
NVIDIA Nsight Systems 是一个综合工具,用于跨 CPU 和 GPU 资源跟踪应用程序性能。它可以帮助确保硬件得到有效使用,跟踪 API 调用,并通过描述低级指标与应用程序性能的总和以及可以改进的地方,深入了解节点间网络通信。
Nsight 系统可以扩展到集群大小的问题,比如 multi-node analysis,但当您刚刚开始优化之旅时,它也可以用于发现简单的性能改进。例如,Nsight Systems 可以用来查看哪里的内存传输比预期的更昂贵。通过快速查看内存活动,可以发现并关联性能损失,并建议如何解决这些损失。
在这篇深入的文章中,我来看看 GROMACS 2019 和 GROMACS 2020 之间的变化。我与 Nsight Systems 一步一步地寻找前一版本中的 GPU 和内存优化机会,并研究它们在新版本中是如何解决的。
GROMACS 2019
GROMACS 是一个通用且广泛使用的软件包,用于生物分子(如蛋白质、脂质和核酸)的分子动力学( MD )模拟。它可以帮助研究人员检查疾病预防和治疗的重要生物过程。
我在带有 NVIDIA Volta GPU 的 Arm 服务器系统上使用 Nsight Systems 分析了 GROMACS 2019 。 Nsight Systems 包括一个用户界面和一个 CLI ,称为nsys.
运行以下命令 nsys 以收集没有 CPU 采样的 CUDA 和 NVTX 的跟踪信息。它可以用于从目标 Arm 服务器收集性能数据,然后可以在 Nsight Systems 用户界面中像往常一样进行分析。更多关于 nsys 和配置文件选项的信息,请参阅 单条命令行示例。
nsys profile -t cuda,nvtx -s none gmx mdrun -dlb no -notunepme -noconfout -nsteps 3000
