Merlin HugeCTR(以下简称 HugeCTR)是 GPU 加速的推荐框架,旨在在多个 GPU 和节点之间分配训练并估计点击率(Click-through rate)。
版本新增内容
HugeCTR 第三代 Embedding 更新:
- 第三代 Embedding 功能优化:自从在 v3.7 中引入新一代 HugeCTR Embedding 以来,进行了一些更新和优化,包括代码重构以提高可用性。此版本的增强功能如下:
- 优化了稀疏查找在 warp 间负载不平衡方面的性能。稀疏操作工具包 (SOK) 利用了此优化来提高性能。
- 修复了用于确定 GlobalEmbeddingData 和 LocalEmbeddingData 类中的最大 Embedding 向量大小的问题。
- Sparse Operation Kit 1.1.4 版可以使用 Pip 安装,并包括前面提到的优化。
- Embedding 表放置策略的 interface 简化:第三代 Embedding 现在为您提供了一种更简单的方法来配置 Embedding 表的放置策略。您可以使用函数参数配置嵌入表放置策略,而不是使用 JSON。您只需提供 shard_matrix、table_group_strategy 和 table_placement_strategy 参数。使用这些参数,第三代 Embedding 可以将不同的表组合在一起,并根据 shard_matrix 参数放置它们。请参阅示例:https://github.com/NVIDIA-Merlin/HugeCTR/blob/master/test/embedding_collection_test/dlrm_train.py
HugeCTR 分层参数服务器(HPS)更新:
- 用于 HPS 查找的 on-device 输入键:HPS 查找支持在推理期间位于 GPU 内存上的输入 Embedding 键。此功能移除了主机到设备的副本,并使用 DLPack lookup_fromdlpack() 接口,使得 embedding key 的 DLPack 包装 可以是一个 GPU tensor。
- 使用可配置的比例来初始化 Embedding Cache:在以前的版本中,cache_refresh_percentage_per_iteration 参数的默认值为 0.1。在此版本中,默认值更改为 0.0,并且该参数提供了额外的用途。如果您将参数设置为大于 0.0 的值并且还将模型的 use_gpu_embedding_cache 设置为 True,则当分层参数服务器 (HPS) 启动时,HPS 通过从模型的稀疏文件对 Embedding Cache 进行初始化时,HPS 在会创建日志记录,日志记录类似于模型的 EC 初始化:“<model-name>”、num_tables:<int> 和设备上的 EC 初始化:<int>。这样将会减少预热阶段的持续时间。
- HPS 插件的隐式初始化:在此版本中,当您使用 Triton 推理服务器部署 TensorFlow 的 SavedModel 时,首次执行加载的模型时会隐式初始化 HPS。在以前的版本中,您需要显式运行 hps.Init(ps_config_file, global_batch_size)。
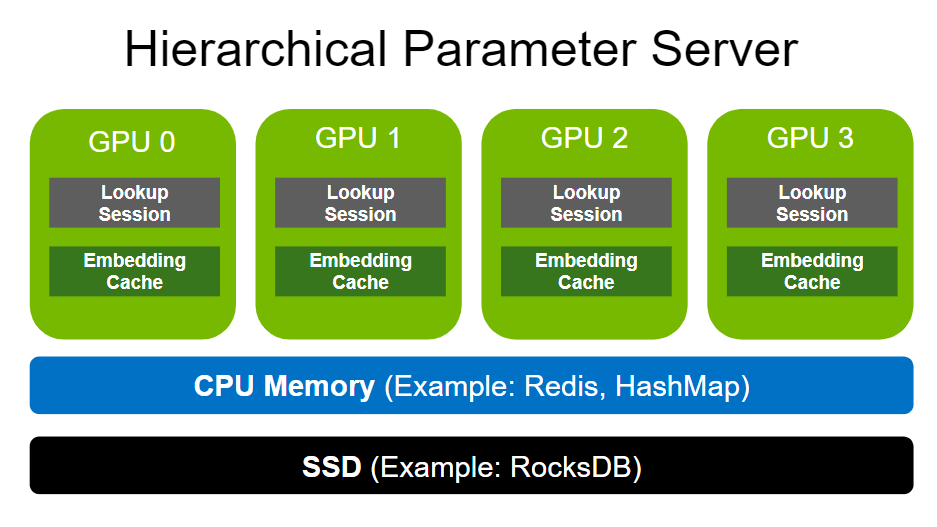
- 图1:HugeCTR 分层参数服务器(HPS)架构
HugeCTR I/O 模块更新:
- 支持了 AWS S3 文件系统:Parquet DataReader 现在可以从 Amazon Web Services S3 文件系统读取数据集。您还可以在训练期间从 S3 加载和存储模型。
- 文件系统使用的简化:您不再需要传递 DataSourceParams 来使用远端文件系统进行模型的加载和存储。 FileSystem 类会根据您在构建模型时指定的路径 URI 自动推断正确的文件系统类型:本地、HDFS 或 S3。例如,路径 hdfs://localhost:9000/ 将被推断为 HDFS 文件系统,路径 https://mybucket.s3.myregion.amazonaws.com/ 将被推断为 S3 文件系统。
