
Transformers, with their attention-based architecture, have become the dominant choice for language models (LMs) due to their strong performance, parallelization capabilities, and long-term recall through key-value (KV) caches. However, their quadratic computational cost and high memory demands pose efficiency challenges. In contrast, state space models (SSMs) like Mamba and Mamba-2 offer constant complexity and efficient hardware optimization but struggle with memory recall tasks, affecting their performance on general benchmarks.
NVIDIA researchers recently proposed Hymba, a family of small language models (SLMs) featuring a hybrid-head parallel architecture that integrates transformer attention mechanisms with SSMs to achieve both enhanced efficiency and improved performance. In Hymba, attention heads provide high-resolution recall, while SSM heads enable efficient context summarization.
The novel architecture of Hymba reveals several insights:
- Overhead in attention: Over 50% of attention computation can be replaced by cheaper SSM computation.
- Local attention dominance: Most global attention can be replaced by local attention without sacrificing performance on general and recall-intensive tasks, thanks to the global information summarized by SSM heads.
- KV cache redundancy: Key-value cache is highly correlated across heads and layers, so it can be shared across heads (group query attention) and layers (cross-layer KV cache sharing).
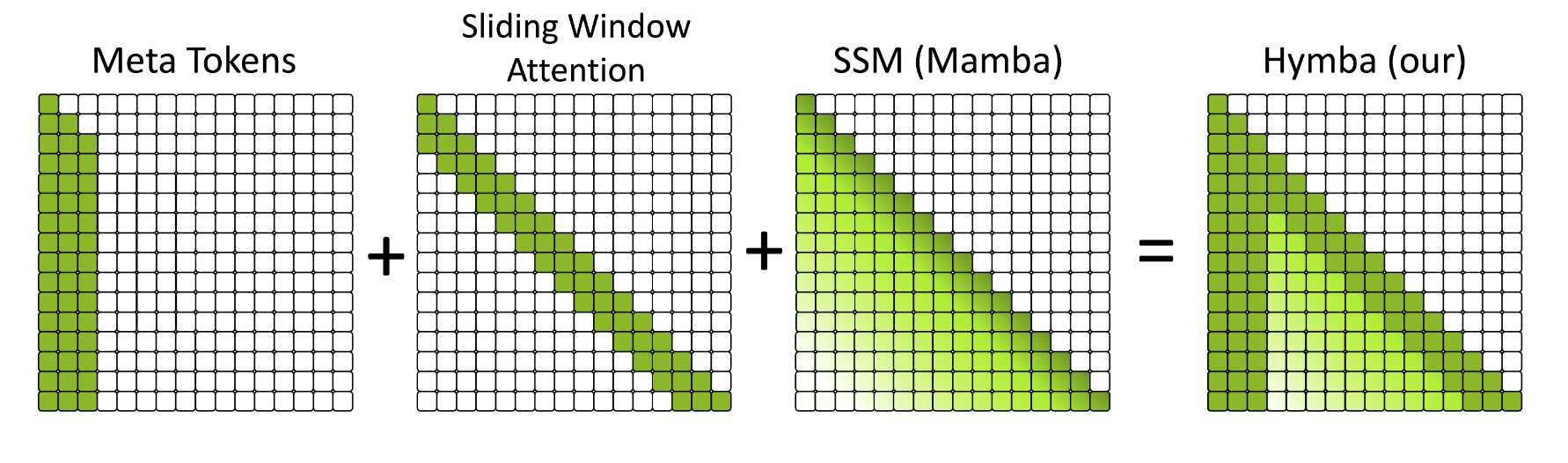
- Softmax attention limitation: Attention mechanisms are constrained to sum to one, limiting sparsity, and flexibility. We introduce learnable meta-tokens that are prepended to prompts, storing critical information and alleviating the “forced-to-attend” burden associated with attention mechanisms.
This post shows that Hymba 1.5B performs favorably against state-of-the-art open-source models of similar size, including Llama 3.2 1B, OpenELM 1B, Phi 1.5, SmolLM2 1.7B, Danube2 1.8B, and Qwen2.5 1.5B. Compared to Transformer models of similar size, Hymba also achieves higher throughput and requires 10x less memory to store cache.
