假设您已经使用 PyTorch 、 TensorFlow 或您选择的框架训练了您的模型,并对其准确性感到满意,并且正在考虑将其部署为服务。有两个重要的目标需要考虑:最大化模型性能和构建将其部署为服务所需的基础设施。这篇文章讨论了这两个目标。
通过在三个堆栈级别上加速模型,可以从模型中挤出更好的性能:
- 硬件加速
- 软件加速
- 算法或网络加速。
NVIDIA GPU 是深度学习从业者在硬件加速方面的首选,其优点在业界得到广泛讨论。
关于 GPU 软件加速的讨论通常围绕库,如 cuDNN 、 NCCL 、 TensorRT 和其他 CUDA-X 库。
算法或网络加速 围绕量化和知识提取等技术的使用,这些技术本质上是对网络本身进行修改,其应用高度依赖于您的模型。
这种加速需求主要是由业务问题驱动的,如降低成本或通过减少延迟来改善最终用户体验,以及战术考虑因素,如在计算资源较少的边缘设备上部署模型。
服务深度学习模型
在模型加速后,下一步是构建一个服务服务来部署您的模型,这会带来一系列独特的挑战。这是一个非详尽列表:
- 该服务能否在不同的硬件平台上工作?
- 它会处理我必须同时部署的其他模型吗?
- 服务是否可靠?
- 如何减少延迟?
- 使用不同的框架和技术堆栈训练模型;我该如何应对?
- 如何缩放?
这些都是有效的问题,解决每一个问题都是一个挑战。
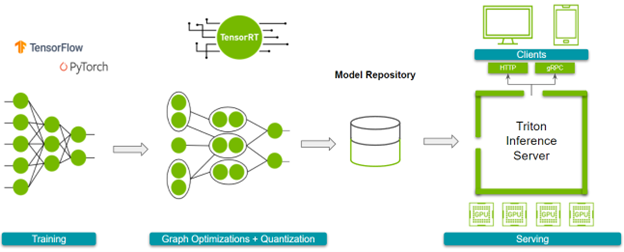
解决方案概述
本文讨论了使用 NVIDIA TensorRT 及其 PyTorch 和 TensorFlow 的框架集成、 NVIDIA Triton 推理服务器和 NVIDIA GPU 来加速和部署模型。
NVIDIA TensorRT 公司
NVIDIA TensorRT 是一个用于高性能深度学习推理的 SDK 。它包括深度学习推理优化器和运行时,为深度学习推理应用程序提供低延迟和高吞吐量。
通过其与 PyTorch 和 TensorFlow 的框架集成,只需一行代码就可以将推理速度提高 6 倍。
NVIDIA Triton 推理服务器
NVIDIA Triton 推理服务器是一种开源的推理服务软件,提供单一的标准化推理平台。它可以支持在数据中心、云、嵌入式设备或虚拟化环境中的任何 GPU 或基于 CPU 的基础设施上对来自多个框架的模型进行推理。
有关更多信息,请参阅以下视频:
工作流概述
在深入细节之前,下面是总体工作流程。接下来,请参阅以下参考资料:
图 1 显示了您必须完成的步骤。
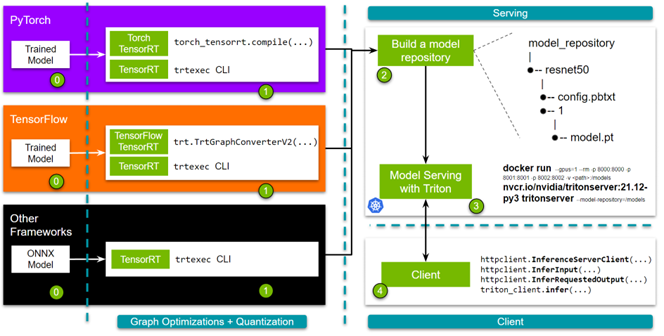
在你开始跟随之前,准备好你训练过的模型。
- 第 1 步: 优化模型。您可以使用 TensorRT 或其框架集成来实现这一点。如果选择 TensorRT ,则可以使用 trtexec 命令行界面。对于与 TensorFlow 或 Pytorch 的框架集成,可以使用单行 API 。
- 第 2 步: 构建模型存储库。启动 NVIDIA Triton 推理服务器需要一个模型存储库。该存储库包含要提供服务的模型、指定详细信息的配置文件以及任何必需的元数据。
- 第 3 步: 启动服务器。
- 第 4 步: 最后,我们提供了简单而健壮的 HTTP 和 gRPC API ,您可以使用它们来查询服务器!
在本文中,使用 NGC 中的 Docker 容器。您可能需要创建一个帐户并获得 API key 来访问这些容器。现在,这里是细节!
