
数据是企业能够拥有的最有价值的资产之一。它是数据科学和数据分析的核心:没有数据,它们都是过时的。积极收集数据的企业可能比不收集数据的公司具有竞争优势。有了足够的数据,组织可以更好地确定问题的原因并做出明智的决定。
在某些情况下,组织可能缺乏足够的数据来得出必要的见解。例如,初创企业几乎总是在没有数据的情况下开始。与其抱怨他们的不足,更好的解决方案是使用数据采集技术来帮助构建定制数据库。
这篇文章介绍了一种流行的数据采集技术,称为网络抓取。您可以使用 kurtispykes/web-scraping-real-estate-data GitHub 存储库中的代码进行后续操作。
什么是数据采集?
Data acquisition (也称为 DAQ )可能与技术人员记录烤箱温度一样简单。您可以将 DAQ 定义为对测量真实世界物理现象的信号进行采样,并将生成的样本转换为计算机可以解释的数字数值的过程。
在一个理想的世界里,我们将把所有的数据都交给我们,随时可以使用。然而,世界远非理想。数据采集技术之所以存在,是因为某些问题需要特定的数据,而您在特定时间可能无法访问这些数据。在进行任何数据分析之前,数据团队必须有足够的可用数据。一种获取数据的技术是 web scraping 。
什么是网页刮取?
Web 抓取是一种流行的数据采集技术,在那些对大数据需求不断增长的人中,它已成为讨论的热门话题。从本质上讲,这是一个从互联网中提取信息并将其格式化以便于在数据分析和数据科学管道中使用的过程。
在过去,网页抓取是一个手动过程。这个过程既乏味又耗时,而且人类容易出错。最常见的解决方案是自动化。 web 刮取的自动化使您能够加快流程,同时节省资金并减少人为错误的可能性。
然而,网络抓取也有其挑战。
刮网的挑战
除了知道如何编程和理解 HTML 之外,构建自己的 web scraper 还有很多挑战。提前了解数据收集过程中可能遇到的各种障碍是有益的。以下是从 web 上抓取数据时面临的一些最常见的挑战。
robots.txt
抓取数据的权限通常保存在 robots.txt 文件中。此文件用于通知爬网程序可在网站上访问的 URL 。它可以防止站点被请求过载。
在开始网页抓取项目之前,首先要检查的是目标网站是否允许网页抓取。网站可以决定是否允许在其网站上使用刮片器进行刮片。
有些网站不允许自动抓取网页,这通常是为了防止竞争对手获得竞争优势,并从目标站点中耗尽服务器资源。它确实会影响网站的性能。
您可以通过将 /robots.txt 附加到域名来检查网站的 robots.txt 文件。例如,检查 Twitter 的 robots.txt 如下: www.twitter.com/robots.txt 。
结构变化
UI 和 UX 开发人员定期对网站进行添加、删除和定期结构更改,以使其跟上最新进展。 Web scraper 依赖于构建 scraper 时网页的代码元素。因此,频繁更改网站可能会导致数据丢失。随时关注网页的更改总是一个好主意。