图 1 显示了执行该命令并打开报告文件。
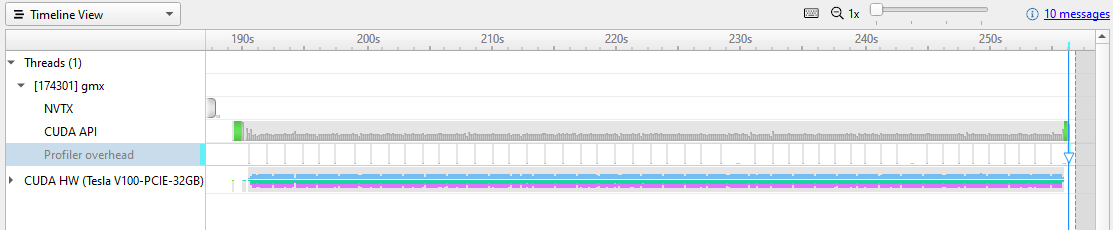
Nsight Systems 使用细节级别( LOD )缩放来显示时间轴上每个像素下的 GPU 使用量。然而,在这种缩放级别上,数据过于密集,无法看到真实的图案。放大显示 Nsight Systems 捕获的内容的粒度。
同样,也有关于 GPU 活动的信息,但详细信息是在下拉列表下组织的。展开 GPU 行以显示有关流和上下文的信息。
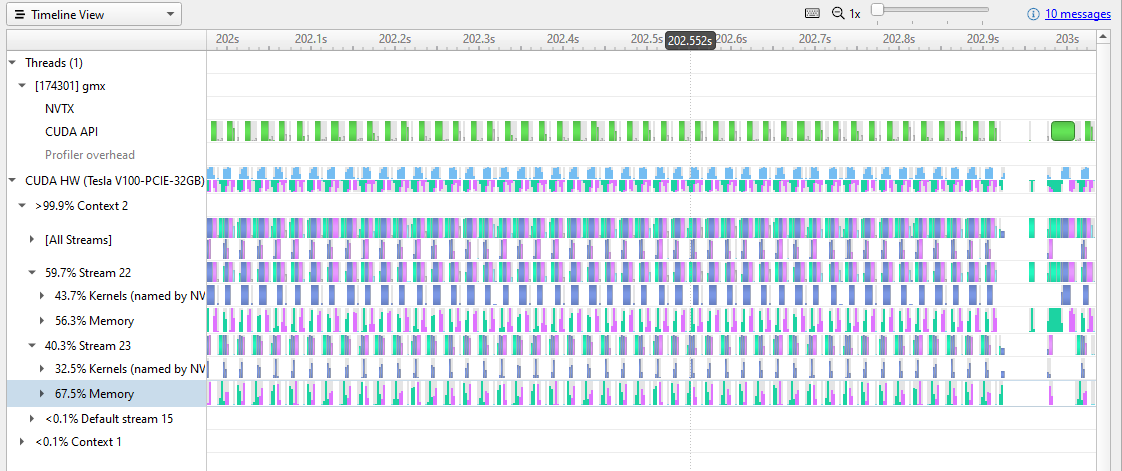
在图 2 中,您可以开始看到 GPU 上内存传输和内核活动的重复模式。重复模式是正常的,但你也可以看到很多时间都花在了内存转移上。 GPU 活动中存在差距,表明存在改进的机会。
图 3 进一步放大到 0 . 1 秒的时钟时间。