使用 TensorRT 加速模型
TensorRT 通过图优化和量化加速模型。您可以通过以下任何方式获得这些好处:
- trtexec CLI 工具
- Python / C ++ API
- Torch- TensorRT (与 PyTorch 集成)
- TensorFlow- TensorRT (与 TensorFlow 集成)
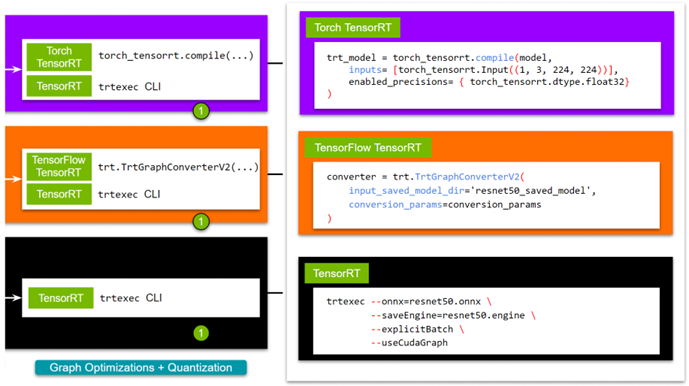
虽然 TensorRT 在本机上支持图形优化的更大定制,但框架集成为生态系统的新开发人员提供了易用性。由于选择用户可能采用的路由取决于其网络的特定需求,我们希望列出所有选项。有关更多信息,请参阅 使用 NVIDIA TensorRT 加速深度学习推理(更新) .
对于 TensorRT ,有几种方法可以构建 TensorRT 引擎。对于本文,请使用 trtexec CLI 工具。如果您想要一个脚本来导出一个预训练的模型,请使用 export_resnet_to_onnx.py 示例。有关更多信息,请参阅 TensorRT 文件 .
docker run -it --gpus all -v /path/to/this/folder:/trt_optimize nvcr.io/nvidia/tensorrt:<xx:yy>-py3 trtexec --onnx=resnet50.onnx \ --saveEngine=resnet50.engine \ --explicitBatch \ --useCudaGraph
要使用 FP16 ,请在命令中添加--fp16。在继续下一步之前,您必须知道网络输入层和输出层的名称,这是定义 NVIDIA Triton 模型存储库配置时所必需的。一种简单的方法是使用polygraphy,它与 TensorRT 容器一起打包。
polygraphy inspect model resnet50.engine --mode=basic
ForTorch TensorRT ,拉动 NVIDIA PyTorch 容器 ,安装了 TensorRT 和火炬 TensorRT 。要继续,请使用 sample 。有关更多示例,请访问 Torch-TensorRT GitHub repo 。
# <xx.xx> is the yy:mm for the publishing tag for NVIDIA's Pytorch # container; eg. 21.12 docker run -it --gpus all -v /path/to/this/folder:/resnet50_eg nvcr.io/nvidia/pytorch:<xx.xx>-py3 python torch_trt_resnet50.py
为了扩展细节,您基本上使用 Torch- TensorRT 用 TensorRT 编译 PyTorch 模型。在幕后,您的模型被转换为 TorchScript 模块,然后对 TensorRT 支持的操作进行优化。有关更多信息,请参阅 PyTorch – TensorRT 文件 .
model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=True).eval().to("cuda") # Compile with Torch TensorRT;
trt_model = torch_tensorrt.compile(model, inputs= [torch_tensorrt.Input((1, 3, 224, 224))], enabled_precisions= { torch_tensorrt.dtype.float32} # Runs with FP32; can use FP16
) # Save the model
torch.jit.save(trt_model, "model.pt")
对于 TensorFlow TensorRT ,过程基本相同。首先,拉动 NVIDIA TensorFlow Container ,它与 TensorRT 和 TensorFlow TensorRT 一起提供。我们以 short script tf_trt_resnet50.py为例。有关更多示例,请参阅 TensorFlow TensorRT github 回购。
# <xx.xx> is the yy:mm for the publishing tag for the NVIDIA Tensorflow # container; eg. 21.12 docker run -it --gpus all -v /path/to/this/folder:/resnet50_eg nvcr.io/nvidia/tensorflow:<xx.xx>-tf2-py3 python tf_trt_resnet50.py
同样,您基本上是使用 TensorFlow- TensorRT 用 TensorRT 编译 TensorFlow 模型。在幕后,您的模型被分割成包含 TensorRT 支持的操作的子图,然后进行优化。有关更多信息,请参阅 张量流 – TensorRT 文档 .
