
RAPIDS cuDF 提供了一系列用于使用 GPU 处理数据的 ETL 算法。对于 pandas 用户,cuDF 加速算法可用于零代码更改 cudf.pandas 解决方案。对于 C++ 开发者和高级用户而言,直接使用 cuDF 中的 C++ 子模块可以开启新的功能和性能选项。
cuDF C++ 编程模型接受非所有权视图作为输入,并返回所有权类型作为输出。这使得推理 GPU 数据的生命周期和所有权变得更加容易,并最大限度地提高 cuDF API 的组合性。然而,这种模型的一个缺点是,一些操作会产生过多的中间结果,导致过多的 GPU 显存传输。过度 GPU 显存传输的一个解决方案是内核融合,即单个 GPU 内核对相同输入数据执行多个计算。
本文解释了 JIT 编译如何将内核融合引入 cuDF C++ 编程模型,从而提高数据处理吞吐量并提高 GPU 内存和计算利用率。
cuDF 中的表达式评估
在数据处理中,表达式通常表示为操作数和运算符的树,其中每个叶子节点都是一列或标量,每个交点都是一个运算符(图 1)。在典型情况下,标量表达式会将一个或多个输入转换为单个输出列。标量表达式通常表示输入和输出之间的行级映射,其中每一行输入产生一行输出。
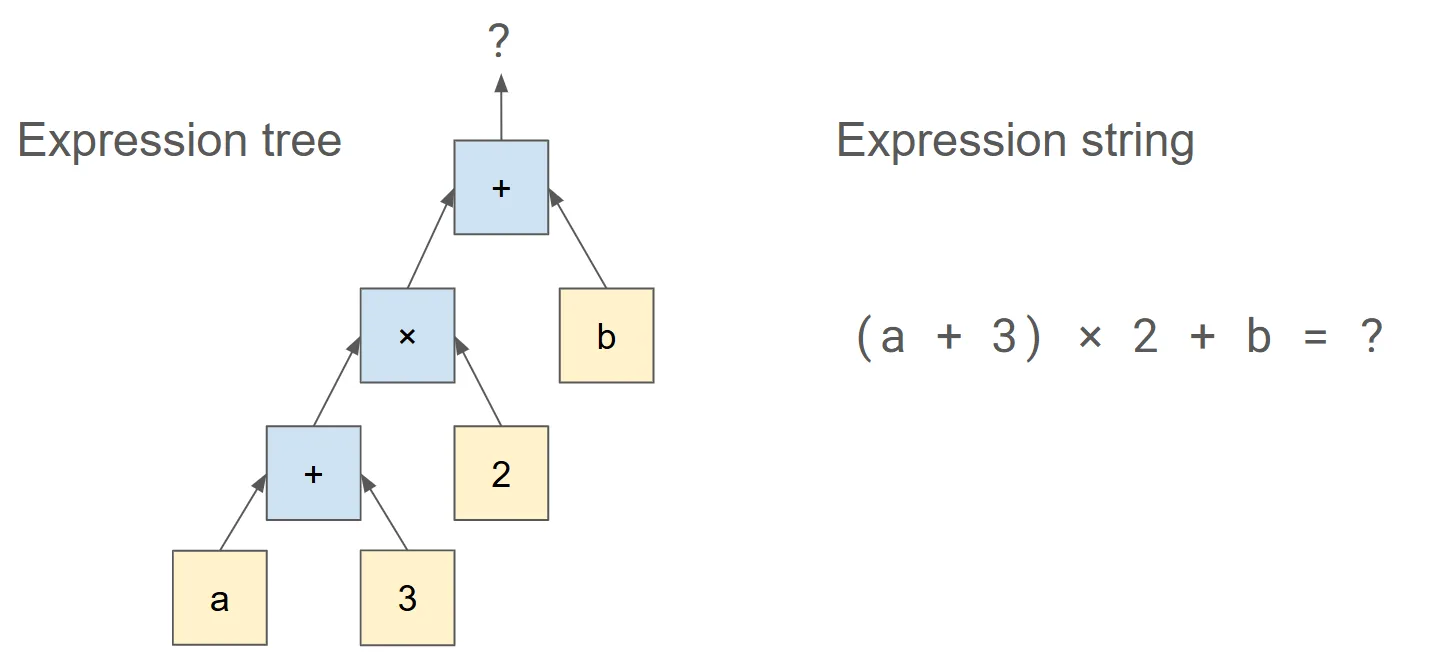
对于算术表达式,cuDF 有三种评估选项:预编译、AST(抽象语法树)和 JIT 转换。
预编译方法会为表达式中的每个运算符调用 libcudf 公共 API,递归计算树。libcudf 中预编译的函数调用具有广泛的数据类型和运算符支持的优势。主要缺点是每个运算符在评估期间都会将中间结果存储在 GPU 全局显存中。
AST 方法使用 libcudf 中的 compute_column API,该 API 接受整个树作为参数,然后使用专门的内核遍历和评估树。AST 执行使用 GPU 行级并行模型。AST 解释器内核是 cuDF 中内核融合的有用工具,但其数据类型支持和运算符支持有限。
cuDF 中的 JIT 转换方法使用 NVRTC 来 JIT 编译一个自定义内核,以完成任意转换。NVRTC 是 CUDA C++ 的运行时编译库,可在运行时创建融合内核。JIT 编译的优势在于,它使用针对要评估的表达式的优化内核。这意味着编译器能够高效地分配 GPU 资源,而不是为最坏情况预留 GPU 寄存器。
从 cuDF 25.08 开始,JIT 转换增加了对 AST 执行不支持的几个关键运算符的支持,包括用于 if-else 分支的三元运算符,以及 find 和 substring 等字符串函数。JIT 编译的主要缺点是,必须在运行时支付 ~600 毫秒的内核编译时间,或者通过预填充 JIT 缓存来管理该时间。本文后续部分将详细介绍此主题。
使用 JIT 转换
