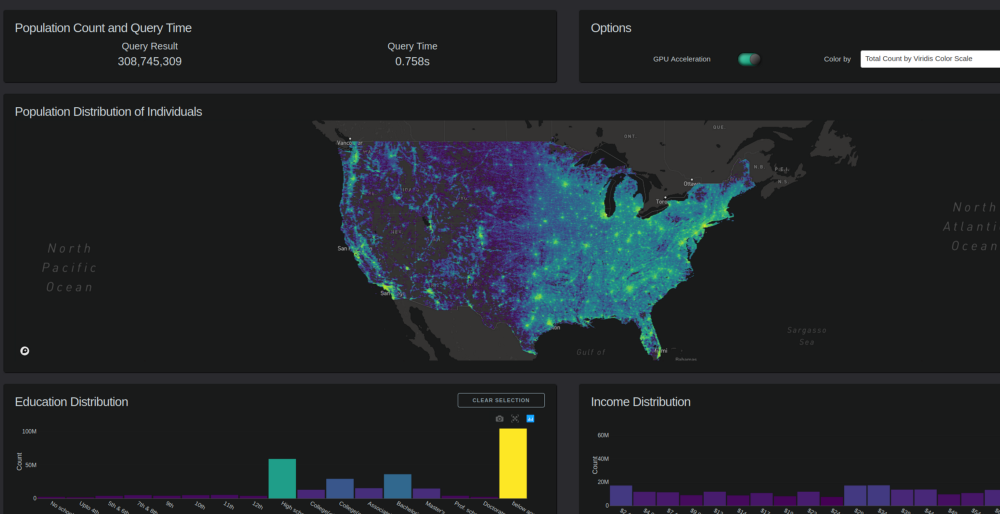
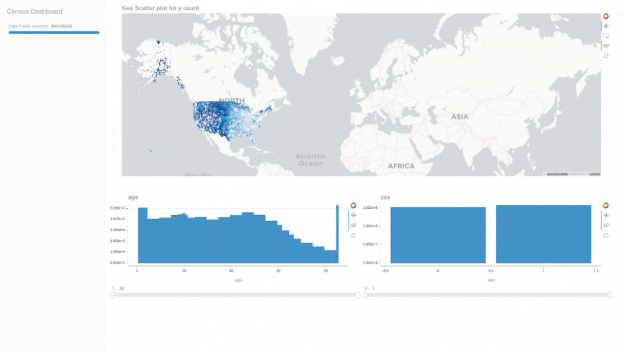
使用 Plotly 的 Dash 、 RAPIDS 和 Data shader ,用户可以构建 viz 仪表板,既可以呈现 3 亿多行的数据集,又可以保持高度的交互性,而无需预先计算聚合。
使用 RAPIDS cuDF 和 Plotly Dash 在 GPU 上进行实时交互式可视化分析
Dash 是来自 Plotly 的一个开源框架,用于使用 Python 构建基于 web 应用程序的交互式仪表板。此外,开放源码软件( OSS )库的 RAPIDS 套件提供了完全在 GPU 上执行端到端数据科学和分析管道的自由。将这两个项目结合起来,即使在单个 GPU 上,也可以实现对数千兆字节数据集的实时、交互式可视化分析。
此人口普查可视化使用 dashapi 生成图表及其回调函数。相反, RAPIDS cuDF 被用来加速这些回调,以实现实时聚合和查询操作。
使用 2010 年人口普查数据的修改版本,结合 2006-2010 年美国社区调查数据(获得了 fantastic IPUMS.org 的许可),我们将 美国的每一个人 映射到位于相当于一个城市街区的单个点(随机)。因此,每个人都有与之相关联的独特的人口统计属性,这些属性支持以前不可能的细粒度过滤和数据发现。我们的 GitHub 上公开了代码、安装细节和数据警告。
第 1 部分:可视化的数据准备
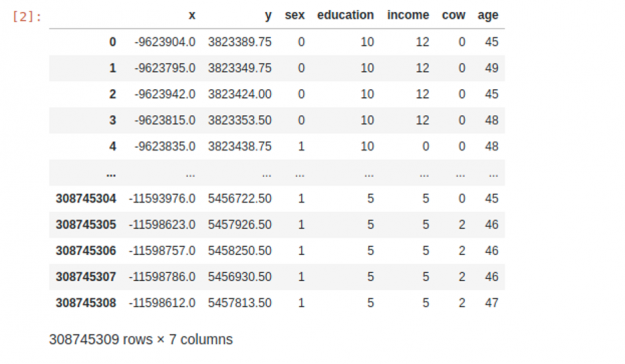
虽然不是最新的数据集,但我们选择使用 2010 年人口普查,因为它具有高地理空间分辨率、大尺寸和可用性。经过一些修改, 3 . 08 亿行× 7 列( int8 型) 的最终数据集足够大,足以说明 GPU 加速的好处。
Census 2010 SF1 +形状文件数据
我们决定把重点放在人口普查数据集上;最明显的选择是搜索 census.gov 网站,其中包括许多表格文件供下载。最适用的概要文件 1 有一个人口计数部分,其属性包括性别、年龄、种族等。但是,该数据集是按 普查区水平 列表的,而不是按单个级别(出于各种隐私原因)。结果是 只有 211267 排, 每个街区一个,包括性别、年龄、种族。
我们选择使用人口普查块边界形状文件来扩展行计数,以使所有块的人口计数相等。然后,在边界内随机分配一个 lat long ,并为每个人创建一个唯一的行。为每个状态执行此操作的脚本可以在 Plotly-dash-rapids-census-demo 中找到。切换到由 IPUMS NHGIS 站点上的 数据查找工具 提供的更为用户友好的数据集文件( SF1 和 tiger 边界文件)可以加快这个过程。
