介绍
用于Apache Spark 的 RAPIDS 加速器 8 月版( 21.08 )现已发布。。自 NVIDIA GTC 2020 首次发布以来,已经有一年多的时间了。我们在许多方面都有所改进,特别是在易用性方面, Apache Spark 应用程序的代码更改很少甚至没有。去年,该团队一直专注于添加功能和持续改进性能。为了证明这一点,我们使用 NVIDIA 数据科学( NDS )基准测试了定期测量在 3000 ( 3 TB 未压缩)的比例因子下的性能和功能。在此版本中,除了添加新功能外,我们非常自豪地在提高所有通过查询的端到端速度和降低 NVIDIA EGX 服务器的总体拥有成本方面取得了进展。
基准更新
NVIDIA 决策支持( NDS )是我们对 Apache Spark 社区常用的行业标准数据科学基准的改编。 NDS 包含与行业标准基准测试 TPC-DS 相同的 105 个 SQL 查询,但修改了数据集生成和执行脚本的部分。在 GTC 2021 更新中,有 95 个查询通过。在 21 . 08 版本中,通过核心外分组方式、窗口排名和密集排名等新功能,我们已经能够在 GPU 上运行所有 105 个查询。
基准设置
- 比例因子 -3K (带浮点数的 3TB 数据集)
- Systems: 4x NVIDIA 认证 EGX 服务器
- EGX 服务器硬件规格: 4-node Dell R740xd, each with (2) 24-core CPUs, 512GB RAM, HDFS on NVMe, (1) CX-6 Dx 25/100Gb NIC, 2x NVIDIA A30 GPU
- CPU 硬件规格: 4-node dell r740xd , each with ( 2 ) 24-core CPU s , 512GB ram , hdfs on nvme ,( 1 ) cx-6 dx 25 / 100gb nic
- 软件: RAPIDS 加速器 v21 . 08 . 0 、 cuDF 21 . 08 . 0 、 Apache Spark 3 . 1 . 1 、 UCX 1 . 10 . 1
结果摘要
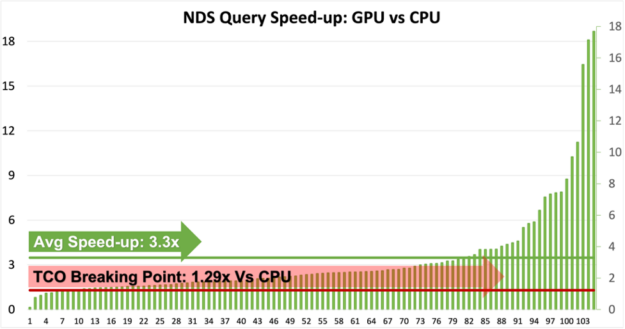
基于此版本,我们很高兴地向大家展示,所有 105 个查询现在都可以在 GPU 上运行,而无需任何代码更改。
- 用于这些基准测试的基准服务器对于四台没有 GPU s 的服务器的成本略低于 170000 美元,而在每台服务器中包含一台 NVIDIA A100 GPU 的成本则低于 220000 美元。
- 简单来说,基准 GPU 服务器的成本是 CPU 服务器的 1 . 29 倍。
- 如上图所示(图 1 ),超过 95 个查询现在比 GPU 快 1 . 29 倍,因此运行起来更便宜。
- GPU 上一些速度较慢的查询目前正在解决中,我们正在不懈地努力改进这些查询并提高总体速度。
- 用户可以很容易地推断出 GPU 的加速从 1x 到 18x 不等,因此建议用户确认 GPU 的正确用例。
- 如果用户不确定 GPU 的正确用例,鉴定工具将是一个方便的资产。有关鉴定工具的更多信息,请参阅以下章节。
分析和鉴定工具
分析与鉴定工具于 21 . 06 发布,获得了用户社区的积极反馈以及对新功能的要求。在 21 . 08 中,鉴定工具现在能够处理 Apache Spark 2 . x 版本生成的事件日志。该工具还将支持 AWS EMR 6 . 3 . 0 、 Google Dataproc 2 . 0 、 Microsoft Azure Synapse 以及 DataRicks 7 . 3 和 8 . 2 运行时生成的事件日志。鉴定工具不再需要 Spark 运行时。用户现在只需在机器上使用 Apache Spark 3 . x JAR 即可使用鉴定工具。最新版本还具有选择事件日志的新过滤功能。该工具还查找插件不支持的读取数据格式和类型,并从分数中删除这些格式和类型(基于 SQL Dataframe 操作中的总任务时间)。输出将以简洁的格式报告在终端上,对每个已处理事件日志的详细分析将存储为 csv 输出。
新功能
此版本为数组和结构添加了更多功能。我们现在可以对多层结构数据类型进行联合,也可以以拼花格式编写数组数据类型。我们在现有的超前、滞后和行号功能中添加了秩和密集秩窗口功能。有了这一新增功能, RAPIDS 加速器现在可以支持 SQL 中最常用的窗口运算符。对于时间戳操作符,我们添加了对遗留时间戳的支持。使用此功能,用户可以读取 Spark 2 . 0 中支持的传统时间戳格式。对于 Databricks 用户,我们添加了在 GPU 中缓存数据的功能(所有其他平台都支持这种功能)。
我们通过处理 GPU 内存溢出的数据集以进行分组和窗口操作,继续改善用户体验。这一改进将节省用户创建分区的时间,以避免 GPU 上出现内存不足错误。类似地, UCX 1 . 11 的采用改进了 RAPIDS Spark 加速洗牌管理器的错误处理。
成长社区
加入我们“使用 NVIDIA RAPIDS 加速器为 Spark 加速数据管道”了解 Informatica 如何消除使用 GPU 的障碍,在大规模运营机器学习项目时实现显著的性能改进。您可以阅读有关网上研讨会和在这里注册的更多信息。
马上就来
正如我们在上一个版本中所指出的,自最新版本( 21.06 ).发布以来,我们已经发布了搬到卡尔弗和每两个月发布一次的 cadence 。即将发布的版本将添加对其他十进制类型的扩展支持,并继续添加对多级结构和映射的更多嵌套数据类型支持。此外,请留意带有代码示例和笔记本的微型基准测试,它们将突出显示最适合 GPU 的操作。我们想听听你和用户的意见。请在GitHub上与我们联系,让我们知道我们如何使用 RAPIDS Spark 继续改进您的体验。