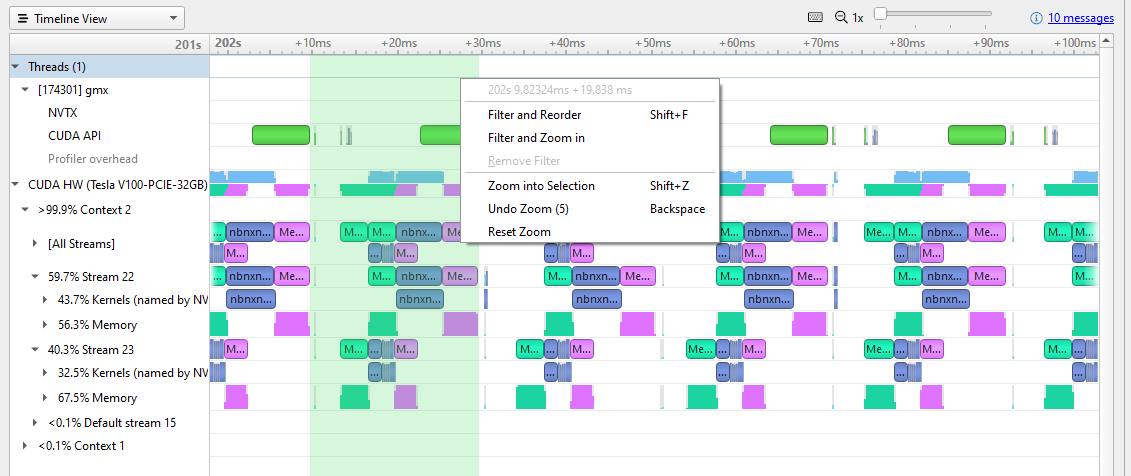
在这个分辨率下,您可以清楚地看到 GPU 上的活动模式。在每次重复中,都会有一个主机到设备的内存传输(绿色),一些内核工作(蓝色),然后是一个内存传输回主机(品红色)。您还可以看到每个内核运行后、新内存传输开始前的暂停。
图 3 显示了从上一次设备主机传输结束到本次迭代的设备主机传输(选择标记为绿色)结束的单次迭代中的移位拖动。右键单击此处将显示菜单,您可以放大以隔离此迭代。
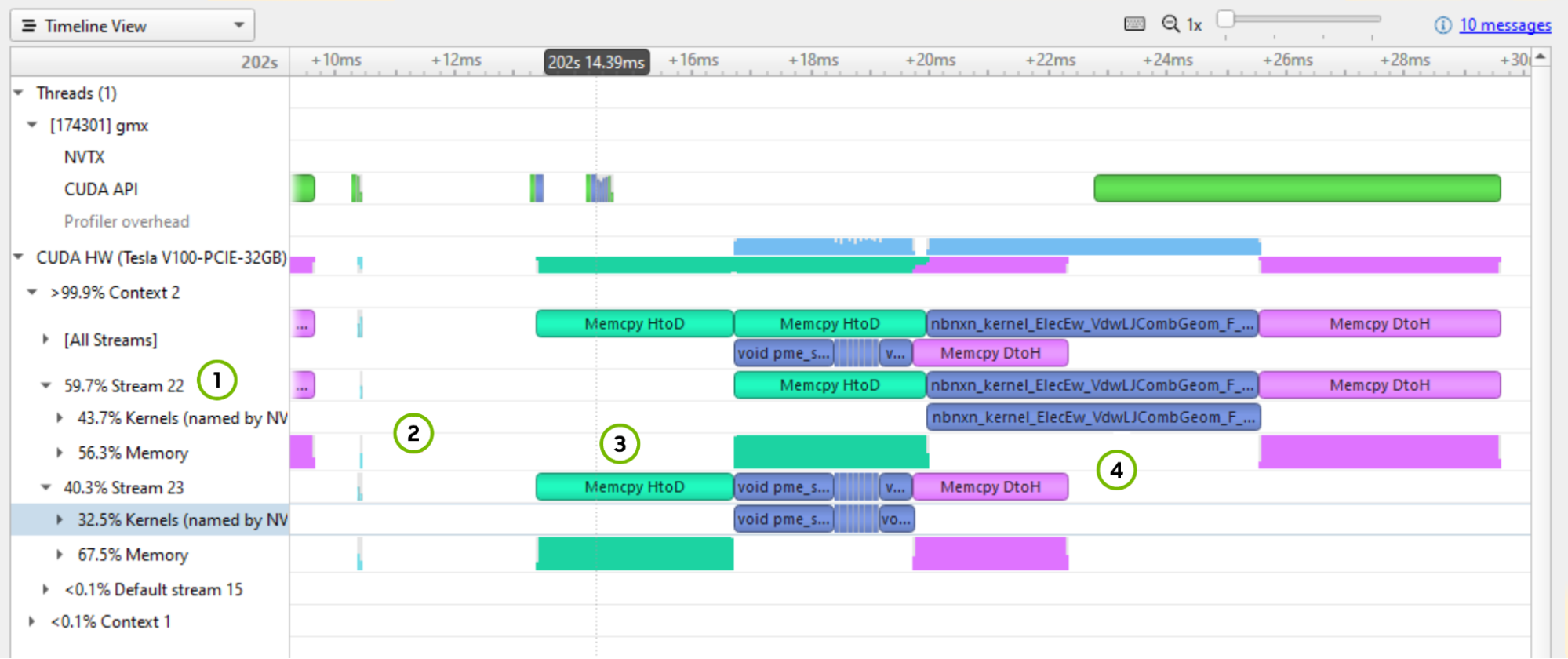
在图 4 上标记的几件事需要指出:
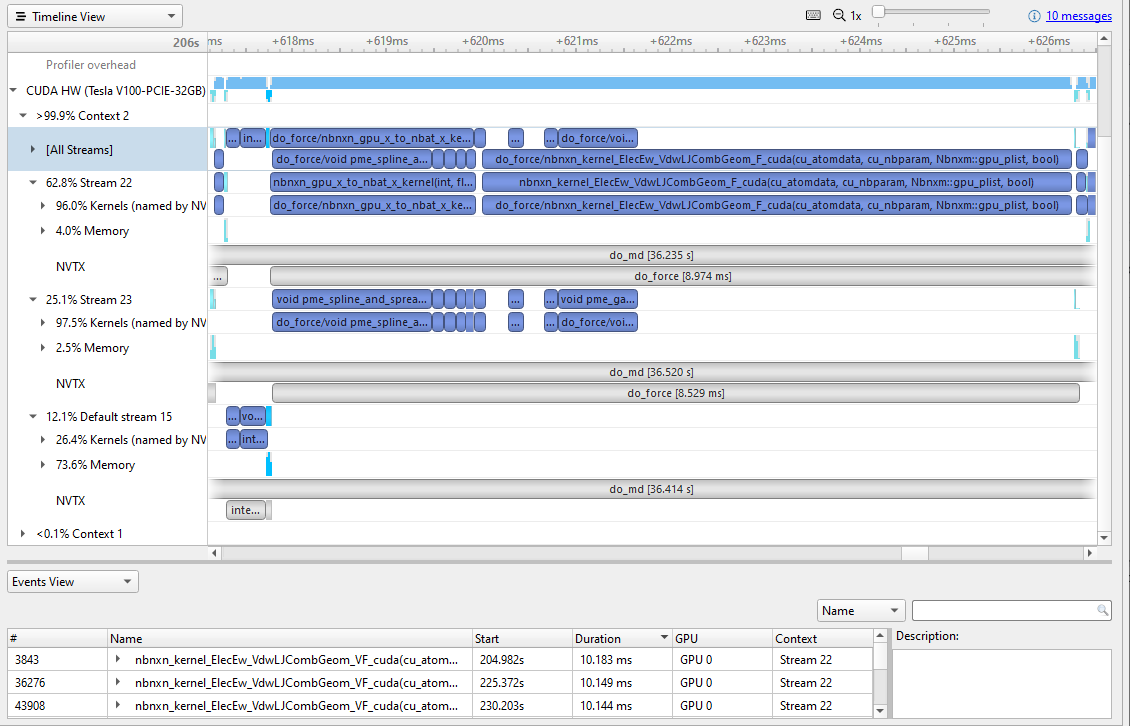
- 这个[All Streams]是流的汇合。关注细分,注意有一个活动上下文和两个活动流(流 22 和 23 ),并且 Default 流是不活动的。