
If you’re an active Jetson developer, you know that one of the key benefits of NVIDIA Jetson is that it combines a CPU and GPU into a single module, giving you the expansive NVIDIA software stack in a small, low-power package that can be deployed at the edge.
Jetson also features a variety of other processors, including hardware accelerated encoders and decoders, an image signal processor, and the Deep Learning Accelerator (DLA).
The DLA is available on Jetson AGX Xavier, Xavier NX, Jetson AGX Orin and Jetson Orin NX modules. The recent NVIDIA DRIVE Xavier and Orin-based platforms also have DLA cores.
If you use the GPU for deep learning execution, read on to learn more about DLA, why it’s useful, and how to use it.
Overview of the Deep Learning Accelerator
The DLA is an application-specific integrated circuit that is capable of efficiently performing fixed operations, like convolutions and pooling, that are common in modern neural network architectures. Though the DLA doesn’t have as many supported layers as the GPU, it still supports a wide variety of layers used in many popular neural network architectures.
In many instances, the layer support may cover the requirements of your model. For example, the NVIDIA TAO Toolkit includes a wide variety of pre-trained models that are supported by the DLA, ranging from object detection to action recognition.
While it’s important to note that the DLA throughput is typically lower than that of the GPU, it is power-efficient and allows you to offload deep learning workloads, freeing the GPU for other tasks. Alternatively, depending on your application, you can run the same model on the GPU and DLA simultaneously to achieve higher net throughput.
Many NVIDIA Jetson developers are already using the DLA to successfully optimize their applications. Postmates optimized their delivery robot application on Jetson AGX Xavier leveraging the DLA along with the GPU. The Cainiao ET Lab used the DLA to optimize their logistics vehicle. If you’re looking to fully optimize your application, the DLA is an important piece in the Jetson repertoire to consider.
How to use the Deep Learning Accelerator
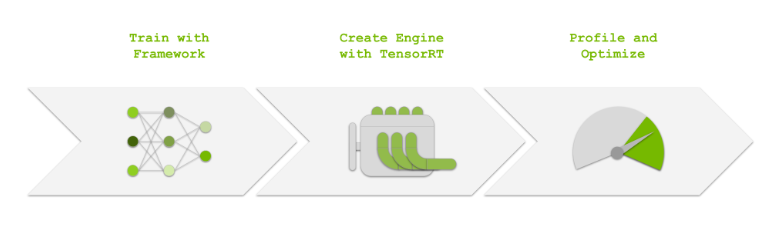
To use the DLA, you first need to train your model with a deep learning framework like PyTorch or TensorFlow. Next, you need to import and optimize your model with NVIDIA TensorRT. TensorRT is responsible for generating the DLA engines, and can also be used as a runtime for executing them. Finally, you should profile your mode and make optimizations where possible to maximize DLA compatibility.
Get started with the Deep Learning Accelerator
Ready to dive in? The Jetson_dla_tutorial GitHub project demonstrates a basic DLA workflow to help you in your journey toward optimizing your application for Jetson.
With the tutorial, you can learn how to define the model in PyTorch, import the model with TensorRT, analyze the performance using the NVIDIA Nsight System profiler, modify the model for better DLA compatibility, and calibrate for INT8 execution. Note that the CIFAR10 dataset is used as a toy example to facilitate reproducing the steps.
Explore the Jetson_dla_tutorial to get started.
More resources
- Visit the Deep Learning Accelerator product page for more information about DLA.
- The NVIDIA TAO Toolkit has pre-trained models covering tasks from object detection to action recognition that are DLA-ready. View performance benchmarks and learn more.