在整个数据挖掘过程中,除了重复检查每个匹配块的聚合外,我们还使用我们自己的 cuxfilter 进行快速原型制作和视觉精度检查。在本例中,为 3 . 08 亿行创建一个交互式地理散点图非常简单:
ACS 2006 – 2010 数据
出于好奇,我们是否可以结合其他有趣的属性进行交叉筛选,例如收入、教育程度和工人阶级,我们添加了 5 年的 2006-2010 年美国社区调查( ACS )数据集。该数据集在普查区块组上聚合(比普查区块大一级)。因此,我们决定在块组上进行聚合,并将其任意分布到每个个体上,同时仍保持块组级别的聚合值。修改后的数据集包括:
- 按年龄划分的性别。
- 按教育程度分列的 25 岁及以上人口的性别。
- 16 岁及以上人口过去 12 个月收入(按 2010 年通货膨胀调整后的美元计算)的性别。
- 按工人阶级分列的 16 岁及以上平民就业人口的性别。
公共列是 Sex ,用于合并所有数据集。然而,虽然这种方法提供了其他有趣的属性来进行过滤,但结果有几个注意事项:
- 在地理位置或单个列上进行交叉过滤将为所有其他列生成准确的计数。
- 同时交叉过滤多个非地理列不一定会产生真实的计数。
- 与个人相关的属性只是统计性的,不能反映真实的人。但是,当汇总到人口普查区块组级别或更高级别时,它们是准确的。
执行该过程的笔记本可以在 plotly-dash-rapids-census-demo 上找到。最终的数据集如下所示:
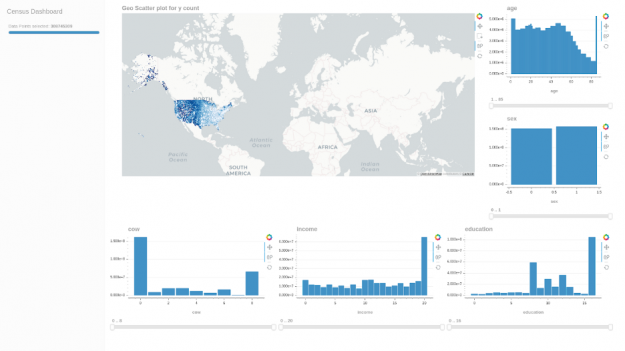
下面是一个用于验证数据集值的快速 cuxfilter 仪表板:
资源链接:
第 2 部分:使用 Plotly Dash 构建交互式仪表板
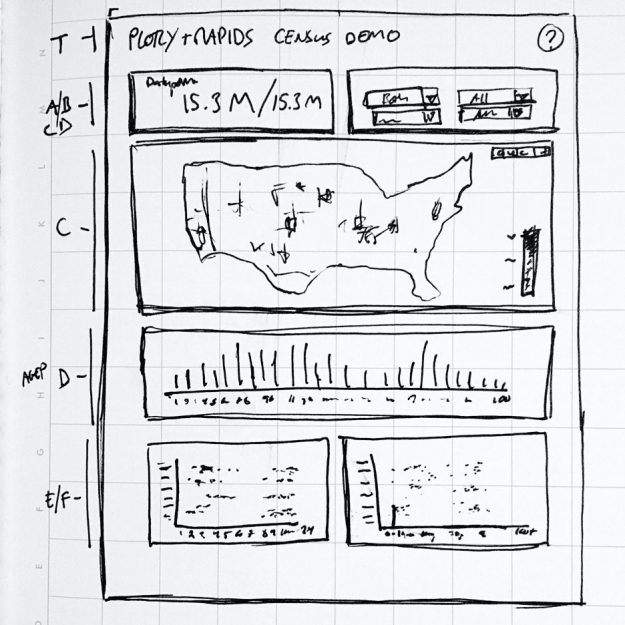
Dash 支持在仪表板中添加单独的 Plotly chart 对象,以及使用 Python 为每个对象图形、选择和布局单独回调。例如,仪表板中基于上述数据集的图表如下:
Scattermapbox :个体的种群分布
此图表由两层组成:
- Scattermapbox 层。
- Datashader 在上面生成了一个输出图像。
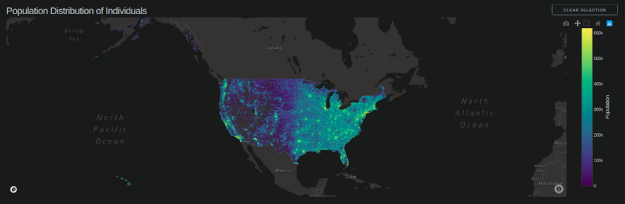
图表更新回调在以下位置触发:
- “重新布局数据”(向内滚动、向外滚动、鼠标平移)根据缩放级别重新渲染数据阴影图像,以便分辨率保持不变。
- 下拉选择“颜色依据”。
- 教育、收入、工人阶级和年龄图表的方框选择。
- 地图上的方框选择。
条形图:教育程度、收入、工人阶级、年龄
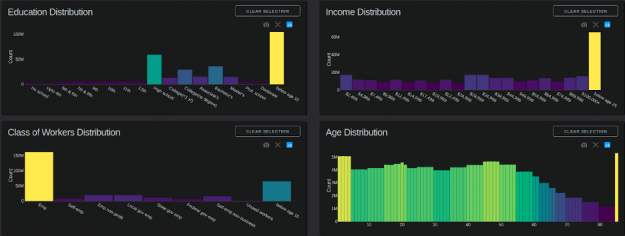
图表更新回调在以下位置触发:
- 教育、收入、工人阶级和年龄图表的方框选择。
- 地图上的方框选择。
- 下拉选择“颜色依据”。
