Edge computing takes place close to the data source to reduce network stress and improve latency. GPUs are an ideal compute engine for edge computing because they are programmable and deliver phenomenal performance per dollar. However, the complexity associated with managing a fleet of edge devices can erode the GPU’s favorable economics.
In 2019, NVIDIA introduced the GPU Operator to simplify scale-out GPU deployment and management on the EGX stack. From that time, NVIDIA customers have successfully applied GPUs to a wide range of edge AI use cases, and the GPU Operator was featured in reference architectures published by HPE and Dell.
Compute performance is only half of the equation. The availability of cheap sensors continues to push data processing demands at the edge. It is not unusual for a single GPU to ingest continuous data streams from dozens of sensors simultaneously. This makes network performance a critical design consideration.
GPUDirect RDMA is a technology that creates a fast data path between NVIDIA GPUs and RDMA-capable network interfaces. It can deliver line-rate throughput and low latency for network-bound GPU workloads. GPUDirect RDMA technology is featured in NVIDIA ConnectX SmartNICs and BlueField DPUs and plays a key role in realizing the benefits of GPUs at the edge.
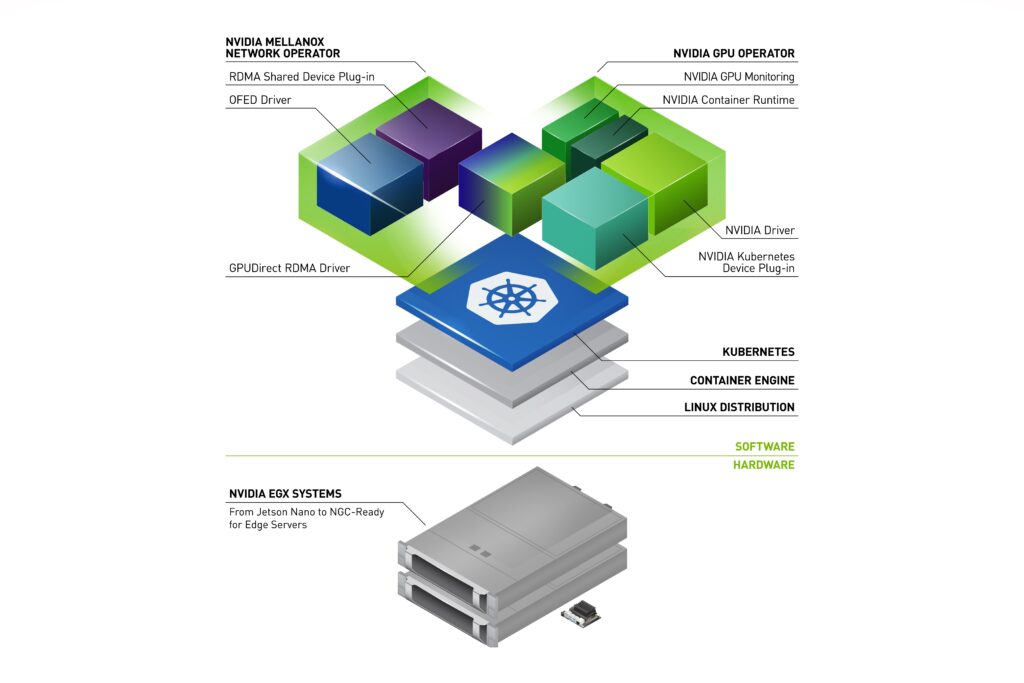
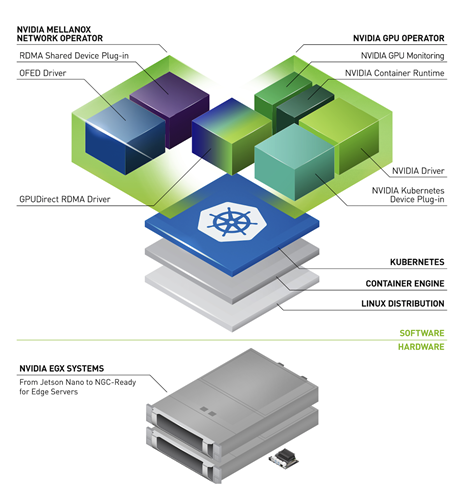
This post introduces the NVIDIA Network Operator. An analogue to the NVIDIA GPU Operator, the Network Operator simplifies scale-out network design for Kubernetes by automating aspects of network deployment and configuration that would otherwise require manual work. It loads the required drivers, libraries, and device plugins on any cluster node with a ConnectX network interface. When installed alongside the GPU Operator, it enables GPUDirect RDMA. In this post, we describe the Network Operator architecture and demonstrate testing GPUDirect RDMA in Kubernetes.
