这些年来,人工智能有了巨大的增长。随之而来的是对人工智能模型和应用程序的更大需求。创造高质量的人工智能需要人工智能和数据科学方面的专业知识,对许多开发人员来说,这仍然是一种威胁。
为了开发准确的人工智能,您必须选择要使用的模型架构、要收集的数据,以及最后如何调整模型以满足期望的 KPI 。有成千上万的模型架构和超参数组合,您必须尝试为您的特定用例获得最佳模型。这个过程非常费力,需要模型架构专业知识来调整超参数。
自动机器学习( AutoML )自动执行手动任务,为所需 KPI 找到最佳模型和超参数。它可以从算法上为给定的 KPI 导出最佳模型,并抽象出 AI 模型创建和优化的许多复杂性。
AutoML 使得即使是新手开发人员也很容易创建高度精确的 AI 模型。
TAO 中的 AutoML
TAO 中的 AutoML 完全可配置,用于自动优化模型的超参数,这减少了手动调整的需要。它迎合了人工智能专家和非专家。
- 对于非专家, Jupyter 笔记本电脑为创建精确的人工智能模型提供了一种简单、高效的方法。
- 对于专家来说, TAO 可以让您完全控制要调整的超参数以及用于扫描的算法。
TAO 目前支持两种优化算法: Baysian 和双曲线优化。这些算法可以有效地扫描一系列超参数,以找到优化用户提供的度量的最佳组合。
双曲线产生的速度更快,因为它不必贯穿整个训练配置。它只运行有限的时间段,丢弃表现不佳的运行,只在剩余的运行中继续。这种消除过程将继续进行,直到有一种配置能够提供最佳结果。
对于贝叶斯,所有扫描的训练都将持续到完成。
AutoML 支持多种 CV 任务:图像分类、对象检测、分割和 OCR 。表 1 显示了支持的网络的完整列表。
| Image Classification | Object Detection | Segmentation | OCR |
| ResNet10/18/34/50/101 EfficientNet_B0-B7 DarkNet19/53 CSPDarkNet19/53/Tiny MobileNet_v1/v2 SqueezeNet VGG16/19 GoogleNet |
YoloV3/V4/V4-Tiny EfficientNet RetinaNet FasterRCNN DetectNet_v2 SSD/DSSD |
UNET MaskRCNN | LPRNet |
AutoML 入门
整个 AutoML 工作流可以从提供的 Jupyter 笔记本运行。 AutoML 使用 TAO API 服务来管理所有培训工作。
TAO API 服务
TAO API 是一种 Kubernetes 服务,它支持将 TAO 作为微服务部署在您自己的 Kubernete 集群上或使用 Amazon EKS 或 Azure AKS 等云 Kubernets 服务。
TAO API 服务为容器提供了额外的抽象层。您可以使用 Helm 图表管理和部署 TAO 服务,并使用 REST API 调用远程运行作业。使用 API ,您可以远程创建和上载数据集、运行培训作业、评估模型和导出模型以进行部署。
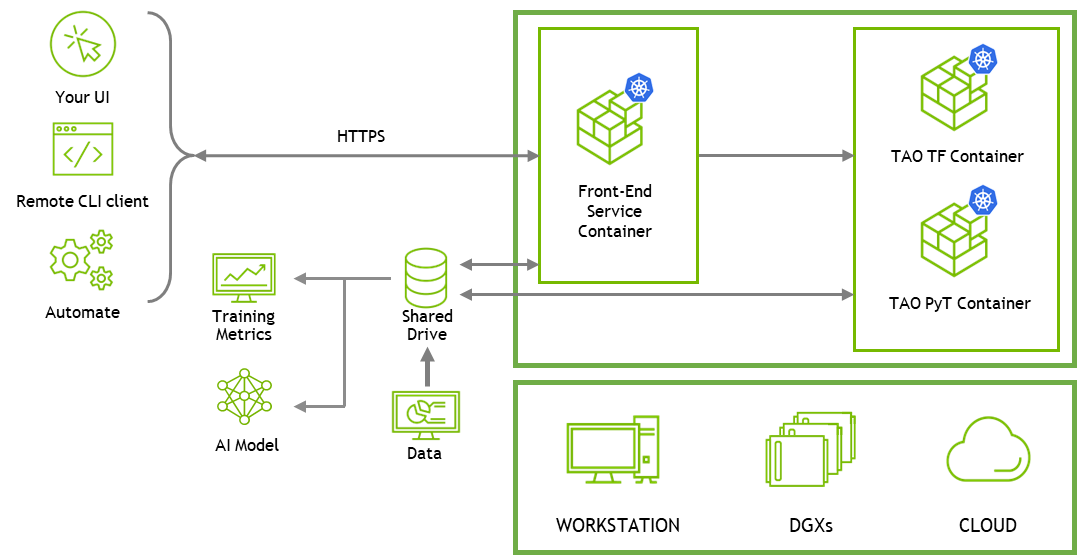
API 服务可以轻松地将 TAO 集成到您自己的自定义应用程序中,或在 TAO 之上构建 web UI 应用程序。要开始使用 REST API 构建自定义应用程序,请参阅 API guide 和 TAO Toolkit Getting Started 中的 API 笔记本。有关更多信息,请参阅本文后面的笔记本部分。
要使用 CLI 进行培训,请使用可以安装在客户端系统上的轻量级 CLI 客户端应用程序来访问 TAO 服务和 CLI 笔记本。 NGC 的 TAO getting started resources 中提供了 CLI 笔记本。
AutoML 需要在训练运行的基础上提供更高级别的服务,以确定和管理一组实验。 TAO 服务跟踪他们用 KPI 进行的所有实验,并构建下一组实验以改进 KPI 。您可以通过远程 CLI 应用程序或直接使用 REST API 使用 TAO API 服务运行 AutoML 。提供两种类型的 Jupyter 笔记本。有关详细信息,请参阅笔记本部分。
如果您在 TAO 之上构建自己的应用程序或 UI , RESTAPI 笔记本主要用作参考。
