Researchers from Google developed a deep learning-based system that can create short video clips from still images shot on stereo cameras, VR cameras, and dual lens cameras, such as an iPhone 7 or X.
“Given two images with known camera parameters, our goal is to learn a deep neural net to infer a global scene representation suitable for synthesizing novel views of the same scene, and in particular extrapolating beyond the input views,” the researchers wrote in their research paper.
Using NVIDIA Tesla P100 GPUs and the cuDNN-accelerated TensorFlow deep learning framework the team trained their system on over 7000 real estate videos posted on YouTube.
“Our view synthesis system based on multiplane images {MPIs) can handle both indoor and outdoor scenes,” the researchers said. “We successfully applied it to scenes which are quite different from those in our training dataset. The learned MPIs are effective at representing surfaces which are partially reflective or transparent.”
The team says their system performs better than previous methods, and can effectively magnifying the narrow baseline of stereo imagery captured by cell phones and stereo cameras.
“We show that our method achieves better numeral performance on a held-out test, and also produces more spatially stable output imagery since our inferred scene representation is shared for synthesizing all target views.”
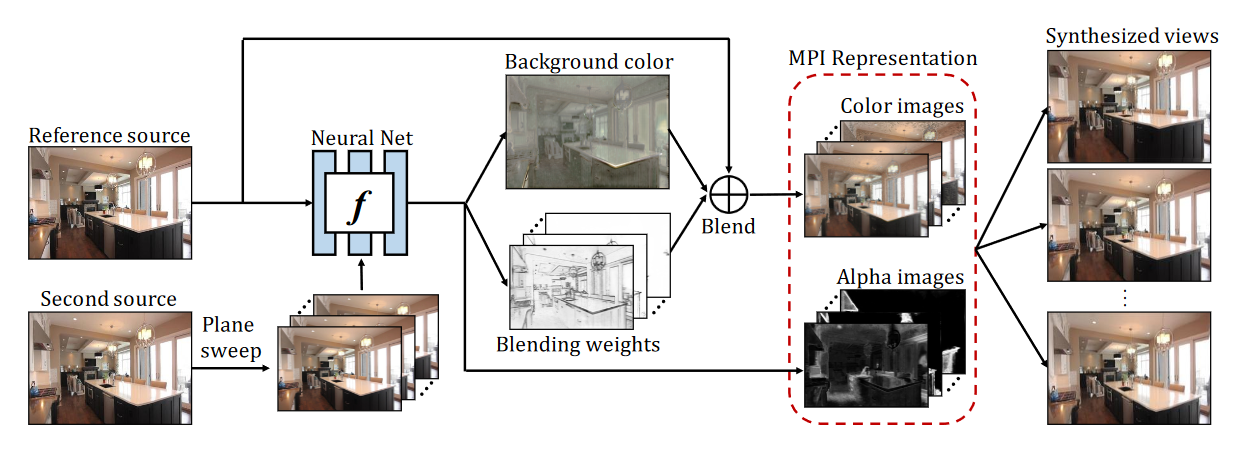
The team concedes their model isn’t perfect, but they believe the method can be used to extrapolate data from two input images, generate light fields allowing view movement in multiple dimensions.
The research was published on ArXiv today.
Read more>
Google Researchers Use AI to Bring Still Photos to Life

May 25, 2018
Discuss (0)
AI-Generated Summary
- Researchers from Google developed a deep learning-based system that creates short video clips from still images captured by stereo cameras, VR cameras, and dual lens cameras.
- The system uses a multiplane image (MPI) representation to synthesize novel views of a scene and can handle both indoor and outdoor scenes, including those with partially reflective or transparent surfaces.
- The team trained their system on over 7000 real estate videos posted on YouTube using NVIDIA Tesla P100 GPUs and the cuDNN-accelerated TensorFlow deep learning framework.
AI-generated content may summarize information incompletely. Verify important information. Learn more