每个流都将超过一半的时间用于内存传输。这个高百分比强烈表明您必须优化内存传输的大小,并考虑将其移动到默认流。
- 迭代大约需要 19 毫秒,但其中 3 毫秒的时间是在活动块之间的空白间隙中。这意味着有大约 17% 的加速等待被捕获。下一个好的步骤是运行 CPU 配置文件来检查暂停的编程原因。
- 内存传输是序列化的。流 23 从主机获取数据,而流 22 等待,在它能够获取数据之前不做任何工作。工作完成后也会发生同样的事情。
- 最主要的工作内核是
nbnxn_kernel_ElecEw_VdwLJCombGeom_VF_cuda我建议在深入研究单个内核之前,先解决 CPU 和 GPU 时间线上的差距。
要查找最昂贵的内核,请右键单击所有流行并选择在事件视图中显示(图 5 )。
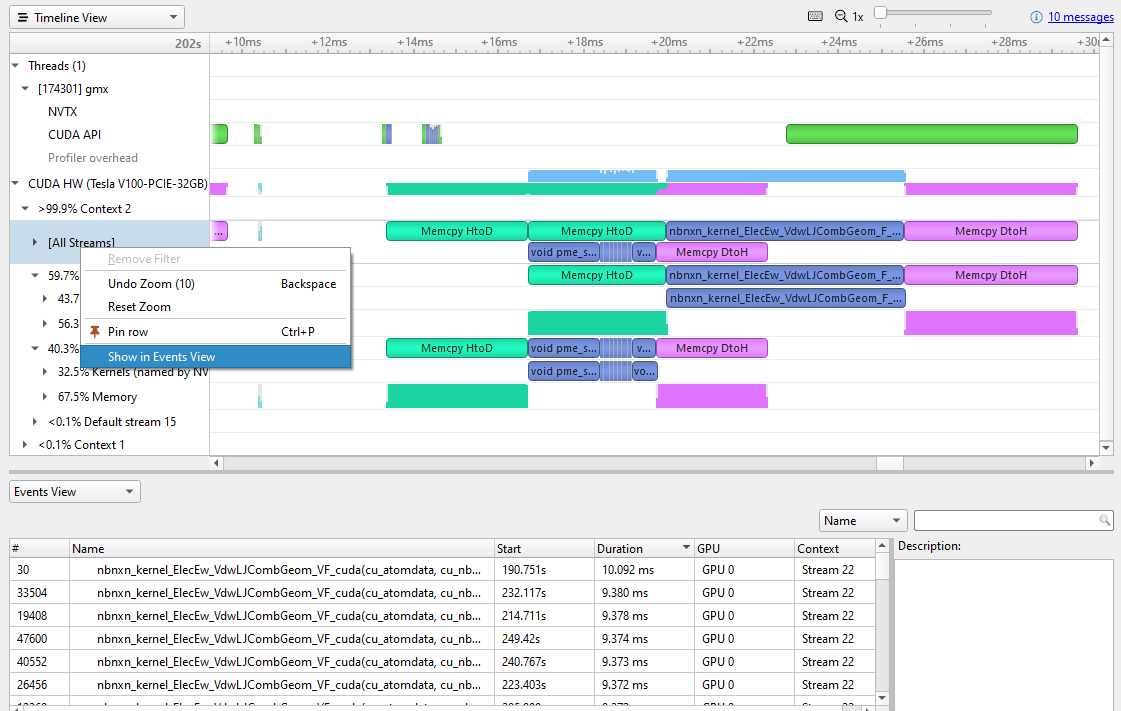
