
Generative AI has the ability to create entirely new content that traditional machine learning (ML) methods struggle to produce. In the field of natural language processing (NLP), the advent of large language models (LLMs) specifically has led to many innovative and creative AI use cases. These include customer support chatbots, voice assistants, text summarization and translation, and more—tasks previously handled by humans.
LLMs continue to evolve through various approaches, including increasing the number of parameters and the adoption of new algorithms like Mixture of Experts (MoE). The application and adaptation of LLMs are anticipated across many industries, including retail, manufacturing, and finance.
However, many models that currently top the LLM leaderboard show insufficient understanding and performance in non-English languages, including Japanese. One of the reasons for this is that the training corpus contains a high proportion of English data. For example, only 0.11% of the GPT-3 corpus is Japanese data. Creating LLM models that perform well in Japanese, which has less training data than English, has been immensely challenging.
This post presents insights gained from training an AI model with 172 billion parameters as part of the Generative AI Accelerator Challenge (GENIAC) project, using NVIDIA Megatron-LM to help address the shortage of high-performance models for Japanese language understanding.
LLM-jp initiatives at GENIAC
The Ministry of Economy, Trade and Industry (METI) launched GENIAC to raise the level of platform model development capability in Japan and to encourage companies and others to be creative. GENIAC has provided computational resources, supported matching with companies and data holders, fostered collaboration with global technology companies, held community events, and evaluated the performance of the developed platform models.
The LLM-jp project to develop a completely open model with 172 billion parameters (available on Hugging Face) with strong Japanese language capabilities was selected for the GENIAC initiative. LLM-jp 172B was the largest model development in Japan at that time (February to August 2024), and it was meaningful to share the knowledge of its development widely.
LLM-jp is an initiative launched by researchers in the field of natural language processing and computer systems, mainly at NII, to accumulate know-how on the mathematical elucidation of training principles, such as how large-scale models acquire generalization performance and the efficiency of learning, through the continuous development of models that are completely open and commercially available. The objective is to accumulate know-how on the efficiency of training.
Training the model using NVIDIA Megatron-LM
Megatron-LM serves as a lightweight research-oriented framework leveraging Megatron-Core for training LLMs at unparalleled speed. Megatron-Core, the main component, is an open-source library that contains GPU-optimized techniques and cutting-edge system-level optimizations essential for large-scale training.
Megatron-Core supports various advanced model parallelism techniques, including tensor, sequence, pipeline, context, and MoE expert parallelism. This library offers customizable building blocks, training resiliency features such as fast distributed checkpointing, and many other innovations such as Mamba-based hybrid model training. It’s compatible with all NVIDIA Tensor Core GPUs, and includes support for Transformer Engine (TE) with FP8 precision introduced with NVIDIA Hopper architecture.
Model architecture and training settings
Table 1 provides an overview of the model architecture for this project, which follows Llama 2 architecture.
| Parameter | Value |
| Hidden size | 12288 |
| FFN intermediate size | 38464 |
| Number of layers | 96 |
| Number of attention heads | 96 |
| Number of query groups | 16 |
| Activation function | SwiGLU |
| Position embedding | RoPE |
| Normalization | RMSNorm |
The LLM-jp 172B model is being trained from scratch using 2.1 trillion tokens of a multilingual corpus developed for the project consisting mainly of Japanese and English. The training is performed using NVIDIA H100 Tensor Core GPUs on Google Cloud A3 Instance with FP8 hybrid training using the Transformer Engine. Megatron-Core v0.6 and Transformer Engine v1.4 are used in the experiment.
Table 2 shows hyperparameter settings for training.
| Parameter | Value |
| LR | 1E-4 |
| min LR | 1E-5 |
| LR WARMUP iters | 2000 |
| Weight decay | 0.1 |
| Grad clip | 1.0 |
| Global batch size | 1728 |
| Context length | 4096 |
In addition, z-loss and batch-skipping techniques, which are used in PaLM, are incorporated to stabilize the training process, and flash attention is used to further speed up the training process.
To view other training configurations, please see llm-jp/Megatron-LM.
Training throughput and results
Pretraining for the latest LLM-jp 172B model is currently underway, with periodic evaluations every few thousand iterations to monitor training progress and ensure successful accuracy results on Japanese and English downstream tasks (Figure 1). So far, over 80% is complete, of the targeted 2.1 trillion tokens.
