
For the past decade and a half, an increasing number of businesses have moved their traditional IT applications from on-premises to public clouds. This first phase of the revolution, which you could call “enterprise cloud transformation,” has allowed enterprises to reap the benefits of the scale, expertise, and flexibility of the cloud. The second phase of this revolution, the “edge AI cloud transformation,” is happening now and is driven by a combination of IoT, 5G, edge computing, and AI. It opens a world of possibilities for new edge AI services that will transform many industries. Businesses and governments will reap the value of edge AI by providing a host of new services, including smart cities, autonomous vehicles, Industry 4.0, smart retail, and telemedicine.
A world where hundreds of billions of devices generate actionable data requires a paradigm shift in the network architecture. The rise of 5G brings with it much higher data speeds and the ability to perform network slicing, which enables network-as-a-service for delivering all kinds of edge applications and services. As many of the edge services rely on ultra-low latency links, they are ill-suited for the traditional cloud IT approach of processing all data in a centralized location. Thus, the rise of edge computing, where data is handled closer to the devices that produce it and the end users or consumers who use it. Edge computing optimizes bandwidth utilization, reduces latency, and ensures greater privacy for these new services. This new phase of the revolution is driven by AI, which powers the innovation in the edge data centers to generate value from the raw data from sensors to garner real-time insights. Hence, these applications of the future are called edge AI services.
NVIDIA has partnered with Mavenir to build an accelerated and efficient Edge AI solution for Intelligent Video Analytics (IVA). IVA application frameworks such as NVIDIA Metropolis make sense of the flood of data generated by cameras and sensors. They help power smart cities by providing intelligent traffic and parking systems, or enable advances in industrial automation to increase productivity and reduce waste.
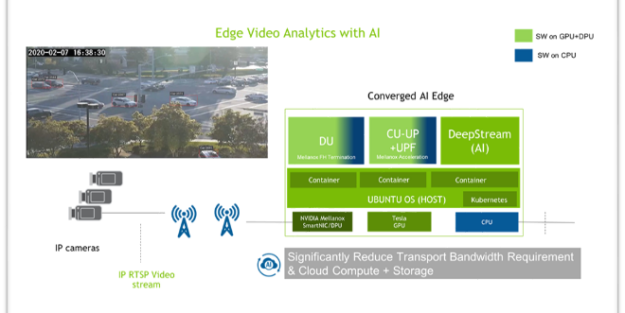
NVIDIA-Mavenir efficient and accelerated IVA solution
NVIDIA and Mavenir have collaborated on an edge AI use case focused on real-time object detection in urban areas or industrial campuses. The solution is used to detect objects of interest, enabling applications such as monitoring smart parking in an airport parking lot, preventing mail theft, or coordinating robotic vehicles.
As shown in Figure 1, the end-to-end solution from NVIDIA and Mavenir takes video streams generated by 5G-connected cameras and routes them through Mavenir’s 5G Core User Plane Function (UPF), accelerated by the NVIDIA smartNICs capabilities, to the NVIDIA Metropolis platform. All this runs in a hyperconverged 2RU NVIDIA EGX edge server. The combination of these disaggregated infrastructure components come together to deliver an accelerated and efficient AI-driven Edge IVA solution for public and private 5G customers.
Packet flow: A day in the life of a packet
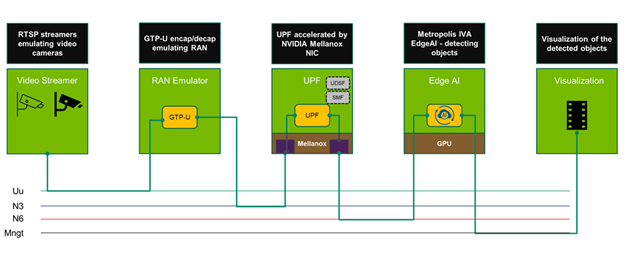
As shown in Figure 2, cameras feed video into the platform. The video frame packets provided by these cameras flows across a Uu connection to an emulated RAN. The RAN routes the packets over an N3 connection into the GPRS Tunneling Protocol (GTP) tunnel of the Mavenir 5G UPF. NVIDIA ConnectX-6 Dx SmartNICs offload and accelerate the packet processing of the UPF, continuing to route the packets out of the GTP tunnel over an N6 connection to the EGX Edge server. The NVIDIA Metropolis IVA Edge AI platform performs the video analysis and outputs visualization data that can be used to drive additional applications to act on the analyzed data.
Each video camera streams at 720p resolution and at 4 Mbps of bandwidth. The use case has 160 cameras, thereby creating an aggregate 640 Mbps of bandwidth per network slice. Efficient utilization of the system becomes key in providing an efficient and economically feasible solution.
Key role of the UPF in the 5G Core
One of the key elements of this joint solution is the 5G Core. One aspect that we are specifically highlighting with this joint solution is how hardware offloads can be used to accelerate elements of the 5G system. Specifically, we can demonstrate the benefits of offloading elements of the Mavenir UPF to provide the most efficient service and throughput possible.
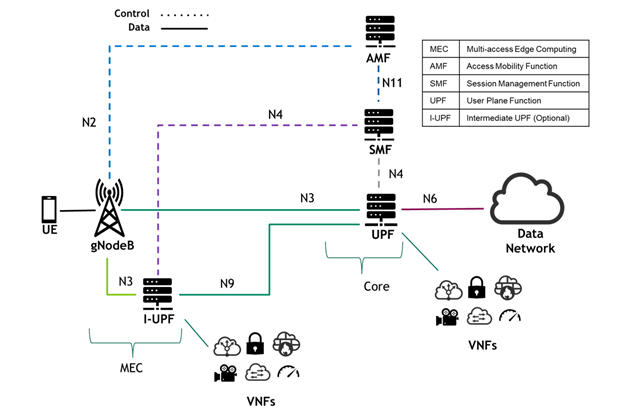
As shown in Figure 3, the UPF is a key component in the 3GPP 5G Core specification. It can be thought of as the backbone of the 5G network. The UPF provides the link between the RAN/MEC on one side and the data network on the other, ensuring the efficient passing of data through the system.
The UPF is managed by the Session Management Function (SMF) component of the 5G Core. The SMF defines the rules for the movement packets through the UPF based on defined business rules. As such, one of the roles of the UPF is to parse the session or user information from incoming packets and match it to rules defined by the SMF.
The connections through the 5G (designated as N3 and N9 in the 3GPP protocol) are based on GTP. The UPF handles the decapsulation and encapsulation of packets as they pass through this GTP tunnel. In addition, the UPF handles packet routing and forwarding, packet inspection, quality of service (QoS) enforcement, and network address translation (NAT). As part of its work, the UPF manages receive side scaling (RSS) of packets, in which packets are load-balanced and directed to different cores inside the UPF server for handling.
This variety of roles provide multiple opportunities for accelerating UPF performance using hardware offload.
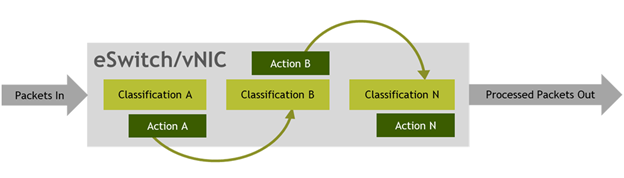
Legacy virtual network functions (VNFs) traditionally run on general-purpose CPUs. While flexible, these are limited in their scalability and response to varying workloads. NVIDIA networking technology uses physical hardware such as smartNICs and DPUs to perform packet processing tasks at high speeds. The focus is on managing flow rules in the NIC tables, matching incoming packets with predefined rules. NVIDIA Mellanox ASAP2 is a flagship open-source–based technology that achieves accelerated switching and packet processing for cloud, virtualized, and bare metal environments.
The hardware executes offloaded functions more efficiently than the software. As a result, operations can be executed with higher throughput and lower latency. In addition, offloading frees up the CPUs to handle other tasks instead of doing packet processing.
ASAP2 offloading UPF functionality to hardware
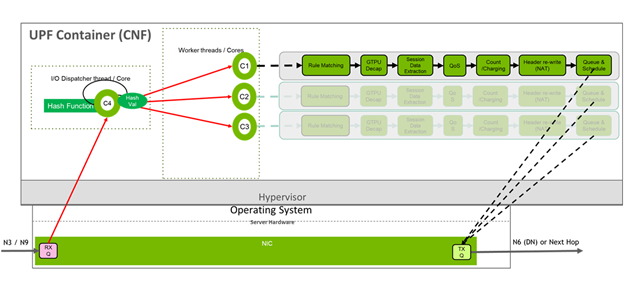
As seen in Figure 5, in a non-accelerated world, UPF receives packets through the N3 or N9 interfaces from the gNodeB. A dispatcher thread or core in the UPF server is then responsible for the RSS. The dispatcher takes the packet and directs it to one of numerous worker threads or virtual cores. These cores then handle the rest of the UPF pipeline:
- Initial matching of subscriber-specific rules identified by the subscriber’s IP address
- GTP encapsulation/decapsulation (based on the flow of the data through the GTP tunnel) to extract the specific subscriber IP address
- Extraction of session data for processing based on SMF rules
- Performing business-focused tasks such as QoS and packet charging and counting
- Rewriting the packet headers for NAT, before queuing the packet to be sent to the data network or the next hop in the 5G system.
This process is CPU-intensive and inefficient. We can demonstrate the advantages of taking the packet processing through the pipeline and executing it in the smartNIC rather than the CPU. The current collaboration with Mavenir has demonstrated this offloading in two phases.
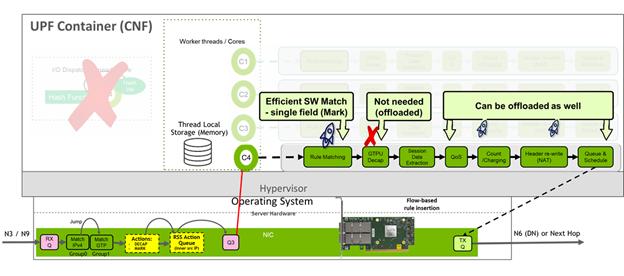
Figure 6 shows that the first offload phase focuses on the packet classification, flow tagging, GTP encap/decap, and RSS.
As the packet is received from the GNodeB, the NIC performs rule matching on IPv4 and session headers. In this way, the NIC understands the session context and performs the RSS function, dispatching the packets to worker threads accordingly. This offloading immediately frees up the dispatcher cores to perform other tasks.
In the second, more advanced phase, additional components of the UPF pipeline are offloaded to the NIC. This process includes flow tagging to maintain context of a match to be retained in a session as a packet is matched against multiple tables.
After the NIC performs the initial rule matching, it then performs GTP encap/decap and marks the packet for flow tagging before dispatching the packet to the worker cores.
As with the phase-I offloads, the dispatcher core is freed up. There are also more benefits. GTP encap/decap overhead is decreased as well as some of the CPU search cycles needed for UPF software matching. In addition, FlowTag marking greatly increases UPF processing by creating affinity-aware RSS. When the system identifies a packet, it can send it to specific threads for processing instead of just acting as a load balancer that is worker thread– and core affinity–aware.
Future developments look to offload the additional functions of the UPF pipeline to hardware, creating even more efficiency in the system.
Performance benefits of 5GC UPF offloads
Testing the system shows the clear advantages of offloading UPF functionality to the smartNIC. Testing was performed with video streams passing through the RAN into the UPF to be pushed towards the edge AI.
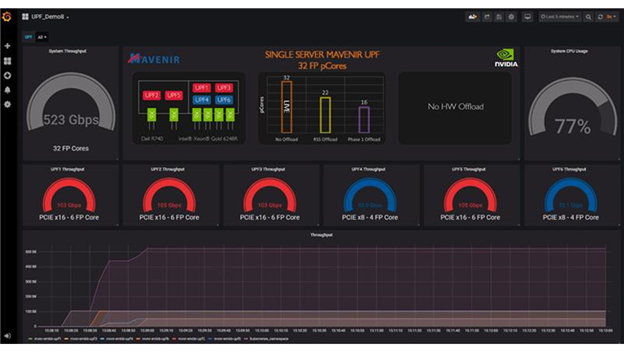
The Mavenir UPF software was configured to run with 32 virtual fast path cores. Figure 7 shows, as a baseline test, video streams pushed through the UPF without any hardware offloading. This test showed the 32 fast path cores reaching a maximum throughput of 524 Gbps
As SmartNIC UPF offloads are turned on, you see an amazing performance without sacrificing the efficiency of the overall IVA solution. For more information, watch the GTC Fall 2020 session, Edge AI Meets 5G: Efficient and Accelerated Intelligent Video Analytics (IVA).
