
NVIDIA Collective Communications Library (NCCL) provides optimized implementation of inter-GPU communication operations, such as allreduce and variants. Developers using deep learning frameworks can rely on NCCL’s highly optimized, MPI compatible and topology aware routines, to take full advantage of all available GPUs within and across multiple nodes.
NCCL is optimized for high bandwidth and low latency over PCIe and NVLink high speed interconnect for intra-node communication and sockets and InfiniBand for inter-node communication. NCCL—allows CUDA applications and DL frameworks in particular—to efficiently use multiple GPUs without having to implement complex communication algorithms and adapt them to every platform.
The latest NCCL 2.3 release makes NCCL fully open-source and available on GitHub. The pre-built and tested binaries (debs, rpms, tgz) will continue to be available on Developer Zone. This should provide you with the flexibility you need and enable us to have open discussions with the community as we continue to build a great product.
Let’s dive into the improvements.
Bandwidth
NCCL provides optimal bandwidth on most platforms, saturating NVLinks, PCIe links and network interfaces.
NCCL performance tests introduced the notion of bus bandwidth for all supported collective operations to make sure NCCL ran at the maximum theoretical speed. This allowed for performance numbers to be compared with the native hardware characteristics, similarly to what can be done for classical send/receive operations. For example, machines connected through a 10Gb/s network card should be able to perform operations at up to 1.2 GB/s.
Intra-node performance
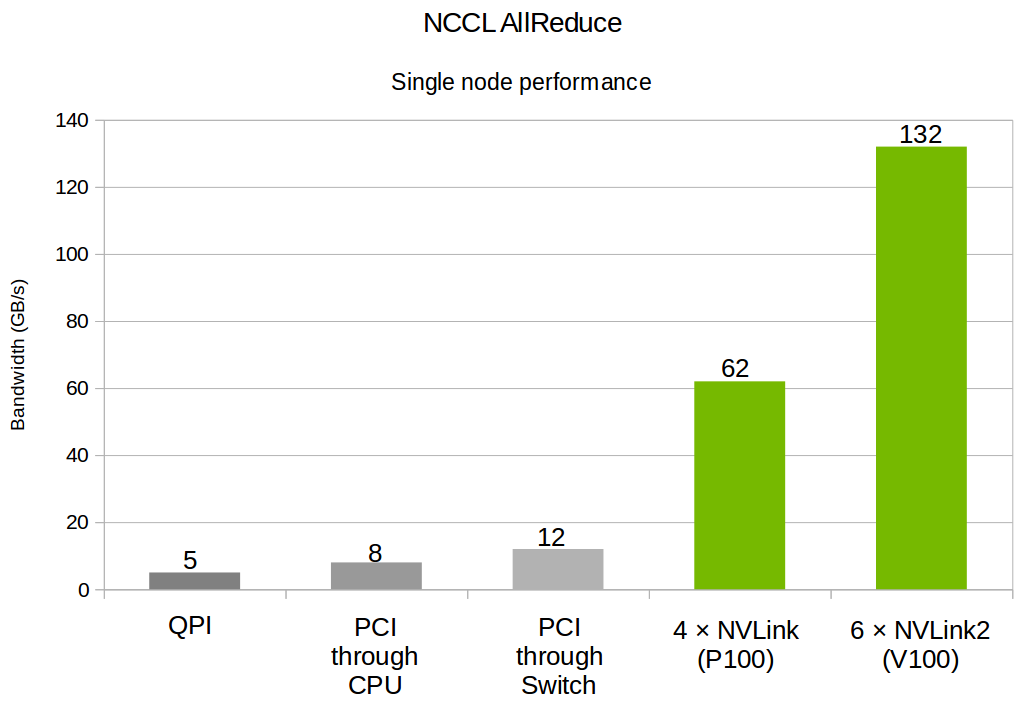
Figure 1 shows the bus bandwidth to expect from various topologies. If some of the GPUs are connected to different CPU sockets without NVLink, GPUs will have to communicate through shared memory which will limit the bandwidth to 5GB/s. With all GPUs connected directly through PCI, NCCL can use GPU Direct P2P to directly write data from one GPU to another. This way, we can achieve 12GB/s. If the PCI traffic is routed through a CPU, bandwidth will be lower, around 8 GB/s. Finally, when GPUs are all connected through NVLink, NCCL detects the topology and can aggregate NVLink connections to get significantly higher bandwidth. Pascal GPUs can communicate at up to 62GB/s using four NVLink connections, while Volta GPUs can reach 132GB/s using six second generation NVLinks.