此外,考虑到不同的网页设计者在设计网页时可能有不同的标准。这意味着,如果你计划抓取多个网站,你可能需要构建多个抓取器,每个网站一个。
IP 拦截器,或被禁止
它有可能被禁止进入网站。如果你的网络爬虫向某个网站发送的请求数量非常高,那么你的 IP 地址可能会被禁止。或者,网站可能会限制其访问,以打破刮取过程。
在被认为是道德的和不道德的网络抓取之间有一条细线:越过这条线很快就会导致 IP 屏蔽。
验证码
CAPTCHA (完全自动化的公共图灵测试,以区分计算机和人类)正是它的名字所说的:区分人类和机器人。验证码所带来的问题对于人类来说通常是合乎逻辑的、简单明了的,但对于机器人来说,要完成同样的任务是很有挑战性的,这可以防止网站被垃圾邮件攻击。
使用 CAPTCHA 抓取网站有一些合乎道德的解决方法。然而,这一讨论超出了本文的范围。
蜜罐陷阱
类似于你如何设置设备或外壳来捕捉入侵你家的害虫,网站所有者设置蜜罐陷阱来捕捉刮器。这些陷阱通常是人类看不到的链接,但对网络爬虫来说是可见的。
其目的是获取有关刮板的信息,例如其 IP 地址,以便他们阻止刮板访问网站。
实时数据抓取
在某些情况下,您可能需要实时丢弃数据(例如,价格比较)。由于更改随时可能发生,因此刮取器必须不断监控网站并刮取数据。实时获取大量数据具有挑战性。
Web 抓取最佳实践
现在,您已经意识到可能面临的挑战,了解最佳实践以确保您在道德上收集网络数据非常重要。
尊重 robots.txt
在抓取 web 数据时,您将面临的一个挑战是遵守 robots.txt 的条款。遵循网站设置的关于 web 抓取可以抓取和不能抓取的指南是最佳做法。
如果一个网站不允许网络抓取,那么抓取该网站是不道德的。最好找到另一个数据源,或者直接联系网站所有者,讨论解决方案。
善待服务器
Web 服务器只能承受这么多。超过 web 服务器的负载会导致服务器崩溃。考虑向主机服务器发出请求的可接受频率。短时间内的几个请求可能会导致服务器故障,进而破坏网站其他访问者的用户体验。
保持请求之间的合理时间间隔,并考虑并行请求的数量。
非高峰时段刮水
了解一个网站什么时候可能会收到最多的流量,并避免在这段时间内进行抓取。您的目标是不妨碍其他访问者的用户体验。当一个网站收到的流量减少时,你的道德责任是刮一刮。(这也对您有利,因为它显著提高了刮板的速度。)
剪贴画教程
Python 中的 Web 抓取通常涉及从零开始编写几个低级任务。然而, Scrapy ,一个开源的网络爬行框架,默认情况下处理几个常见的启动需求。这意味着您可以专注于从目标网站中提取所需的数据。
为了展示 Scrapy 的威力,您开发了一个 spider ,这是一个 Scrapy 类,您可以在其中定义刮网器的行为。使用这个蜘蛛从 Boston Realty Advisors 网站上抓取所有列表(图 1 )。
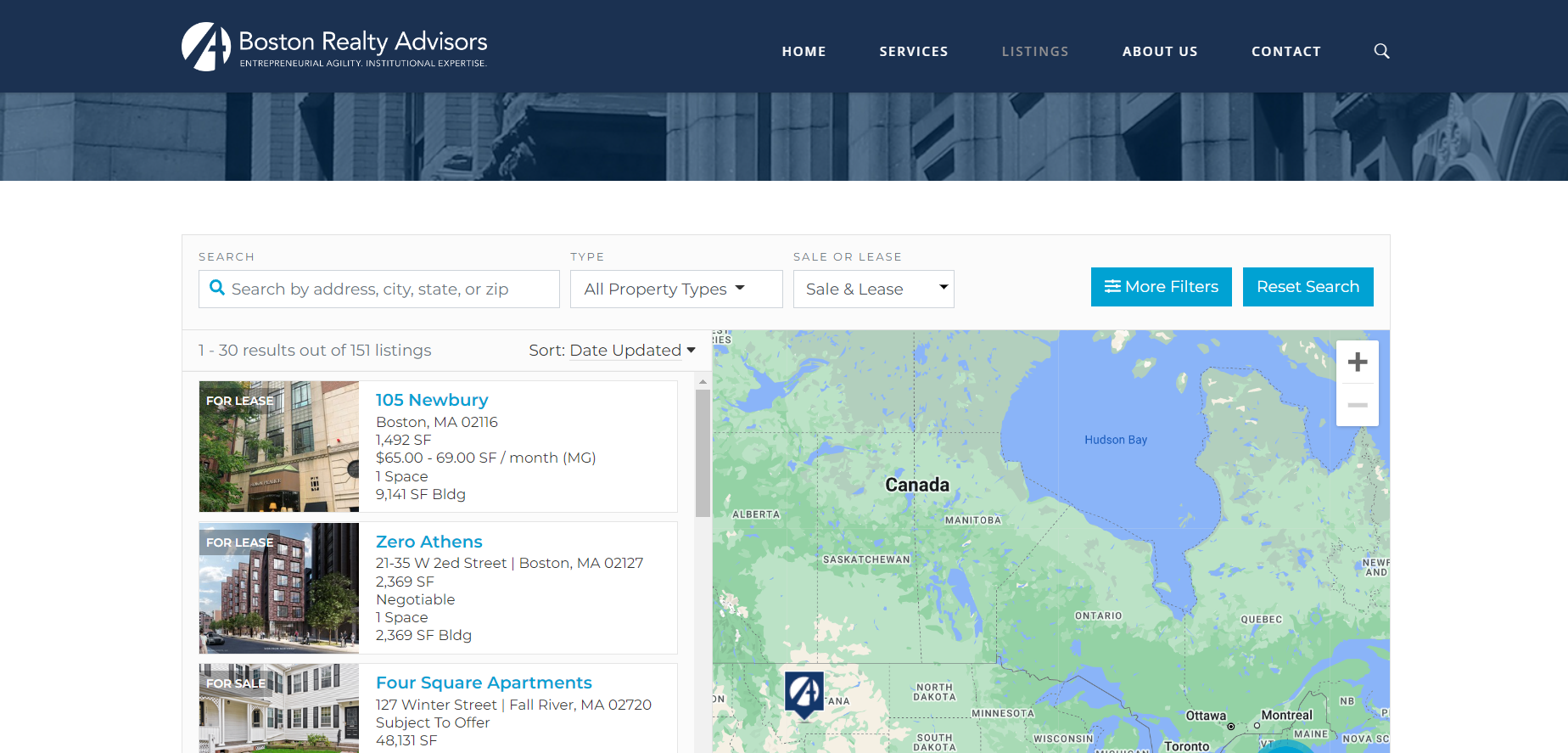
检查目标网站
在开始任何 web 刮取项目之前,检查目标网站以进行刮取非常重要。在检查网站时,我喜欢检查的第一件事是页面是静态的还是由 JavaScript 生成的。