- 支持将模型从远程文件系统加载到 HPS:此版本使您能够在推理期间将模型从 HDFS 和 S3 远程文件系统加载到 HPS。要使用这个新功能,请在 InferenceParams 中为模型文件路径提供准确的 HDFS 或者 S3 URL。
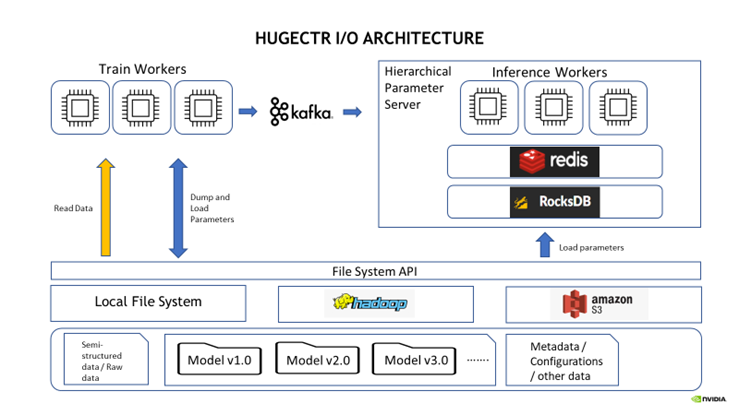
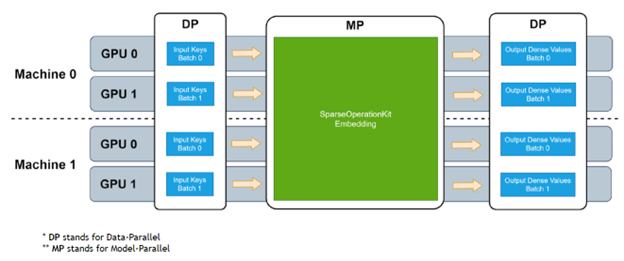
图2:HugeCTR I/O 框架
文档和示例更新:
- 新的 MMoE 模型示例:https://github.com/NVIDIA-Merlin/HugeCTR/tree/master/samples/mmoe
- 新的 HPS 示例笔记本: https://github.com/NVIDIA-Merlin/HugeCTR/tree/master/hierarchical_parameter_server/notebooks
- HPS 文档样式更新:https://nvidia-merlin.github.io/HugeCTR/master/hierarchical_parameter_server/index.html
- 删除了两个已弃用的教程 triton_tf_deploy 和 dump_to_tf。
- 增加了 Performance 相关页面:https://nvidia-merlin.github.io/HugeCTR/master/performance.html
其他更新:
- 对重叠 Pipeline 进行了更精细的粒度控制:我们弃用了旧的重叠 Pipeline knob,并引入了四个新的 knob:
- train_intra_iteration_overlap
- train_inter_iteration_overlap
- eval_intra_iteration_overlap
- eval_inter_iteration_overlap
以帮助用户更好地控制重叠行为。有关详细信息,请参阅 API 文档 https://nvidia-merlin.github.io/HugeCTR/master/api/python_interface.html#createsolver-method
- 支持在训练过程中将 Tensor 的值导出到 Numpy Array: 为 Model 和 InferenceModel 类新增了 check_out_tensor() 方法。现在用户可以使用这个 Pyhon 方法将 Tensor 的值导出,方便 debug。
修复的问题
- InteractionLayer 类已修复,它可以在 num_feas > 30 时正常工作了。
- 通过增加工作空间大小和添加结尾掩码来更正 cuBLASLt 配置。
- 用于演示特征交叉的示例的预处理脚本已修复。
- 异步数据读取器是固定的。以前,由于不正确的 I/O 块大小和 I/O 对齐问题,它会挂起并报错。 AsyncParam 类已更改以实现修复。 io_block_size 参数被 max_nr_request 参数替换,并且异步读取器使用的实际 I/O 块大小会相应计算
- 修复了在调试模式下触发的构建错误。
- 使用 Parquet DataReader 时,如果 metadata.json 中指定的 Parquet 数据集文件不存在,HugeCTR 不再崩溃,而是跳过丢失的文件并显示警告消息。
已知问题
以下是目前 HugeCTR 存在的已知问题,我们将在之后的版本中尽快修复:
- HugeCTR 使用 NCCL 在队列之间共享数据,并且 NCCL 可能需要共享系统内存用于 IPC 和固定(页面锁定)系统内存资源。如果您在容器内使用 NCCL,请在启动容器时通过指定参数 -shm-size=1g -ulimit memlock=-1 来增加这些资源。
- 即使目标 Kafka 代理没有响应,KafkaProducers 启动也会成功。为避免与来自 Kafka 的流模型更新相关的数据丢失,您必须确保足够数量的 Kafka 代理正在运行、正常运行,并且可以从运行 HugeCTR 的节点访问。
- 文件列表中的数据文件数量应大于或等于数据读取器工作人员的数量。否则,不同的 worker 会映射到同一个文件,并且数据加载不会按预期进行。
- 暂时不支持使用正则化器的联合损失训练。
- 暂时不支持将 Adam 优化器状态导出到 AWS S3。