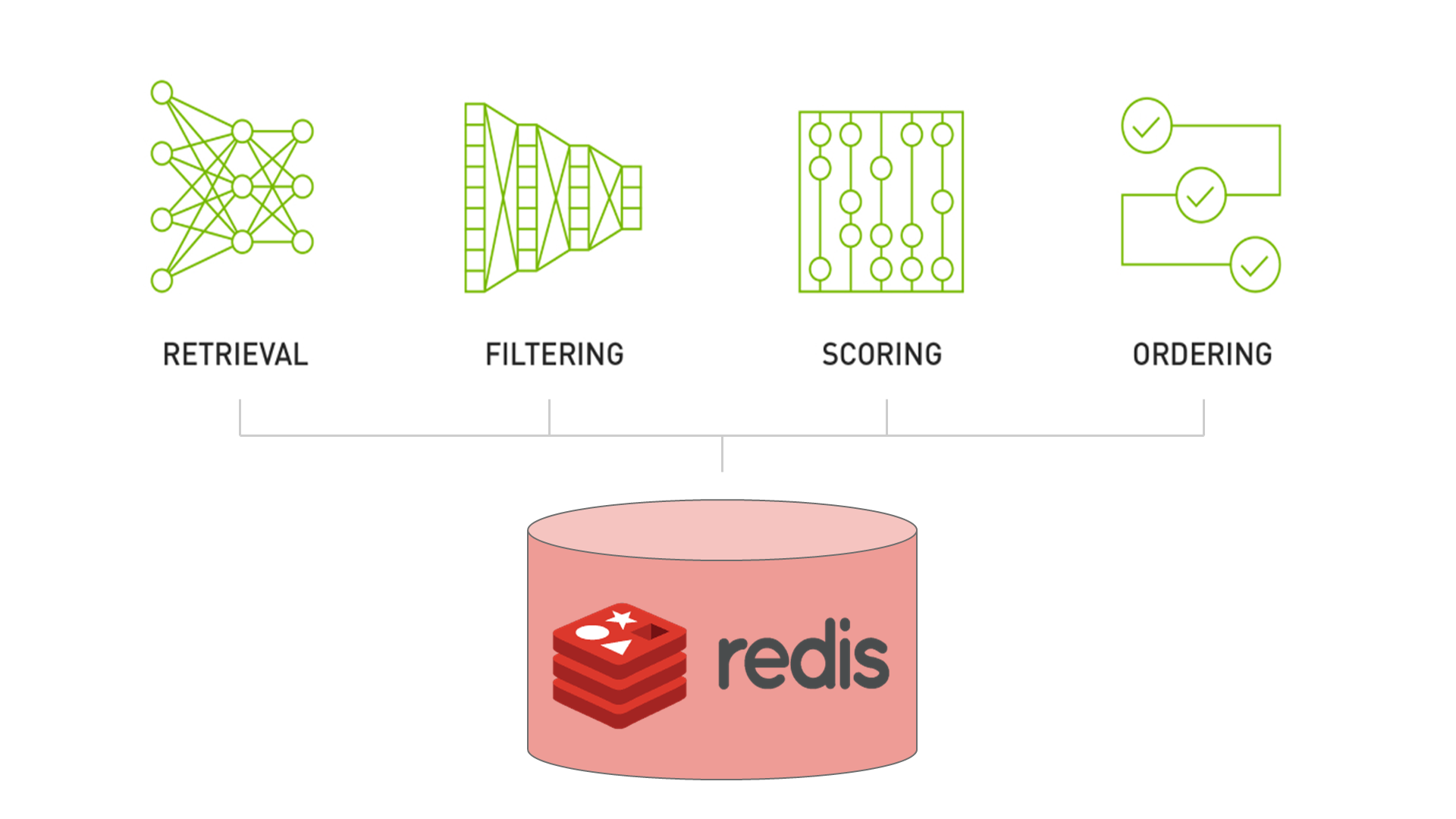
Merlin HugeCTR(以下简称 HugeCTR)是 GPU 加速的推荐程序框架,旨在在多个 GPU 和节点之间分配训练并估计点击率(Click-through rate)。
此次 v3.4 更新涉及的模块主要为:
相关介绍:
V3.4 版本新增内容
- 使用 Merlin Unified Container 支持 HugeCTR 开发:
Merlin v22.02 开始,我们鼓励您按照贡献者 指南 中的说明在 Merlin Unified Container(发布容器)下开发 HugeCTR,以保持开发环境一致。
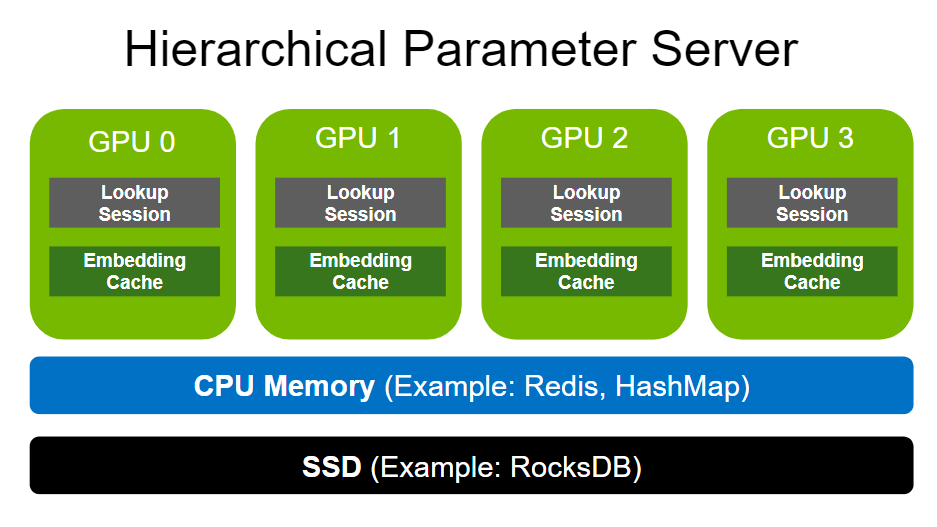
- 分层参数服务器的新增内容:
- 缺失键的插入功能: 通过一个简单的标志,现在可以配置 HugeCTR,以便使在查找期间丢失的 Embedding 条目自动插入到 Redis 和 Hashmap 后端等数据库层中。
- 异步时间戳刷新: 在上一个版本中,我们引入了传递时间感知驱逐策略。这些策略适用于通过删除键来缩小数据库分区,如果它们的增长超过了某些限制。但是,这些驱逐策略使用的时间信息代表了更新时间。因此,Embedding 是基于自上次更新以来经过的时间而被驱逐的。如果您在推理模式下操作 HugeCTR,则 Embedding table 通常是不可变的。通过上述缺失的密钥插入功能,我们现在支持在查找期间主动调整数据库层的内容以适应数据分布。为了允许基于时间的驱逐发生,现在可以为经常使用的 Embedding 启用时间戳刷新。启用后,将使用后台线程异步处理刷新。因此,它不会阻塞您的推理工作。对于大多数应用程序,启用此功能对性能的相关影响几乎不明显。
- 在训练中支持导出到 HDFS(Hadoop Distributed File System)
- 提供了一个新的 Python API DataSourceParams 用于指定文件系统以及数据和模型文件的路径。
- 支持将数据从 HDFS 加载到本地文件系统进行 HugeCTR 训练。
- 支持将训练好的模型和优化器状态转储到 HDFS。
- 模型密集部分参数在线无缝更新
HugeCTR Backend 现已支持通过 Load API 在线更新模型版本(包括密集部分的无缝更新以及同一模型对应的嵌入推理缓存),并且 Load API 仍然完全兼容新模型的在线部署。