要打开开发人员工具箱,请按 F12 。在 Network 选项卡上,确保选中 Disable cache 。
要打开命令选项板,请按 CTRL + SHIFT + P ( Windows \ Linux )或 command + SHIFT-P ( Mac )。键入 Disable JavaScript ,然后按 Enter 键并重新加载目标网站。
图 2 显示了没有 JavaScript 的 Boston Realty Advisors 网站的外观。
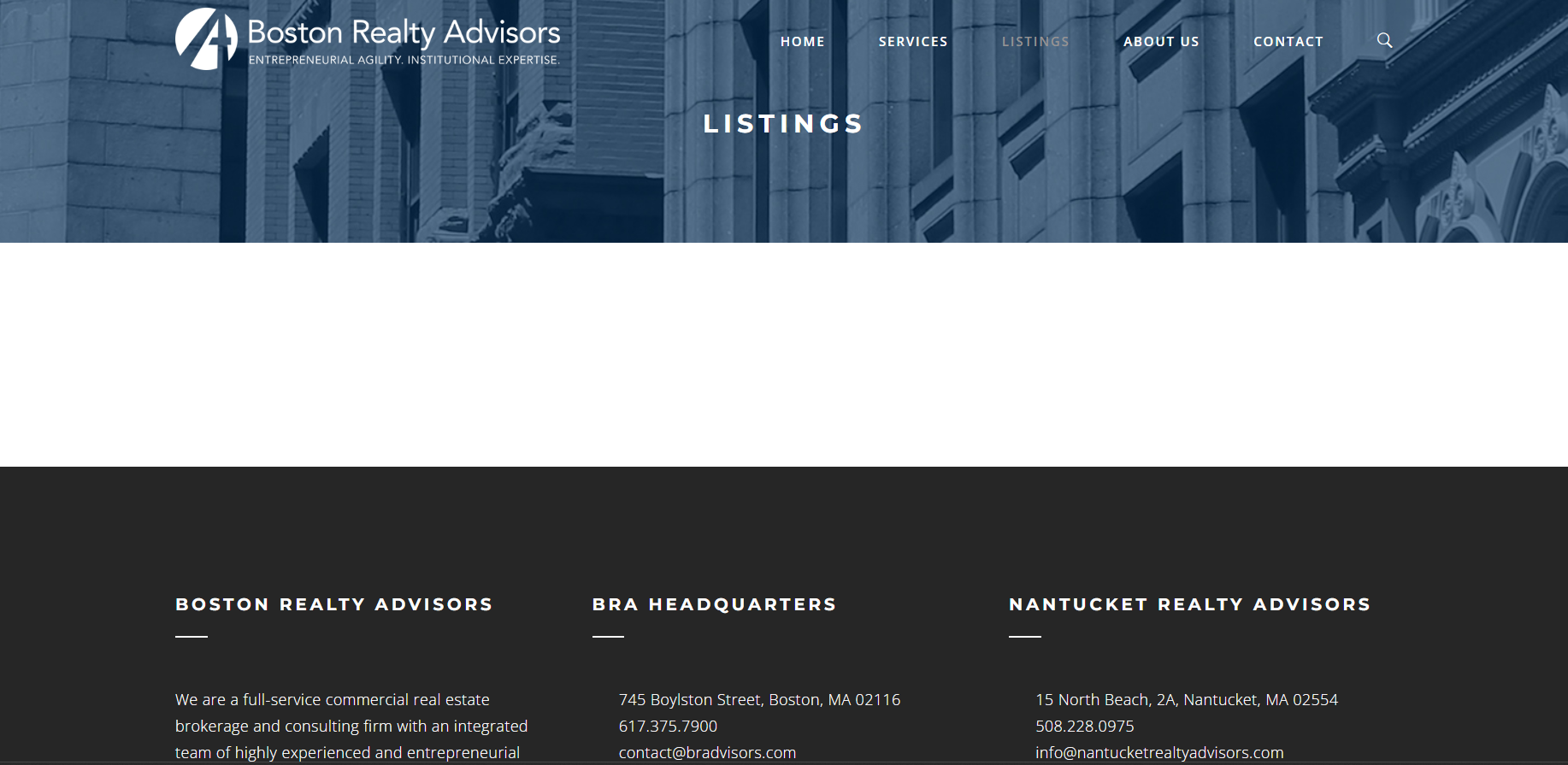
空页面告诉您目标网页是使用 JavaScript 生成的。您无法通过解析开发者工具箱 Elements 选项卡中显示的 HTML 元素来抓取页面。在开发人员工具中重新启用 JavaScript 并重新加载页面。
还有更多要检查的。
I 在开发人员工具箱中,选择 XHR ( XMLHTTPRequest )选项卡。浏览发送到服务器的请求后,我注意到一些有趣的事情。有两个请求称为“ inventory ”,但在一个请求中,您可以访问 JSON 中第一页上的所有数据。
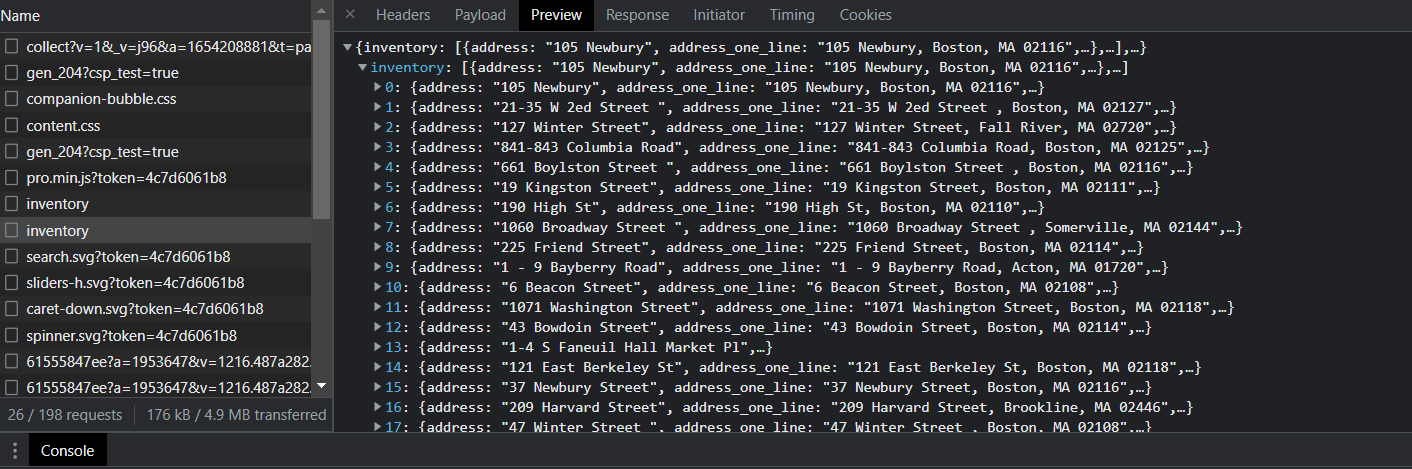
这一信息非常有用,因为这意味着您不必访问波士顿房地产顾问网站上的主列表页面即可获取所需的数据。
现在你可以开始刮了。(我做了更多的检查,以更好地理解如何模拟向服务器发出的请求,但这超出了本文的范围。)
创建报废项目
要设置 Scrapy 项目,首先安装scrapy。我建议在 virtual environment 中执行此步骤。
pip install scrapy
激活虚拟环境后,输入以下命令:
scrapy startproject bradvisors
该命令创建一个名为bradvisors的 Scrapy 项目。 Scrapy 还会自动将一些文件添加到目录中。
运行命令后,最终目录结构如下所示:
. └── bradvisors ├── bradvisors │ ├── __init__.py │ ├── items.py │ ├── middlewares.py │ ├── pipelines.py │ ├── settings.py │ └── spiders │ └── __init__.py └── scrapy.cfg
到目前为止,您已经检查了网站的元素,并创建了 Scrapy 项目。
构建蜘蛛
蜘蛛模块必须构建在bradvisors/bradvisors/spiders目录中。我的蜘蛛脚本的名称是bradvisors_spider.py,但您可以使用自定义名称。
以下代码从该网站中提取数据。代码示例仅在items.py文件更新时成功运行。有关详细信息,请参阅示例后的说明。
import json
import scrapy
from bradvisors.items import BradvisorsItem