设置 TAO 服务
Amazon API 服务可以在任何 Kubernetes 平台上运行。为了简化 TAO 服务的部署,我们提供了一个一键部署脚本。这简化了在裸机设置或 TAO EKS 上部署 TAO 服务。在本文中,我们使用裸机设置,但 API 指南中提供了在云上部署的说明。
先决条件
- NVIDIA GPU (内部或云端):
- NVIDIA Volta 架构
- NVIDIA 图灵架构
- NVIDIA Ampere 架构
- NVIDIA Hopper 架构
- TAO 工具包 4.0
- Ubuntu 18.04 或 20.04
使用 NGC CLI 下载一键部署文件夹:
ngc registry resource download-version "nvidia/tao/tao-getting-started:4.0.0"
更改当前目录:
cd tao-getting-started_v4.0.0/cv/resource/setup/quickstart_api_bare_metal
在hosts文件中添加主机 IP 地址和登录凭据。这是您计划运行 TAO 服务的系统。它可以是本地或远程系统,但您必须具有sudo权限。
对于凭据,可以使用密码(ansible_ssh_pass)或 SSH 私钥文件(ansible_ssh_private_key_file)。对于单节点群集,只能列出主节点。
File name: hosts: [master] <IP Address> ansible_ssh_user='<username>' ansible_ssh_pass='<password>' [nodes] <IP Address> ansible_ssh_user='<username>' ansible_ssh_pass='<password>'
您可以使用以下命令验证远程计算机的 SSH 凭据。正确的答案应该是根。
ssh <username>@<IP Address> 'sudo whoami'
接下来,修改tao-toolkit-api-ansible-values.yml文件以添加 NGC 凭证和 Helm 图表。这将从 NGC 注册表中提取 Helm 图。有关详细信息,请参见 Generating Your NGC API Key 。
File name: tao-toolkit-api-ansible-values.yml ngc_api_key: <NGC API Key> ngc_email: <NGC email> api_chart: https://helm.ngc.nvidia.com/nvidia/tao/charts/tao-toolkit-api-4.0.0.tgz api_values: ./tao-toolkit-api-helm-values.yml cluster_name: tao-automl-demo
安装依赖项并部署 TAO 服务。在安装之前,首先通过运行check-inventory.yml检查是否满足所有依赖项。如果一切正常,您应该会看到一条消息,显示 0 失败。然后,运行install,这需要 10 – 15 分钟。
bash setup.sh check-inventory.yml bash setup.sh install
下载 AutoML 笔记本
从 NGC 上的 TAO Toolkit Getting Started 下载计算机视觉训练资源。
wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/tao/getting_started/versions/4.0.0/zip -O getting_started_v4.0.0.zip unzip -u getting_started_v4.0.0.zip -d ./getting_started_v4.0.0 && rm -rf getting_started_v4.0.0.zip && cd ./getting_started_v4.0.0
所有与 AutoML 相关的笔记本都位于 TAO API 目录中。笔记本以目录结构提供:
notebooks
|--> tao_api_starter_kit
|--> API
|--> automl
|--> end2end
