
As AI models grow larger and process longer sequences of text, efficiency becomes just as important as scale.
To showcase what’s next, Alibaba released two new open source models, Qwen3-Next 80B-A3B-Thinking and Qwen3-Next 80B-A3B-Instruct to preview a new hybrid Mixture of Experts (MoE) architecture with the research and developer community.
Qwen3-Next-80B-A3B-Thinking is now live on build.nvidia.com, giving developers instant access to test its advanced reasoning capabilities directly in the UI or through the NVIDIA NIM API.
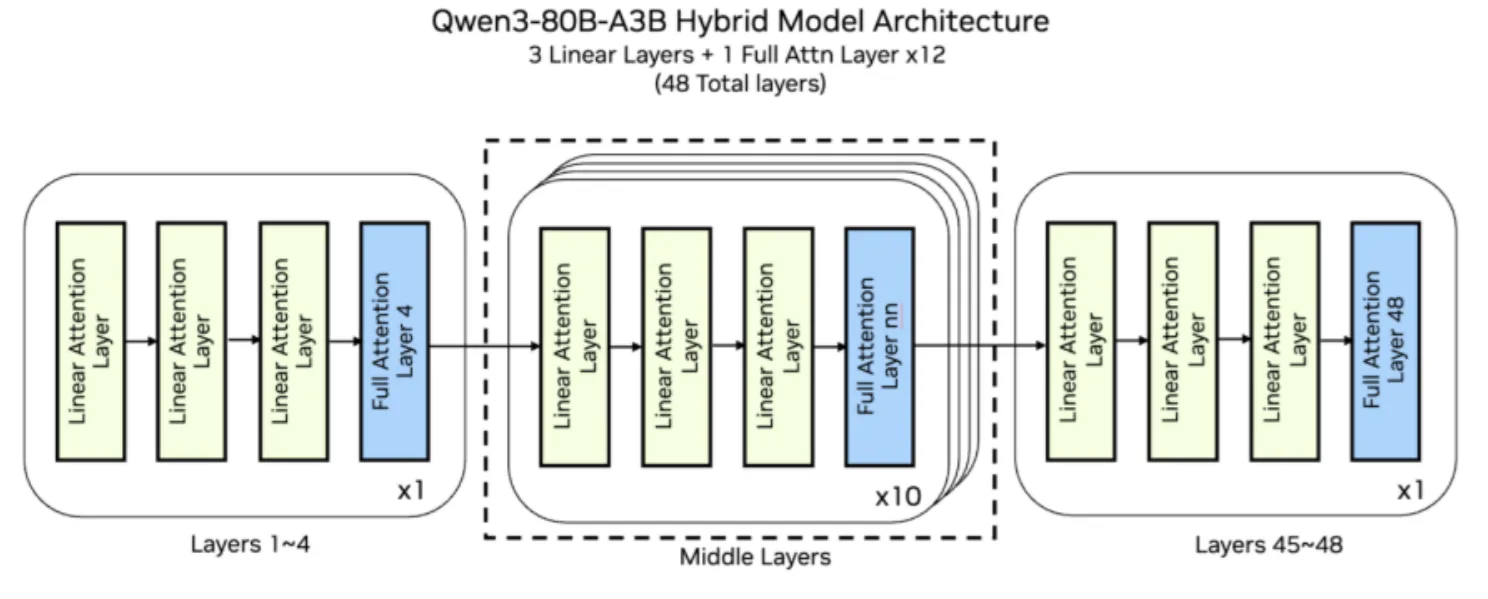
The new architecture of these Qwen3-Next models is optimized for long context lengths (>260K tokens input) and large-scale parameter efficiency. Each model has a total of 80B parameters, but only 3B are activated per token due to its sparse MoE structure, delivering the power of a massive model with the efficiency of a smaller one. The MoE module has 512 routed experts and 1 shared expert, with 10 experts being activated per token.
The performance of an MoE model like Qwen3-Next, which routes requests between 512 different experts, is heavily dependent on inter-GPU communication. Blackwell’s 5th-generation NVLink provides 1.8 TB/s of direct GPU-to-GPU bandwidth. This high-speed fabric is essential for minimizing latency during the expert routing process, directly translating to faster inference and higher token throughput in the AI Factory.
There are 48 layers in the model, every 4th layer using GQA attention while the remaining use the new linear attention. Large language models (LLMs) use attention layers to interpret and assign importance to each token of the input sequence. Less mature software stacks lack pre-optimized primitives for novel architectures or the specific fusions required to make the constant switching between attention types efficient.