按持续时间对 Events 视图进行排序会显示最昂贵的内核。不同的实例略有不同,但目前最昂贵的是约 10 毫秒。单击某个特定的内核实例会以青色高亮显示时间线上与其相关的所有事件。
在图 6 中,闭合行上的青色标记表示该行中的某些内容高亮显示。时间线顶部或左侧的箭头表示高亮显示的内容当前不在屏幕上。
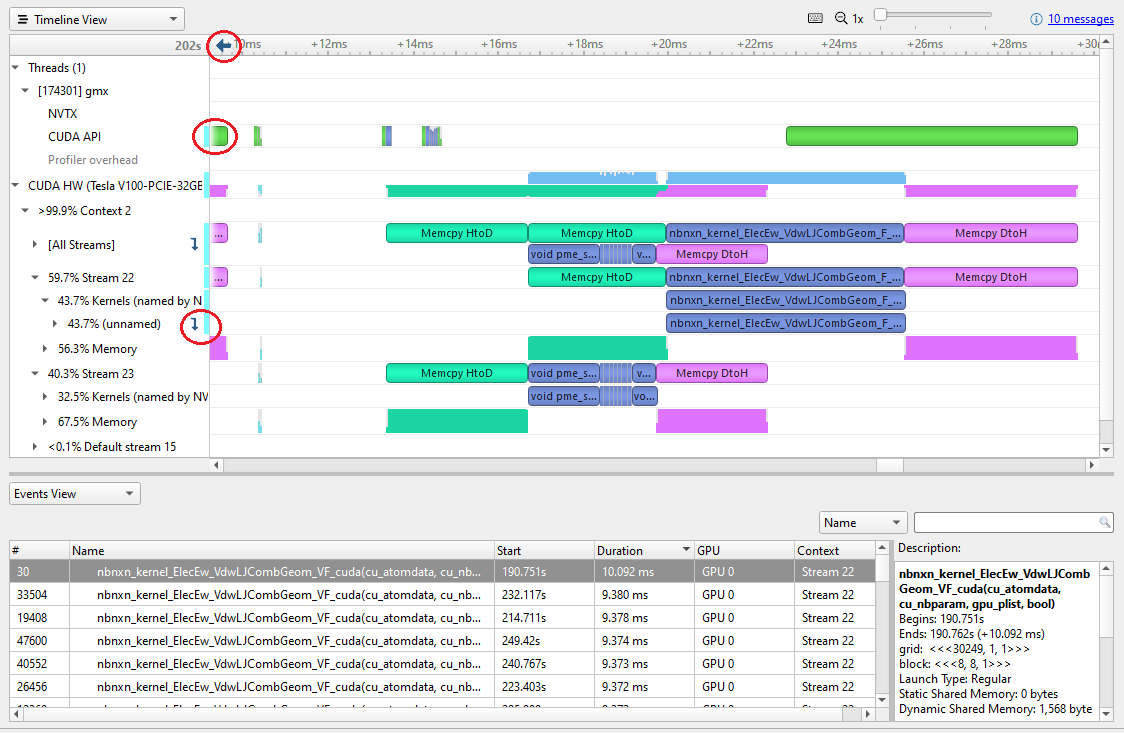
或者,您可以在事件表中单击鼠标右键,然后选择在日程表中显示当前以将时间轴缩放到该内核。
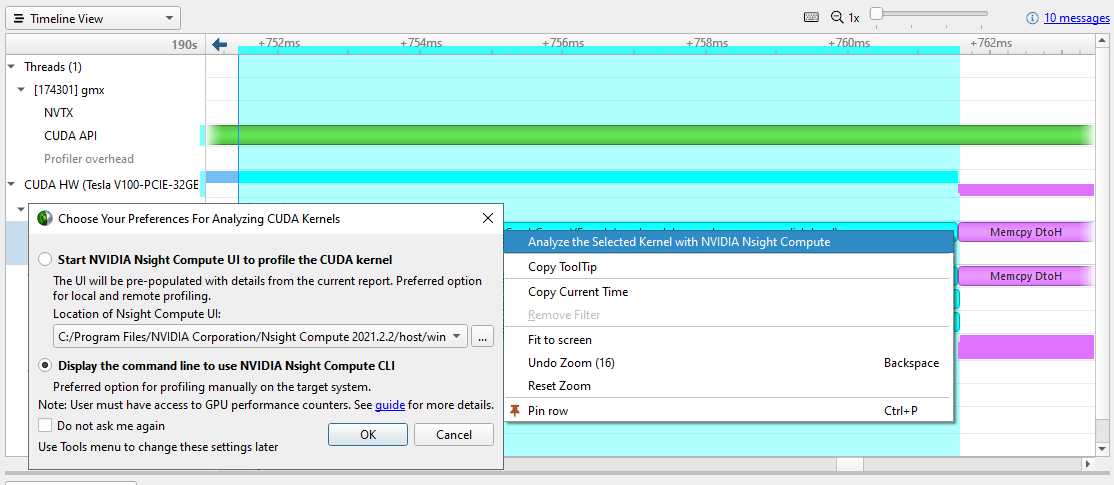
大多数时候,您会集中精力消除时间线间隙,并确保在深入到各个内核之前,工作已分配给所有 CPU 和 GPU 。届时,或者如果内核性能与您的期望不符,您可以右键单击感兴趣的内核并选择使用 NVIDIA Nsight Compute 分析所选内核.