class BradvisorsSpider(scrapy.Spider):
name = "bradvisors"
start_urls = ["https://bradvisors.com/listings/"]
url = "https://buildout.com/plugins/5339d012fdb9c122b1ab2f0ed59a55ac0327fd5f/inventory"
headers = {
'authority': 'buildout.com',
'accept': 'application/json, text/javascript, */*; q=0.01',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',
'cache-control': 'no-cache',
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'origin': 'https://buildout.com',
'pragma': 'no-cache',
'referer': 'https://buildout.com/plugins/5339d012fdb9c122b1ab2f0ed59a55ac0327fd5f/bradvisors.com/inventory/?pluginId=0&iframe=true&embedded=true&cacheSearch=true&=undefined',
'sec-ch-ua': '"Google Chrome";v="105", "Not)A;Brand";v="8", "Chromium";v="105"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'x-newrelic-id': 'Vg4GU1RRGwIJUVJUAwY=',
'x-requested-with': 'XMLHttpRequest'
}
def parse(self, response):
url = "https://buildout.com/plugins/5339d012fdb9c122b1ab2f0ed59a55ac0327fd5f/inventory"
# There are 5 pages on the website
for i in range(5):
# Change the page number in the payload
payload = f"utf8=%E2%9C%93&polygon_geojson=&lat_min=&lat_max=&lng_min=&lng_max=&mobile_lat_min=\
&mobile_lat_max=&mobile_lng_min=&mobile_lng_max=&page={str(i)}&map_display_limit=500&map_type=roadmap\
