
Language models such as the NVIDIA Megatron-LM and OpenAI GPT-2 and GPT-3 have been used to enhance human productivity and creativity. Specifically, these models have been used as powerful tools for writing, programming, and painting. The same architecture can be used for music composition.
Large datasets are required to use language models in these domains. Starting with 50GB of uncompressed text files for language generation is no surprise. This implies the need for a log of GPU compute to train the models effectively for rapid development, prototyping, and iteration.
This post provides an account of a series of experiments performed in the field of AI music using the NVIDIA DGX-2. The DGX-2 boosted progress significantly in both data preprocessing and training language models.
Datasets for AI music
There are two major classes when it comes to datasets for Computational Music. One approach involves training on the music represented as pure audio (WAV files or MP3s). The second approach does not work with the pure audio. Instead, you map anything that resembles sheet music to a token representation.
Usually, this requires tokens for which note starts (C, D, E, F, G), how much time passes (quarter notes or eighth notes, for example), and which note ends. In research and application, MIDI-files have proven to be fruitful sources for musical material. The MIDI standard has been designed to electronically store music information.
These experiments used several sets of MIDI files, including:
- JS Fake Chorales Dataset with 500 fake chorales in the style of J.S. Bach
- Lakh MIDI Dataset and its Clean subset (176K and 15K MIDI files respectively), with a mixed variety of genres and styles
- MetaMIDI Dataset with 463K MIDI files, again of varying genres and styles
The MIDI format is a non-human-readable representation of music which, in order to train a Causal Language Model, has to be mapped to a readable token representation. For this representation, we took inspiration from the mmmtrack encoding.
This encoding represents pieces of music as a hierarchy. A piece of music consists of different tracks for different instruments: drums, guitars, bass, and piano, for example. Each track consists of several bars (4, 8, or 16 bars, depending on the use case). And each bar holds a sequence of note-on, time-delta, and note-off events. Although this hierarchy can be considered a tree, it is possible to encode everything as a linear sequence, making it an ideal representation for decoder-only language models.