NVIDIA Network Operator architecture
The NVIDIA Network Operator leverages Kubernetes custom resources and the Operator framework to configure fast networking, RDMA, and GPUDirect. The Network Operator’s goal is to install the host networking components required to enable RDMA and GPUDirect in a Kubernetes cluster. It does so by configuring a high-speed data path for IO intensive workloads on a secondary network in each cluster node.
The NVIDIA Network Operator was released as an open source project on GitHub under the Apache 2.0 license. The operator is currently in alpha state. NVIDIA does not support the network operator for production workloads.
The Network Operator includes the following components:
- MOFED driver
- Kubernetes RDMA shared device plugin
- NVIDIA peer memory driver
MOFED driver
The Mellanox OpenFabrics Enterprise Distribution (MOFED) is a set of networking libraries and drivers packaged and tested by NVIDIA networking team. MOFED supports Remote Direct Memory Access (RDMA) over both Infiniband and Ethernet interconnects. The Network Operator deploys a precompiled MOFED driver container onto each Kubernetes host using node labels. The container loads and unloads the MOFED drivers when it is started or stopped.
Kubernetes RDMA shared device plugin
The device plugin framework advertises system hardware resources to the Kubelet agent running on a Kubernetes node. The Network Operator deploys a device plugin that advertises RDMA resources to Kubelet and exposes RDMA devices to Pods running on the node. It allows the Pods to perform RDMA operations. All Pods running on the node share access to the same RDMA device files.
NVIDIA peer memory driver
The NVIDIA peer memory driver is a client that interacts with the network drivers to provide RDMA between GPUs and host memory. The Network Operator installs the NVIDIA peer memory driver on nodes that have both a ConnectX network controller and an NVIDIA GPU. This driver is also loaded and unloaded automatically when the container is started and stopped.
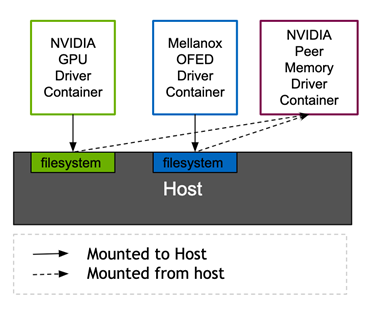
The NVIDIA peer memory driver requires headers from both the MOFED and NVIDIA drivers to link against the running kernel. Both the Mellanox network driver container and the NVIDIA driver container in the GPU operator expose the required header files through Kubernetes volume mounts to the host filesystem. Currently, the NVIDIA peer memory driver is delivered through the Network Operator. In the future, the NVIDIA GPU Operator will deliver it. This architecture allows ConnectX network controllers to DMA to non-NVIDIA clients in a standard way.
Kubernetes DaemonSets ensure that each node runs the appropriate driver containers. The containers are scheduled to nodes based on the node labels and the Pod node selectors in each Pod specification.
| Pod | nodeSelector |
| rdma-device-plugin | pci-15b3.present |
| ofed-driver | pci-15b3.present, kernel-version.full |
| nv-peer-mem-driver | pci-15b3.present, pci-10de.present |
The pci-*.present node selectors inform the Kubernetes schedulers that the Pods are required to be scheduled on nodes containing a PCI device with the corresponding vendor PCI ID. 15b3 is the PCI vendor ID for Mellanox and 10de is the vendor ID for NVIDIA. The MOFED driver DaemonSet and RDMA device plugin DaemonSet are scheduled to nodes with Mellanox devices. The nv-peer-mem-driver DaemonSet is scheduled to nodes with both Mellanox and NVIDIA devices.