|--> dataset_prepare
|--> client
|--> automl
|--> classification.ipynb
|--> object_detection.ipynb
|--> segmentation.ipynb
|--> lprnet.ipynb
|--> end2end
|--> dataset_prepare
对于这篇文章,请使用对象检测笔记本(TAO API Starter Kit/Notebooks/client/automl/object_detection.ipynb),但您也可以在其他计算机视觉任务上执行 AutoML 。
使用 AutoML 使用 TAO 微调对象检测模型
以下是使用对象检测 AutoML 笔记本快速演练 AutoML 工作流。在本演练中,将使用前面显示的层次结构中的client/automl/object_detection.ipynb笔记本。我们在这里强调了关键步骤,但所有步骤都记录在 Jupyter 笔记本中。

选择模型拓扑
选择为该笔记本列出的任何一种可用型号。每个笔记本都有该域的默认模型。在此示例中,默认模型为 DetectNet V2 ,但您可以将其更改为 FasterRCNN 、 SSD 、 DSSD 、 Retinanet 、 EfficientDet 、 Yolo V3 、 Yolo V4 或 YoloV4 tiny 。
model_name = "detectnet-v2"
创建数据集
下一步是使用笔记本中给出的数据集作为示例,或者使用自己的数据集。笔记本中提供了数据集要求的文件夹结构。
train_dataset_id = subprocess.getoutput(f"tao-client {model_name} dataset-create --dataset_type object_detection --dataset_format {ds_format}")
print(train_dataset_id)
eval_dataset_id = subprocess.getoutput(f"tao-client {model_name} dataset-create --dataset_type object_detection --dataset_format {ds_format}")
print(eval_dataset_id)
上载数据集
准备好数据集后,通过用于 TAO 客户端笔记本的 Unix rsync命令将其上载到 TAO Toolkit REST API 部署的计算机。您必须上传培训和验证数据的图像和标签。
rsync -ah --info=progress2 {TRAIN_DATA_DIR}/images ~/shared/users/{os.environ['USER']}/datasets/{train_dataset_id}/
rsync -ah --info=progress2 {TRAIN_DATA_DIR}/labels ~/shared/users/{os.environ['USER']}/datasets/{train_dataset_id}/
rsync -ah --info=progress2 {VAL_DATA_DIR}/images ~/shared/users/{os.environ['USER']}/datasets/{eval_dataset_id}/
rsync -ah --info=progress2 {VAL_DATA_DIR}/labels ~/shared/users/{os.environ['USER']}/datasets/{eval_dataset_id}/
转换数据集
上传数据集后,通过数据集转换操作将数据集转换为tfrecords。所有对象检测模型都需要数据集转换,但其他领域的一些模型(如分类)可以对上传的原始数据进行操作。
train_convert_job_id = subprocess.getoutput(f"tao-client {model_name} dataset-convert --id {train_dataset_id} --action {convert_action} ")
配置 AutoML 参数
