
The complexity of wireless system design is continually growing. Communications engineering strives to further improve metrics like throughput and interference robustness while simultaneously scaling to support the explosion of low-cost wireless devices. These often-competing needs makes system complexity intractable. Furthermore, algorithmic and hardware components are designed separately, then optimized, and integrated to form complete systems. This approach makes globally optimizing the end-to-end communications link extremely difficult, if not impossible.

DeepSig overcomes this complexity barrier by designing neural networks that learn how to effectively communicate, even under harsh impairments. To accomplish this, we leverage our background in radio and signal processing, recent developments in deep learning, and technology from NVIDIA such as GPU hardware and software libraries optimized for machine learning.
Our work in learned communications demonstrates that machines easily match the performance of human-designed systems in simple scenarios, as shown in Figure 1. In more complex scenarios, a deep learning-based system can dramatically outperform existing approaches by learning a physical layer (PHY) inherently optimized for the radio hardware and channel.
Learning from complexity
Communications systems suffer from a wide variety of impairments. For example, hardware introduces intermodulation and amplifier distortion, quadrature imbalance, local oscillator and clock harmonic leakage, and quantization loss. The channel introduces fading, multipath, interference, propagation loss, and reflections.
Performing end-to-end optimization means jointly optimizing the full chain of physical layer signal processing from the transmit bits to the decoded received bits. Optimizing RF systems with this level with complexity has never quite been practical. Instead, designers rely on simplified closed-form models that don’t accurately or holistically capture the effects of real-world systems and channels.
The degrees of freedom required to operate next-generation communications systems also continues to increase. The number of radio and modulation parameters, such as antennas, channels, bands, beams, codes, and bandwidths, represent degrees of freedom that must be controlled by the radio system. Individual communications standards now use many more of these—in part, as an effort to mitigate the growing number of impairments.
The combination of these impairments and degrees of freedom within modern communications makes the larger system exceedingly difficult to optimize. When building networks that need to scale to many users it’s simply not possible to perform end-to-end optimization in practice. To date, the effect of this complexity barrier has just been sub-optimal performance and power consumption, increasing cost, Size-Weight-and-Power (SWaP), and heat dissipation.
As future communication standards efforts work to scale to many more devices operating in congested environments while increasing data rates and reducing latency, this complexity is a significant barrier to even the feasibility of system design.
The latest advances in machine learning provide a path forward. By using deep learning approaches with NVIDIA hardware to train on raw time-series measurements sampled directly from the channel, it’s now possible to learn the best way to communicate over combinations of hardware and channel effects. This enables optimizing for high-level system objectives such as bit error rate (BER) or power consumption. Previous methodologies simply could not contend with the extreme complexity described earlier, making truly optimal solutions impossible.
Advances made by NVIDIA in hardware architectures optimized for deep learning and tensor processing, combined with the NVIDIA cuDNN library of optimized primitives for deep neural networks, represents a new class of processing that is enabling technology breakthroughs. These advances make it possible to finally design robust and highly optimal communications systems.
DeepSig’s approach optimizes end-to-end
To accomplish this, we cast the “fundamental problem of communications” as an end-to-end machine learning optimization problem which seeks to reconstruct a random input message transmitted and received over a channel. For more information, see A Mathematical Theory of Communication.
This task of input reconstruction within a neural network is known as an autoencoder. Autoencoders traditionally seek to perform reconstruction through some compact, lower-dimension representation. Its application in modeling communications systems, where a lossy stochastic channel model is traversed in the hidden layer, is known as a channel autoencoder. For more information, see Learning to Communicate: Channel Auto-encoders, Domain Specific Regularizers, and Attention.
In its simplest form, the channel autoencoder considers everything between the codecs (that is, ADCs and DACs) part of the channel. This includes attributes such as amplifier impairments and interference, mitigating these effects by learning a representation that minimizes a selected global loss function. Constructing a channel autoencoder involves inserting a channel model representative of the system impairments into the hidden layer of a traditional autoencoder or variational autoencoder, then choose a set of bits or codewords (s) which represents the data to be sent and then reconstructed (Figure 2).