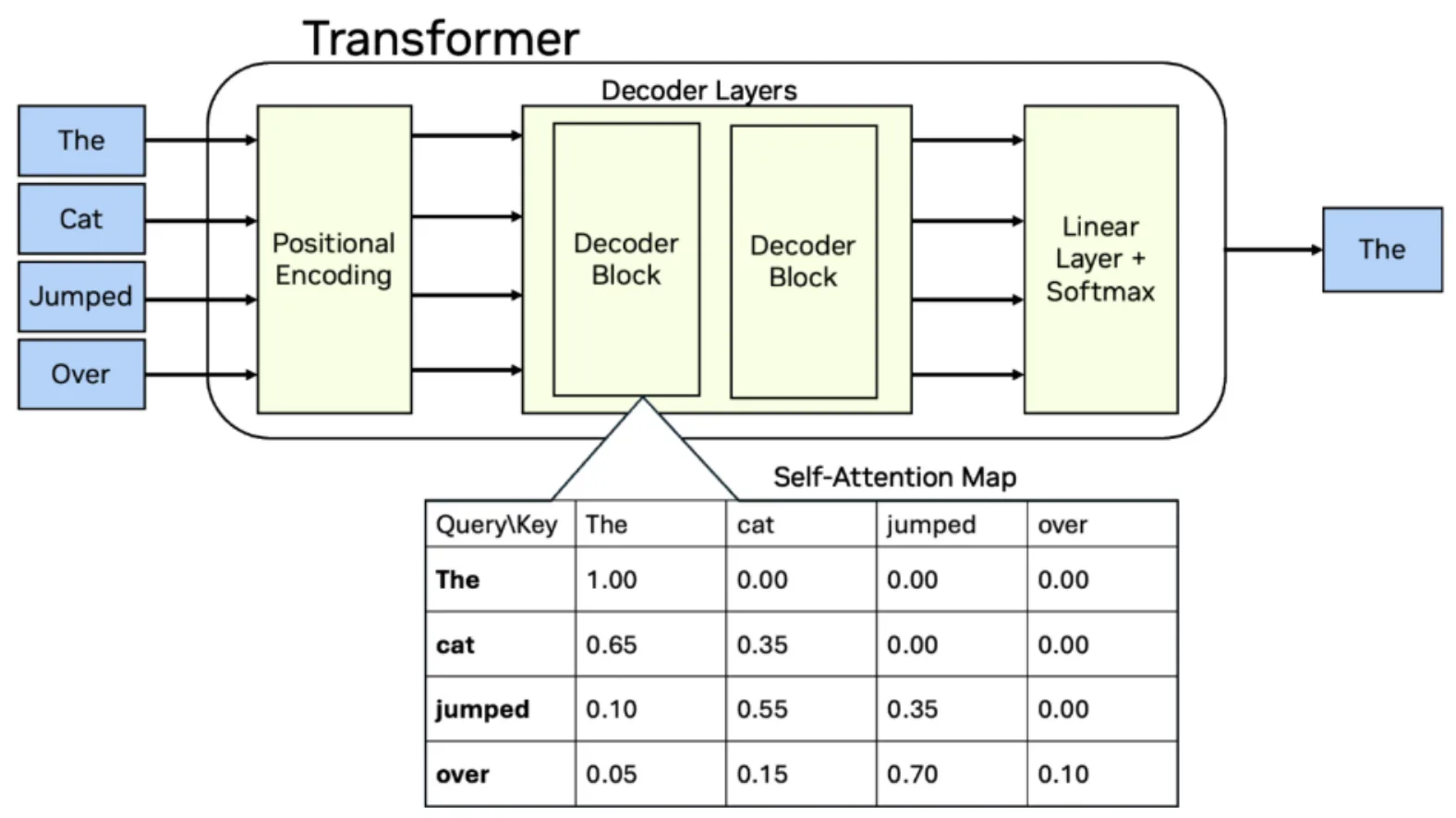
To achieve long input context capability, the model leverages Gated Delta Networks from NVIDIA research and MIT. Gated DeltaNets improve focus sequence processing so the model can process super long text efficiently without drifting off or forgetting what matters. This allows it to efficiently process extremely long sequences, with memory and computation scaling almost linearly with sequence length.
In addition to these architectural innovations, the model can be run on NVIDIA Hopper and Blackwell for optimized inference performance. NVIDIA’s flexible CUDA programming architecture allows for the experimentation of new and unique approaches, enabling both full attention layers of traditional Transformer models and the linear attention layers in the Qwen3-Next models. When run on NVIDIA, the hybrid approach seen in the Qwen3-Next models can lead to efficiency gains, paving the way for greater token generation and revenue for AI Factories.
NVIDIA collaborated with open source frameworks SGLang and vLLM to enable model deployment for the community as well as packaging both models as NVIDIA NIM. Developers can consume leading open models through enterprise software containers, depending on their needs.
Deploying with SGLang
Users deploying models with SGLang serving framework can use the following instructions. See the SGLang documentation for more information and configuration options.
python3 -m sglang.launch_server --model Qwen/Qwen3-Next-80B-A3B-Instruct --tp 4
Deploying with vLLM
Users deploying models with vLLM serving framework can use the following instructions. See the vLLM announcement blog for more information.
uv pip install vllm --extra-index-url https://wheels.vllm.ai/nightly --torch-backend=auto
vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct -tp 4
Production-ready deployment with NVIDIA NIM
Enterprise developers can try Qwen3-Next-80B-A3B along with the rest of the Qwen models for free using NVIDIA-hosted NIM microservice endpoints in the NVIDIA API catalog. Prepackaged, optimized NIM microservices are also available for secure, self-hosted deployment. For a step-by-step tutorial on building AI agents with the Qwen3-Next NIM, explore our Jupyter notebook guide that demonstrates practical implementation using the OpenAI Agents SDK.
Building on the Power of Open Source AI
The new hybrid MoE Qwen3-Next architecture pushes the boundaries of efficiency and reasoning, marking a significant advancement for the community. Making these models openly available empowers researchers and developers everywhere to experiment, build, and accelerate innovation. At NVIDIA, we share this commitment to open source through contributions such as NeMo for AI lifecycle management, Nemotron LLMs, and Cosmos world foundation models (WFMs). We’re working alongside the community to advance the state of AI. Together, these efforts ensure that the future of AI models is not just more powerful, but more accessible, transparent, and collaborative.
Get started today
Try the models on Open Router: Qwen3-Next-80B-A3B-Thinking and Qwen3-Next-80B-A3B-Instruct or download from Hugging Face: Qwen3-Next-80B-A3B-Thinking and Qwen3-Next-80B-A3B-Instruct.
Learn to build AI agents powered by Qwen3-Next: Follow our hands-on Jupyter notebook tutorial to create a simple note-taking agent powered by Qwen3-Next NIM endpoints.
Learn how NVIDIA Blackwell NVL72 runs 10x faster and delivers 1/10 the token cost for MoE models in this blog.
