What if you could take your photos that were originally taken in low light and automatically remove the noise and artifacts? Have grainy or pixelated images in your photo library and want to fix them? This deep learning-based approach has learned to fix photos by simply looking at examples of corrupted photos only.
The work was developed by researchers from NVIDIA, Aalto University, and MIT, and is being presented at the International Conference on Machine Learning in Stockholm, Sweden this week.

Recent deep learning work in the field has focused on training a neural network to restore images by showing example pairs of noisy and clean images. The AI then learns how to make up the difference. This method differs because it only requires two input images with the noise or grain.
Without ever being shown what a noise-free image looks like, this AI can remove artifacts, noise, grain, and automatically enhance your photos.

“It is possible to learn to restore signals without ever observing clean ones, at performance sometimes exceeding training using clean exemplars,” the researchers stated in their paper.“[The neural network] is on par with state-of-the-art methods that make use of clean examples — using precisely the same training methodology, and often without appreciable drawbacks in training time or performance.”
Using NVIDIA Tesla P100 GPUs with the cuDNN-accelerated TensorFlow deep learning framework, the team trained their system on 50,000 images in the ImageNet validation set.
To test the system, the team validated the neural network on three different datasets.
The method can even be used to enhance MRI images, perhaps paving the way to drastically improve medical imaging.
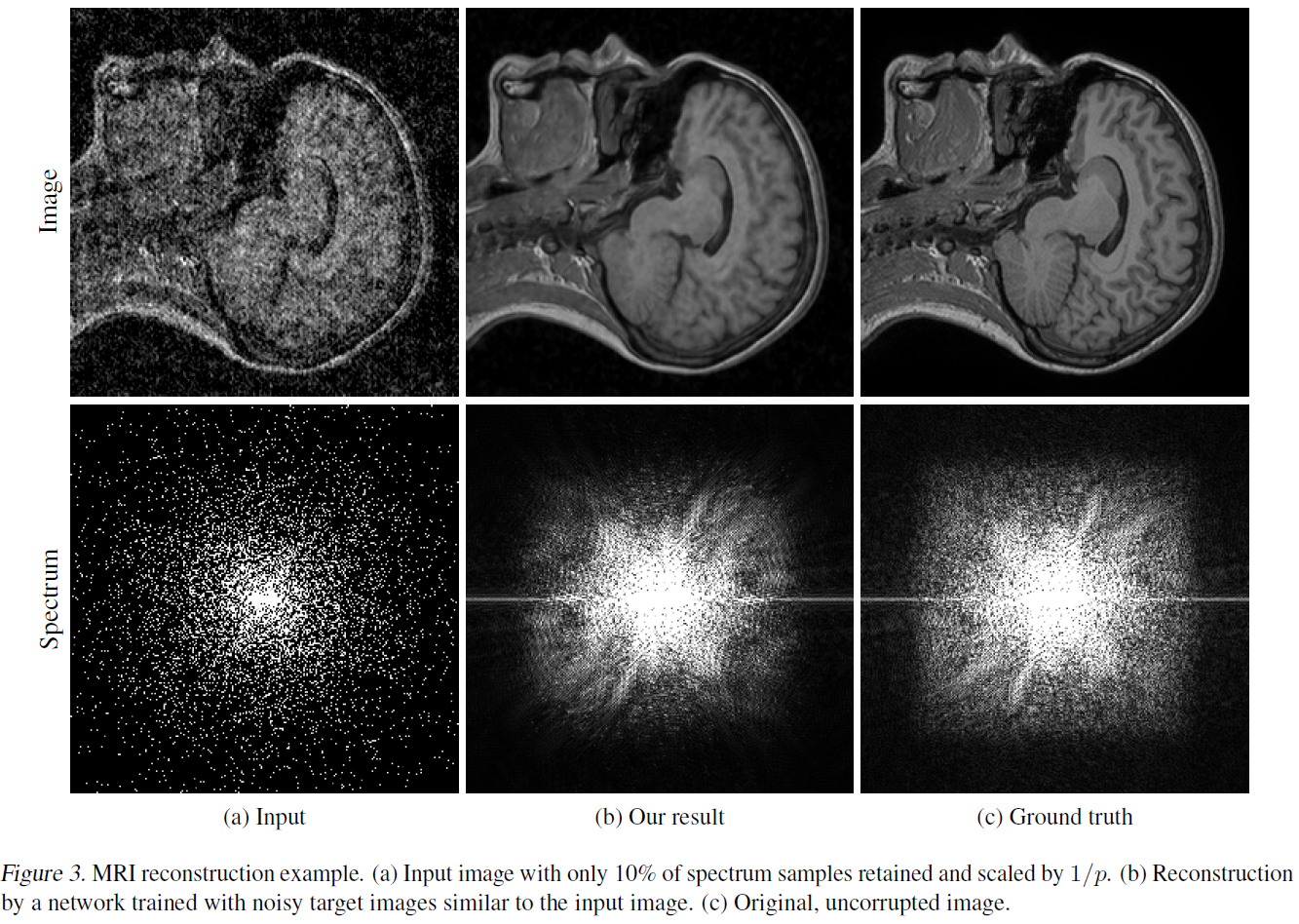
“There are several real-world situations where obtaining clean training data is difficult: low-light photography (e.g., astronomical imaging), physically-based rendering, and magnetic resonance imaging,” the team said. “Our proof-of-concept demonstrations point the way to significant potential benefits in these applications by removing the need for potentially strenuous collection of clean data. Of course, there is no free lunch – we cannot learn to pick up features that are not there in the input data – but this applies equally to training with clean targets.”

The team will present their work in an oral presentation and a poster at the ICML conference. You can meet the team on Thursday, July 12 at the Supervised Learning oral session (2:20 pm) and 6:15 pm poster session.
Read more >
AI Can Now Fix Your Grainy Photos by Only Looking at Grainy Photos

Jul 09, 2018
Discuss (1)
AI-Generated Summary
- Researchers from NVIDIA, Aalto University, and MIT have developed a deep learning-based approach that can remove noise and artifacts from images without being trained on clean images.
- The AI model was trained on 50,000 images from the ImageNet validation set using NVIDIA Tesla P100 GPUs and the cuDNN-accelerated TensorFlow deep learning framework.
- The method has potential applications in various fields, including low-light photography, astronomical imaging, and medical imaging, such as enhancing MRI images.
AI-generated content may summarize information incompletely. Verify important information. Learn more