rapidsai/cudf GitHub 资源库提供了一套 string_transforms 示例,用于演示使用预编译方法和新的 JIT 转换方法进行字符串操作。示例用例采用用户定义函数 (UDF) 的形式进行字符串处理。
示例用例 extract_email_jit JIT 和 extract_email_precompiled 侧重于一项计算,该计算需要输入字符串,确认字符串作为电子邮件地址的基本格式,然后从字符串中提取电子邮件提供商。对于 user@provider.com 这样的典型电子邮件地址,目标输出将是 provider。如果输入格式不正确,示例会返回 unknown 作为备用条目。
图 2 显示了 extract_email_precompiled 示例,其中以绿色突出显示的逻辑标识了 “@” 和 “.” 位置。以粉色突出显示的逻辑根据 “@” 和 “.” 字符的存在和位置计算 is_valid 字段。最后,蓝色突出显示的逻辑从输入字符串中切分提供者,并在输入无效时复制备用条目。这种方法可以产生正确的结果,但需要使用额外的内存和计算来实现字符位置、多个布尔列和包含备用条目的列。

extract_email_precompiled 代码块,突出显示字符检测逻辑(绿色)、验证逻辑(粉色)和结果构建(蓝色)使用 JIT 编译,您可以创建更高效地执行相同工作的 GPU 内核。图 3 显示了 extract_email_jit 示例,其中使用了定义变换的原始字符串 “udf”。这个过程首先在 “@” 字符处查找并切片,然后在 “.” 字符处查找并切片。
与预编译示例中的每一步都将数据作为完整列进行处理相比,这种操作顺序使验证检查变得更加简单。UDF 使用标准 C++ 模式(如 if-else 分支和早期返回)来简化逻辑。

extract_email_jit 代码块,突出显示字符检测逻辑(绿色)、验证逻辑(粉色)和结果构建(蓝色)我们鼓励您查看其他示例,以了解这些差异的实际应用。
JIT 编译可提升性能
使用 JIT 转换方法处理 UDF 的运行速度比使用预编译方法更快。速度提升的主要原因是 JIT 转换方法中的内核总数较低。当同一项工作可以用更少的内核执行时,计算通常具有更好的缓存局部性,并且 GPU 寄存器可以保存中间值,否则这些中间值必须存储在全局内存中以供后续内核使用。
图 4 显示了三个字符串转换示例的内核启动时间线,其中蓝色条形图表示通过预编译方法启动的内核,绿色条形图表示通过 JIT 转换方法启动的内核。时间线数据是在 NVIDIA GH200 Grace Hopper Superchip 硬件上使用 CUDA 异步内存资源收集的,输入行数为 2 亿行(输入文件大小为 12.5 GB)。请注意,运行时间 <10 μs 的内核已省略。
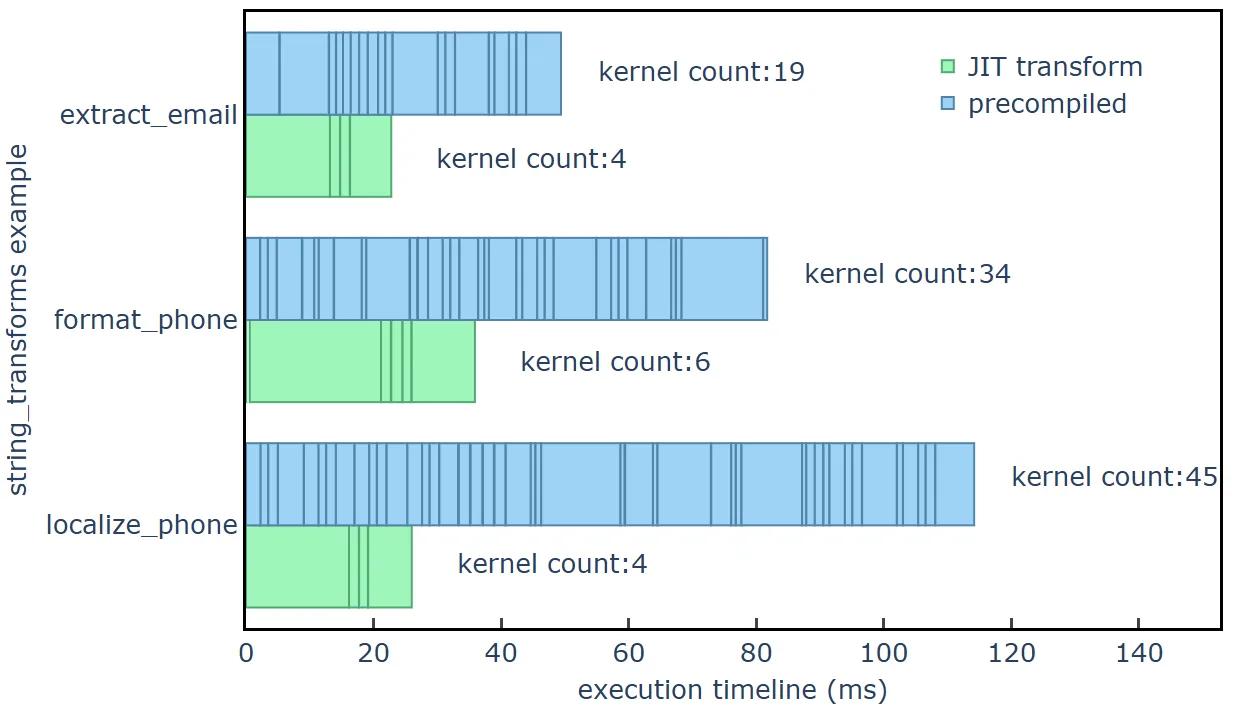