The example below is a four-part chorale in its piano roll representation. A chorale features four voices: soprano, alto, tenor, and bass. Soprano and alto are female voices, and tenor and bass are male voices. Usually, all four voices sing at the same time but with different, harmonic pitches.
Figure 1 visualizes the voices with pitch color coding. The soprano is green, the alto is orange, the tenor is blue, and the bass is red. You can encode these musical events—which have both a time and a pitch dimension—to a sequence of tokens.
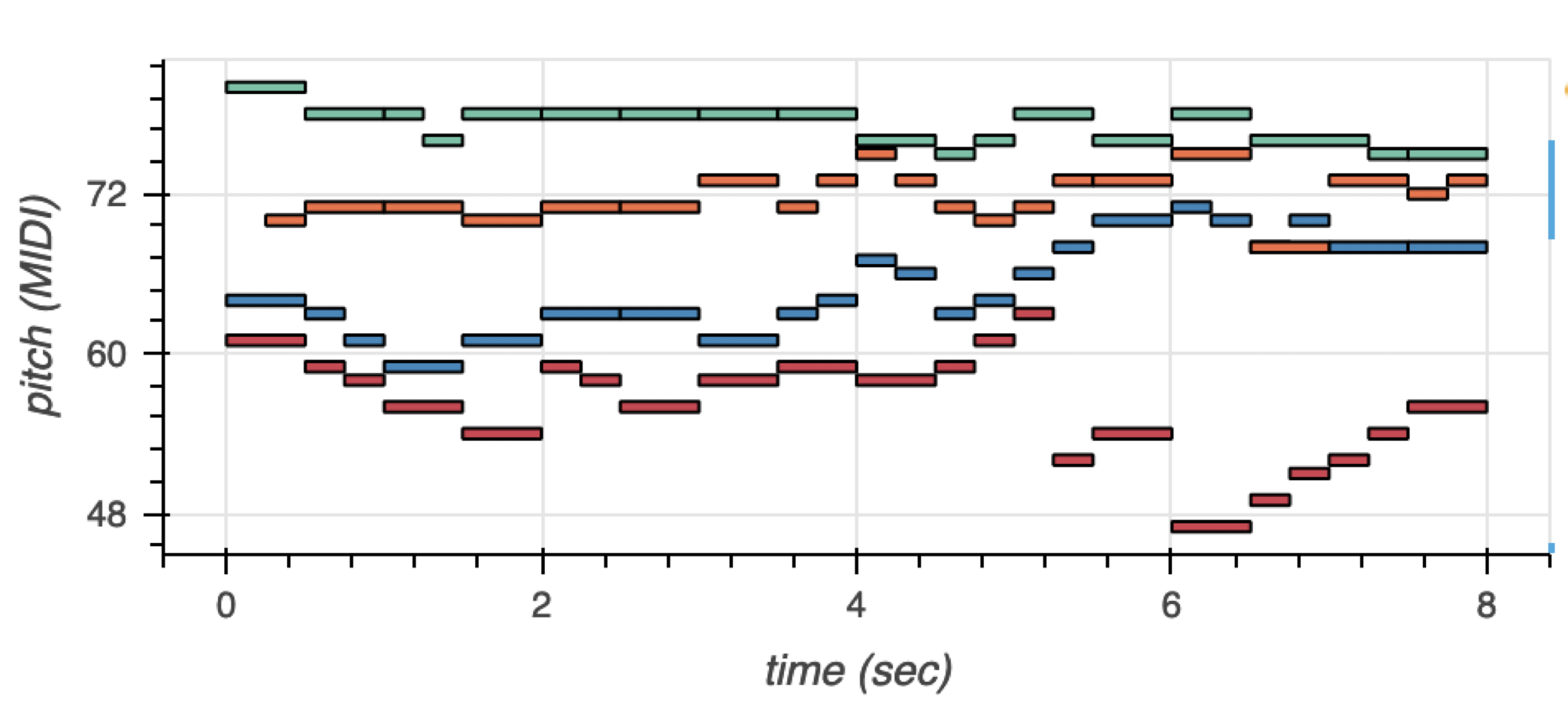
Following the mmmtrack encoding, the bass part would be mapped to the following token representation:
PIECE_START TRACK_START INST=BASS BAR_START NOTE_ON=61 TIME_DELTA=4 NOTE_OFF=61 NOTE_ON=59 TIME_DELTA=2 NOTE_OFF=59 NOTE_ON=58 TIME_DELTA=2 NOTE_OFF=58 NOTE_ON=56 TIME_DELTA=4 NOTE_OFF=56 NOTE_ON=54 TIME_DELTA=4 NOTE_OFF=54 BAR_END BAR_START NOTE_ON=59 TIME_DELTA=2 NOTE_OFF=59 NOTE_ON=58 TIME_DELTA=2 NOTE_OFF=58 NOTE_ON=56 TIME_DELTA=4 NOTE_OFF=56 NOTE_ON=58 TIME_DELTA=4 NOTE_OFF=58 NOTE_ON=59 TIME_DELTA=4 NOTE_OFF=59 BAR_END BAR_START NOTE_ON=58 TIME_DELTA=4 NOTE_OFF=58 NOTE_ON=59 TIME_DELTA=2 NOTE_OFF=59 NOTE_ON=61 TIME_DELTA=2 NOTE_OFF=61 NOTE_ON=63 TIME_DELTA=2 NOTE_OFF=63 NOTE_ON=52 TIME_DELTA=2 NOTE_OFF=52 NOTE_ON=54 TIME_DELTA=4 NOTE_OFF=54 BAR_END BAR_START NOTE_ON=47 TIME_DELTA=4 NOTE_OFF=47 NOTE_ON=49 TIME_DELTA=2 NOTE_OFF=49 NOTE_ON=51 TIME_DELTA=2 NOTE_OFF=51 NOTE_ON=52 TIME_DELTA=2 NOTE_OFF=52 NOTE_ON=54 TIME_DELTA=2 NOTE_OFF=54 NOTE_ON=56 TIME_DELTA=4 NOTE_OFF=56 BAR_END TRACK_END TRACK_START INST=TENOR …
With a little practice, humans can read and understand this representation. The representation starts with PIECE_START indicating the start of a piece of music. TRACK_START indicates the beginning and TRACK_END the end of a track (or instrument or voice). The INST=BASS token denotes that this track contains the bass voice. Other voices are represented the same way. BAR_START and BAR_END represent the beginning and the end of a bar, respectively. NOTE_ON=61 is the start of a note with pitch 61.
