张量收缩是机器学习、计算化学和量子计算中许多重要工作的核心。随着科学家和工程师们对不断增长的问题的研究,基础数据变得越来越大,计算时间也越来越长。
当张量收缩不再适合单个 GPU 时,或者如果在单个 GPU 上花费的时间太长,自然下一步是将收缩分布到多个 GPU 上。我们一直在用这个新功能扩展 cuTENSOR ,并将其作为一个名为 cuTENSORMg (多 GPU )的新库发布。它在块循环分布张量上提供单进程多 GPU 功能。
cuTENSORMg 的copy和contraction操作大致分为句柄、张量描述符和描述符。在这篇文章中,我们将解释句柄和张量描述符,以及复制操作是如何工作的,并演示如何执行张量收缩。然后,我们将展示如何测量各种工作负载和 GPU 配置下收缩操作的性能。
库把手
库句柄表示参与计算的设备集。句柄还包含跨调用重用的数据和资源。通过将设备列表传递给cutensorMgCreate函数,可以创建库句柄:
cutensorMgCreate(&handle, numDevices, devices);
cuTENSORMg 中的所有对象都是堆分配的。因此,必须通过匹配的destroy调用释放它们。为了简洁起见,我们在这篇文章中没有展示这些,但是生产代码应该销毁它创建的所有对象,以避免泄漏。
cutensorMgDestroy(handle);所有库调用都返回cutensorStatus_t类型的错误代码。在生产中,您应该始终检查错误代码,以便尽早检测故障或使用问题。为了简洁起见,我们在本文中省略了这些检查,但它们包含在相应的示例代码中。
除了错误代码, cuTENSORMg 还提供与 cuTENSOR 类似的日志记录功能 。可以通过适当设置CUTENSORMG_LOG_LEVEL环境变量来激活这些日志。例如,CUTENSORMG_LOG_LEVEL=1将为您提供有关返回的错误代码的附加信息。
张量描述符
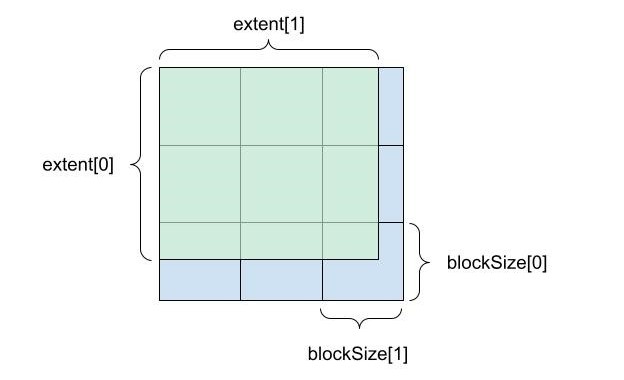
张量描述符描述了张量在内存中的布局以及在设备中的分布。对于每种模式,有三个核心概念来确定布局:
extent:每个模式的逻辑大小。blockSize:将extent细分为大小相等的块,但最后的剩余块除外。deviceCount:确定块在设备上的分布方式。
图 1 显示了extent和block size如何细分二维张量。
![A 3x3 square showing deviceCount [0] on the Y axis and deviceCount[1] on the X axis.](https://developer-blogs.nvidia.com/wp-content/uploads/2022/03/Introducing-Multi-GPU-Tensor-Contractions-4-625x494_2.jpg)
块以循环方式分布,这意味着连续的块被分配给不同的设备。图 2 显示了块到设备的逐块分布,将设备分配到使用另一个数组devices编码的块。该阵列是一个密集的柱状主张量,其范围与设备计数类似。
![A 4x4 block with Y axis as blockStride[0] and X axis blockStride[1]. This block is comprised of smaller by 4x4 blocks with elementStride[1] as the X axis and and elementStride[0] as the Y axis.](https://developer-blogs.nvidia.com/wp-content/uploads/2022/03/Introducing-Multi-GPU-Tensor-Contractions-2-625x469_2.jpg)
最后,设备上的确切数据布局由每种模式的elementStride和blockStride 值决定。它们分别以元素为单位在线性存储器中确定给定模式下两个相邻元素和相邻块的位移(图 3 )。
这些属性都是使用cutensorMgCreateTensorDescriptor调用设置的:
cutensorMgCreateTensorDescriptor(handle, &desc, numModes, extent, elementStride, blockSize, blockStride, deviceCount, numDevices, devices, type);
可以将NULL传递给elementStride、blockSize、blockStride和deviceCount。
如果elementStride是NULL,则使用通用列主布局假定数据布局密集。如果blockSize是NULL,则等于extent。如果blockStride是NULL,则它等于blockSize * elementStride,这将产生交错块格式。如果deviceCount为NULL,则所有设备计数都设置为 1 。在这种情况下,张量是分布式的,完全驻留在devices[0]的内存中。
通过将CUTENSOR_MG_DEVICE_HOST作为所属设备传递,可以指定 tensor 位于主机上的固定、托管或定期分配的内存中。
复制操作
copy操作可以更改数据布局,包括将张量重新分配到不同的设备。其参数是源和目标张量描述符(descSrc和descDst),以及源和目标模式列表(modesSrc和modesDst)。这两个张量在重合模式下的范围必须匹配,但它们的其他方面可能不同。一个可能位于主机上,另一个跨设备,它们可能具有不同的阻塞和步幅。
与 cuTENSORMg 中的所有操作一样,它分三步进行:
cutensorMgCopyDescriptor_t:编码应该执行的操作。cutensorMgCopyPlan_t:编码操作的执行方式。cutensorMgCopy:根据计划执行操作。
第一步是创建复制描述符:
cutensorMgCreateCopyDescriptor(handle, &desc, descDst, modesDst, descSrc, modesSrc);有了拷贝描述符,您可以查询所需的设备端和主机端工作空间的数量。deviceWorkspaceSize阵列的元素数量与手柄中的设备数量相同。 i -th 元素是句柄中 i -th 设备所需的工作空间量。
cutensorMgCopyGetWorkspace(handle, desc, deviceWorkspaceSize, &hostWorkspaceSize);
确定工作空间大小后,规划副本。你可以传递一个更大的工作空间大小,呼叫可能会利用更多的工作空间,或者你可以尝试传递一个更小的大小。规划可能能够适应这一点,否则可能会产生错误。
cutensorMgCreateCopyPlan(handle, &plan, desc, deviceWorkspaceSize, hostWorkspaceSize最后,计划完成后,执行copy操作。
cutensorMgCopy(handle, plan, ptrDst, ptrSrc, deviceWorkspace, hostWorkspace, streams);在这个调用中,ptrDst和ptrSrc是指针数组。它们包含对应的张量描述符中每个设备的一个指针。在本例中,ptrDst[0]对应于作为devices[0]传递给cutensorMgCreateTensorDescriptor的设备。
另一方面,deviceWorkspace和streams也是数组,其中每个条目对应一个设备。它们是根据库句柄中设备的顺序排序的,例如deviceWorkspace[0]和streams[0]对应于在devices[0]传递给cutensorMgCreate的设备。工作空间必须至少与传递给cutensorMgCreateCopyPlan的工作空间大小相同。
收缩手术
cuTENSORMg 库的核心是contraction操作。它目前实现了一个或多个设备上张量的张量收缩,但将来可能支持主机上的张量。作为复习,收缩是以下形式的操作:

其中







与copy操作一样,它分三个阶段进行:
cutensorMgCreateContractionDescriptor:对问题进行编码。cutensorMgCreateContractionPlan:对实现进行编码。cutensorMgContraction:使用计划并执行实际收缩。
首先,根据张量描述符、模式列表和所需的计算类型(例如计算期间可能使用的最低精度数据)创建收缩描述符。
cutensorMgCreateContractionDescriptor(handle, &desc, descA, modesA, descB, modesB, descC, modesC, descD, modesD, compute);
由于收缩操作有更多的自由度,您还必须初始化find对象,以便更好地控制给定问题描述符的计划创建。目前,这个find对象只有一个默认设置:
cutensorMgCreateContractionFind(handle, &find, CUTENSORMG_ALGO_DEFAULT);
然后,您可以按照为copy操作所做的操作来查询工作空间需求。与该操作相比,您还传入了find和workspace首选项:
cutensorMgContractionGetWorkspace(handle, desc, find, CUTENSOR_WORKSPACE_RECOMMENDED, deviceWorkspaceSize, &hostWorkspaceSize);
创建一个计划:
cutensorMgCreateContractionPlan(handle, &plan, desc, find, deviceWorkspaceSize, hostWorkspaceSize);
最后,使用计划执行收缩:
cutensorMgContraction(handle, plan, alpha, ptrA, ptrB, beta, ptrC, ptrD, deviceWorkspace, hostWorkspace, streams);
在这个调用中, alpha 和 beta 是与BFloat16精度,在这种情况下是 single precision 。不同数组ptrA、ptrB、ptrC和ptrD中指针的顺序对应于它们在描述符devices数组中的顺序。deviceWorkspace和streams数组中指针的顺序与库句柄的devices数组中的顺序相对应。
表演
你可以在 CUDA 库样本 GitHub 回购。我们将其扩展为两个参数: GPU 的数量和比例因子。您可以随意尝试其他收缩、块大小和缩放模式。它是以这样一种方式编写的,即在保持 K 不变的情况下,将 M 和 N 放大。它实现了形状的几乎 GEMM 形状的张量收缩:

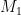
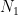

开始使用 cuTENSORMg
是否有兴趣尝试 cuTENSORMg ,将张量收缩扩展到单个 GPU 之外?
我们继续致力于改进 cuTENSORMg ,包括核心功能之外的功能。如果您有任何疑问或新功能要求,请联系产品经理 Matthew Nicely US 。




