Many organizations today run applications in containers to take advantage of the powerful orchestration and management provided by cloud-native platforms based on Kubernetes. However, virtual machines continue to remain as the predominant data center infrastructure platform for enterprises, and not all applications can be easily modified to run in containers. For example, applications requiring older operating systems, custom kernel modules, or specialized hardware require more effort to containerize.
KubeVirt and OpenShift Virtualization are add-ons to Kubernetes that provide virtual machine (VM) management. These solutions eliminate the need to manage separate clusters for VM and container workloads. KubeVirt is a community-supported open source project, and it also serves as the upstream project for the OpenShift Virtualization feature from Red Hat.
NVIDIA GPUs have been accelerating applications that are virtualized for many years, and NVIDIA has also created technology to support GPU acceleration for containers managed by Kubernetes. The latest release of the NVIDIA GPU Operator adds support for KubeVirt and OpenShift Virtualization. Now, GPU-accelerated applications running as virtual machines can be orchestrated by Kubernetes too, just like ordinary enterprise applications, enabling unified management.
GPUs in KubeVirt and OpenShift Virtualization
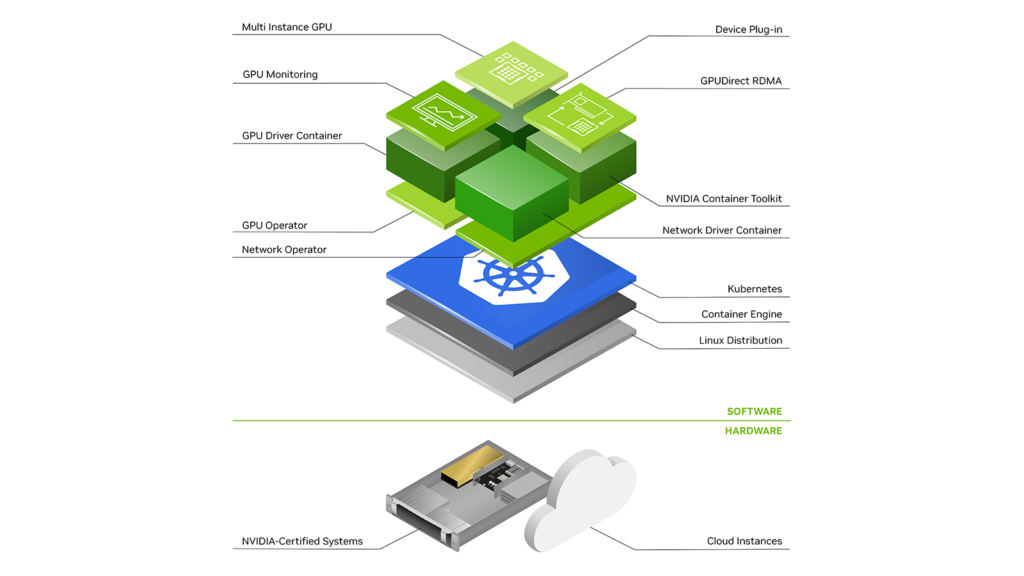
NVIDIA GPU Operator v22.9 enables GPU-accelerated containers and GPU-accelerated virtual machines, using either NVIDIA Virtual GPU (vGPU) or PCI passthrough, to run alongside each other in the same cluster. This version introduces new software components that support virtual machines.
Additionally, the operator is responsible for providing automation to manage the deployment, configuration, and lifecycle of this software, easing the operational overhead on cluster administrators. More detailed information about these components is provided below.
The vfio-pci driver (Virtual Function I/O) provides a secure user space driver that is needed when using a physical GPU for PCI passthrough. PCI passthrough presents the entire GPU as a PCI device to a virtual machine. When using PCI passthrough, the GPU cannot be shared, but provides the highest performance.
The NVIDIA vGPU Manager is the driver installed on the hypervisor that enables NVIDIA Virtual GPU technology. NVIDIA vGPU enables multiple virtual machines to have simultaneous, time-based shared access to a single physical GPU.
The NVIDIA vGPU Device Manager is responsible for interacting with the vGPU Manager and creating vGPU devices on the worker node.
The NVIDIA KubeVirt device plug-in discovers and advertises both physical and NVIDIA vGPU devices to kubelet so that they can be requested and assigned to VMs. Kubelet is an agent running on every node in the cluster, responsible for communication between the node and the Kubernetes control plane.
Planning for deployment
Prior to deployment, it is important to be aware of some of the limitations. Currently, MIG-backed vGPU instances are not supported. Additionally, a given GPU worker node can only run GPU workloads of single type—containers, VMs with PCI passthrough, or VMs with NVIDIA vGPU—but not a combination.
To enable this new functionality, set sandboxWorkloads.enabled to true in ClusterPolicy. When enabled, the GPU Operator will manage and deploy the new software components needed for supporting virtual machines. This option is disabled by default, meaning that the GPU Operator will only provision worker nodes for container workloads.
Administrators have the ability to control where workloads get deployed through the use of Kubernetes node labels. GPU Operator v22.9 introduces a new node label, nvidia.com/gpu.workload.config, which dictates which software components get deployed by the GPU Operator and consequently controls what type of GPU workloads a node supports. This node label can take on the values container, vm-passthrough, and vm-vgpu which correspond to the different workloads now supported.
This concept allows administrators to have pools of machine types, each with different capabilities, and managed by a common control plane. If the nvidia.com/gpu.workload.config node label is not present on a GPU worker node, the GPU Operator will use the default workload type, which is configurable in ClusterPolicy through the sandboxWorkloads.defaultWorkload field.
Conclusion
GPU Operator v22.9 brings with it additional capabilities required to run GPU-powered workloads on Kubernetes with KubeVirt and OpenShift Virtualization. VMs in Kubernetes can attach GPU devices using PCI passthrough or NVIDIA vGPU. This flexibility speeds the adoption of cloud-native platforms by removing the need to refactor GPU-accelerated applications to support containerization. Administrators can continue to run these applications in VMs alongside other container native applications, with Kubernetes performing the orchestration.
Getting started
To get started with GPU accelerated virtual machines, see the official documentation on Running KubeVirt VMs with the GPU Operator. Submit feedback and bug reports through the gpu-operator/issues GitHub repository. Contributions to the kubernetes/gpu-operator GitLab repository are also encouraged.