Hymba 1.5B is released to the Hugging Face collection and GitHub.
Hymba 1.5B performance
Figure 1 compares Hymba 1.5B against sub-2B models (Llama 3.2 1B, OpenELM 1B, Phi 1.5, SmolLM2 1.7B, Danube2 1.8B, Qwen2.5 1.5B) in terms of average task accuracy, cache size (MB) relative to sequence length, and throughput (tok/sec).
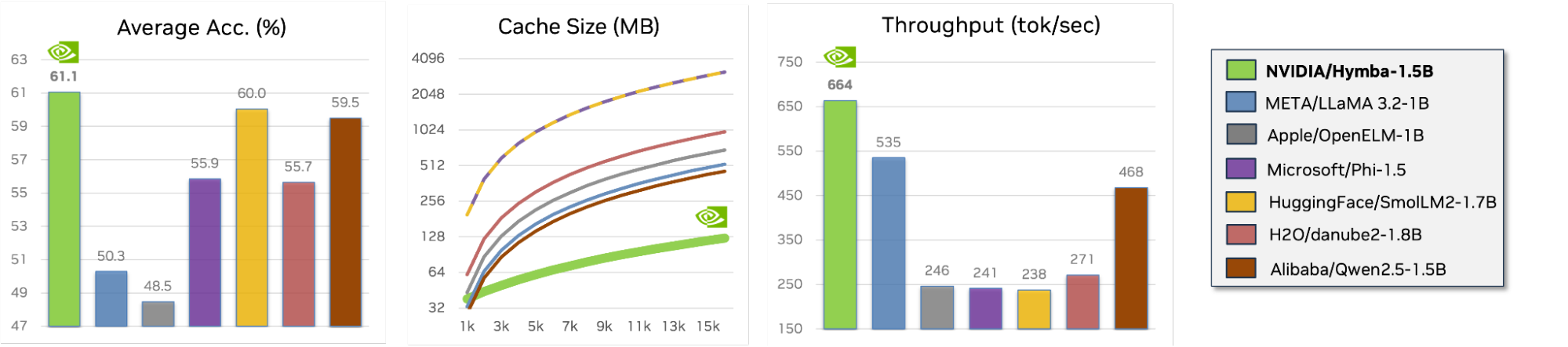
In this set of experiments, the tasks include MMLU, ARC-C, ARC-E, PIQA, Hellaswag, Winogrande, and SQuAD-C. The throughput is measured on an NVIDIA A100 GPU with a sequence length of 8K and a batch size of 128 using PyTorch. For models encountering out of memory (OOM) issues during throughput measurement, the batch size was halved until the OOM is resolved to measure the maximal achievable throughput without OOM.
Hymba model design
SSMs such as Mamba were introduced to address the quadratic complexity and large inference-time KV cache issues of transformers. However, due to their low-resolution memory, SSMs struggle with memory recall and performance. To overcome these limitations, we propose a road map for developing efficient and high-performing small LMs in Table 1.
| Configuration | Commonsense reasoning (%) ↑ | Recall (%) ↑ | Throughput (token/sec) ↑ | Cache size (MB) ↓ | Design reason |
| Ablations on 300M model size and 100B training tokens | |||||
| Transformer (Llama) | 44.08 | 39.98 | 721.1 | 414.7 | Accurate recall while inefficient |
| State-space models (Mamba) | 42.98 | 19.23 | 4720.8 | 1.9 | Efficient while inaccurate recall |
| A. + Attention heads (sequential) | 44.07 | 45.16 | 776.3 | 156.3 | Enhance recall capabilities |
| B. + Multi-head heads (parallel) | 45.19 | 49.90 | 876.7 | 148.2 | Better balance of two modules |
| C. + Local / global attention | 44.56 | 48.79 | 2399.7 | 41.2 | Boost compute/cache efficiency |
| D. + KV cache sharing | 45.16 | 48.04 | 2756.5 | 39.4 | Cache efficiency |
| E. + Meta-tokens | 45.59 | 51.79 | 2695.8 | 40.0 | Learned memory initialization |
| Scaling to 1.5B model size and 1.5T training tokens | |||||
| F. + Size / data | 60.56 | 64.15 | 664.1 | 78.6 | Further boost task performance |
| G. + Extended context length (2K→8K) | 60.64 | 68.79 | 664.1 | 78.6 | Improve multishot and recall tasks |
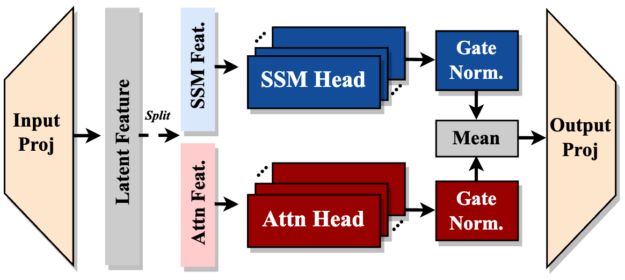
Fused hybrid modules
Fusing attention and SSM heads in parallel within a hybrid-head module outperforms sequential stacking, according to the ablation study. Hymba fuses attention and SSM heads in parallel within a hybrid head module, enabling both heads to process the same information simultaneously. This architecture improves reasoning and recall accuracy.
