
Despite substantial progress in natural language processing (NLP) research over the last two years and its commercial success, little effort has been devoted to adapting this capability to other significant languages, such as Hindi, Arabic, Portuguese, or Spanish. Obviously, catering to the entire human population with more than 6,500 languages is challenging. At the same time, supporting just 40 languages addresses the NLP needs of more than 60% of the human population.
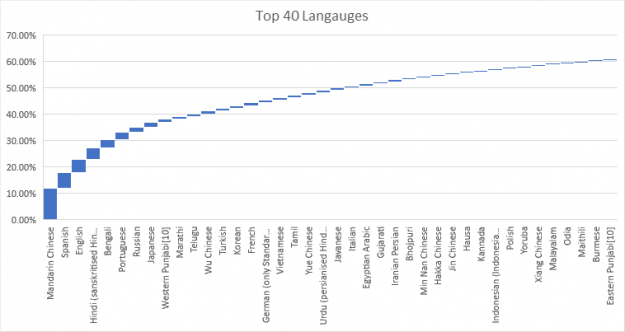
Figure 2 shows that, even across the most frequently used languages, the performance of language models varies tremendously. Bear in mind that this comparison is not perfect, as those languages do have different language entropy. More importantly, the research on most capable large-scale language models seems to be limited to only a handful of high resource languages (languages with a high number of documents available publicly), such as English or Chinese.
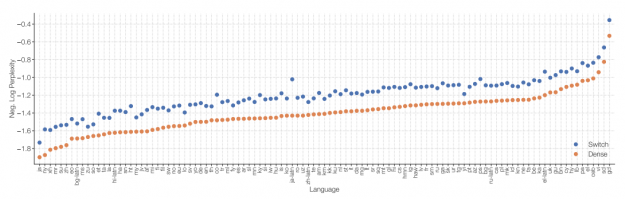
The situation is even more complex when you account for domain-specific languages (such as medical, technical, or legal jargon), where besides English only a few high-quality models exist. This is regretful as those domain-specific language models are currently transforming the way that clinicians, engineers, researchers or other experts access information.
- Models such as GatorTron are changing the way that clinicians access medical notes.
- Models such as bioMegatron change the way that medical researchers identify drug or chemical interactions affecting the human body.
- Models such as sciBERT change the way that engineers find and interact with scientific information.
Unfortunately, there is a limited number of equivalent models outside of English. Fortunately, replicating the success of English-language models across other languages is no longer a research task but predominantly an engineering activity. It no longer requires inventing new models and training approaches, but instead systematic and iterative dataset engineering, model training, and its continuous validation.
This does not mean that engineering those models is trivial. Because of the model and dataset sizes used in modern NLP, the training process requires a substantial amount of computing power. Secondly, to use large models, you must collect large textual datasets. Thirdly, because of the shared size of models used, new approaches to training and inference are required.
NVIDIA has extensive experience not only in building large-scale language models (ranging from 1 billion to 175 billion parameters) but also in deploying them to production. The goal of this post is to share our knowledge around project organization, infrastructure requirements, and budgeting and to support projects in this area.
Dawn of large models
As hypothesized in Deep Learning Scaling is Predictable, Empirically, the NLP model performance seems to follow a power law with respect to both the model size and the volume of data used for training. As you make models and datasets bigger, the performance continues to improve. The following diagram from Scaling Laws for Neural Language Models demonstrates not only that this relationship holds but more importantly, it holds across nine orders of magnitude of compute.
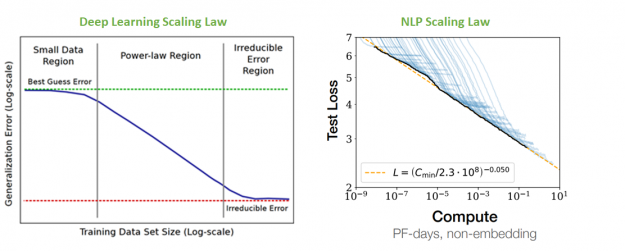
In the NLP scaling law, despite the models at the far right reaching as much as 175 billion parameters (more than 500 times larger than BERT Large), this relationship does not show signs of stopping. This suggests that even further improvement can be expected from larger models. Indeed, switch transformers when scaled to 1.6 trillion parameters (roughly 5000x larger than BERT Large) continue to demonstrate the previously mentioned behavior.
More importantly, the large NLP models seem to generate much more robust features capable of solving complex problems even without large-scale fine-tuning datasets. Figure 4 shows this capability across three orders of magnitude of models.
