Editor’s note: Interested in GPU Operator? Register for our upcoming webinar on January 20th, “How to Easily use GPUs with Kubernetes”.
For many years, docker was the only container runtime supported by Kubernetes. Over time, support for other runtimes has not only become possible but often preferred, as standardization around a common container runtime interface (CRI) has solidified in the broader container ecosystem. Runtimes such as containerd and cri-o have grown in popularity as docker has struggled to keep pace with support for the CRI.
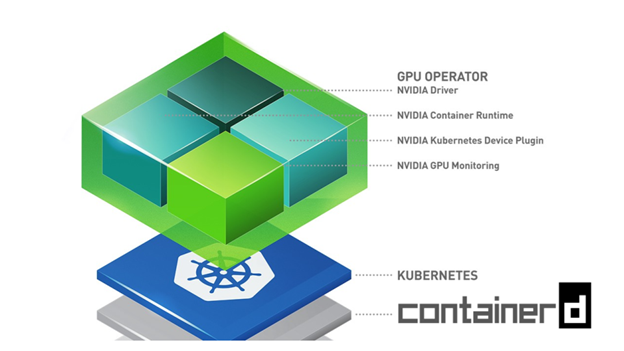
As of Kubernetes 1.20 support for docker has been deprecated, prompting many to rethink their future choice of container runtime. For existing docker users, the obvious and less risky choice is containerd, as docker already runs on top of containerd under the hood. From a user’s perspective, such a transition would be completely transparent.
Until recently, the NVIDIA GPU Operator only ran on Kubernetes deployments using docker or cri-o as their underlying container runtime. Starting with version 1.4.0, integrated support for containerd is available as well.
Support for containerd has been a longstanding feature request for the GPU Operator, as it enables systems such as microK8s, which only runs on containerd, and the NVIDIA edge computing platform (EGX) to reach a broader number of users.
In the simplest form, all it takes to deploy the GPU operator with containerd support is to set a single value in a Helm chart and run helm install:
helm install --wait --generate-name \ nvidia/gpu-operator \ --set operator.defaultRuntime="containerd"
In this post, you learn how to enable containerd support in the GPU Operator, what customizable features are available for it, and how it works under the hood.
Supporting containerd in the GPU Operator
The NVIDIA GPU Operator simplifies GPU lifecycle management in Kubernetes. With a single helm command, you can install the GPU Operator onto a Kubernetes cluster and make GPUs available to end users.
Under the hood, Node Feature Discovery is used to detect GPU-equipped cluster nodes and provision any required software components to them. These include the NVIDIA GPU driver, the NVIDIA container runtime, the Kubernetes device plugin, the DCGM monitoring agent, and GPU Feature Discovery. Once installed, the GPU Operator continuously monitors the state of the cluster, adding these components to any new GPU nodes that get attached over time. A high-level state-machine of the GPU Operator can be seen below.
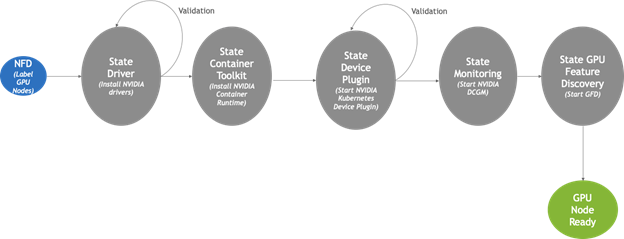
Most of the work in adding containerd support to the GPU Operator was done in the Container Toolkit component shown in Figure 1. In general, the Container Toolkit is responsible for installing the NVIDIA container runtime on the host. It also ensures that the container runtime being used by Kubernetes, such as docker, cri-o, or containerd is properly configured to make use of the NVIDIA container runtime under the hood.
For containerd support, this involved the following steps:
- Installing the NVIDIA container runtime on the host.
- Updating the
containerdconfig file to point at this newly installed runtime. - Sending a
SIGHUPtocontainerdto force the config changes to take effect.
The rest of the work was just adding the necessary plumbing to make this feature available through helm. The following code example shows the helm settings available for configuring the GPU operator with containerd support.
operator: defaultRuntime: containerd toolkit: env: - name: CONTAINERD_CONFIG value: /etc/containerd/config.toml - name: CONTAINERD_SOCKET value: /run/containerd/containerd.sock - name: CONTAINERD_RUNTIME_CLASS value: nvidia - name: CONTAINERD_SET_AS_DEFAULT value: true
The only required setting is for operator.defaultRuntime to be set to containerd. This triggers the GPU operator to load the Container Toolkit with containerd support. The rest of the settings are optional and are used to customize specific containerd settings under the hood. The values shown earlier are the defaults.
CONTAINERD_CONFIG:The path on the host to thecontainerdconfig to have updated with support fornvidia-container-runtime. By default, this points to/etc/containerd/config.toml(default location forcontainerd). If yourcontainerdinstallation is not in the default location, this value should be customized.CONTAINERD_SOCKET:The path on the host to the socket file used to communicate withcontainerd. The operator uses this to send aSIGHUPsignal to thecontainerddaemon to reload its config. By default, this points to/run/containerd/containerd.sock(default location forcontainerd). If yourcontainerdinstallation is not in the default location, this value should be customized.CONTAINERD_RUNTIME_CLASS:The name of the RuntimeClass resource to associate with thenvidia-container-runtime. Pods launched with aruntimeClassNamevalue equal toCONTAINERD_RUNTIME_CLASSalways run with thenvidia-container-runtime. The defaultCONTAINERD_RUNTIME_CLASSvalue isnvidia.CONTAINERD_SET_AS_DEFAULT:A flag indicating whether to setnvidia-container-runtimeas the default runtime used to launch all containers. When set tofalse, only containers in pods with aruntimeClassNamevalue equal toCONTAINERD_RUNTIME_CLASSare run with thenvidia-container-runtime. The default value istrue.
The following code example launches the GPU Operator with containerd support and explicit values for each of the optional settings described earlier.
helm install --wait --generate-name \ nvidia/gpu-operator \ --set operator.defaultRuntime=containerd \ --set toolkit.env[0].name=CONTAINERD_CONFIG \ --set toolkit.env[0].value=/etc/containerd/config.toml \ --set toolkit.env[1].name=CONTAINERD_SOCKET \ --set toolkit.env[1].value=/run/containerd/containerd.sock \ --set toolkit.env[2].name=CONTAINERD_RUNTIME_CLASS \ --set toolkit.env[2].value=nvidia \ --set toolkit.env[3].name=CONTAINERD_SET_AS_DEFAULT \ --set toolkit.env[3].value=true
And that’s it! You should now have all the tools you need to get the GPU operator up and running with containerd. For more information, see Getting Started.