&custom_map_marker_url=%2F%2Fs3.amazonaws.com%2Fbuildout-production%2Fbrandings%2F7242%2Fprofile_photo\
%2Fsmall.png%3F1607371909&use_marker_clusterer=true&placesAutoComplete=&q%5Btype_use_offset_eq_any%5D%5B%5D=\
&q%5Bsale_or_lease_eq%5D=&q%5Bbuilding_size_sf_gteq%5D=&q%5Bbuilding_size_sf_lteq%5D=&q%5B\
listings_data_max_space_available_on_market_gteq%5D=&q%5Blistings_data_min_space_available_on_market_lteq\
%5D=&q%5Bproperty_research_property_year_built_gteq%5D=&q%5Bproperty_research_property_year_built_lteq\
%5D=&q%5Bproperty_use_id_eq_any%5D%5B%5D=&q%5Bcompany_office_id_eq_any%5D%5B%5D=&q%5Bs%5D%5B%5D="
# Crawl the data, given the payload
yield scrapy.Request(method="POST", body=payload, url=url, headers=self.headers, callback=self.parse_api)
def parse_api(self, response):
# Response is json, use loads to convert it into Python dictionary
data = json.loads(response.body)
# Our item object defined in items.py
item = BradvisorsItem()
for listing in data["inventory"]:
item["address"] = listing["address_one_line"]
item["city"] = listing["city"]
item["city_state"] = listing["city_state"]
item["zip"] = listing["zip"]
item["description"] = listing["description"]
item["size_summary"] = listing["size_summary"]
item["item_url"] = listing["show_link"]
item["property_sub_type_name"] = listing["property_sub_type_name"]