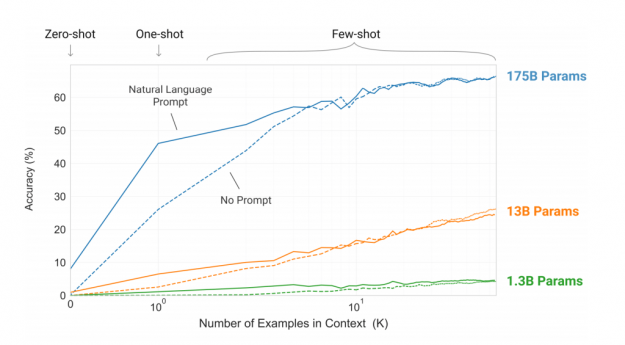
Due to this capability, and despite the relatively high cost of their development, large NLP models are likely to not only continue to dominate the NLP processing landscape but also continue to grow, at least by another order of magnitude approaching trillions of parameters.
This relationship between model size, dataset size, and model performance is not unique to NLP. I see the same behavior of automatic speech recognition and computer vision models, and across many other disciplines that are a backbone of conversational AI.
At the same time, a limited amount of work was devoted to the development of both large-scale datasets and models for other languages. Indeed, the majority of the work that focuses on languages other than English take advantage of smaller models and less curated datasets. For example, NLP using subset from general datasets such as raw Common Crawl).
Even less effort is devoted to supporting any of the following:
- More localized models, such as Arabic dialects and variants or Mandarin subgroups and dialects.
- Domain-specific models such as used those for clinical note taking, scientific publications, financial report analysis, interpretation of engineering documents, parsing through legal texts, or even variants of language used on platforms such as Twitter.
The current status creates an opportunity for local companies willing to invest in model training to lead the development of NLP technologies in the region.
Building your local language model
Building large-scale language models is not trivial for many reasons. First, the large-scale datasets are not trivial to curate. In the raw format, they are actually quite easy to obtain. Second, the infrastructure required to train these huge models requires substantial systems knowledge to set up. Finally, they require extensive research expertise to train and optimize.
What is less widely understood is that training such large models requires software engineering effort. Most interesting models are larger than the memory capacity of not only individual GPUs but also of many multi-GPU servers. The number of mathematical operations required to train them can also make training times unmanageable, measured in months even on fairly sizable systems. Approaches such as model and pipeline parallelism overcome some of those challenges. However, applying them in a naive way could lead to scaling issues, exacerbating an already long training time.
Together with organizations such as Microsoft and Stanford University, NVIDIA has worked towards developing tools that streamline the development process of the largest language models and provide computational efficiency and scalability to allow cost-effective training. As a consequence, a wide range of tools abstracting the complexity of large model development are now available, including the following:
- NVIDIA Megatron LM—A computationally efficient model and pipeline parallel implementation of self-attention and multilayer perceptron together with implementations of models such as GPT-3, T5, or even Vision Transformers. In particular, the GPT-3 code was tested with up to 1 trillion parameters. For more information, see Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism and Efficient Large-Scale Language Model Training on GPU Clusters.
- Microsoft DeepSpeed—A library that not only supports Megatron LM as a foundation for model and pipeline parallelism but also further optimizes the implementation with Zero Redundancy Optimizer (ZeRO), 1-bit Adam and LAMB, or sparse attention.
- Facebook FairScale—A library that addresses large-scale training through the implementation of model parallel training (based on NVIDIA Megatron LM), sharded training, or an AdaScale optimizer.
As a result of those efforts, I’ve seen a substantial reduction in training times of large models. Indeed, the GPT-3 model with 175 billion parameters trained on 300 billion tokens using 1024 NVIDIA A100 Tensor Core GPUs can be trained today in 34 days (as shown in Efficient Large-Scale Language Model Training on GPU Clusters). Based on experimentation, NVIDIA estimates that 1 trillion parameter models can be trained in approximately 84 days with 3072 A100 GPUs. Despite the training cost of those models being high, it is not beyond reach of most large organizations. With further software advances, it is likely to reduce further.
Because the development of large language models requires scalable infrastructure, NVIDIA has also consolidated knowledge from building the internal Selene cluster (used for NLP internal research and to deliver record-breaking performance in MLPerf training and inference benchmarks) into a fully packaged product called NVIDIA DGX SuperPOD. This cluster is more than just a system reference design. In fact, it can be bought in its entirety together with software and support of NVIDIA data scientists and applied researchers, similar to the NLP-focused deployment by Naver Clova).
Such an approach has already had a substantial impact on the NLP landscape, as it enables organizations with extensive NLP expertise to scale out their efforts fast. More importantly, it enables organizations with limited systems, HPC, or large-scale NLP workload expertise to start iterating in weeks, rather than months or years.

