NVIDIA Jetson Orin 是同类中最优秀的人工智能工作负载嵌入式平台。Orin 平台的关键组件之一是第二代 Deep Learning Accelerator (DLA),这是一个专用的深度学习推理引擎,在 AGX Orin 平台上提供了三分之一的人工智能计算能力。
这篇文章深入探讨了使用 Orin 平台的嵌入式开发人员如何使用 YOLOv5 作为参考。要了解 DLA 如何帮助最大限度地提高深度学习应用程序的性能的更多信息,请参阅 Maximizing Deep Learning Performance on NVIDIA Jetson Orin with DLA。
YOLOv5 是一种对象检测算法。在 YOLOv3 和 YOLOv4 的成功基础上,YOLOv5 旨在提高实时目标检测任务的准确性和速度。YOLOv5 因其在准确性和速度之间的出色权衡而备受赞誉,成为计算机视觉领域研究人员和从业者的首选。其开源实现使开发人员能够利用预先训练的模型,并根据特定目标进行定制。
以下部分将介绍 end-to-end YOLOv5 cuDLA 示例,它将向您展示如何:
- 使用量化感知训练(QAT)训练 YOLOv5 模型,并将其导出以部署在 DLA 上。
- 使用 CUDA 到 TensorRT 和 cuDLA 部署网络并运行推理。
- 执行目标 YOLOv5 准确性验证和性能评测。
使用此示例,我们演示了如何使用 DLA INT8 在 COCO 数据集上实现 37.3 毫安时(官方 FP32 毫安时为 37.4)。我们还演示了如何在单个 NVIDIA Jetson Orin DLA 上获得超过 400 FPS 的 YOLOv5。(Orin 上共有两个 DLA 实例可用。)
DLA 的 QAT 培训和出口
为了平衡 YOLOv5 的推理性能和准确性,在模型上应用量化感知训练(QAT)是至关重要的。由于在撰写本文时,DLA 不支持通过 TensorRT 的 QAT,因此有必要在推理之前将 QAT 模型转换为训练后量化(PTQ)模型。步骤如图 1 所示。

QAT 培训工作流程
使用 TensorRT pytorch-quantization 量化 YOLOv5。第一步是将量化器模块添加到神经网络图中。此工具包提供 一套量化层模块 用于常见的 DL 操作。如果某个模块不在提供的量化模块中,则可以为模型中的正确位置创建自定义量化模块。
第二步是校准模型,获得每个量化/去量化(Q/DQ)模块的标度值。校准完成后,选择一个训练计划,并使用 COCO 数据集对校准后的模型进行微调。

添加 Q/DQ 节点
有两个选项可用于将 Q/DQ 节点添加到网络中:
选项 1:根据建议,将 Q/DQ 节点放置在 TensorRT 处理 Q/DQ 网络 中。该方法遵循用于 Q/DQ 层的 TensorRT 融合策略。这些 TensorRT 策略主要针对 GPU 推断进行调整。要使其与 DLA 兼容,请添加额外的 Q/DQ 节点,这些节点可以使用 Q/DQ 翻译器。
否则,任何丢失的标尺都会导致 FP16 中运行某些层。这可能导致 mAP 的轻微降低,并且可能导致大的性能下降。Orin-DLA 针对 INT8 卷积进行了优化,大约是 FP16 密集性能的 15 倍(或者当将密集 FP16 与 INT8 稀疏性能进行比较时为 30 倍)。
选项 2:在每一层插入 Q/DQ 节点,以确保所有张量都具有 INT8 标度。使用此选项,可以在模型微调期间获得所有层的比例。然而,当在 GPU 上运行推理时,这种方法可能会潜在地破坏具有 Q/DQ 层的 TensorRT 融合策略,并导致在 GPU 上出现更高的延迟。另一方面,对于 DLA,PTQ 量表的经验法则是,“可用量表越多,延迟就越低。”
实验证实,我们的 YOLOv5 模型在 COCO 2017 验证数据集上进行了验证,分辨率为 672 x 672 像素。选项 1 和选项 2 的 mAP 得分分别为 37.1 和 37.0。
根据您的需求选择最佳选项。如果您已经有了 GPU 的现有 QAT 工作流,并且希望尽可能多地保留它,那么选项 1 可能会更好。(您可能需要扩展 Q/DQ 转换器,以推断更多丢失的规模,从而实现最佳 DLA 延迟。)
另一方面,如果您正在寻找一种将 Q/DQ 节点插入所有层并与 DLA 兼容的 QAT 训练方法,选项 2 可能是您最佳的。
Q/DQ 翻译器工作流程
Q/DQ 翻译器的目的是将用 QAT 训练的 ONNX 图翻译为 PTQ 张量尺度和没有 Q/DQ 节点的 ONNX 模型。