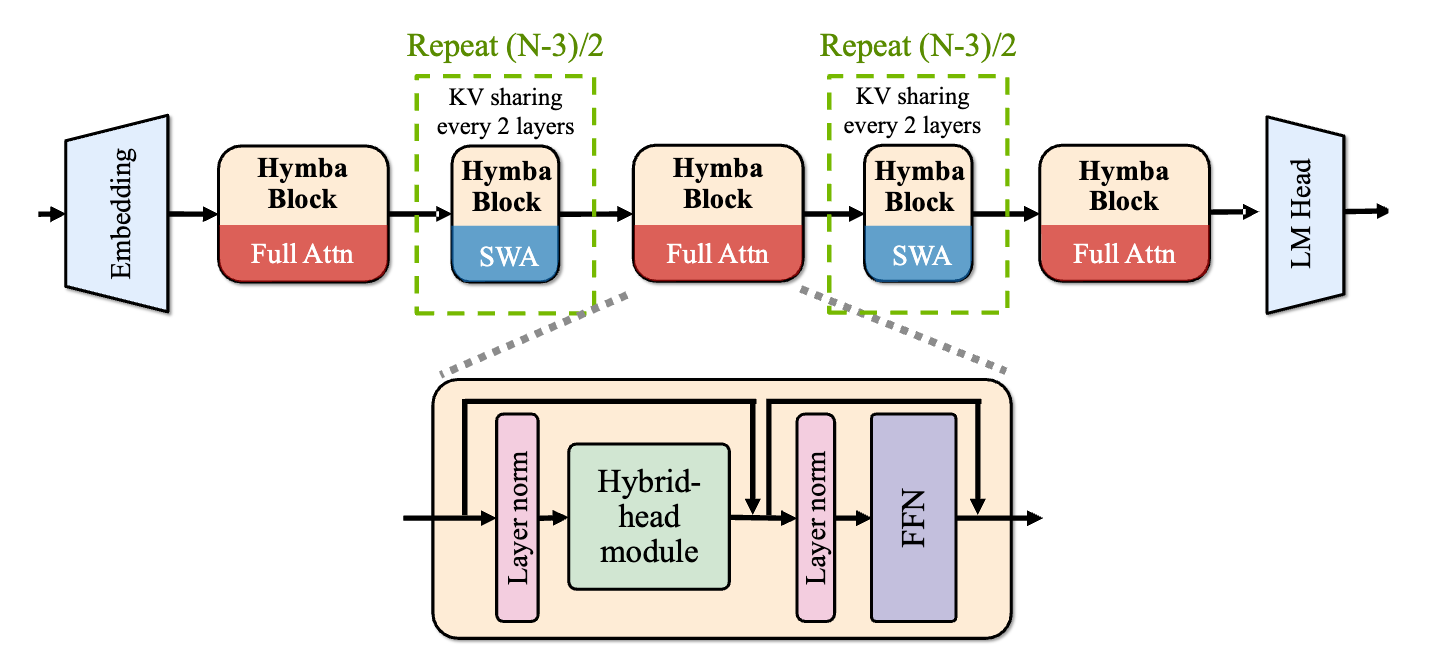
Efficiency and KV cache optimization
While attention heads improve task performance, they increase KV cache requirements and reduce throughput. To mitigate this, Hymba optimizes the hybrid-head module by combining local and global attention and employing cross-layer KV cache sharing. This improves throughput by 3x and reduces cache by almost 4x without sacrificing performance.