Production deployment
The ability to build large language models is just an academic achievement when it’s impossible to take advantage of the results of your work by deploying your models to production. The challenge of deploying models such as GPT-3 correlates to their sheer size, which exceeds the memory capacity of a GPU, and computational complexity. Both are factors that contribute to decreased throughput and high latency of inference. This is a widely understood problem and a range of tools and solutions currently exist to make serving the largest language models simple and cost-effective.
- NVIDIA Triton Inference Server
- NVIDIA TensorRT and other model optimization techniques
NVIDIA Triton Inference Server
NVIDIA Triton Inference Server is an open-source cloud and edge inferencing solution optimized for both CPUs and GPUs. It can be used to host distributed models effectively. To deploy a large model using pipeline parallelism, the model must be split into several parts, for example, manipulating the ONNX graph with tools such as ONNX Graph Surgeon. Each of the parts must be small enough to fit into the memory space of a single GPU.
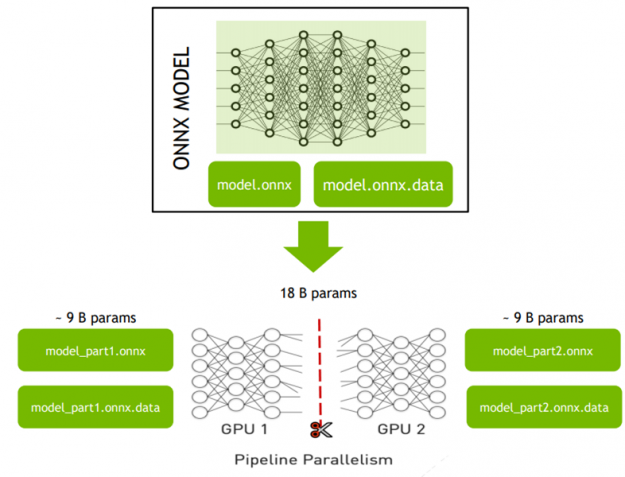
After the model is subdivided, it can be distributed across multiple GPUs without the need to develop any code. You create an NVIDIA Triton YAML configuration file defining how individual parts of the model should be connected.
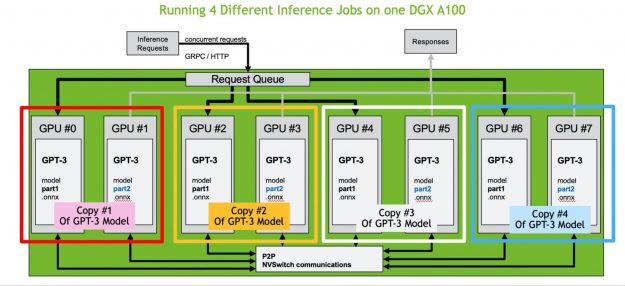
The traffic between individual model parts and their load balancing can be managed automatically by Triton Inference Server. The communication overheads are also kept to a minimum as Triton takes advantage of the latest NVIDIA NVSwitch and third-generation NVIDIA NVLink technology, providing 600 GB/sec GPU-to-GPU direct bandwidth, which is 10X higher than PCIe gen4. This means that you can efficiently deploy not only medium-scale models of multi billions of parameters but even the largest of models, including GPT-3 with trillions of parameters.
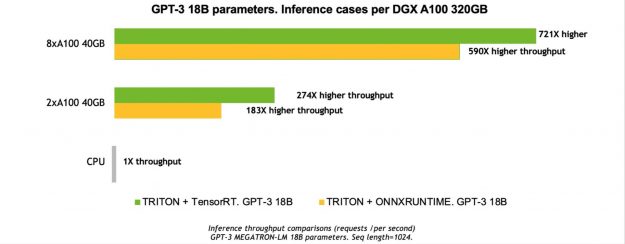
For more information, see Megatron GPT-3 Large Model Inference with Triton and ONNX Runtime (GTC21 session).
NVIDIA TensorRT and other model optimization techniques
Beyond the ability to host trained large models, it is important to look at optimization techniques. Such techniques can reduce the memory footprint of the models, through quantization and pruning; substantially accelerate the execution; and reduce latency by optimizing memory access, taking advantage of TensorCores or sparsity acceleration.
Utilities such as TensorRT provide a wide range of optimized kernels for execution of transformer-based architectures. They can automatically do half precision (FP16) or, in certain cases, INT8 quantization. TensorRT also supports quantization-aware training and provides early support for hardware-accelerated sparsity.
The NVIDIA FasterTransformer library specializes in the inference of the transformer neural networks and can be used with models such as BERT or GPT-2/3. This library includes a tensor-parallel inference backend that provides the ability to do the inference of the huge GPT-3 models in parallel on multiple GPUs within the DGX A100 system. This enables you to reduce inference latency by as much as 1.2–3x, depending on model size. With FasterTransformer, you can deploy the largest of Megatron Models with a single line of code.
