
The advent of large language models (LLMs) has significantly benefited the AI industry, offering versatile tools capable of generating human-like text and handling a wide range of tasks. However, while LLMs demonstrate impressive general knowledge, their performance in specialized fields, such as veterinary science, is limited when used out of the box. To enhance their utility in specific areas, two primary strategies are commonly adopted in the industry: fine-tuning and retrieval-augmented generation (RAG).
Fine-tuning involves training the model on a carefully curated and structured dataset, demanding substantial hardware resources, as well as the involvement of domain experts, a process that is often time-consuming and costly. Unfortunately, in many fields, it’s incredibly challenging to access domain experts in a way that is compatible with business constraints.
Conversely, RAG involves building a comprehensive corpus of knowledge literature, alongside an effective retrieval system that extracts relevant text chunks to address user queries. By adding this retrieved information to the user query, LLMs can produce better answers. Although this approach still requires subject matter experts to curate the best sources for the dataset, it is more tractable and business-compatible than fine-tuning. Also, since extensive training of the model isn’t necessary, this approach is less computationally intensive and more cost-effective.
In creating RAG systems, developers invest significant effort into designing an effective mechanism to retrieve the best pieces of information from the knowledge dataset. As a result, it’s common to use semantic similarity measures through textual embeddings to retrieve the most pertinent text.
NVIDIA NIM and NLP pipelines
NVIDIA NIM streamlines the design of NLP pipelines using LLMs. These microservices simplify the deployment of generative AI models across platforms, allowing teams to self-host LLMs while offering standard APIs to build applications.
NIM abstracts model inference internals like execution engines and runtime operations, ensuring optimal performance with TensorRT-LLM, vLLM, and others. Key features include the following:
- Scalable deployment
- Support for diverse LLM architectures with optimized engines
- Flexible integration into existing workflows
- Enterprise-grade security with safetensors and constant CVE monitoring
You can run NIM microservices with Docker and perform inference using APIs. Specialized trained model weights can also be used for specific tasks, such as document parsing, by modifying container commands.
In this post, I describe how NIM microservices are helping the AITEM team develop LAIKA, an AI copilot for veterinary practitioners. Specifically, I explore how NIM supports the RAG pipeline to maximize retrieval effectiveness, showing how the models both simplify and speed up the analysis and development processes.
Reimagining veterinarian care with AI
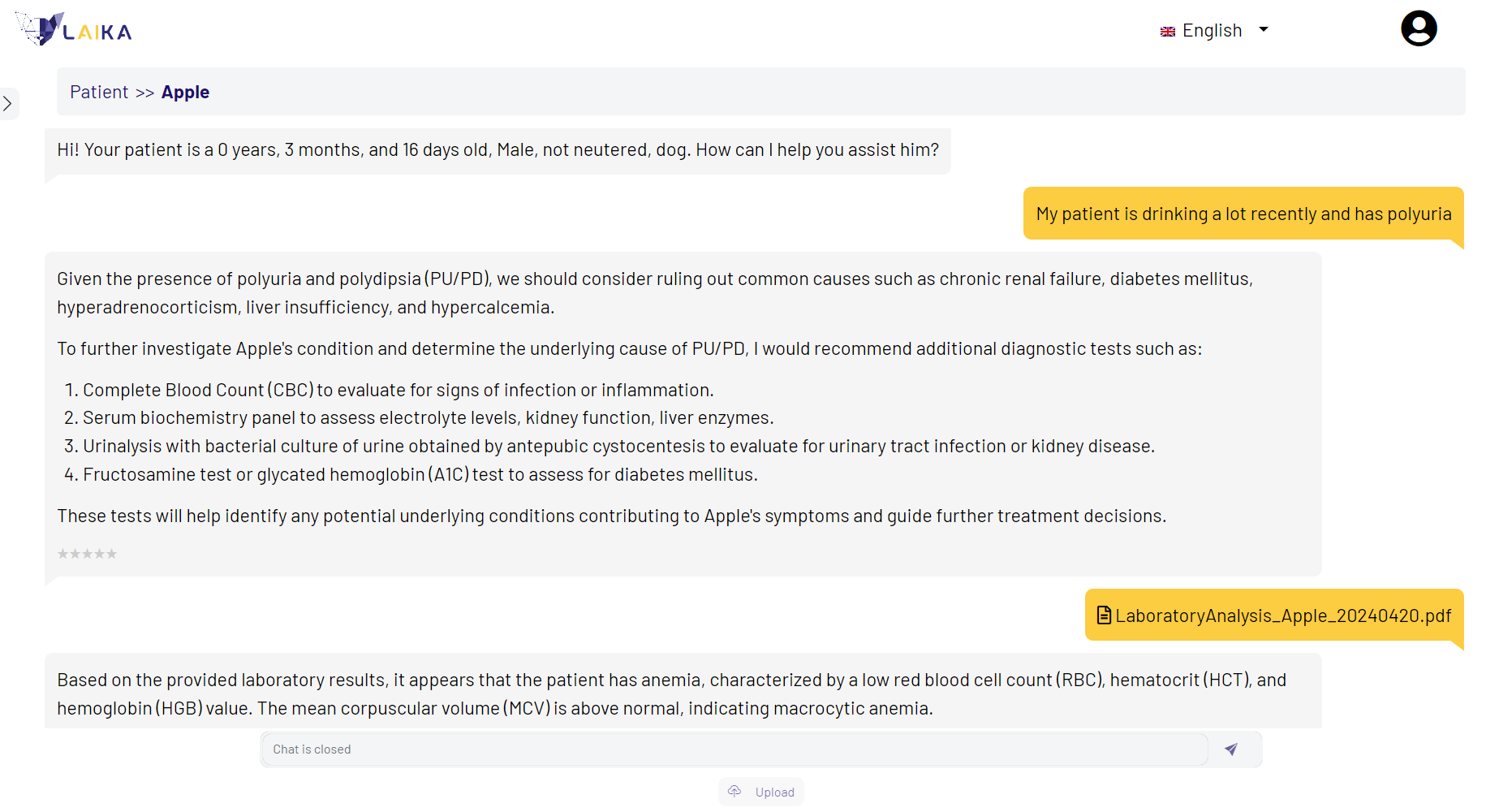
At AITEM, which is a member of the NVIDIA Inception Program for startups, we’ve collaborated closely with NVIDIA and concentrated on the development of AI-based solutions across multiple fields, including industrial and life sciences.
In the veterinary sector, we are working on LAIKA, an innovative AI copilot designed to assist veterinarians by processing patient data and offering diagnostic suggestions, guidance, and clarifications. LAIKA acts as a conversational agent, capable of handling both textual queries and laboratory analysis documents. Recently launched in Italy and France, LAIKA will soon expand to other countries.
LAIKA integrates multiple LLMs and RAG pipelines. The RAG component retrieves relevant information from a curated dataset of veterinary resources (Figure 2). During preparation, each resource is divided into chunks, with embeddings calculated and stored in the RAG database. During inference, the query is pre-processed and its embeddings are computed and compared with those in the RAG database using geometric distance metrics. The closest matches are selected as the most relevant and used to generate responses.
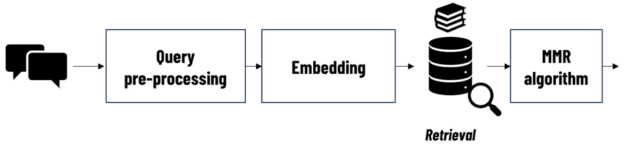
Due to potential redundancy in the RAG database, multiple retrieved chunks might contain the same information, limiting the diversity of concepts that are provided to the answer system. To address this, LAIKA employs the Maximal Marginal Relevance (MMR) algorithm to minimize chunk redundancy and ensure a broader range of relevant information.
As chunk extraction from resources is automated and the volume of resources is too large for manual verification, malformed chunks can be included, such as footnotes, bad charsets, or OCR errors. Although the probability of retrieving such irrelevant chunks is low due to out-of-distribution embeddings, it is not zero and that may still affect the response quality.
While distance metric-based similarity retrieval is a widely used method, it is not flawless. It can retrieve well-formed but non-useful or even misleading information. Minimizing the impact of incorrect retrievals is essential for maintaining high answer quality.
NVIDIA NeMo Retriever Reranking NIM microservice
The NVIDIA API Catalog has a collection of NeMo Retriever NIM microservices that enable organizations to seamlessly connect custom models to diverse business data and deliver highly accurate responses.
The collection includes NVIDIA Retrieval QA Mistral 4B reranking NIM microservice, a model designed to assess the probability that a given text passage contains relevant information for answering a user query. Integrating this model into the RAG pipeline enabled us to filter out retrievals that do not pass the reranking model’s evaluation, ensuring that only the most relevant and accurate information was used. Alternatively, the output from the reranking model can be used to sort retrieved chunks, retaining only those ranked at the top.
To assess the impact of this step on the RAG pipeline, we designed an experiment:
- Extract a dataset of ~100 anonymized questions from LAIKA users.
- Run the current RAG pipeline to retrieve chunks for each question.
- Sort the retrieved chunks based on probabilities provided by the reranking model.
- Evaluate each chunk for relevance to the query.
- Analyze the reranking model’s probability distribution in relation to the relevance determined in Step 4.
- Compare the ranking of chunks in Step 3 against their relevance from Step 4.
User questions in LAIKA can vary significantly in form (Figure 3). Some queries contain detailed explanations of a situation but lack a specific question. Others contain precise inquiries regarding research, while some seek guidance or differential diagnoses based on clinical cases or analysis documents.