Inter-node performance
When communicating inter-node, NCCL can also aggregate multiple network interfaces and deliver the full bandwidth, provided the intra-node topology can also sustain that bandwidth.
NCCL uses TCP/IP sockets to communicate with standard network cards. While this works well on relatively slow 10GbE cards, getting the full bandwidth out of 100GbE cards can be harder. The TCP stack might need to be tuned. Also, the lack of GPU-Direct RDMA equivalent for sockets limits the bandwidth to half the PCIe bandwidth due to data going multiple times through the PCIe link to the CPU.
NCCL supports InfiniBand and RoCE cards to yield higher bandwidth, using the InfiniBand verbs API instead of sockets. Using GPU Direct RDMA permits it to reach 11 GB/s with an IB EDR or RoCE 100GbE adapter. DGX1 and DGX2 machines respectively possess 4 and 8 InfiniBand/RoCE cards to maintain consistency with internal NVLink bandwidth. Transfer rates can therefore achieve 42 and 82 GB/s as shown in Figure 2 below.

Latency
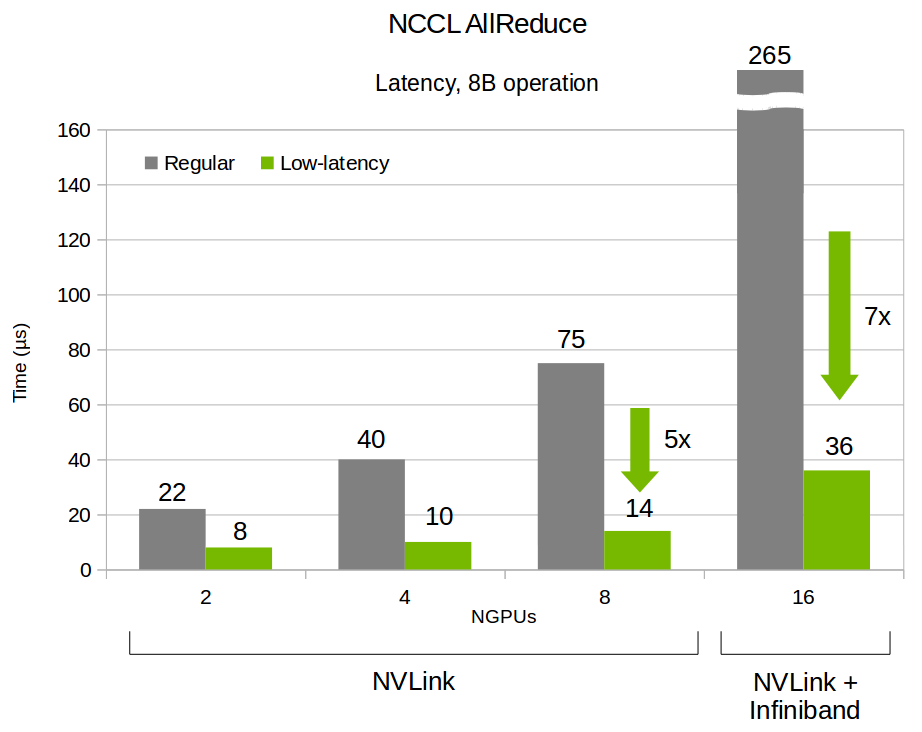
We have substantially improved the performance of small operations over the past few releases. This is a result of the low-latency (LL) algorithm which features fast thread-to-thread communication without the need for costly memory fences. Figure 3 below shows how this latency reduction greatly impacts the performance of small operations.