The Microsoft DeepSpeed library has a number of features focused on inference, including support for Mixture-of-Quantization (MoQ), high-performance INT8 kernels, or DeepFusion.
Thanks to all of those advances, large language models are no longer limited to academic research as they are making headway into commercial AI-based products.
Sizing the challenge
Correct sizing of the challenge is critical for the success of your NLP initiative. The amount of engineering and research staff needed as well as training and inference infrastructure significantly affects your business case. The following factors have significant impact on the overall cost of the development:
- Number of supported languages and dialects
- Number of applications being developed (named entity recognition, translation, and so on)
- Development schedule (to train faster, you need more compute)
- Requirements towards model accuracy (driven by dataset size and model size)
After the fundamental business questions are addressed, it is possible to estimate the effort and compute required for their development. When you have an understanding of how good your model must be to allow for the product or service, it is possible to estimate the model size needed. The relationship between the performance of language models and the amount of data and model size is widely understood (Figure 9).
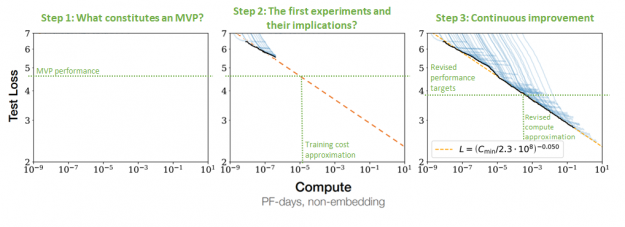
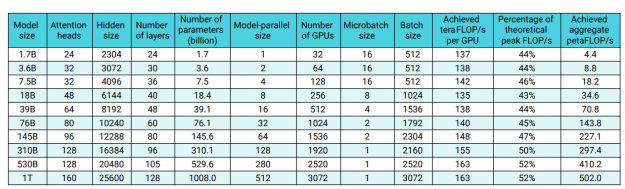
After you understand the size of the model and dataset that you need, you can estimate the amount of infrastructure required and training time. For more information, see Efficient Large-Scale Language Model Training on GPU Clusters. Furthermore, the scaling of large language models is superlinear, meaning that the training performance does not degrade with the increasing model size but actually increases (Figure 10).
Here are the key factors to consider for initial infrastructure sizing:
- Number of supported languages, dialects, and domain-specific variants
- Number of applications per language
- Project timelines
- Performance metrics and targets that must be achieved by models to create minimal viable products
- Number of data scientists, researchers, and engineers actively involved in training per application or language
- Minimal turnaround time and training frequencies, both for pretraining and fine-tuning
- Rough understanding of inference demand of the application, the average or maximal number of requests per day or hour and its seasonality
- Training pipeline performance, or how long a single training cycle takes and how far from theoretical maximum performance is your pipeline implementation (Figure 10 shows a Megatron GPT-3 based example)
Large models are the present and the future of NLP
Large language models have appealing properties and will help expand the availability of NLP around the globe. They more performant across a wide number of NLP tasks, but they are also much more sample efficient. They are what are known as few-shot learners and in certain ways are easier to design, as their exact hyperparameter configuration seems unimportant in comparison to their size. As a consequence, the NLP models are likely to continue to grow. I see empirical evidence justifying at least one if not two orders of magnitude of growth.
Fortunately, the technology to build and deploy them to production has matured considerably. The software required to train them has also matured considerably and is broadly available, such as the NVIDIA open source Megatron-based implementation of GPT-3. Quality is continuing to improve, driving down the training times. The infrastructure required to train models in this space is also well understood and commercially available (DGX SuperPOD). It is now possible to deploy the largest of NLP models to production using tools such as Triton Inference Server. As a consequence, big NLP models are in reach of everyone with the will to pursue them.
Summary
NVIDIA actively supports customers in the scoping and delivery of large training and inference systems, as well as supporting them in establishing NLP training capability. If you are working towards building your NLP capability, reach out to your local NVIDIA account team.
You can also join one of our Deep Learning Institute NLP classes. During the course, you learn how to work with modern NLP models, optimise them with TensorRT, and deploy for cost-effective production with Triton Inference Server.
For more information, see any of the following NLP-related GTC presentations:
- Natural Language Processing: The New Opportunity [E32293]
- Megatron GPT-3 Large Model Inference with Triton and ONNX Runtime [S31578]
- Accelerating AI at-scale with Selene DGXA100 SuperPOD and Parallel Filesystem Storage [S31522]
- S32030: GatorTron – The Biggest Clinical Language Model
- Designing and Optimizing Deep Neural Networks for High-Throughput and Low-Latency Production Deployment [E31970]
