Yoshi Suhara; Datasets: Sanjeev Satheesh, Shengyang Sun, Jiaqi Zeng, Zhilin Wang, Yi Dong, Zihan Liu, Rajarshi Roy, Wei Ping, Makesh Narsimhan Sreedhar, Oleksii Kuchaiev; TRT-LLM: Bobby Chen, James Shen; HF support: Ao Tang, Greg Heinrich; Model optimization: Chenhan Yu; Discussion and feedback: Daniel Korzekwa; Blog post preparation: Vinh Nguyen, Sharath Turuvekere Sreenivas.