string_transforms 中的 UDF 执行示例用例期间 GPU 内核的数量和持续时间JIT 转换方法显示了随着数据规模的增加而产生的优势。在较小数据大小下,由于内核启动次数较少,JIT 转换方法的开销较小,这可根据 UDF 的复杂性提供加速。除了减少开销外,JIT 转换方法还使用更少的 GPU 显存带宽和计算资源,因此在数据量较大时,与预编译方法相比,速度更快。
图 5 显示了 localize_phone 示例用例的加速倍数为 2 倍至 4 倍,而更简单的 extract_email 和 format_phone 示例用例的加速倍数为 1 倍至 2 倍。请注意,由于中间结果的减少,JIT 转换方法在 Grace Hopper 超级芯片上处理的数据大小大约比达到 ~100 GB GPU 显存限制之前大 30%。

string_transforms 中的示例用例中,JIT 转换方法与预编译方法的加速对比,针对 60 MB 至 40 GB 的文件大小绘制而成JIT 编译的特殊成本
JIT 编译也为高效执行带来了一些独特的挑战。当 JIT 转换方法首次运行时,cuDF 将检查位于环境变量 LIBCUDF_KERNEL_CACHE_PATH 指定路径的内核缓存。在此示例中,缓存内核大小约为 130 KB。如果未找到缓存内核,则 string_transforms 示例中的 JIT 编译时间为每个内核约 600 毫秒。如果找到内核,则加载内核大约需要 3 毫秒。
编译和加载后,同一进程中对内核的后续调用不会产生额外的开销。图 6 显示了首次运行的时间,其中每次重复都是一个新进程,并且第 1 次重复从空内核缓存开始。JIT 编译时间显示,由于 NVRTC 的 JIT 编译,首次执行的实际时间较长,但后续的实际时间会大幅下降。在示例中,壁钟时间被报告为“预热时间”,数据大小为 200M 行。

对于 string_transforms 中的示例,如果 JIT 编译必须推迟到运行时,则盈亏平衡数据大小约为 1-3B 行,以 ~100M 行为一批处理。如果应用层预先使用先前编译的内核填充 JIT 缓存,那么 JIT 转换通常会带来好处,即使是从第一百万行开始。
开始使用 cuDF 中的高效变换功能
NVIDIA cuDF 提供了用于处理表达式和 UDF 的强大、灵活且加速的工具。有关 CUDA 加速数据帧的更多信息,请参阅 cuDF 文档和 rapidsai/cudf GitHub 资源库。为了便于测试和部署,RAPIDS Docker 容器还可用于发布和夜间构建。
要开始使用 cuDF 的 C++ 子模块 libcudf,我们建议使用 rapidsai-nightly Conda 频道安装预构建二进制文件。找到 libcudf-example Conda 软件包并安装本文中介绍的 string_transforms 示例。libcudf-tests Conda 包中包含单元测试和微基准测试,因此可以轻松运行 cuDF 预编译和 JIT 编译表达式评估器并对其进行分析。