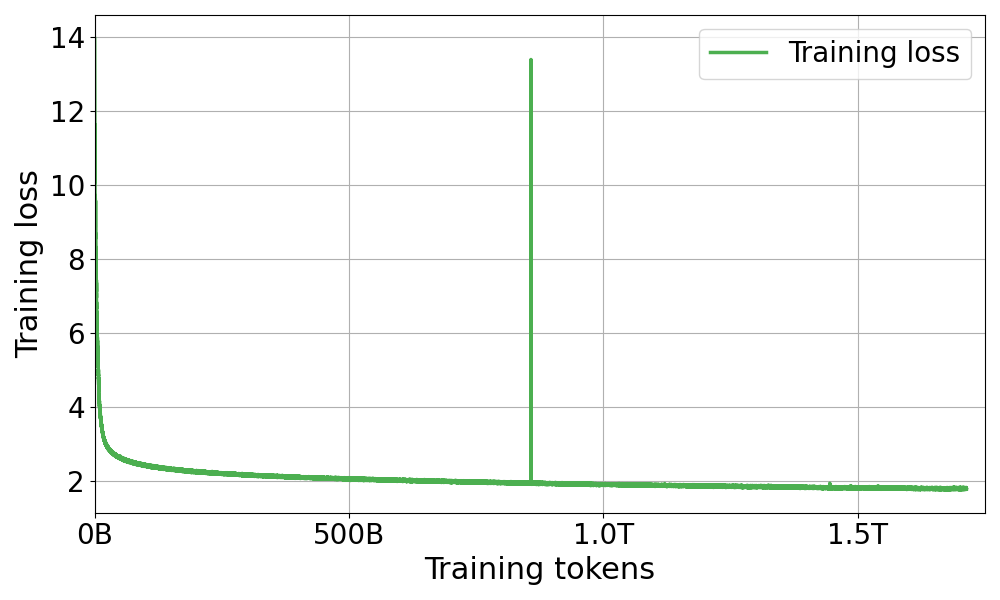
Notably, there is a sharp increase in TFLOP/s after approximately 7,000 iterations, corresponding to the transition from BF16 to FP8-hybrid precision. In this experiment, BF16 plus TE was used for training before 7,000 iterations, and FP8 hybrid plus TE was used after 7,000 iterations. In Megatron-LM, it is possible to enable hybrid FP8 training with the simple option --fp8-format ‘hybrid‘. Note that this feature is experimental, with further optimizations coming soon.
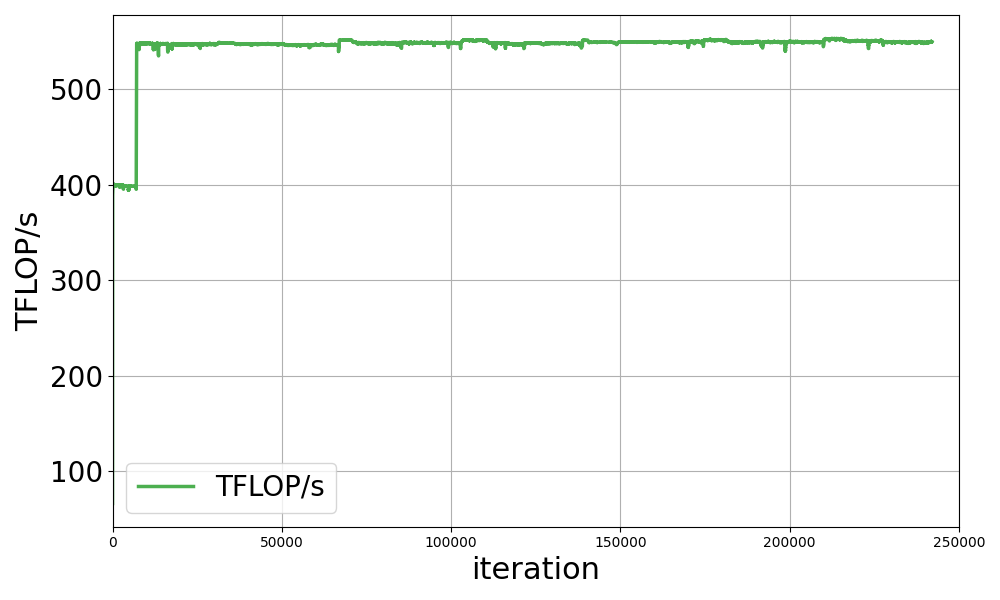
The reason we started the training with BF16 plus TE and then switched to FP8 hybrid was not only to see the tokens/sec performance difference between BF16 and FP8, but also to make the initial training more stable. In the early stages of training, the learning rate (LR) increases due to the warm-up, leading to unstable training.
We chose to perform the initial training with BF16, and after confirming that there were no problems with the values of training loss, optimizer states, gradient norm, and so on, we switched to FP8 to speed up the training process. FP8 hybrid has improved the training speed. We observed a training speed of 545-553 TFLOP/s with Megatron-LM.
Conclusion
As mentioned above, the training of LLM-jp 172B is still ongoing using Megatron-LM. Based on the evaluation results of downstream tasks using the current checkpoint data, we suppose that the model has already acquired excellent Japanese language capabilities, but the complete model is expected to be ready early next year.Training time is often a significant challenge in pretraining LLMs, where vast datasets are required.Therefore, efficient training frameworks like Megatron-LM are crucial for accelerating Generative AI research and development. For the 172B model trained with Megatron-LM, we explored FP8-hybrid training as a potential method for improving training speed, achieving a 1.4x training speed acceleration from 400 TFLOP/s to 550 TFLOP/s. We observed a performance acceleration from 400 TFLOP/s to 550 TFLOP/s, suggesting that FP8-hybrid could be a valuable approach for enhancing the efficiency of large-scale model pretraining.
