Researchers from Facebook, Stanford, and the University of Washington developed a deep learning based method that can transform audio of musical instruments into skeleton predictions, which can be used to animate an avatar.
“The key idea is to create an animation of an avatar that moves their hands similarly to how a pianist or violinist would do, just from audio,” the researchers stated in their paper. “We believe the correlation between audio to human body is very promising for a variety of applications in VR/AR and recognition.”
Using NVIDIA Tesla GPUs the team trained their system on hours of violin and piano playing footage the researchers found on YouTube.
“The intuition behind our choice of video was to have clear high quality music sound, no background noise, no accompanying instruments, solo performance. On the video quality side, we searched for videos of high resolution, stable fixed camera, and bright lighting. We preferred longer videos for continuity.,” the researchers said.
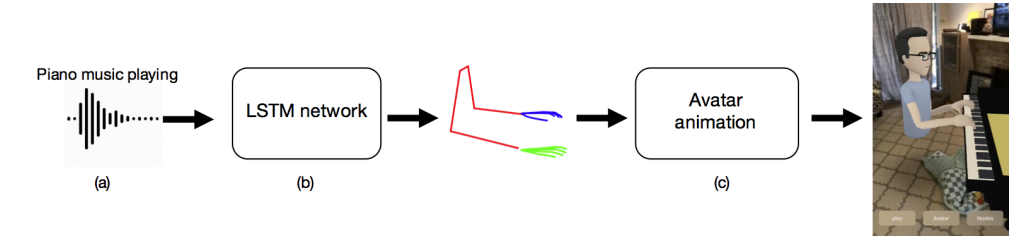
To increase realism in the VR/AR predictions, the team will complement training data with sensor information or midi files, the team said.
Read more>
AI-Generated Summary
- Researchers from Facebook, Stanford, and the University of Washington created a deep learning method that transforms audio of musical instruments into skeleton predictions to animate an avatar.
- The team trained their system using hours of violin and piano playing footage from YouTube on NVIDIA Tesla GPUs, selecting high-quality videos with solo performances and clear sound.
- To improve the realism of their VR/AR predictions, the researchers plan to complement their training data with sensor information or midi files in the future.
AI-generated content may summarize information incompletely. Verify important information. Learn more