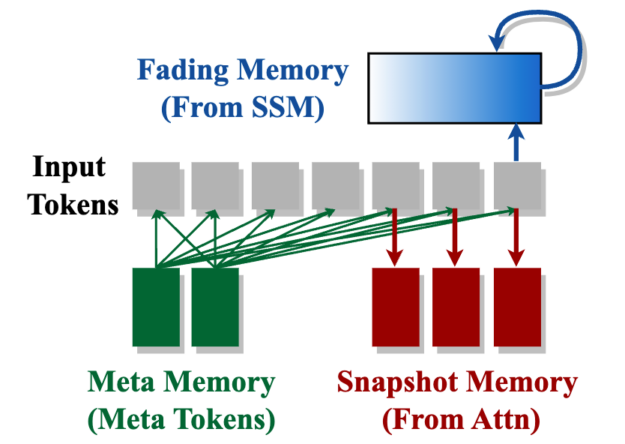
Meta-tokens
A set of 128 pretrained embeddings prepended to inputs, functioning as learned cache initialization to enhance focus on relevant information. These tokens serve a dual purpose:
- Mitigating attention drain by acting as backstop tokens, redistributing attention effectively
- Encapsulating compressed world knowledge
Model analysis
This section presents an apples-to-apples comparison across different architectures under the same training settings. We then visualize the attention maps of SSM and Attention in different pretrained models. Finally, we perform head importance analysis for Hymba through pruning. All the analyses in this section help to illustrate how and why the design choices for Hymba are effective.
Apples-to-apples comparison
We performed an apples-to-apples comparison of Hymba, pure Mamba2, Mamba2 with FFN, Llama3 style, and Samba style (Mamba-FFN-Attn-FFN) architectures. All models have 1 billion parameters and are trained from scratch for 100 billion tokens from SmolLM-Corpus with exactly the same training recipe. All results are obtained through lm-evaluation-harness using a zero-shot setting on Hugging Face models. Hymba performs the best on commonsense reasoning as well as question answering and recall-intensive tasks.
Table 2 compares various model architectures on language modeling and recall-intensive and commonsense reasoning tasks, with Hymba achieving strong performance across metrics. Hymba demonstrates the lowest perplexity in language tasks (18.62 for Wiki and 10.38 for LMB) and solid results in recall-intensive tasks, particularly in SWDE (54.29) and SQuAD-C (44.71), leading to the highest average score in this category (49.50).
| Model | Language (PPL) ↓ | Recall intensive (%) ↑ | Commonsense reasoning (%) ↑ |
| Mamba2 | 15.88 | 43.34 | 52.52 |
| Mamba2 w/ FFN | 17.43 | 28.92 | 51.14 |
| Llama3 | 16.19 | 47.33 | 52.82 |
| Samba | 16.28 | 36.17 | 52.83 |
| Hymba | 14.5 | 49.5 | 54.57 |
In commonsense reasoning and question answering, Hymba outperforms other models in most tasks, such as SIQA (31.76) and TruthfulQA (31.64), with an average score of 54.57, slightly above Llama3 and Mamba2. Overall, Hymba stands out as a balanced model, excelling in both efficiency and task performance across diverse categories.