On the piano, this would be the note C#5. TIME_DELTA=4 means that a duration of four sixteenth notes would elapse. That would be a quarter note. After that, the note would end, represented by NOTE_OFF=61. And so on and so forth. At this point, this notation would also allow for polyphony. Several tracks would sound notes at the same time, and each track could have parallel notes. This makes the encoding universal.
Each piece of music differs in the number of bars. It is quite possible that encoding an entire song would require a long sequence length, making the training of a respective Transformer computationally expensive. These experiments encode most of the datasets with four bars and a few with eight bars. Experiments with 16 bars are underway. In addition, only music in a 4/4 time meter was used. This covers the better part of western music. Other meters such as 3/4 (waltz) can be the subject of future work.
This sequence of different experiments mapped many MIDI datasets to the described token format. The same preprocessor was used throughout. Once the preprocessor worked with small datasets, it immediately worked with larger ones.
The processing time depends on the number of MIDI files to be encoded, ranging from a few minutes to many hours. The longest preprocessing took 30 hours on DGX-2 running on all 96 CPUs in parallel. It is estimated that this would take about 10-14 days of processing on a state-of-the-art MacBook Pro.
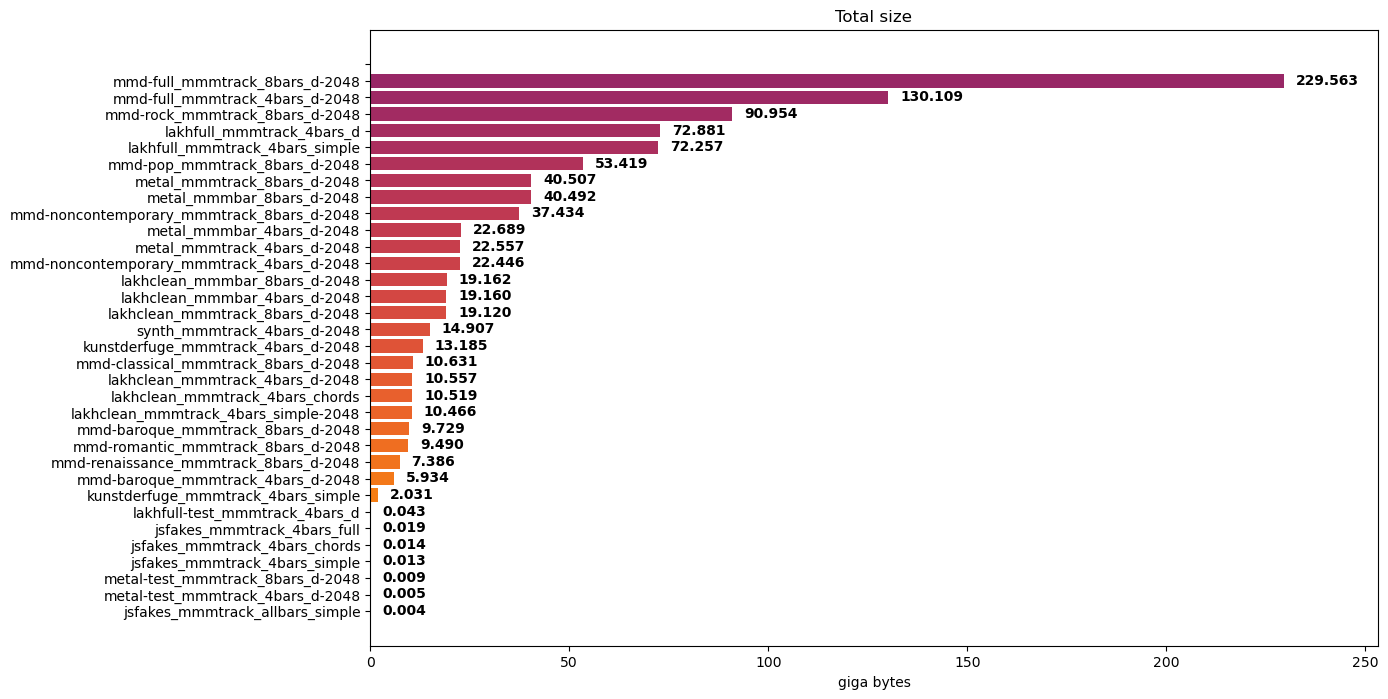
Encoding a dataset of MIDI files would yield a collection of token files. The size of those token files depends on the number of MIDI files and the number of bars. Consider some of the experiment datasets and their encoded dataset sizes:
- JS Fake Chorales Dataset: 14 MB with four bars per sample
- The Lakh MIDI Dataset: 72 GB, its Clean subset 19 GB with four bars per sample
- The MetaMIDI Dataset: 130 GB with four bars and 230 GB with eight bars per sample
You can imagine that training on the 14 MB of JS Fake Chorales would take just a few hours. Training on the MetaMIDI Dataset with its 130 GB would take many days. Training for these experiments lasted between 10 and 15 days.