GPU 的适用范围和帮助方式:
此仪表板中的每个图表都从 GPU 加速到 cuDF :使用 GPU – 加速模式,在 24GB NVIDIA Titan NVIDIA RTX 上进行过滤或缩放交互通常需要 0 . 2 – 2 秒。在高端 CPU 和 64GB 系统内存上运行,相同的交互通常需要 10-80 秒。通常, cuDF GPU 模式比 pandas CPU 模式快 20 倍以上 根据图表。 20 倍的不同之处在于将报表仪表板转换为交互式可视分析应用程序。
数据可视化是一个迭代设计过程
尽管像人口普查中这样一个记录良好且可用的数据集,但了解这些数据并制定一个 viz 来有效地与之交互似乎总是比对数据集 MIG 的任何初步研究都要花费更长的时间。
与所有数据可视化一样,最终结果通常取决于在可用的数据和图表、您试图传达的故事以及您正在通过的媒介(和硬件)之间找到适当的平衡。例如,我们对列格式进行了多次迭代,以确保 GPU 的使用可靠地保持在 24GB 单个 GPU 限制之下,同时仍然允许多个图表之间的平滑交互。
处理数据是复杂的,而处理大型数据集则更为复杂,但通过将 Plotly Dash 与 RAPIDS 相结合,我们可以提高分析师和数据科学家的能力。这些库允许用户在熟悉的环境中工作,并生成更大、更快、更具交互性的可视化应用程序,为开箱即用的生产做好准备—将传统可视化分析的边界推向高性能计算领域。
GTC 数字直播网络研讨会
在即将于 5 月 28 日上午 9 点举行的 GTC Digital live 网络研讨会 RAPIDS 状态:连接 GPU 数据科学生态系统[S22181] 上,请听 Josh Patterson 讨论更多关于 RAPIDS 和 Plotly 合作的内容。
社区和下一步
Plotly 和 RAPIDS 通过他们的开源社区蓬勃发展,我们希望看到他们一起成长。在未来,我们将致力于与 Dash 建立更紧密的集成,并与 dask 琰 cuDF 建立强大的多 – GPU 支持。
最后,我们希望看到开发人员试用这些工具,并在许多大型数据集上创建非常棒的演示,让我们知道 RAPIDS 是如何使用这些数据集的!谁知道呢,也许一年后我们会有一个更好的 2020 人口普查可视化应用程序!
NVIDIA 启动
Plotly 也是 NVIDIA 启动 的主要成员,这是一个虚拟加速器,旨在支持使用 GPU 进行人工智能和数据科学应用的初创企业。该计划对所有申请者开放,并提供 NVIDIA 工程支持和硬件访问。如果有兴趣,请使用 here 。
有用的链接
- RAPIDS Plotly 社区网页 带演示
- RAPIDS Plotly Dash 人口普查演示 github 回购
- 涵盖 RAPIDS 集成和合作关系的 Plotly Medium 最近的博客
这篇文章最初发表在 RAPIDS AI 博客上