- SOK 的新增内容:
- 混合精度训练:
现在可以通过 TF 的模式启用混合精度训练,以提高训练性能并减少内存使用。
- DLRM 相关性能指标更新。
- 现已支持使用 Pypi 来 pip install。
- 现已支持 Uint32_t / int64_t 的 Embedding key dtype:
默认情况下,key dtype 为 int64。
- 添加了 TensorFlow 的初始化程序支持。
- 用户体验增强:
- 我们修改了几个 Jupyter 笔记本和自述文件,以阐明使用说明并使 HugeCTR 更易用。
- 感谢 GitHub 用户 @MuYu-zhi,他提醒我们,配置过少的共享内存会影响 HugeCTR 的正常运行。我们扩展了 SOK docker 设置说明,以解决如何使用 docker 的 `–shm-size` 设置解决此类问题。
- 尽管 HugeCTR 是为可扩展性而设计的,但对于较小的工作负载和测试来说,拥有强大的机器并不是必需的。我们在 README 中添加了有关 Jupyter 笔记本测试环境所需规范的信息。
- 多任务
我们现已支持多任务的 HugeCTR 推理。当标签维度是二分类任务的数量并且 MultiCrossEntropyLoss 在训练过程中使用了时,推理结果的维度将是 (batch_size*num_batches, label_dim)。有关更多信息,请参阅 推理 API。
- 修复了超小型 Embedding table 在 Embedding Cache 中的缓存问题
已知问题
- HugeCTR 使用 NCCL 在 rank 之间共享数据,并且 NCCL 可能需要共享系统内存用于 IPC 和固定(页面锁定)系统内存资源。在容器内使用 NCCL 时,建议您通过发出以下命令 (-shm-size=1g -ulimit memlock=-1) 来增加这些资源。
另见 NCCL 的已知问题 以及GitHub 问题。
- Softmax 层目前暂不支持 16 位浮点数模式。
- 目前即使目标 Kafka broker 无响应,KafkaProducers 启动也会成功。为了避免与来自 Kafka 的流模型更新相关的数据丢失,您必须确保有足够数量的 Kafka brokers 启动、正常工作并且可以从运行 HugeCTR 的节点访问。