Attention map visualization
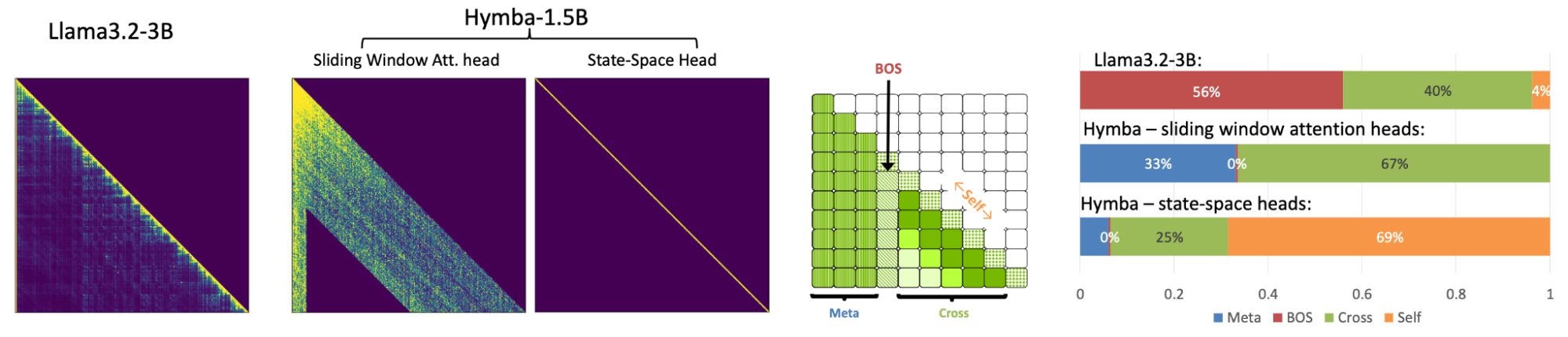
We further categorized elements in the attention map into four types:
- Meta: Attention scores from all real tokens to meta-tokens. This category reflects the model’s preference for attending to meta-tokens. In attention maps, they are usually located in the first few columns (for example, 128 for Hymba) if a model has meta-tokens.
- BOS: Attention scores from all real tokens to the beginning-of-sequence token. In the attention map, they are usually located in the first column right after the meta-tokens.
- Self: Attention scores from all real tokens to themselves. In the attention map, they are usually located in the diagonal line.
- Cross: Attention scores from all real tokens to other real tokens. In the attention map, they are usually located in the off-diagonal area.
The attention pattern of Hymba is significantly different from that of vanilla Transformers. In vanilla Transformers, attention scores are more concentrated on BOS, which is consistent with the findings in Attention Sink. In addition, vanilla Transformers also have a higher proportion of Self attention scores. In Hymba, meta-tokens, attention heads, and SSM heads work complementary to each other, leading to a more balanced distribution of attention scores across different types of tokens.
Specifically, meta-tokens offload the attention scores from BOS, enabling the model to focus more on the real tokens. SSM heads summarize the global context, which focuses more on current tokens (Self attention scores). Attention heads, on the other hand, pay less attention to Self and BOS tokens, and more attention to other tokens (that is, Cross attention scores). This suggests that the hybrid-head design of Hymba can effectively balance the attention distribution across different types of tokens, potentially leading to better performance.
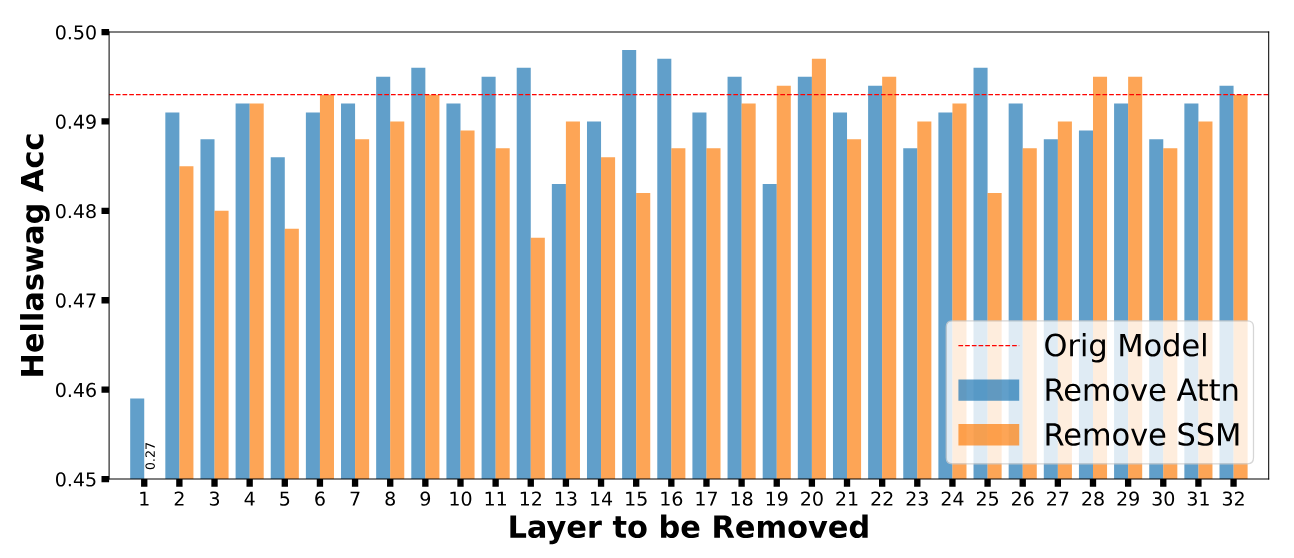
Heads importance analysis
We analyzed the relative importance of attention and SSM heads in each layer by removing them and recording the final accuracy. Our analysis reveals the following:
- The relative importance of attention/SSM heads in the same layer is input-adaptive and varies across tasks, suggesting that they can serve different roles when handling various inputs.