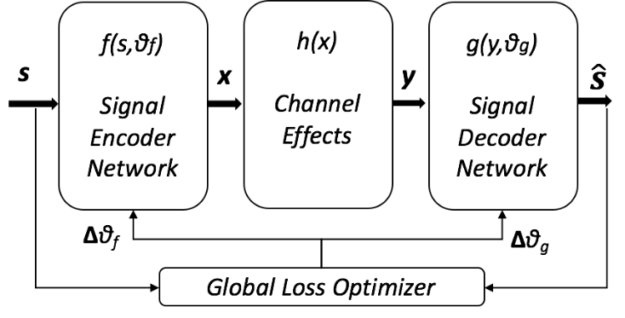
The structure in Figure 2 forces the network to learn a representation (x) on some basis function (for example, quadrature samples, OFDM carriers) optimized for estimating the decoded values ( ) from a received form (y) on the other end of the channel.
) from a received form (y) on the other end of the channel.
A key difference from traditional autoencoder usage is that we may not care about compressing (s) to a lower dimensionality to form (x). Instead, we simply seek a representation suitable for RF communication that is resilient to the channel’s effects. Using this design enables us to jointly optimize both sides of the link, in an end-to-end manner, over the real-world effects that impact the communications system.
Figure 3 presents a basic example of training a learned physical layer, where a channel autoencoder learns how to optimize BER for two bits of information over a simple additive white Gaussian noise (AWGN) effect.
Figure 3 shows an accelerated visualization of training a channel autoencoder, simple enough in design that it can be trained in just a few seconds on a single NVIDIA GTX 1080 GPU. The left image shows the transmitted symbol constellation produced by the encoder network. The middle graphic highlights the received constellation seen by the decoder network and the rightmost chart is the end-to-end global loss calculated over the entire system. The final learned constellation is clearly recognizable as a QAM4 (that is, QPSK) modulation scheme, but optimized for the channel model used to learn the physical layer encoder and decoder.
DeepSig enables new classes of physical layer modems
This end-to-end optimization provided by channel autoencoders enables entirely new classes of PHY-layer design. The example in Figure 3 shows a fairly simple system, but the same principles are applicable in far more complex environments.
As an example, some existing systems operate high-power amplifiers in compression to maximize SNR and power efficiency. However, this also forces the use of lower-order or constant modulus constellations to cope with the severe non-linear distortion caused by the amplifier. This is the case with NASA’s Tracking and Data Relay Satellite (TDRS) System, which uses Traveling Wave Tube Amplifiers (TWTAs) for space-based relay communications.
Working with NASA, DeepSig applied its work in channel autoencoders to the TDRS communications system. Following the high-level model shown in Figure 2, DeepSig designed a deep neural network (DNN) channel autoencoder using the structure shown in Figure 4. The channel model within the structure contains layers typical to communications system modeling, such as amplitude and phase noise, as well as a Distortion Model layer that captures the non-linear effects caused by the TWTAs. The Encoder and Decoder networks, mapping to the same in Figure 2, learn what constitutes a physical layer modem (that is, a modulator-demodulator pair).
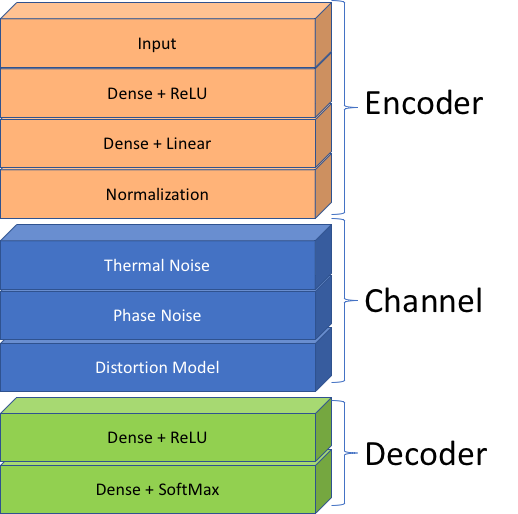
Using the channel autoencoder structure in Figure 4, DeepSig trained a novel physical layer optimized for TDRSS, inclusive of channel and hardware impairments. Figure 5 offers an accelerated visualization of the channel autoencoder in Figure 4 learning how to communicate over the TDRSS physical layer.