下一步是选择要运行的 AutoML 算法。有一些选项可以调整某些特定于 AutoML 的参数。您可以查看默认情况下为模型的 AutoML 搜索启用的参数,以及网络可用的所有参数
tao-client {model_name} model-automl-defaults --id {model_id} | tee ~/shared/users/{os.environ['USER']}/models/{model_id}/specs/automl_defaults.json
这将输出用于 AutoML 的超参数列表。对于这个实验,您选择了五个不同的超参数来扫描。
[ "bbox_rasterizer_config.deadzone_radius", "training_config.learning_rate.soft_start_annealing_schedule.min_learning_rate", "training_config.learning_rate.soft_start_annealing_schedule.annealing", "training_config.regularizer.type", "classwise_config.postprocessing_config.clustering_config.dbscan_confidence_threshold" ]
您可以添加其他参数或删除现有的默认参数。例如,要扫描soft_start超参数,请在笔记本中添加以下内容:
additional_automl_parameters = [“training_config.learning_rate.soft_start_annealing_schedule.soft_start”]
也有调整算法特定参数的选项,但默认参数工作正常。有关详细信息,请参见 AutoML 。
使用 AutoML 训练
此时,您已经拥有启动 AutoML 运行所需的所有工具。您还可以在触发 AutoML 运行之前更改默认训练规范,如图像扩展或类映射:
train_job_id = subprocess.getoutput(f"tao-client {model_name} model-train --id " + model_id)
当 AutoML 运行开始时,您可以看到各种统计数据,例如当时的最佳准确度分数、已完成的实验数量、估计完成时间等。您应该看到类似于以下内容的输出日志。
{
"best_map": 0.59636,
"Estimated time for automl completion": "23.13 minutes remaining approximately",
"Current experiment number": 3,
"Number of epochs yet to start": 429.0,
"Time per epoch in seconds": 3.24
}
比较模型
在 AutoML 运行结束时,您可以看到所有实验的结果。您将看到在 AutoML 扫描中实现最高精度的模型的等级库文件和二进制权重文件。
Checkpoints for the best performing experiment
Folder: /home/nvidia/shared/users/95af85a9-805c-5680-b01a-3c85ed70f009/models/4f22c462-1d97-4537-99b2-15ee69eb2660/168d6149-6c47-40e6-b6a3-267867cea551/best_model/weights
Files: [epoch-80.tlt']
Results of all experiments
id result
0 0 0.43636
1 1 0.41818
2 2 0.53636
3 3 0.44545
4 4 0.33636
5 5 0.44545
6 6 0.53636
7 7 0.53636
8 8 0.61636
9 9 0.62727
10 10 0.593636
11 11 0.52727
12 12 0.53636
13 13 0.54545
14 14 0.61636
15 15 0.60909
16 16 0.5636
17 17 0.54545
18 18 0.53636
19 19 0.53636
最佳实验的规范文件存储在以下目录中:
{home}/shared/users/{os.environ['USER']}/models/{model_id}/{train_job_id}/{automl_job_dir}/best_model
该实验的最佳模型是 mAP 为 0.627 的 ID 9 。这存储在best_model/recommendataion_9.kitti文件中。
保存从 AutoML 获得的最佳模型后,您可以将模型和规范文件插入到端到端笔记本中,然后修剪和优化模型以进行推断。
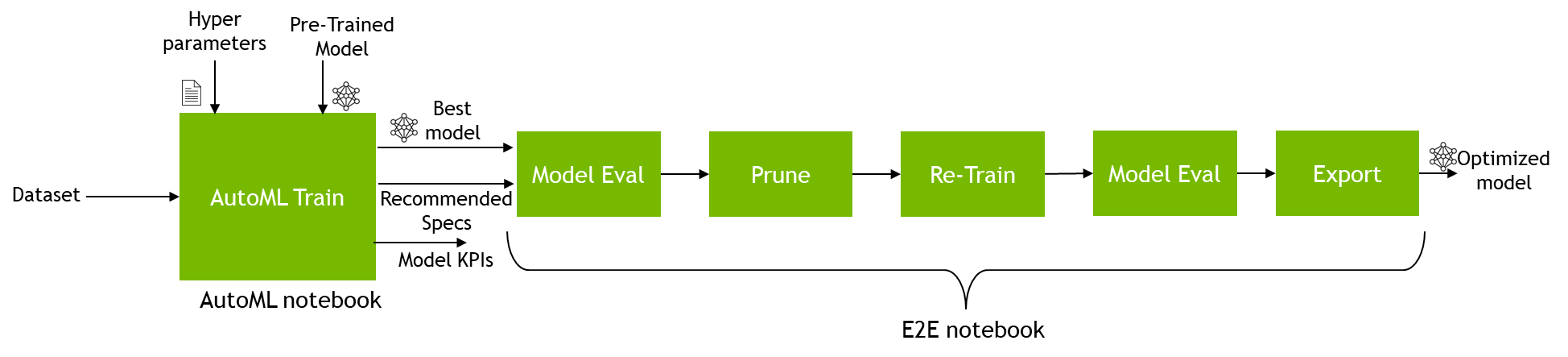
要将模型插入新笔记本,请从 AutoML 笔记本复制列车作业 ID 。运行培训作业时会打印 AutoML 培训作业 ID 。
train_job_id = subprocess.getoutput(f"tao-client {model_name} model-train --id " + model_id)
print(train_job_id)
当您具有培训作业 ID 时,请从前面的笔记本层次结构中打开端到端笔记本。对于这篇文章,请使用TAO API Starter Kit/Notebooks/client/end2end/detectnet_v2.ipynb笔记本。由于您已经训练了一个模型,只需在第一个单元格中运行import语句,然后一直跳到Run Evaluate部分。在本节中,在计算之前创建一个代码单元。
train_job_id = “id_you_copied”
在添加job_map代码单元后,您可以评估模型,修剪模型以进行压缩,甚至可以对原始模型或修剪后的模型进行量化感知训练,如端到端笔记本中所示
后果
我们在公共数据集上使用 AutoML 训练了各种模型,以了解我们可以在准确性方面提高多少。我们将基于 AutoML 的最佳精度与包中提供的默认规范文件中的基线精度数字进行了比较。结果见表 2 。
- 对于物体检测,我们在 FLIR dataset 上进行了训练,其中包含来自热传感器和 RGB 传感器的图像。
- 对于图像分类,我们使用 Pascal VOC 20 12 Dataset 。
- 对于语义分割,我们使用 ISBI dataset 。
为了准确度,我们使用 mAP (平均平均精度)进行对象检测,使用所有类别和任务的平均精度进行图像分类,使用平均 IoU (交集加联合)得分进行语义分割。
| Task | Model | Baseline Accuracy (default spec) |
Best AutoML accuracy | Dataset |
| Object Detection | DetectNet_v2 – ResNet18 | 44.16 | 51.37 | FLIR |
| Object Detection | FasterRCNN – ResNet18 | 56.42 | 60.44 | FLIR |
| Object Detection | YOLOv4 – ResNet18 | 40.12 | 63.46 | FLIR |
| Object Detection | YOLOv3 – ResNet18 | 42.36 | 61.84 | FLIR |
| Object Detection | RetinaNet – ResNet18 | 50.54 | 63.09 | FLIR |
| Image Classification | ResNet18 | 53.95 | 66.28 | Pascal VOC |
| Semantic Segmentation | UNET | 71.64 | 76.65 | ISBI |
在我们测试的所有模型中,与静态默认超参数相比,模型精度的提高是显著的。改进的程度因模型而异,但我们通常看到 5% 到 20% 以上的改进。这表明 AutoML 可以在各种数据集上工作,以训练给定 KPI 的最佳模型。
总结
随着用例和定制数量的增长,加快人工智能创建过程变得势在必行。 AutoML 可以消除手动调优的需要,为开发人员节省宝贵的时间。
有了 TAO AutoML ,您现在可以使用各种流行的模型架构自动调整模型以用于对象检测、分类和分割用例。 TAO AutoML 为新手用户入门提供了简单性,也为专家选择自己的超参数进行扫描提供了可配置性。