- The SSM head in the first layer is critical for language modeling, and removing it causes a substantial accuracy drop to random guess levels.
- Generally, removing one attention/SSM head results in an average accuracy drop of 0.24%/1.1% on Hellaswag, respectively.
Model architecture and training best practices
This section outlines key architectural decisions and training methodologies for Hymba 1.5B Base and Hymba 1.5B Instruct.
Model architecture
- Hybrid architecture: Mamba is great at summarization and usually closer focuses on the current token, while attention is more precise and acts as snapshot memory. Combining them in parallel merges these benefits, but standard sequential fusion does not. We chose a 5:1 parameter ratio between SSM and attention heads.
- Sliding window attention: Full attention heads are preserved in three layers (first, last, and middle), with sliding window attention heads used in the remaining 90% layers.
- Cross-layer KV cache sharing: Implemented between every two consecutive attention layers. It is done in addition to GQA KV cache sharing between heads.
- Meta-tokens: These 128 tokens are learnable with no supervision, helping to avoid entropy collapse problems in large language models (LLMs) and mitigate the attention sink phenomenon. Additionally, the model stores general knowledge in these tokens.
Training best practices
- Pretraining: We opted for two-stage base model training. Stage 1 maintained a constant large learning rate and used less filtered large corpus data. Continuous learning rate decay was then performed to 1e-5 using high-quality data. This approach enables continuous training and resuming of Stage 1.
- Instruction fine-tuning: Instruct model tuning is performed in three stages. First, SFT-1 provides the model with strong reasoning abilities by training on code, math, function calling, role play, and other task-specific data. Second, SFT-2 teaches the model to follow human instructions. Finally, DPO is leveraged to align the model with human preferences and improve the model’s safety.

Performance and efficiency evaluation
With only 1.5T pretraining tokens, the Hymba 1.5B model performs the best among all small LMs and achieves better throughput and cache efficiency than all transformer-based LMs.
For example, when benchmarking against the strongest baseline, Qwen2.5, which is pretrained on 13x more tokens, Hymba 1.5B achieves a 1.55% average accuracy improvement, 1.41x throughput, and 2.90x cache efficiency. Compared to the strongest small LM trained on fewer than 2T tokens, namely h2o-danube2, our method achieves a 5.41% average accuracy improvement, 2.45x throughput, and 6.23x cache efficiency.