The low-latency algorithm can also improve performance for medium sizes reductions.
Figure 4 and 5 below show the evolution of latency and bandwidth from NCCL 2.0 up until NCCL 2.3. These are theoretical numbers extrapolated for illustration purposes, not actual benchmarks. NCCL 2.1 provides much lower latency for small sizes, but had a fixed threshold of 16kB which is not adapted for more than 8 GPUs. NCCL 2.3 introduces better automatic tuning to provide a smooth transition from one algorithm to the other.
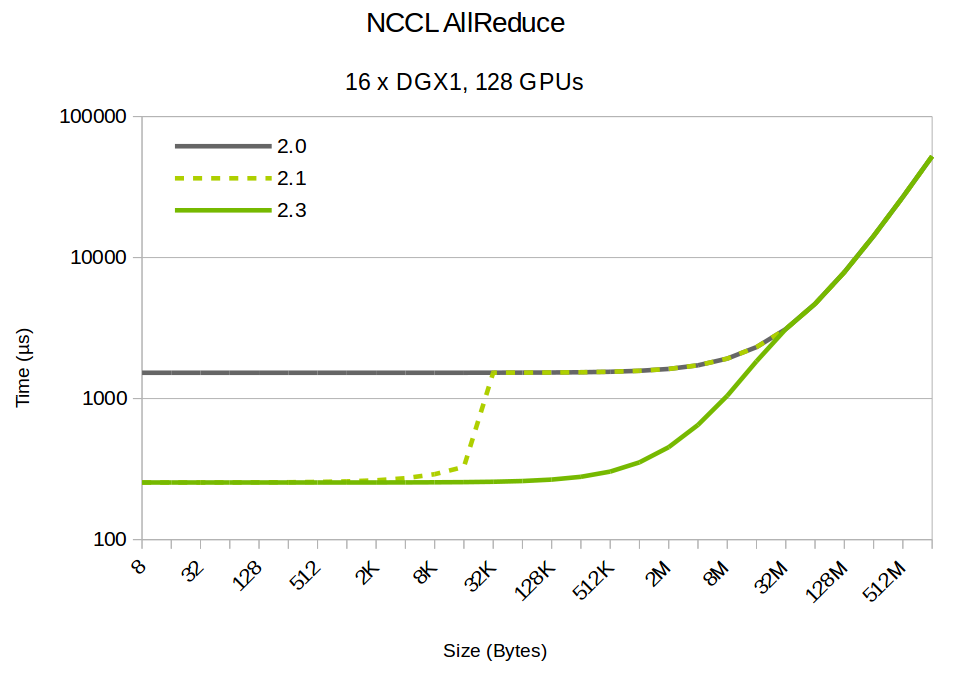
Because of its design, the low-latency path is however limited to 50% of the bandwidth, hence NCCL needs to switch back to the regular algorithm for large sizes, as shown in Figure 5 below.

Aggregation
Multiple operations can be grouped together to recoup the kernel launch cost and perform multiple operations in parallel, leading to a better utilization of the resources and hardware. This further reduces the time per operation.
Figure 6 below shows how 8 GPUs in a DGX1 server takes less than a microsecond per operation when aggregating 64 operations together. Contrast this with 14 microseconds without aggregation.

Flexible multi-GPU management
NCCL allows the application developers to decide how to manage GPUs from processes and threads. One thread may launch operations on multiple GPUs; applications may also have one thread per GPU or even one process per GPU, similar to MPI applications. NCCL is easily integrated in client-server, multi-threaded, or MPI applications.
Get started with NCCL today
You can download the latest version of prebuilt and test NCCL binaries here. The source code is available on Github. See how NCCL can help you accelerate your deep learning applications. NCCL performance tests can be found at https://github.com/nvidia/nccl-tests. Read the latest Release Notes for a detailed list of new features and enhancements.