The node labels can either be added by hand or set automatically by node feature discovery. Version 0.6.0 or higher of node-feature-discovery is required to discover ConnectX devices and enable RDMA feature support.
Deploy the Network Operator
In this section, we describe how to deploy the Network Operator and test GPUDirect RDMA. First, prepare the environment by validating the host and GPU configuration. Next, install the network operator and configure the secondary network interface. After you apply the Kubernetes custom resource that creates the driver containers, you can launch test Pods that run a network performance benchmark to validate GPUDirect RDMA.
Prepare the environment
Check the operating system and kernel version on the Kubernetes nodes. You must have Ubuntu 18.04 with the 4.15.0-109-generic kernel.
$ kubectl get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME ubuntu Ready master 52d v1.17.5 10.136.5.105 <none> Ubuntu 18.04.4 LTS 4.15.0-109-generic docker://19.3.5 ubuntu00 Ready <none> 48d v1.17.5 10.136.5.14 <none> Ubuntu 18.04.5 LTS 4.15.0-109-generic docker://19.3.12
Verify that the ConnectX network card and NVIDIA GPU are recognized by the operating system kernel. In this example output, the system has four NVIDIA GPUs and a dual-port “Mellanox Technologies” HCA.
$ lspci | egrep 'Mell|NV' 12:00.0 3D controller: NVIDIA Corporation Device 1eb8 (rev a1) 37:00.0 Ethernet controller: Mellanox Technologies MT27800 Family [ConnectX-5] 37:00.1 Ethernet controller: Mellanox Technologies MT27800 Family [ConnectX-5] 86:00.0 3D controller: NVIDIA Corporation Device 1eb8 (rev a1) af:00.0 3D controller: NVIDIA Corporation Device 1eb8 (rev a1) d8:00.0 3D controller: NVIDIA Corporation Device 1eb8 (rev a1)
Verify that the nodes are labeled with the PCI vendor IDs for Mellanox and NVIDIA:
$ kubectl describe nodes | egrep 'hostname|10de|15b3' feature.node.kubernetes.io/pci-10de.present=true feature.node.kubernetes.io/pci-15b3.present=true kubernetes.io/hostname=ubuntu feature.node.kubernetes.io/pci-10de.present=true feature.node.kubernetes.io/pci-15b3.present=true kubernetes.io/hostname=ubuntu00
If the Node Feature Discovery operator is not in use, manually label the nodes with the required PCI vendor IDs:
$ kubectl label nodes ubuntu feature.node.kubernetes.io/pci-15b3.present=true node/ubuntu labeled $ kubectl label nodes ubuntu00 feature.node.kubernetes.io/pci-15b3.present=true node/ubuntu00 labeled
Verify that the GPU operator is installed and running:
$ helm ls -a NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION gpu-operator-1595438607 gpu-operator 1 2020-07-22 10:23:30.445666838 -0700 PDT deployed gpu-operator-1.1.7 1.1.7 $ kubectl get ds -n gpu-operator-resources NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE nvidia-container-toolkit-daemonset 2 2 2 2 2 feature.node.kubernetes.io/pci-10de.present=true 32d nvidia-dcgm-exporter 2 2 2 2 2 feature.node.kubernetes.io/pci-10de.present=true 32d nvidia-device-plugin-daemonset 2 2 2 2 2 feature.node.kubernetes.io/pci-10de.present=true 32d nvidia-driver-daemonset 2 2 2 2 2 feature.node.kubernetes.io/pci-10de.present=true 32d
Install the network operator
Clone the network-operator git branch tagged v0.1.0:
$ git clone --branch v0.1.0 --single-branch git@github.com:Mellanox/network-operator.git Cloning into 'network-operator'... remote: Enumerating objects: 1, done. remote: Counting objects: 100% (1/1), done. remote: Total 729 (delta 0), reused 0 (delta 0), pack-reused 728 Receiving objects: 100% (729/729), 195.29 KiB | 1.70 MiB/s, done. Resolving deltas: 100% (405/405), done. Note: checking out '09088d76ef29e5208673e3d1ec90c787754c1bee'.
