
Meshes are one of the most important and widely used representations of 3D assets. They are the default standard in the film, design, and gaming industries and they are natively supported by virtually all the 3D softwares and graphics hardwares.
A 3D mesh can be considered as a collection of polygon faces, most commonly consisting of triangles or quadrilaterals.
An important property of a mesh is its topology, which refers to the organization of these polygon faces that discretize the 3D surface. Artist-created meshes usually feature highly informative and well-organized topologies that align closely with the underlying structure of the object.
Having artist-like topology is essential for editing, texturing, animation, and efficient rendering. However, creating these meshes manually by artists is a labor-intensive task that requires significant time and expertise in 3D modeling.
A mesh can be extracted algorithmically from other 3D representations. In a typical text-to-3D or image-to-3D generation system, a neural generator produces a neural field, which is then converted into a mesh using algorithms such as variants of Marching Cubes [FlexiCubes (NVIDIA), NMC, DiffMC] or Marching Tetrahedra [DMTet (NVIDIA)].
Unfortunately, these hand-designed algorithms produce dense meshes that do not have artist-like topology, hindering the quality and usefulness of these methods.
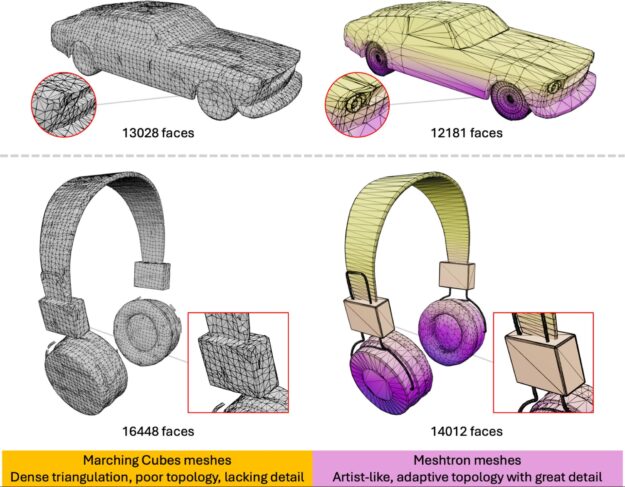
Figure 1. Mesh comparisons
An emerging line of work generates meshes in a data-driven fashion by learning from existing artist-created meshes using machine learning algorithms. These works show great potential yet are limited in scalability, with the best method handling up to 1.6K faces:
In sharp contrast, a delicate 3D object often requires over 10K faces to be accurately modeled. Our survey shows that artist-created meshes typically have a median face count of 10K and a mean of 32K.
Meshtron provides a simple and scalable, data-driven solution for generating intricate, artist-like meshes of up to 64K faces at 1024-level coordinate resolution. This is over an order of magnitude higher face count and 8x higher coordinate resolution compared to existing methods.
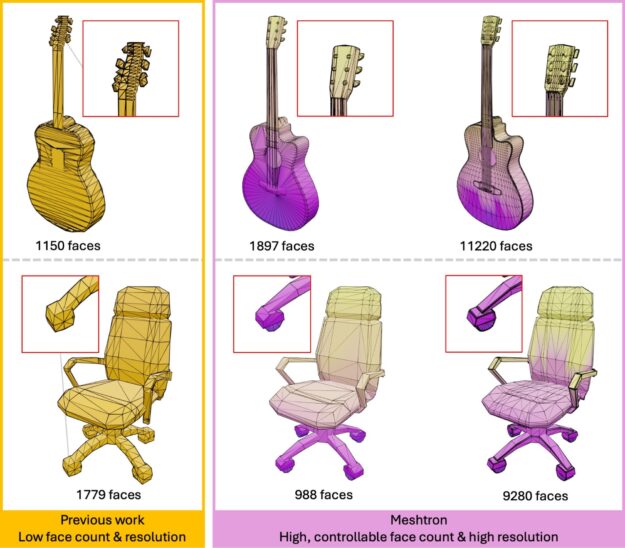
Figure 2. Comparison of previous low-poly meshes with low resolution and Meshtron-generated meshes with controllable face count and high resolution
A mesh as a sequence of tokens
Meshtron is an autoregressive model that generates mesh tokens. It shares the same working principle as autoregressive language models such as GPTs.