Nsight Compute 是一个强大的独立工具,用于分析、调试和优化 CUDA 内核。如果它已安装在您的机器上,您可以直接从 Nsight Systems 中有问题的内核启动它的用户界面或 CLI。
GROMACS 2020
NVIDIA 与斯德哥尔摩 GROMACS 开发团队合作,对 GROMACS 进行了改进。有关详细信息,请参阅 《将 Gromacs 带入现代多 GPU 系统的新速度》。
您可能会注意到以下几个变化:
- 这个
nbnxn_gpu_x_to_nbat_x_内核是一个函数的 GPU 实现,该函数将原子的坐标数据从“ XYZ ”转换为一个结构,该结构中也有数据局部性的电荷: XYZQ 。在 GROMACS 2019 中,这是在 CPU 上完成的。 2020 版本调整了内存传输的大小,并将其移动到默认流。 - 长内核
nbnxn_kernel_ElecEw_VdwLJCombGeom_VF_cuda现在启用两个流之间的重叠内核执行。
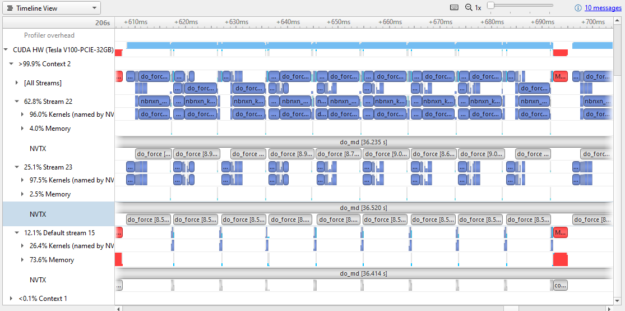
将图 8 中的结果与图 3 中的结果进行比较。两者都显示约 100 毫秒的挂钟时间。如图 8 所示, GPU 中有更多的时间实际上是在工作。 GPU 的使用显然在不同版本之间进行了优化。
几乎所有的内存传输工作都转移到了默认流上,这意味着这两个活动流在内存传输操作上花费的时间很少( 4% 和 2.5% ,而 GROMACS 2019 中超过 50% )。小的内存传输也被组合成更大的大小,仍然适合传输缓冲区。
将图 4 ( GROMACS 2019 的一个工作片段)与图 9 ( GROMACS 2020 的一个作品片段)进行比较并不公平。正如我前面提到的,大部分内存传输都被打包并转移到默认流。有几件有趣的事情需要注意:
- 在这两个流之间有更多的并行内核执行。
- 这个
nbnxn_gpu_x_to_nbat_x_在进行昂贵的计算之前,内核正在 GPU 上运行。将其移动到 GPU 而不是 CPU 不仅填充了一些间隙时间,而且还消除了一些存储器传输开销。 - 昂贵的内核,
nbnxn_kernel_ElecEw_VdwLJCombGeom_VF_cuda,并没有变得更快。最长的实例仍然大约是 10 毫秒。然而,由于它在整个运行迭代中更有效地提供了数据,因此这项工作减少到了 10 毫秒,而不是 GROMACS 2019 中的 19 毫秒。
既然间隙被清除了,nbnxn_kernel_ElecEw_VdwLJCombGeom_VF_cuda在运行时占主导地位,这表明您的性能调优之旅接下来应该转到该内核。
主要收获
改进 CUDA 内核并不是优化 GPU 代码时应该做的第一件事。提高内存利用率并确保 GPU 得到足够的“馈送”,会产生最直接的影响。
当最初重构 GPU 或转移到新一代的 GPU 硬件时,这一点尤其重要。如果 GPU 缺乏工作,您将永远无法实现可用的性能提升。
准备好开始了吗?
这只是 Nsight Systems 必须提供的所有系统性能信息的开始。
您可以从 NVIDIA CUDA ToolKit public download 中获取 NVIDIA Nsight Systems。此外,您还可以在 NVIDIA CUDA 工具包中获取最新的 Nsight Systems 增强和修复,请访问 Nsight Systems 页面。
想了解更多关于 GROMACS 的信息,请参阅 http://manual.gromacs.org/documentation/。
关于最近的其他帖子,请参阅以下内容:
有关文章、视频和其他教程的完整列表,请参阅 Nsight Systems 文档的Other Resources第节。
有任何问题吗?请将其发布到 NVIDIA 论坛 NVIDIA Nsight Systems,或者将邮件发送至 nsight-systems-feedback@NVIDIA.com。或者,只需在应用程序中选择 反馈,让我们知道您所看到的以及您的想法。