Deploy the network operator with the deploy-operator.sh script.
$ cd ~/network-operator/example ~/network-operator/example$ sudo ./deploy-operator.sh Deploying Network Operator: ########################### namespace/mlnx-network-operator created customresourcedefinition.apiextensions.k8s.io/nicclusterpolicies.mellanox.com created role.rbac.authorization.k8s.io/network-operator created clusterrole.rbac.authorization.k8s.io/network-operator created serviceaccount/network-operator created rolebinding.rbac.authorization.k8s.io/network-operator created clusterrolebinding.rbac.authorization.k8s.io/network-operator created deployment.apps/network-operator created
View the resources created by the installer script.
$ kubectl get all -n mlnx-network-operator NAME READY STATUS RESTARTS AGE pod/network-operator-7b6846c69f-skms6 1/1 Running 0 14m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/network-operator 1/1 1 1 14m NAME DESIRED CURRENT READY AGE replicaset.apps/network-operator-7b6846c69f 1 1 1 14m
Configure the secondary network
As mentioned earlier, the network operator deploys and configures MOFED drivers and an RDMA shared device plugin. It also installs GPUDirect RDMA drivers on nodes with an NVIDIA GPU. Additional configuration is required before RDMA workloads can run on the Kubernetes cluster:
- Configuring persistent and predictable network device names.
- Initializing network devices.
- Deploying a secondary Kubernetes macvlan network on the RDMA network device.
- Configuring IP address management (IPAM) for the secondary network.
- Defining workloads to request the RDMA device and its corresponding secondary network and GPU if needed.
This environment-specific configuration is not included in the automation.
Edit the RDMA network custom resource definition to configure the IP address range and MACVLAN network device name. In this example, the secondary network interface is device ens2f0.
~/network-operator/example$ egrep 'range|master|mtu' networking/rdma-net-cr-whereabouts-ipam.yml # Configuration below assumes 'ens2f0' as master device for macvlan CNI, "range": "192.168.111.0/24", "master": "ens2f0", "mtu": 9000
Run the deploy-rdma-net-ipam.sh script. This script configures the secondary network and manages IP address assignment.
~/network-operator/example$ sudo ./deploy-rdma-net-ipam.sh Deploying Secondary Network with Whereabouts IPAM: "rdma-net-ipam" with RDMA resource : "rdma/hca_shared_devices_a" ####################################################################################################################### customresourcedefinition.apiextensions.k8s.io/network-attachment-definitions.k8s.cni.cncf.io created clusterrole.rbac.authorization.k8s.io/multus created clusterrolebinding.rbac.authorization.k8s.io/multus created serviceaccount/multus created configmap/multus-cni-config created daemonset.apps/kube-multus-ds-amd64 created daemonset.apps/kube-multus-ds-ppc64le created customresourcedefinition.apiextensions.k8s.io/ippools.whereabouts.cni.cncf.io created serviceaccount/whereabouts created clusterrolebinding.rbac.authorization.k8s.io/whereabouts created clusterrole.rbac.authorization.k8s.io/whereabouts-cni created daemonset.apps/whereabouts created networkattachmentdefinition.k8s.cni.cncf.io/rdma-net-ipam created
Set the devicePlugin.config field in the custom resource to match the RDMA netdevice name. In this example, it is ens2f0.
~/network-operator/example$ grep devices \ deploy/crds/mellanox.com_v1alpha1_nicclusterpolicy_cr.yaml # Replace 'devices' with your (RDMA-capable) netdevice name. "resourceName": "hca_shared_devices_a", "devices": ["ens2f0"]
Apply the NIC cluster policy custom resource definition to specify the driver container versions.