Due to the large number of chunks per question, we used the Llama 3.1 70B Instruct NIM microservice for the evaluation, which is also available in the NVIDIA API Catalog.
To better understand the reranking model’s performance on the dataset, we examined specific queries and model responses in detail. Table 1 highlights the top and bottom reranked chunks for the query, “The cat has been losing weight for two months with preserved appetite, without vomiting or diarrhea. What are the potential differential diagnoses?”
The top three chunks with positive logits (relevance probability: >50%), all provided useful information directly related to the question. In contrast, the bottom three chunks, which had large negative logits, were less relevant, covering limited case studies and drug complaints that were not helpful.
| Text | Reranking Logit |
| Causes of weight loss that can be particularly difficult to diagnose … include gastric disease not causing vomiting, intestinal disease not causing vomiting or diarrhea, hepatic disease … | 3.3125 |
| Differential diagnoses for nonspecific signs like anorexia, weight loss, vomiting, and diarrhea … acute pancreatitis is rare in cats, … signs are nonspecific and ill-defined (anorexia, lethargy, weight loss). | 2.3222 |
| Severe weight loss (with or without increased appetite) may be noted where there is cancer cachexia, maldigestion/malabsorption … Appetite may be increased in some conditions, such as hyperthyroidism in cats, … However, a normal appetite does not rule out the presence of a serious condition. | 2.2265 |
| Overall, weight loss was the most common presenting sign … with little difference between the groups … | -5.0078 |
| Other client complaints include lethargy, anorexia, weight loss, vomiting … | -7.3672 |
| There were 6 British Shorthair, 4 European Shorthair, and 1 Bengal cat … Reported clinical signs by owners included: reduced appetite or anorexia… | -10.3281 |
Figure 4 compares the reranking model probability output distribution (in logits) between relevant (good) and irrelevant (bad) chunks. The probabilities for good chunks are higher compared to bad chunks and a t-test confirmed that this difference is statistically significant, with a p-value lower than 3e-72.

