Posts by Sharath Sreenivas

Agentic AI / Generative AI
Dec 17, 2024
Data-Efficient Knowledge Distillation for Supervised Fine-Tuning with NVIDIA NeMo-Aligner
Knowledge distillation is an approach for transferring the knowledge of a much larger teacher model to a smaller student model, ideally yielding a compact,...
5 MIN READ

Agentic AI / Generative AI
Oct 08, 2024
Mistral-NeMo-Minitron 8B Model Delivers Unparalleled Accuracy
This post was originally published August 21, 2024 but has been revised with current data. Recently, NVIDIA and Mistral AI unveiled Mistral NeMo 12B, a leading...
7 MIN READ

Agentic AI / Generative AI
Aug 14, 2024
How to Prune and Distill Llama-3.1 8B to an NVIDIA Llama-3.1-Minitron 4B Model
Large language models (LLM) are now a dominant force in natural language processing and understanding, thanks to their effectiveness and versatility. LLMs such...
12 MIN READ
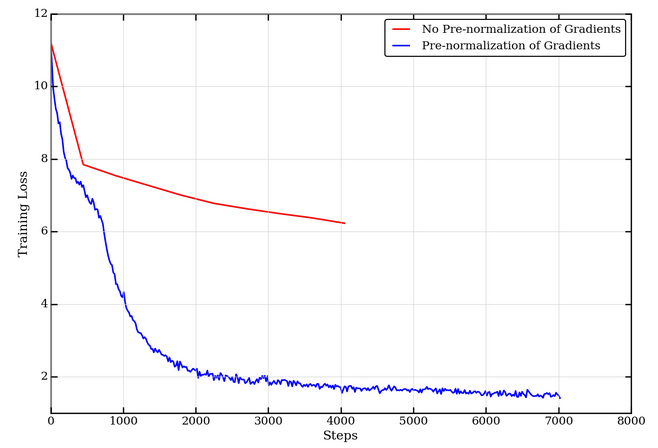
AI / Deep Learning
Dec 05, 2019
Pretraining BERT with Layer-wise Adaptive Learning Rates
Training with larger batches is a straightforward way to scale training of deep neural networks to larger numbers of accelerators and reduce the training time....
10 MIN READ