~/network-operator/example$ kubectl create -f deploy/crds/mellanox.com_v1alpha1_nicclusterpolicy_cr.yaml nicclusterpolicy.mellanox.com/example-nicclusterpolicy created
Verify that the driver containers are deployed successfully.
$ kubectl get pods -n mlnx-network-operator NAME READY STATUS RESTARTS AGE network-operator-7b6846c69f-tccv8 1/1 Running 2 51m nv-peer-mem-driver-amd64-ubuntu18.04-ds-2qrjh 1/1 Running 16 33m nv-peer-mem-driver-amd64-ubuntu18.04-ds-5k5wb 1/1 Running 0 33m ofed-driver-amd64-ubuntu18.04-kver4.15.0-109-generic-ds-2knvc 1/1 Running 0 75s ofed-driver-amd64-ubuntu18.04-kver4.15.0-109-generic-ds-c9xz9 1/1 Running 0 33m rdma-shared-dp-ds-4cgr2 1/1 Running 0 33m rdma-shared-dp-ds-lqmk7 1/1 Running 2 33m
The OFED driver container is precompiled to support a specific MOFED version, operating system, and kernel version combination.
| Component | Version |
| OFED version | 5.0-2.1.8.0 |
| Operating system | ubuntu-18.04 |
| Kernel | 4.15.0-109-generic |
Validate that the NVIDIA peer memory drivers are installed on the nodes.
$ lsmod | grep nv_peer_mem nv_peer_mem 16384 0 ib_core 323584 11 rdma_cm,ib_ipoib,mlx4_ib,nv_peer_mem,iw_cm,ib_umad,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm,ib_ucm nvidia 20385792 117 nvidia_uvm,nv_peer_mem,nvidia_modeset
The NIC cluster policy custom resource is the configuration interface for the network operator. The following code example shows the contents of the custom resource specification.
apiVersion: mellanox.com/v1alpha1
kind: NicClusterPolicy
metadata:
name: example-nicclusterpolicy
namespace: mlnx-network-operator
spec:
ofedDriver:
image: ofed-driver
repository: mellanox
version: 5.0-2.1.8.0
devicePlugin:
image: k8s-rdma-shared-dev-plugin
repository: mellanox
version: v1.0.0
config: |
{
"configList": [
{
"resourceName": "hca_shared_devices_a",
"rdmaHcaMax": 1000,
"devices": ["ens2f0"]
}
]
}
nvPeerDriver:
image: nv-peer-mem-driver
repository: mellanox
version: 1.0-9
gpuDriverSourcePath: /run/nvidia/driver
This file defines the OFED driver, RDMA shared device plugin, and the NVIDIA peer memory client driver versions. It also defines the RDMA root device name and specifies the number of shared RDMA devices to create at install time.
Validate the installation
Create Pods to test shared RDMA on the secondary network.
~/network-operator/example$ kubectl create -f rdma-test-pod1.yml pod/rdma-test-pod-1 created ~/network-operator/example$ kubectl create -f rdma-test-pod2.yml pod/rdma-test-pod-2 created ~/network-operator/example$ kubectl get pods NAME READY STATUS RESTARTS AGE rdma-test-pod-1 1/1 Running 0 7s rdma-test-pod-2 1/1 Running 0 5s
Find the name of the active network device in the Pod.
~/network-operator/example$ kubectl exec -it -n mlnx-network-operator ofed-driver-amd64-ubuntu18.04-kver4.15.0-109-generic-ds-2knvc ibdev2netdev mlx5_0 port 1 ==> ens2f0 (Up) mlx5_1 port 1 ==> ens2f1 (Down) mlx5_2 port 1 ==> eno5 (Down) mlx5_3 port 1 ==> eno6 (Down)
Run the perftest server on Pod 1.