Figure 5 shows the distribution difference in the reranking-induced sorting positions: good chunks are predominantly in top positions, while bad chunks are lower. The Mann-Whitney test confirmed that these differences are statistically significant, resulting in a p-value lower than 9e-31.

Figure 6 shows the ranking distribution and helps define an effective cutoff point. In the top five positions, most chunks are good, while the majority of chunks in positions 11-15 are bad. Thus, retaining only the top five retrievals or another chosen number can serve as one way to effectively exclude most of the bad chunks.

To optimize retrieval pipelines, and minimize ingestion costs while maximizing accuracy, a lightweight embedding model can be paired with the NVIDIA reranking NIM microservice, to boost retrieval accuracy. Execution time can be improved by 1.75x (Figure 7).

Better answers with the NVIDIA reranking NIM microservice
The results demonstrate that adding the NVIDIA reranking NIM microservice to the LAIKA RAG pipeline positively affects the relevance of retrieved chunks. By forwarding more precise, specialized information to the downstream answering LLM, it equips the model with the knowledge that’s necessary for highly specialized fields like veterinary science.
The NVIDIA reranking NIM microservice, available in the NVIDIA API Catalog, simplifies adoption as you can easily pull and run the model and infer its evaluations through APIs. This eliminates stress related to environment settings and manual optimization, as it comes pre-quantized and optimized with NVIDIA TensorRT for almost any platform.
For more information and the latest updates about LAIKA and other AITEM projects, see AITEM Solutions and follow LAIKA and AITEM on LinkedIn.