item["sale"] = listing["sale"]
item["sublease"] = listing["sublease"]
yield item
该代码完成以下任务:
- 将刮刀的名称定义为
bradvisors。 - 定义随请求传递的标头。
- 指定
parse方法是刮板运行时的自动回调。 - 定义
parse方法,在该方法中,您遍历要抓取的页数,将页码传递给有效负载,并生成该请求。这会在每次迭代时调用parse_api方法。 - 定义
parse_api方法并将有效的 JSON 响应转换为 Python 字典。 - 在
items.py中定义BradvisorsItem类(下一个代码示例)。 - 循环遍历库存中的所有列表并抓取特定元素。
# items.py import scrapy class BradvisorsItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() address = scrapy.Field() city = scrapy.Field() city_state = scrapy.Field() zip = scrapy.Field() description = scrapy.Field() size_summary = scrapy.Field() item_url = scrapy.Field() property_sub_type_name = scrapy.Field() sale = scrapy.Field()
接下来,必须执行刮取以解析数据。
运行铲运机
从命令行导航到项目的根目录(在本例中为bradvisors)。运行以下命令:
scrapy crawl bradvisors -o data.csv
该命令将抓取 Boston Realty Advisors 网站,并将提取的数据保存在项目根目录的data.csv文件中。
太好了,您现在已经获得了房地产数据!
接下来是什么?
随着对大数据需求的增长,让自己具备使用网络抓取工具获取数据的能力是一项非常有价值的技能。从互联网上删除数据可能会带来一些挑战。除了获取所需的数据外,您的目标还应该是尊重网站,并以道德的方式收集网站。
你觉得这个剪贴画教程有用吗?在评论中留下您的反馈或与我联系:
Web 抓取常见问题解答
网络抓取是非法的吗?
不,网络抓取是合法的,因为你抓取的数据是公开的。谷歌( Google )等搜索引擎每天收集网络数据,为用户整理搜索结果。
网页刮取免费吗?
您可以为 web 刮取服务付费,以简化 web 刮取过程。你也可以免费学习编程语言并自己动手。
我可以使用哪些工具在 Python 中进行 web 抓取?
Python 中有几种用于 web 抓取的工具,如 Beautiful Soup 、 MechanicalSoup 、 Requests ( Python 模块)、 Scrapy 、 Selenium 和 Urllib 。