~/network-operator/example$ kubectl exec -it rdma-test-pod-1 -- bash [root@rdma-test-pod-1 /]# ib_write_bw -d mlx5_0 -a -F --report_gbits -q 1 ************************************ * Waiting for client to connect... * ************************************
In a separate terminal, print the network address of the secondary interface on Pod 1.
~/network-operator/example$ kubectl exec rdma-test-pod-1 -- ip addr show dev net1 5: net1@if24: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc noqueue state UP group default link/ether 62:51:fb:13:88:ce brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 192.168.111.1/24 brd 192.168.111.255 scope global net1 valid_lft forever preferred_lft forever
Start an interactive terminal on Pod 2 and print the interface on Pod 1.
~$ kubectl exec -it rdma-test-pod-2 -- bash [root@rdma-test-pod-2 /]# ping -c 3 192.168.111.1 PING 192.168.111.1 (192.168.111.1) 56(84) bytes of data. 64 bytes from 192.168.111.1: icmp_seq=1 ttl=64 time=0.293 ms 64 bytes from 192.168.111.1: icmp_seq=2 ttl=64 time=0.120 ms 64 bytes from 192.168.111.1: icmp_seq=3 ttl=64 time=0.125 ms --- 192.168.111.1 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2037ms rtt min/avg/max/mdev = 0.120/0.179/0.293/0.081 ms Run the perftest write benchmark. This test measures maximum RDMA network throughput between the Pods. [root@rdma-test-pod-2 /]# ib_write_bw -d mlx5_0 -a -F --report_gbits -q 1 192.168.111.1 --------------------------------------------------------------------------------------- RDMA_Write BW Test Dual-port : OFF Device : mlx5_0 Number of qps : 1 Transport type : IB Connection type : RC Using SRQ : OFF TX depth : 128 CQ Moderation : 100 Mtu : 4096[B] Link type : Ethernet GID index : 2 Max inline data : 0[B] rdma_cm QPs : ON Data ex. method : rdma_cm --------------------------------------------------------------------------------------- local address: LID 0000 QPN 0x01fd PSN 0x4ebaee GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:111:02 remote address: LID 0000 QPN 0x01f8 PSN 0xbe97c2 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:111:01 --------------------------------------------------------------------------------------- #bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps] 2 5000 0.083670 0.082376 5.148474 4 5000 0.17 0.17 5.229830 8 5000 0.34 0.33 5.229340 16 5000 0.68 0.67 5.213672 32 5000 1.35 1.34 5.248994 64 5000 2.70 2.68 5.228968 128 5000 5.41 5.40 5.275896 256 5000 10.80 10.73 5.239736 512 5000 21.42 21.30 5.200598 1024 5000 42.67 42.66 5.207166 2048 5000 76.99 76.27 4.655341 4096 5000 96.15 90.05 2.748027 8192 5000 97.64 97.29 1.484576 16384 5000 97.84 97.74 0.745729 32768 5000 97.82 97.76 0.372912 65536 5000 97.96 97.95 0.186826 131072 5000 97.94 97.57 0.093055 262144 5000 97.95 97.54 0.046513 524288 5000 97.95 97.65 0.023282 1048576 5000 98.02 98.01 0.011684 2097152 5000 98.03 98.03 0.005843 4194304 5000 97.38 97.27 0.002899 8388608 5000 98.02 97.64 0.001455 -------------------------------------------------------------------------------------
The benchmark achieved approximately 98 Gbps throughput, close to the maximum line rate of this 100 Gb controller.
Delete the rdma test Pods.
$ kubectl delete pod rdma-test-pod-1 pod "rdma-test-pod-1" deleted $ kubectl delete pod rdma-test-pod-2 pod "rdma-test-pod-2" deleted
Repeat the same test using the rdma-gpu-test podspecs. These Pods test the GPUdirect RDMA performance between the network card in one system and the GPU in the other.