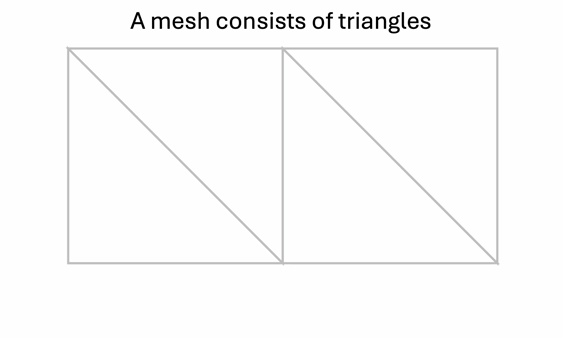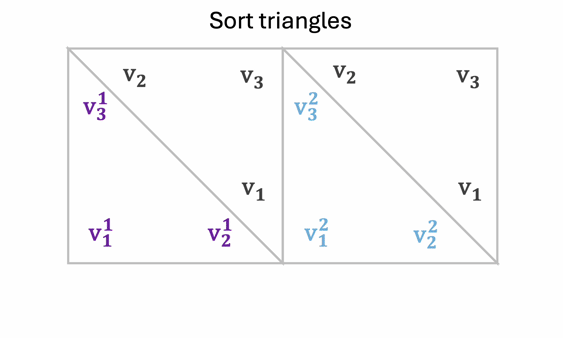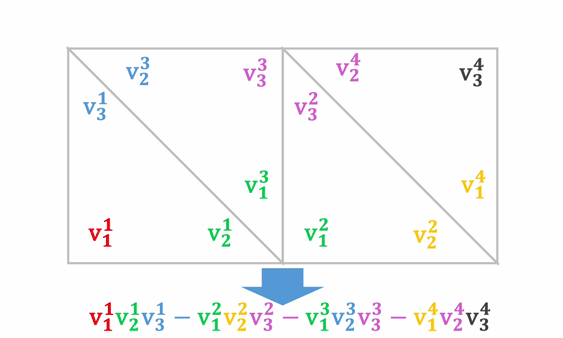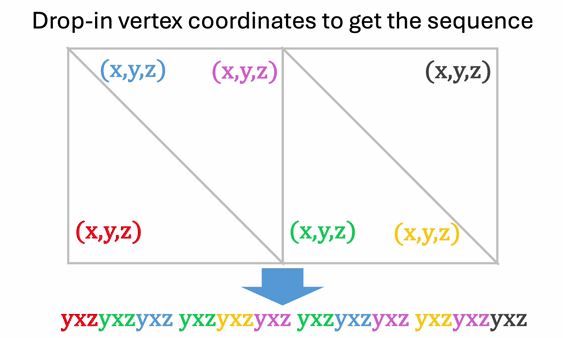
A mesh can easily be converted to a sequence of tokens. The basic building block of a mesh is a triangle face, which can be represented with nine tokens:
- Each triangle has three vertices.
- Each vertex has three coordinates.
- Each coordinate can be quantized to obtain a discrete token.
A mesh can thus be represented uniquely as a sequence of tokens by chaining these face tokens together according to a bottom-to-top sorted order.

Meshtron is an efficient mesh generator
Directly generating these mesh tokens can be costly. A mesh with 32K faces requires 300K tokens. For a typical autoregressive model, this would be extremely slow to generate and expensive to train.
Meshtron adopts an Hourglass Transformer architecture, which saves computation and memory by internally merging the tokens to reduce the sequence length. More specifically, the model consists of three stages, each stage reducing the sequence length by three times:
- First stage: Operates on the coordinate level, which processes every token.
- Second stage: Operates on the vertex level, processing one token per vertex (3x reduction).
- Third stage: Operates on the face level, processing one token per face (9x reduction).

By allocating more layers to the stages with higher reduction ratios, the computation and memory cost is significantly reduced compared to conventional, single-staged models.
Each stage of the Hourglass network aligns perfectly with the coordinate-vertex-face semantics of a mesh. This not only improves the modeling efficiency, but also has the additional benefit of allocating more compute power to difficult-to-generate tokens. Within each triangle, the first vertex is the easiest to generate while the last vertex is the most difficult.