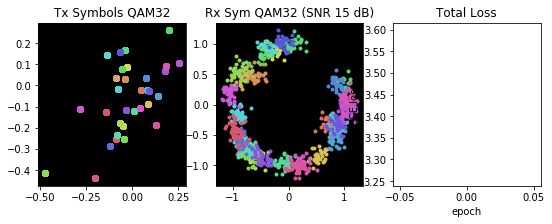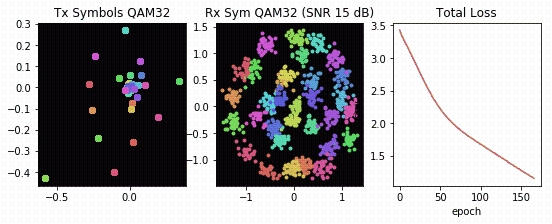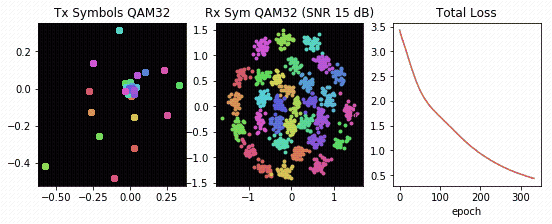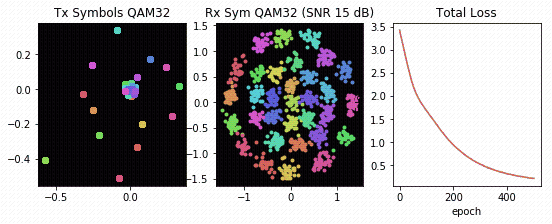
You can once again see the learned transmit constellation on the left, the received constellation in the middle, and the global reconstruction loss function on the right. The resulting encoder network is especially interesting in that it learns a novel transmit waveform optimized for the non-linear compression caused by the amplifiers, yielding a separable 32-symbol QAM-like constellation at the receiver.
Using traditional approaches to communications design, which typically segregate the various aspects of the physical layer for design purposes, humans have struggled to create a PHY that can cope with the severe impairments of the TDRS system. The channel autoencoder, however, is able to learn a representation that is both well-suited to the effects of the channel and outperforms known constellations (for example, rectangular 32-QAM, 32-PSK, 32-APSK).
When using an NVIDIA Titan V-class GPU, a channel autoencoder like the one shown in Figure 4 can be trained on the order of minutes, making it possible to quickly experiment and iterate on architecture designs. This ability to quickly learn new modems, optimized for extremely complex channels, makes entirely new classes of physical layers possible.
The future of communications
Existing approaches for digital communications and signal processing have revolutionized the world over the last century. Mdern communications design poses different challenges than those from even two decades ago. Many commercial systems (for example, cellular) are now primarily interference-limited. Further scaling them to support more devices, more throughput, and lower latency (which are some of the primary goals of 5G) with traditional approaches creates a significant challenge. As existing technology starts to show its limits, deep learning provides new solutions. For more information, see Machine Learning Modems: How ML Will Change How We Specify and Design Next-Generation Communication Systems.
Furthermore, the channel autoencoder approach outlined in this post makes entirely new types of physical layers feasible, such as modems optimized for non-linear channel effects and specific hardware devices, and PHYs that can provide an unprecedented degree of adaptivity using online updates.
Using NVIDIA GPUs accelerates the actual training of the channel autoencoders to speeds comparable to compiling programs for desktop processors – minutes, and sometimes even seconds. Once the model has been trained, it can then be deployed into low-power embedded systems, such as those based on the NVIDIA Jetson TX2 or Xavier. This creates a design flow whereby communications engineers can easily build optimized physical layers and then deploy them to embedded devices at the edge.
Building on our seminal research into deep learning applied to communications, DeepSig has created the first commercial software products that provide learned communications capabilities. OmniPHY enables learned physical layers for communications, using techniques such as the channel autoencoder presented in this post. OmniSIG , based on foundational work done by DeepSig principals, provides a deep learning-based RF-sensing capability for wideband low-latency signal detection, classification, and spectrum monitoring. For more information, see Deep Architectures for Modulation Recognition.
Machine learning methods alone are unlikely to fundamentally replace traditional communications and signal processing systems in the near future, as today’s domain-specific techniques and knowledge are powerful and effective in many cases.
However, work done to-date by DeepSig and others has clearly demonstrated that combining novel machine learning-based approaches with modern radio algorithms substantial potential exists to improve the performance of current systems and address the complexity problems of future communications systems. Based on our success in applying deep learning and AI to the field of telecommunications thus far, we believe that the GPUs and developer support provided by NVIDIA constitute an AI platform that enable driving considerable innovation and disruption in telecom and signal processing.
We remain excited and eager to see what new capabilities become possible as we continue to explore and develop this deep learning-based technology. To learn more, follow our work on the DeepSig website, or reach out to us directly.