~/network-operator/example$ kubectl create -f rdma-gpu-test-pod1.yml pod/rdma-gpu-test-pod-1 created ~/network-operator/example$ kubectl create -f rdma-gpu-test-pod2.yml pod/rdma-gpu-test-pod-2 created
Start an interactive terminal on one of the Pods.
$ kubectl exec -it rdma-gpu-test-pod-1 -- bash
Start the performance benchmark with the --use_cuda option.
rdma-gpu-test-pod-1:~# ib_write_bw -d mlx5_0 -a -F --report_gbits -q 1 --use_cuda=0 ------------------------------------------------------------------------------------- ************************************ * Waiting for client to connect... * ************************************
Connect to the second Pod and start the performance test.
$ kubectl exec -it rdma-gpu-test-pod-2 -- bash rdma-gpu-test-pod-2:~# ib_write_bw -d mlx5_0 -a -F --report_gbits -q 1 192.168.111.1 RDMA_Write BW Test Dual-port : OFF Device : mlx5_0 Number of qps : 1 Transport type : IB Connection type : RC Using SRQ : OFF PCIe relax order: Unsupported ibv_wr* API : OFF TX depth : 128 CQ Moderation : 100 Mtu : 4096[B] Link type : Ethernet GID index : 2 Max inline data : 0[B] rdma_cm QPs : OFF Data ex. method : Ethernet ------------------------------------------------------------------------------------- local address: LID 0000 QPN 0x020e PSN 0x29b8e1 RKey 0x014e8d VAddr 0x007f4a2f74b000 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:111:02 remote address: LID 0000 QPN 0x020d PSN 0x24bc9e RKey 0x012864 VAddr 0x007fca15800000 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:111:01 ------------------------------------------------------------------------------------- #bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps] 2 5000 0.076617 0.074692 4.668252 4 5000 0.16 0.15 4.781188 8 5000 0.31 0.31 4.838186 16 5000 0.62 0.62 4.812724 32 5000 1.25 1.23 4.817500 64 5000 2.49 2.42 4.724497 128 5000 4.99 4.93 4.816670 256 5000 9.99 9.85 4.811366 512 5000 19.97 19.56 4.776414 1024 5000 39.64 34.57 4.219684 2048 5000 75.75 73.78 4.503022 4096 5000 81.89 81.70 2.493145 8192 5000 80.60 80.58 1.229511 16384 5000 82.08 82.08 0.626200 32768 5000 82.11 82.11 0.313206 65536 5000 82.12 81.95 0.156307 131072 5000 82.13 82.12 0.078317 262144 5000 82.10 82.10 0.039147 524288 5000 82.12 82.10 0.019575 1048576 5000 82.12 82.11 0.009789 2097152 5000 82.11 82.06 0.004891 4194304 5000 82.12 82.06 0.002446 8388608 5000 82.12 82.07 0.001223 -------------------------------------------------------------------------------------
The RDMA sample Pods do not enforce NUMA alignment between the GPU, network controller, and the Pod CPU socket. Performance can vary across runs, depending on which resources are presented to the Pod.
Delete the RDMA GPU test Pods.
$ kubectl delete pod rdma-gpu-test-pod-1 pod "rdma-gpu-test-pod-1" deleted $ kubectl delete pod rdma-gpu-test-pod-2 pod "rdma-gpu-test-pod-2" deleted
Conclusion and next steps
The NVIDIA GPU Operator automates GPU deployment and management on Kubernetes. This post introduced the NVIDIA Network Operator: software that automates the deployment and configuration of the network stack on Kubernetes. When deployed together, they enable GPUDirect RDMA, a fast data path between NVIDIA GPUs and RDMA-capable network interfaces. This is a critical technology enabler for data-intensive edge workloads.
The Network Operator is still in early stages of development and is not yet supported by NVIDIA. Clone the network-operator GitHub repo and contribute code or raise issues. Directions for future work include improving NUMA alignment between the devices, expanding the device plugin to include SR-IOV, supporting additional operating systems, and configuring GPUDirect RDMA between multiple NIC/GPU pairs.