Model training
Many models were trained using the HuggingFace GPT-2 implementation. A few models were trained using the NVIDIA Megatron-LM in GPT-2 mode.
Training with HuggingFace boiled down to uploading the dataset to the DGX-2 and then running a training script that contained all functionality, including the model and training parameters. The same script was used, with just a few changes here and there for all our datasets. It was just a matter of scale.
For Megatron-LM, the environment setup is as easy as pulling and running an NGC PyTorch Docker container, then getting to work immediately with a Jupyter notebook in the browser through ssh tunneling into the DGX-2 machine.
Most of the experiments used the same GPT-2 architecture: six decoder-blocks and eight attention heads; the embedding size was 512, and the sequence length was 2048. Although this is definitely not a Large Language Model (LLM), which can have around 100 decoder blocks, subjective evaluation showed that for AI music this architecture works like a charm.
Using the NVIDIA DGX-2 really made a difference in rapid iteration. Datasets that would train for multiple days on a single GPU, would train for just a few hours on DGX-2. Datasets that would train for months on a single GPU, finished training after two weeks maximum on DGX-2. Especially for experiments with datasets <25 GB, the models converged very fast.
Training times for some of the datasets were as follows:
- The Lakh MIDI Clean Dataset took 15 hours for 10 epochs and roughly 15K songs
- The Lakh MIDI Dataset took 130 hours for 10 epochs and roughly 175K songs
- The MetaMIDI Dataset took 290 hours for 9 epochs and roughly 400K songs
Note that the JS Fake Chorales dataset was trained earlier and not on the DGX-2. Due to its very small size, it was not necessary to use a multi-GPU setup. It could even be trained overnight on a MacBook Pro.
NVIDIA DGX-2
This section provides a closer look at the NVIDIA DGX-2 specifications. As mentioned above, the platform is very effective, both when it comes to accelerated dataset preprocessing, and when it comes to training language models. This section will be a delightfully technical one.

NVIDIA DGX-2 is a powerful system with 16 fully connected NVIDIA V100 32 GB GPUs using NVSwitch. It is capable of delivering 2.4 TB/s of bisection bandwidth. DGX-2 has been designed for AI researchers and data scientists who need both performance and scalability.
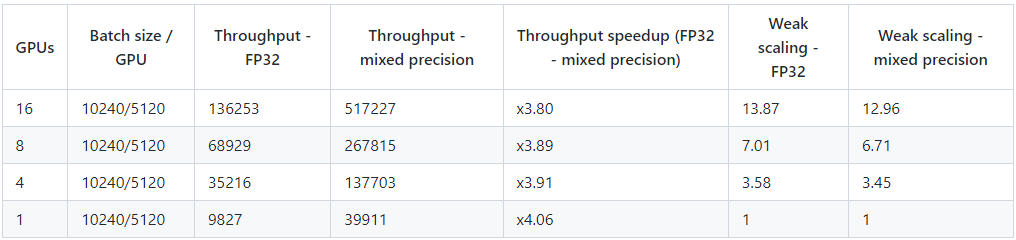
For transformer models, NVIDIA DGX-2 is able to deliver up to 517,227 tokens per second throughput with mixed precision, making it especially powerful.
Software framework: NVIDIA Megatron-LM
To get the most out of powerful compute, you need stable and optimized software. With a performance-optimized framework such as NVIDIA Megatron-LM, performance is scaled almost linearly as the GPT model sizes are scaled. For related information, see Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism.
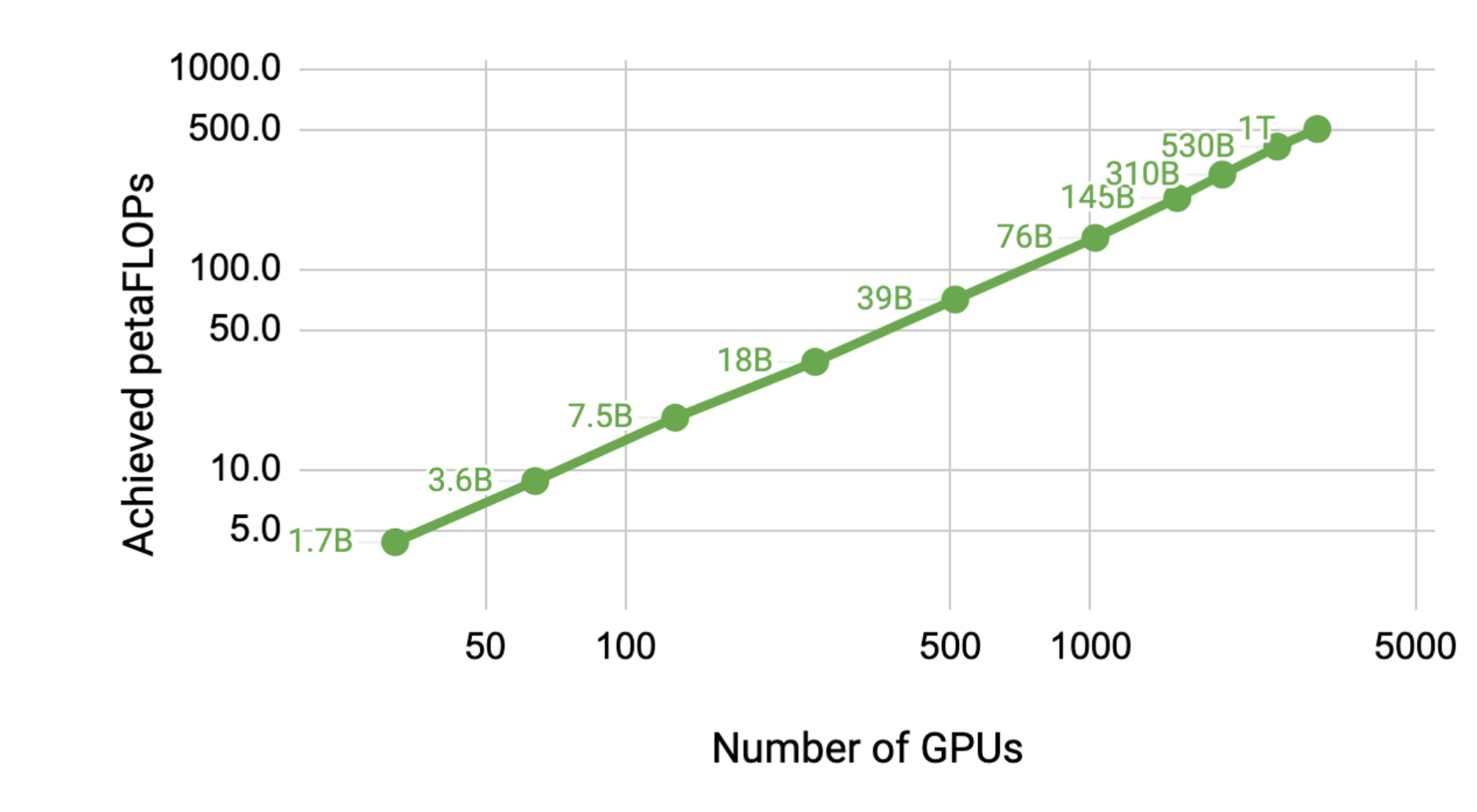
A baseline is achieved by training a model of 1.2 billion parameters on a single NVIDIA V100 32 GB GPU, that sustains 39 teraflops. This is 30% of the theoretical peak flops for a single GPU as configured in a DGX-2H server, and is thus a strong baseline.
Scaling the model to 8.3 billion parameters on 512 GPUs with 8-way model parallelism achieved up to 15.1 petaflops per second sustained over the entire application. This is 76% scaling efficiency compared to the single GPU case.
By fixing the seq_len, short-hands, equal to 4,096, and modifying training configurations and launch training runs with only a few iterations, it is possible to calculate the teraflop percent achieved in real application job runs.
After a native run, both the nvidia-smi as well as the output Nsight profile were analyzed. Different configurations were tested to obtain the highest possible teraflop, as the below table illustrates:
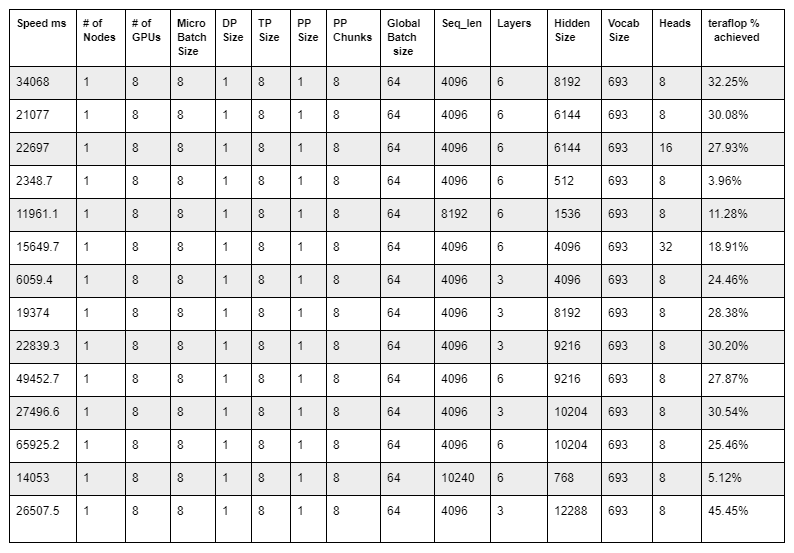
The training configuration presented in the last row of the table delivered the highest teraflop of 45.45%.
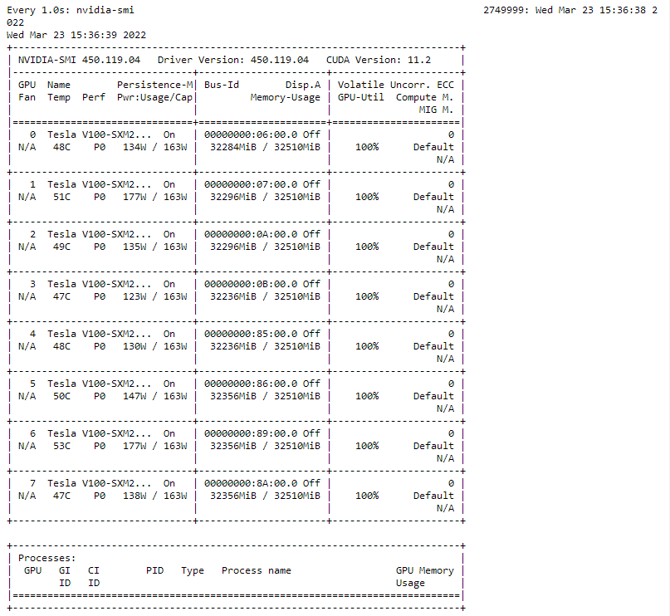
Note that eight V100 32 GB GPUs were used instead of 16 GPUs to shorten the time it takes to run each profiling job. The nvidia-smi command was used to verify with the training config that achieved 45.45% teraflops utilization, as illustrated below.
Summary
The AI music experiments presented here were performed using the NVIDIA DGX-2. We trained language models using datasets ranging from just a few megabytes in size to 230 GB. We used the HuggingFace GPT-2 implementation and showed that NVIDIA Megatron-LM is also a great alternative for experimentation.
NVIDIA DGX-2 made a significant difference in accelerating dataset preprocessing—mapping MIDI files to a token representation—and training models. This allowed for rapid experimentation. DGX-2 worked like a charm when it came to training the largest MIDI dataset available (MetaMIDI with 400K files).