| Model | # Para-ms | Train tokens | Token per sec | Cache (MB) | MMLU 5- shot | ARC-E 0-shot | ARC-C 0-shot | PIQA 0-shot | Wino. 0-shot | Hella. 0-shot | SQuAD -C 1-shot | Avg |
| Open ELM-1 | 1.1B | 1.5T | 246 | 346 | 27.06 | 62.37 | 19.54 | 74.76 | 61.8 | 48.37 | 45.38 | 48.57 |
| Rene v0.1 | 1.3B | 1.5T | 800 | 113 | 32.94 | 67.05 | 31.06 | 76.49 | 62.75 | 51.16 | 48.36 | 52.83 |
| Phi 1.5 | 1.3B | 0.15T | 241 | 1573 | 42.56 | 76.18 | 44.71 | 76.56 | 72.85 | 48 | 30.09 | 55.85 |
| Smol LM | 1.7B | 1T | 238 | 1573 | 27.06 | 76.47 | 43.43 | 75.79 | 60.93 | 49.58 | 45.81 | 54.15 |
| Cosmo | 1.8B | .2T | 244 | 1573 | 26.1 | 62.42 | 32.94 | 71.76 | 55.8 | 42.9 | 38.51 | 47.2 |
| h20 dan-ube2 | 1.8B | 2T | 271 | 492 | 40.05 | 70.66 | 33.19 | 76.01 | 66.93 | 53.7 | 49.03 | 55.65 |
| Llama 3.2 1B | 1.2B | 9T | 535 | 262 | 32.12 | 65.53 | 31.39 | 74.43 | 60.69 | 47.72 | 40.18 | 50.29 |
| Qwen 2.5 | 1.5B | 18T | 469 | 229 | 60.92 | 75.51 | 41.21 | 75.79 | 63.38 | 50.2 | 49.53 | 59.51 |
| AMD OLMo | 1.2B | 1.3T | 387 | 1049 | 26.93 | 65.91 | 31.57 | 74.92 | 61.64 | 47.3 | 33.71 | 48.85 |
| Smol LM2 | 1.7B | 11T | 238 | 1573 | 50.29 | 77.78 | 44.71 | 77.09 | 66.38 | 53.55 | 50.5 | 60.04 |
| Llama 3.2 3B | 3.0B | 9T | 191 | 918 | 56.03 | 74.54 | 42.32 | 76.66 | 69.85 | 55.29 | 43.46 | 59.74 |
| Hymba | 1.5B | 1.5T | 664 | 79 | 51.19 | 76.94 | 45.9 | 77.31 | 66.61 | 53.55 | 55.93 | 61.06 |
Instructed models
The Hymba 1.5B Instruct model achieves the highest performance on an average of all tasks, outperforming the previous state-of-the-art model, Qwen 2.5 Instruct, by around 2%. Specifically, Hymba 1.5B surpasses all other models in GSM8K/GPQA/BFCLv2 with a score of 58.76/31.03/46.40, respectively. These results indicate the superiority of Hymba 1.5B, particularly in areas requiring complex reasoning capabilities.
| Model | # Params | MMLU ↑ | IFEval ↑ | GSM8K ↑ | GPQA ↑ | BFCLv2 ↑ | Avg. ↑ |
| SmolLM | 1.7B | 27.80 | 25.16 | 1.36 | 25.67 | -* | 20.00 |
| OpenELM | 1.1B | 25.65 | 6.25 | 56.03 | 21.62 | -* | 27.39 |
| Llama 3.2 | 1.2B | 44.41 | 58.92 | 42.99 | 24.11 | 20.27 | 38.14 |
| Qwen2.5 | 1.5B | 59.73 | 46.78 | 56.03 | 30.13 | 43.85 | 47.30 |
| SmolLM2 | 1.7B | 49.11 | 55.06 | 47.68 | 29.24 | 22.83 | 40.78 |
| Hymba 1.5B | 1.5B | 52.79 | 57.14 | 58.76 | 31.03 | 46.40 | 49.22 |
Conclusion
The new Hymba family of small LMs features a hybrid-head architecture that combines the high-resolution recall capabilities of attention heads with the efficient context summarization of SSM heads. To further optimize the performance of Hymba, learnable meta-tokens are introduced to act as a learned cache for both attention and SSM heads, enhancing the model’s focus on salient information. Through the road map of Hymba, comprehensive evaluations, and ablation studies, Hymba sets new state-of-the-art performance across a wide range of tasks, achieving superior results in both accuracy and efficiency. Additionally, this work provides valuable insights into the advantages of hybrid-head architectures, offering a promising direction for future research in efficient LMs.
Learn more about Hybma 1.5B Base and Hymba 1.5B Instruct.
Acknowledgments
This work would not have been possible without contributions from many people at NVIDIA, including Wonmin Byeon, Zijia Chen, Ameya Sunil Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, Nikolaus Binder, Hanah Zhang, Maksim Khadkevich, Yingyan Celine Lin, Jan Kautz, Pavlo Molchanov, and Nathan Horrocks.