# Load model
model = ResNet50(weights='imagenet')
model.save('resnet50_saved_model') # Optimize with tftrt converter = trt.TrtGraphConverterV2(input_saved_model_dir='resnet50_saved_model')
converter.convert() # Save the model
converter.save(output_saved_model_dir='resnet50_saved_model_TFTRT_FP32')
现在,您已经使用 TensorRT 优化了模型,可以继续下一步,设置 NVIDIA Triton ®声波风廓线仪。
设置 NVIDIA Triton 推理服务器
NVIDIA Triton 推理服务器用于简化生产环境中大规模部署模型或模型集合。为了实现易用性和灵活性,使用 NVIDIA Triton 围绕着构建一个模型存储库,其中包含模型、用于部署这些模型的配置文件以及其他必要的元数据。
看看最简单的例子。图 4 有四个关键点。config.pbtxt文件( a )是前面提到的配置文件,其中包含模型的配置信息。
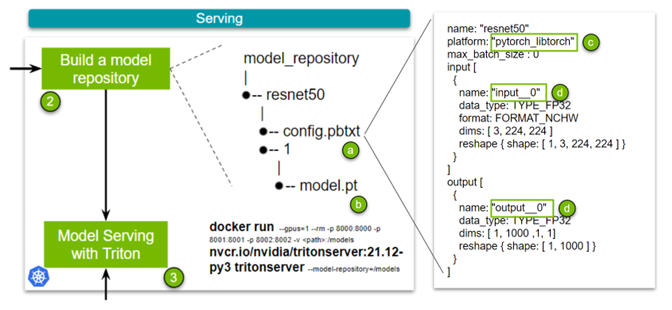
此配置文件中有几个要点需要注意:
- Name: 此字段定义模型的名称,并且在模型存储库中必须是唯一的。
- Platform: ( c )此字段用于定义模型的类型:是 TensorRT 引擎、 PyTorch 模型还是其他模型。
- 输入和输出: ( d )这些字段是必需的,因为 NVIDIA Triton 需要关于模型的元数据。本质上,它需要网络输入和输出层的名称以及所述输入和输出的形状。对于 TorchScript ,由于没有输入和输出层的名称,请使用
input__0。数据类型设置为 FP32 ,输入格式指定为 3 、 224 、 224 的(通道、高度、宽度)。
该集合中的 TensorRT 、 Torch TensorRT 和 TensorFlow- TensorRT 工作流之间存在微小差异,其归结为指定平台并更改输入和输出层的名称。我们为所有三个( TensorRT 、 Torch-TensorRT 或 TensorFlow-TensorRT )制作了示例配置文件。最后,添加经过训练的模型( b )。
现在已经构建了模型存储库,您可以启动服务器了。为此,您只需拉动容器并指定模型存储库的位置。有关使用 Kubernetes 扩展此解决方案的更多信息,请参阅 大规模部署 NVIDIA Triton 与 MIG 和 Kubernetes .
docker run --gpus=1 --rm -p 8000:8000 -p 8001:8001 -p 8002:8002 -v /full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models
随着服务器的启动和运行,您最终可以构建一个客户端来满足推理请求!
设置 NVIDIA Triton 客户端
管道中的最后一步是查询 NVIDIA Triton 推理服务器。您可以通过 HTTP 或 gRPC 请求向服务器发送推断请求。在深入细节之前,安装所需的依赖项并下载一个示例图像。
pip install torchvision pip install attrdict pip install nvidia-pyindex pip install tritonclient[all] wget -O img1.jpg "https://bit.ly/3phN2jy"
在本文中,使用 Torchvision 将原始图像转换为适合 ResNet-50 模型的格式。客户不一定需要它。我们有更全面的 image client 和为 triton-inference-server/client GitHub repo 中可用的标准用例预先制作的大量不同的客户端。然而,对于这个解释,我们将使用一个简单得多的瘦客户端来演示 API 的核心。
好的,现在您已经准备好查看 HTTP 客户端(图 5 )。下载客户端脚本:
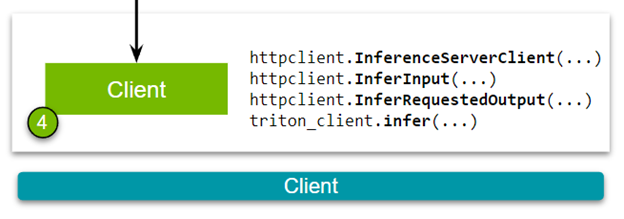
构建客户端有以下步骤。首先,在 NVIDIA Triton 推理服务器和客户端之间建立连接。
triton_client = httpclient.InferenceServerClient(url="localhost:8000")
其次,传递图像并指定模型的输入和输出层的名称。这些名称应该与您在创建模型存储库时构建的配置文件中定义的规范一致。
test_input = httpclient.InferInput("input__0", transformed_img.shape, datatype="FP32")
test_input.set_data_from_numpy(transformed_img, binary_data=True) test_output = httpclient.InferRequestedOutput("output__0", binary_data=True, class_count=1000)
最后,向 NVIDIA Triton 推理服务器发送推理请求。
results = triton_client.infer(model_name="resnet50", inputs=[test_input], outputs=[test_output])
这些代码示例讨论了 Torch- TensorRT 模型的细节。不同模型(在构建客户端时)之间的唯一区别是输入和输出层名称。我们用 Python 、 C ++、 Go 、 Java 和 JavaScript 构建了 NVIDIA Triton 客户端。有关更多示例,请参阅 triton-inference-server/client GitHub repo 。
结论
这篇文章介绍了一个端到端的推理管道,您首先使用 TensorRT 、 Torch TensorRT 和 TensorFlow TensorRT 优化训练模型,以最大限度地提高推理性能。然后,通过设置和查询 NVIDIA Triton 推理服务器,对服务进行建模。所有软件,包括 TensorRT 、 Torch-TensorRT 、 TensorFlow-TensorRT 和 Triton 在本教程中讨论,今天可以从 NGC 下载 Docker 容器。