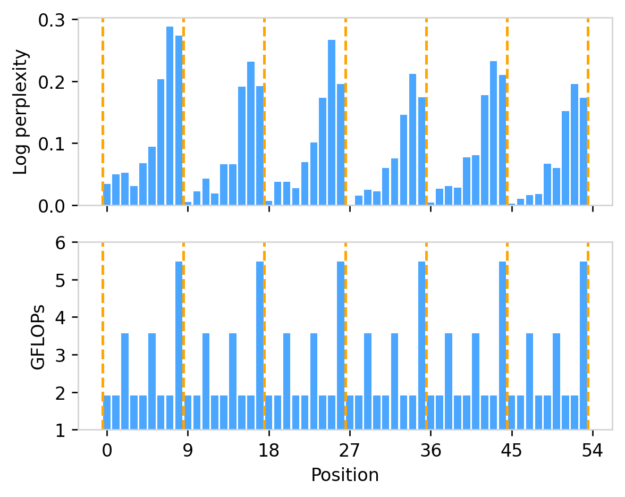
Figure 6. Log perplexity and per-token GFLOPs at different token positions
Another efficiency-boosting technique used by Meshtron is sliding window attention. A conventional Transformer model has a context length that grows with the sequence length, leading to quadratic growth of compute and linear growth of memory consumption as the sequence becomes longer. This leads to significant slowdown with long sequences both during training and generation.
Instead, Meshtron maintains a fixed-length context window of 8192 faces. During training, the mesh sequences are randomly cropped to up to 8192 faces. During inference, the token generated more than 8192 faces ago is evicted from the KV cache. The sliding window technique leads to a constant memory cost and constant token throughput that never slows down as the mesh size grows.
With the help of these techniques, Meshtron achieves 2.5x faster token throughput and over 50% saving in memory both during training and inference, while generating better quality meshes.
Meshtron is highly controllable
The current version of Meshtron accepts the following control inputs:
- Point cloud: Determines the shape of the output mesh.
- Face count: Determines the density of the output mesh.
- Quad ratio: Switches between quad and triangle tessellation.
- Creativity: Can be adjusted to generate extra details not present in the point cloud.
As almost all of the 3D representations can be converted to point clouds, Meshtron can either serve as a stand-alone remesher to improve the quality of existing meshes, or be used in tandem with a text-to-3D or image-to-3D model to generate artist-grade meshes from scratch.
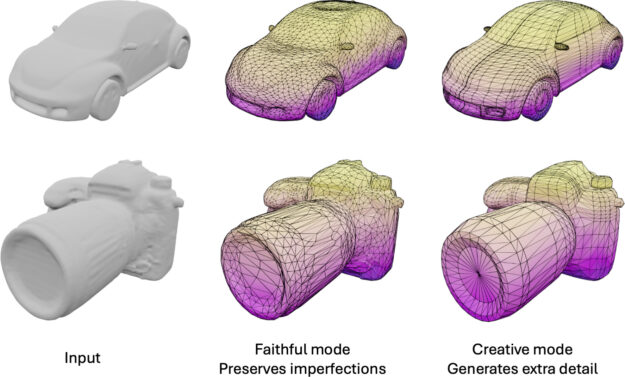
Figure 7. Meshtron control over creativity
The control input of Meshtron is implemented with cross-attention, which is highly extensible and can easily be adapted to other types of inputs such as images, additional control, and so on. It also enables sliding-window inference by providing the global context.
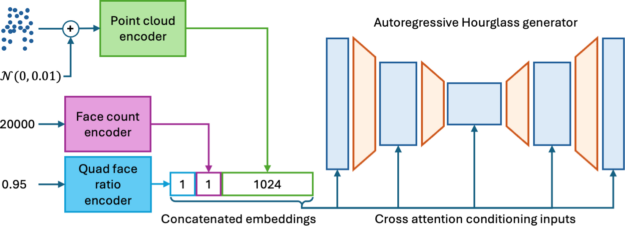
Figure 8. Meshtron full model architecture
Conclusion
Meshtron is an autoregressive mesh generator based on the Hourglass architecture and using sliding window attention. It exploits the periodicity and locality of a mesh sequence to achieve greatly improved efficiency.
Meshtron generates meshes of detailed, complex 3D objects at unprecedented levels of resolution and fidelity, closely resembling those created by professional artists. It opens the door to a more realistic generation of detailed 3D assets for animation, gaming, and virtual environments.
Owing to its general and highly extensible architecture, we hope that Meshtron can serve as the reference for future mesh generation research and applications.
For more information see the following resources:
