The post Getting Started with OpenACC covered four steps to progressively accelerate your code with OpenACC. It’s often necessary to use OpenACC directives to express both loop parallelism and data locality in order to get good performance with accelerators. After expressing available parallelism, excessive data movement generated by the compiler can be a bottleneck, and correcting this by adding data directives takes effort. Sometimes expressing proper data locality is more effort than expressing parallelism with loop directives.

Wouldn’t it be nice if programs could manage data locality automatically? Well, this is possible today with Unified Memory (on Kepler and newer GPU architectures). In this post I demonstrate how to combine OpenACC with Unified Memory to GPU-accelerate your existing applications with minimal effort. You can download the source code for the example in this post from the Parallel Forall GitHub repository.
Jacobi Iteration with Heap Memory
I’ll use the popular Jacobi iteration example code which is representative of many real-world stencil computations. In contrast to the previous OpenACC post, I modified the array data allocation to use heap memory instead of using automatic stack-allocated arrays. This is a more common scenario for real applications since real-world data arrays are often too large for stack memory. This change also makes it a more challenging case for OpenACC since the compiler no longer knows the size of the arrays. The following excerpt shows the main loop of the Jacobi iteration with 2D index computation.
while( err > tol && iter < iter_max ) {
err=0.0;
for( int j = 1; j < n-1; j++ ) {
for( int i = 1; i < m-1; i++ ) {
Anew[j*m+i] = 0.25 * (A[j*m+i+1] + A[j*m+i-1] +
A[(j-1)*m+i] + A[(j+1)*m+i]);
err = max(err, abs(Anew[j*m+i] - A[j*m+i]));
}
}
for( int j = 1; j < n-1; j++ ) {
for( int i = 1; i < m-1; i++ ) {
A[j*m+i] = Anew[j*m+i];
}
}
iter++;
}
The outer loop iterates for item_max iterations or until the results converge to within an acceptable tolerance tol (whichever comes first). The first double-nested inner loop calculates the new values for each point in the matrix as the mean of the neighboring values. The second double-nested loop copies these values into the A array for the next iteration.
Express Parallelism
In this code it’s clear that the convergence loop cannot be parallelized because of the dependence of each iteration on the results of the previous. The two inner loop nests over i and j, however, can be parallelized, as each iteration writes its own unique value and does not read from the values calculated in other iterations. I’ll use the OpenACC kernels directive to accelerate the loop nest. The kernels directive tells the compiler to analyze the code in the specified region to look for parallel loops. In the following code, I’ve placed a kernels region within the convergence loop to tell the compiler to find parallelism there.
while( err > tol && iter < iter_max ) {
err=0.0;
#pragma acc kernels
{
for( int j = 1; j < n-1; j++ ) {
for( int i = 1; i < m-1; i++ ) {
Anew[j*m+i] = 0.25 * (A[j*m+i+1] + A[j*m+i-1] +
A[(j-1)*m+i] + A[(j+1)*m+i]);
err = max(err, abs(Anew[j*m+i] - A[j*m+i]));
}
}
for( int j = 1; j < n-1; j++ ) {
for( int i = 1; i < m-1; i++ ) {
A[j*m+i] = Anew[j*m+i];
}
}
}
iter++;
}
I build the code with the PGI C/C++ compiler, pgcc, by specifying the NVIDIA Tesla GPU target architecture using the -ta=tesla command line argument. I included the -Minfo=all option, which provides compiler feedback about the generated code, resulting in the following output.
$ pgcc -fast -acc -ta=tesla -Minfo=all laplace2d.c
main:
85, Accelerator restriction: size of the GPU copy of Anew,A is unknown
Loop carried dependence of Anew-> prevents parallelization
Loop carried dependence of Anew-> prevents vectorization
Loop carried backward dependence of Anew-> prevents vectorization
Generating copyin(A[:])
Generating copyout(Anew[:])
86, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
86, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
91, Max reduction generated for error
95, Accelerator restriction: size of the GPU copy of A,Anew is unknown
Loop carried dependence of A-> prevents parallelization
Loop carried backward dependence of A-> prevents vectorization
Generating copyout(A[:])
Generating copyin(Anew[:])
96, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
96, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
From the output you can see that the compiler found an accelerator restriction which prevents the execution of our loops on the GPU. The compiler can’t determine the size of the A and Anew arrays that need to be copied to the GPU for the kernels to execute correctly. One way to resolve this issue is to specify the sizes of the arrays explicitly with an OpenACC data directive. Although in this simple example we know the size and range that needs to be copied to the accelerator, similar cases with complex data structures and non-trivial indexing are not unusual in real codes. This is where Unified Memory really demonstrates its power and provides great assistance to application developers.
Enable Unified Memory
Unified Memory simplifies memory management in GPU-accelerated applications managing memory regions that are shared between all CPUs and GPUs in the system. This memory can be accessed using a single pointer from CPU or GPU code. Because in most systems the CPU and GPU memories are physically separate, the underlying CUDA runtime system automatically migrates data in managed regions between CPU and GPU memory. This allows developers to focus on developing and optimizing algorithms rather than focusing on memory transfers and managing duplicate copies of the data shared between CPU and GPU memories. Unified Memory makes data locality an optimization rather than a prerequisite.
In the PGI compiler, the Unified Memory support is provided through the special Unified Memory Evaluation package. It is included with the standard download package since version 15.7, however make sure to select it during installation. To enable Unified Memory use in OpenACC you just need to add the -ta=tesla:managed option to the PGI compiler command line when compiling and linking your program. This option changes the way dynamic memory is allocated. In particular, for C programs, it replaces calls to malloc, calloc and free with calls to routines that allocate using Unified Memory (e.g. cudaMallocManaged()). More details about Unified Memory in the PGI compiler can be found in the PGInsider post OpenACC and CUDA Unified Memory.
Now I’ll compile my program with Unified Memory and look at the compiler feedback.
$ pgcc -fast -acc -ta=tesla:managed -Minfo=all laplace2d.c
main:
83, Generating copyout(Anew[:])
Generating copy(A[:])
85, Loop carried dependence of Anew-> prevents parallelization
Loop carried dependence of Anew-> prevents vectorization
Loop carried backward dependence of Anew-> prevents vectorization
86, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
86, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
91, Max reduction generated for error
95, Loop carried dependence of A-> prevents parallelization
Loop carried backward dependence of A-> prevents vectorization
96, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
96, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
The accelerator restriction is removed because the compiler can now rely on the CUDA runtime to migrate data automatically through Unified Memory. This code can execute on the GPU, but the compiler reports some loop dependencies which restrict parallelization of the outer loops at lines 85 and 95. Often the reason for such dependencies is pointer aliasing which can be resolved by adding the restrict keyword to array pointers (see this CUDA Pro Tip).
However, in my case the compiler cannot detect that the loop iterations are not overlapping because of the linearized index calculations. I know that the loop iterations are independent, and I can safely force the compiler to parallelize the code by using loop independent directives, similar to how I would use omp parallel directives on the CPU. Below is my final code and the corresponding compiler output.
while( err > tol && iter < iter_max ) {
err=0.0;
#pragma acc kernels
{
#pragma acc loop independent
for( int j = 1; j < n-1; j++ ) {
for( int i = 1; i < m-1; i++ ) {
Anew[j*m+i] = 0.25 * (A[j*m+i+1] + A[j*m+i-1] +
A[(j-1)*m+i] + A[(j+1)*m+i]);
err = max(err, abs(Anew[j*m+i] - A[j*m+i]));
}
}
#pragma acc loop independent
for( int j = 1; j < n-1; j++ ) {
for( int i = 1; i < m-1; i++ ) {
A[j*m+i] = Anew[j*m+i];
}
}
}
iter++;
}
$ pgcc -fast -acc -ta=tesla:managed -Minfo=all laplace2d.c
main:
83, Generating copyout(Anew[:])
Generating copy(A[:])
86, Loop is parallelizable
87, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
86, #pragma acc loop gang /* blockIdx.y */
87, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
92, Max reduction generated for error
97, Loop is parallelizable
98, Loop is parallelizable
Accelerator kernel generated
Generating Tesla code
97, #pragma acc loop gang /* blockIdx.y */
98, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
All loops are now parallelizable and you can see that the compiler generated corresponding kernels for them.
Performance Results
Figure 1 shows the performance results. The results were gathered for OpenMP implementation running on Intel Xeon E5-2698 v3 @ 2.30GHz and OpenACC implementations on NVIDIA Tesla K40 using PGI 15.7 compiler.
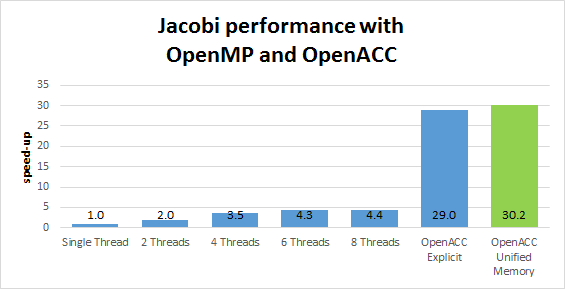
We can see that the GPU achieves about 7x improvement with OpenACC and Unified Memory over the multi-core CPU implementation. Note that the Unified Memory approach for this code achieves about the same performance as the optimized Jacobi iteration implementation with explicit data directives from Getting Started with OpenACC. I lost no performance and gained ease of programming: I didn’t have to insert any data directives!
LULESH
Now, what about something more interesting and realistic than the Jacobi iteration? Recently I had a chance to try out the OpenACC Unified Memory option in the hydrodynamics mini-application called LULESH. LULESH represents a typical hydrodynamics code found in DOE applications that simulate large deformations. LULESH is hard-coded to solve a simple Sedov blast problem but represents the numerical algorithms, data motion, and programming style typical in scientific C or C++ based applications.
LLNL’s initial port of LULESH to OpenACC in 2013 required a major rewrite of LULESH due to lack of support for structs and classes and other C++ features in the PGI OpenACC compiler. Performance was pretty good, but the port was too time consuming, requiring a graduate student to spend a few weeks.
PGI’s OpenACC compiler has come a long way, allowing more natural use of OpenACC in C++ programs. With Unified Memory and the PGI 15.x compiler I was able to port the LULESH code in just a couple days! Moreover, I was able to enter the OpenACC directives essentially side-by-side with the existing OpenMP directives in LULESH. I didn’t have to modify the data structures or insert any data directives, the only code changes were related to the actual computations and loops.
Unified Memory makes porting of real codes easier and delivers a more rewarding experience for the developers. You can start optimizing the loops from Day 1, instead of trying to make your code just run on the GPU. Figure 2 demonstrates performance results using the FOM (figure of merit) of zones/s comparing OpenMP and OpenACC implementations running on a single socket Intel E5-2690 v2 @ 3.0GHz with 10 cores and an NVIDIA Tesla K40. As you can see with the latest PGI compiler and Unified Memory I didn’t lose much in performance compared to the original optimized OpenACC code. More aggressive loop optimizations can likely improve OpenACC performance further.
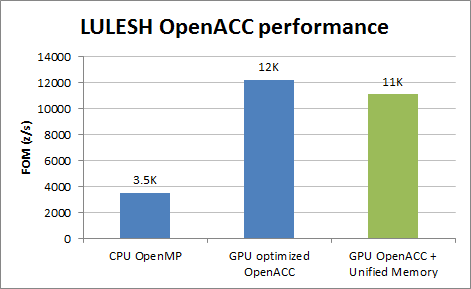
Conclusions
Unified Memory and OpenACC make a very powerful combination that lets you achieve good GPU performance in a very short time. There are some limitations of Unified Memory on current-generation GPU architectures:
- Only heap allocations can be used with Unified Memory, no stack memory, static or global variables.
- The total heap size for Unified Memory is limited to the GPU memory capacity.
- When Unified Memory is accessed on the CPU, the runtime migrates all the touched pages back to the GPU before a kernel launch, whether or not the kernel uses them.
- Concurrent CPU and GPU accesses to Unified Memory regions are not supported and result in segmentation faults.
On systems with multiple GPUs, Unified Memory allocations are visible to all devices with peer-to-peer capabilities. If peer mappings are not available between all GPUs, Unified Memory allocations fall back to using zero-copy memory, regardless of whether multiple GPUs are actually used by a program. To avoid performance regressions I recommend always setting the environment variable CUDA_MANAGED_FORCE_DEVICE_ALLOC to 1. This forces the driver to use device memory for storage, and an error is reported if an application tries to use Unified Memory between multiple devices that are not peer-to-peer compatible.
For full details on these limitations, see the Parallel Forall post on Unified Memory and the CUDA Documentation. These limitations will be eliminated in the future, notably with the introduction of the future Pascal GPU architecture.
Free Online OpenACC Course
 Join OpenACC experts from the HPC Industry for a free online OpenACC course starting October 1, 2015. This course comprises four instructor-led classes that include interactive lectures, hands-on exercises, and office hours with the instructors. You’ll learn everything you need to start accelerating your code with OpenACC on GPUs and x86 CPUs. The course will provide an introduction on how to parallelize, profile and optimize your code, as well as how to manage data movement and utilize multiple GPUs. Learn more and sign up at https://developer.nvidia.com/openacc-course
Join OpenACC experts from the HPC Industry for a free online OpenACC course starting October 1, 2015. This course comprises four instructor-led classes that include interactive lectures, hands-on exercises, and office hours with the instructors. You’ll learn everything you need to start accelerating your code with OpenACC on GPUs and x86 CPUs. The course will provide an introduction on how to parallelize, profile and optimize your code, as well as how to manage data movement and utilize multiple GPUs. Learn more and sign up at https://developer.nvidia.com/openacc-course