
Developers from Amazon’s Alexa Research group have just published a developer blog and published a paper describing how they are using adversarial training to recognize and improve emotion detection.
“A person’s tone of voice can tell you a lot about how they’re feeling. Not surprisingly, emotion recognition is an increasingly popular conversational-AI research topic,” said Viktor Rozgic, a senior applied scientist in the Alexa Speech group stated.
The work was completed in collaboration with Srinivas Parthasarathy, a doctoral student in the Electrical Engineering Department at The University of Texas at Dallas who previously interned at Amazon.
“Typically, emotion classification systems are neural networks trained in a supervised fashion: training data is labeled according to the speaker’s emotional state, and the network learns to predict the labels from the data,” Rozgic said.
This work uses an alternative approach, in which the team trains a neural network using an adversarial autoencoder, which is comprised of an encoder-decoder neural network.
Using 8 NVIDIA Tesla GPUs on the Amazon Web Services cloud, the team trained their neural network on a dataset that contains over 10,000 utterances from 10 different speakers.
The team’s latent emotion representation consists of three network nodes: valence, which dictates whether the speaker’s emotion is positive or negative; activation, which includes whether the speaker is alert and engaged or passive; dominance, or if the speaker is in control.
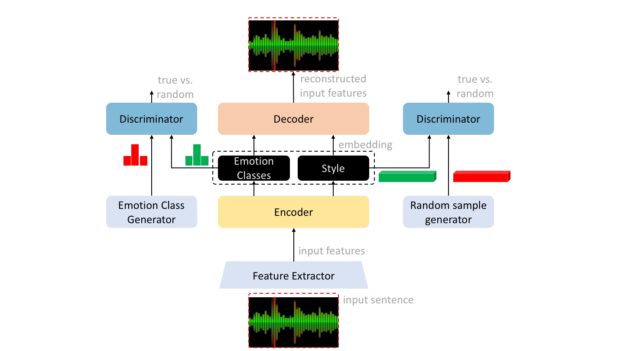
“In tests in which the inputs to our network were sentence-level feature vectors hand-engineered to capture relevant information about a speech signal, our network was 3% more accurate than a conventionally trained network in assessing valence,” the team stated.
When the network was supplied with a sequence of representations of the acoustic characteristics of 20-millisecond frames, the network improvements was 4%, compared to a baseline approach developed by the researchers.
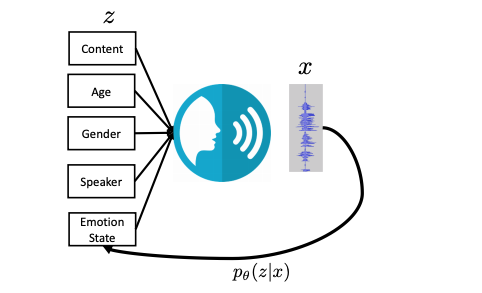
For inference, the team relies on the NVIDIA Tesla GPUs to detect the emotional state, as well as speaker, gender, age, and content.
“We demonstrated that the proposed approach is applicable to fully-connected network models operation on utterance-level features and convolutional neural network models operating on frame-level features,” the researchers stated in their paper.
The work has the potential to help make conversational AI systems more responsive, as well as potentially helping detect life-threatening medical events such as a heart attack.
The researchers recently presented their work at the International Conference on Acoustics, Speech, and Signal Processing. A version of the paper appears on IEEE.