对于该 YOLOv5 模型,从 QAT 模型中的 Q/DQ 节点提取量化尺度。使用相邻层的信息来推断其他层的输入/输出比例,例如 YOLOv5 的 SiLU 中的 Sigmoid 和 Mul 或 Concat 节点。提取刻度后,导出不带 Q/DQ 节点的 ONNX 模型和(PTQ)校准缓存文件,以便 TensorRT 可以使用它们来构建 DLA 引擎。
将网络部署到 DLA 进行推理
下一步是部署网络,并通过 TensorRT 和 cuDLA 使用 CUDA 运行推理。
带有 TensorRT 的可加载构建
使用 TensorRT 构建可加载的 DLA。这为 DLA 可加载建筑提供了一个易于使用的界面,并在需要时与 GPU 无缝集成。有关 TensorRT – DLA 的更多信息,请参阅 Working with DLA 在 TensorRT 开发人员指南中。
trtexec 是 TensorRT 提供的一个方便的工具,用于构建发动机和基准测试性能。请注意,DLA 可加载文件是通过 DLA 编译器成功编译 DLA 的结果,并且 TensorRT 可以将 DLA 可装载文件封装在序列化引擎中。
首先,准备 ONNX 模型和上一节中生成的校准缓存。DLA 可加载文件可以使用单个命令构建。通过 — 安全的选项,整个模型可以在 DLA 上运行。这直接将编译结果保存为可加载的串行 DLA(没有 TensorRT 引擎)。有关此步骤的更多详细信息,请参阅 NVIDIA 深度学习 TensorRT 文档。
trtexec --onnx=model.onnx --useDLACore=0 --safe --saveEngine=model.loadable --inputIOFormats=int8:dla_hwc4 --outputIOFormats=fp16:chw16 --int8 --fp16 --calib=qat2ptq.cache
请注意,从性能的角度来看,如果您的模型输入合格,强烈建议使用输入格式 dla_hwc4。输入最多必须有 四个输入通道并被卷积消耗。在 INT8 中,DLA 可以从特定的硬件和软件优化中受益,例如如果您使用 --inputIOFormats=int8:chh32。
使用 cuDLA 运行推理
cuDLA 是 DLA 的 CUDA 运行时接口,它是将 DLA 与 CUDA 集成在一起的 CUDA 编程模型的扩展。cuDLA 使您能够使用 CUDA 编程构造并提交 DLA 任务。您可以通过 TensorRT 运行时隐式地使用 cuDLA 运行推理,也可以显式地调用 cuDLA API。此示例演示了后一种方法,即显式调用 cuDLA API 以在 混合模式 和 独立模式 中运行。
cuDLA 混合模式和独立模式主要在同步方面不同。在混合模式中,DLA 任务被提交到 CUDA 流,因此可以与其他 CUDA 任务无缝地进行同步。
在独立模式下cudlaTask结构有一个规定,指定 cuDLA 必须分别等待和发出信号的等待和信号事件,作为cudla 提交任务。
简而言之,使用 cuDLA 混合模式可以快速集成其他 CUDA 任务。使用 cuDLA 独立模式可以防止 CUDA 上下文的创建,因此在管道没有 CUDA context 的情况下可以节省资源。
YOLOv5 示例中使用的主要 cuDLA API 如下所示。
- cudlaCreateDevice 创建 DLA 设备。
- cudlaModuleLoadFromMemory 用于加载引擎内存以供 DLA 使用。
- cudaMalloc 和 cudlaMemRegister 被调用以首先在 GPU 上分配内存,然后让 CUDA 指针向 DLA 注册。(仅用于混合动力模式。)
- cudlaImportExternalMemory 和 cudlaImportExternalSemaphore 被调用以导入外部 NvSci 缓冲区和同步对象。(仅用于独立模式。)
- cudlaModuleGetAttributes 从加载的模块中获取模块属性。
- cudlaSubmitTask 用于提交推理任务。在混合模式下,用户需要指定 CUDA 流,以便 cuDLA 任务在其上运行。在独立模式下,需要指定信号事件和等待事件,以便 cuDLA 在相应的围栏到期时等待并发出信号。
目标验证和分析
注意 GPU 与 DLA 之间的数值差异非常重要。底层硬件不同,因此计算并不精确。因为训练网络是在 GPU 上完成的,然后部署到目标上的 DLA,所以在目标上进行验证很重要。当涉及到量化时,这一点尤其重要。与参考基线进行比较也很重要。
YOLOv5 DLA 准确性验证
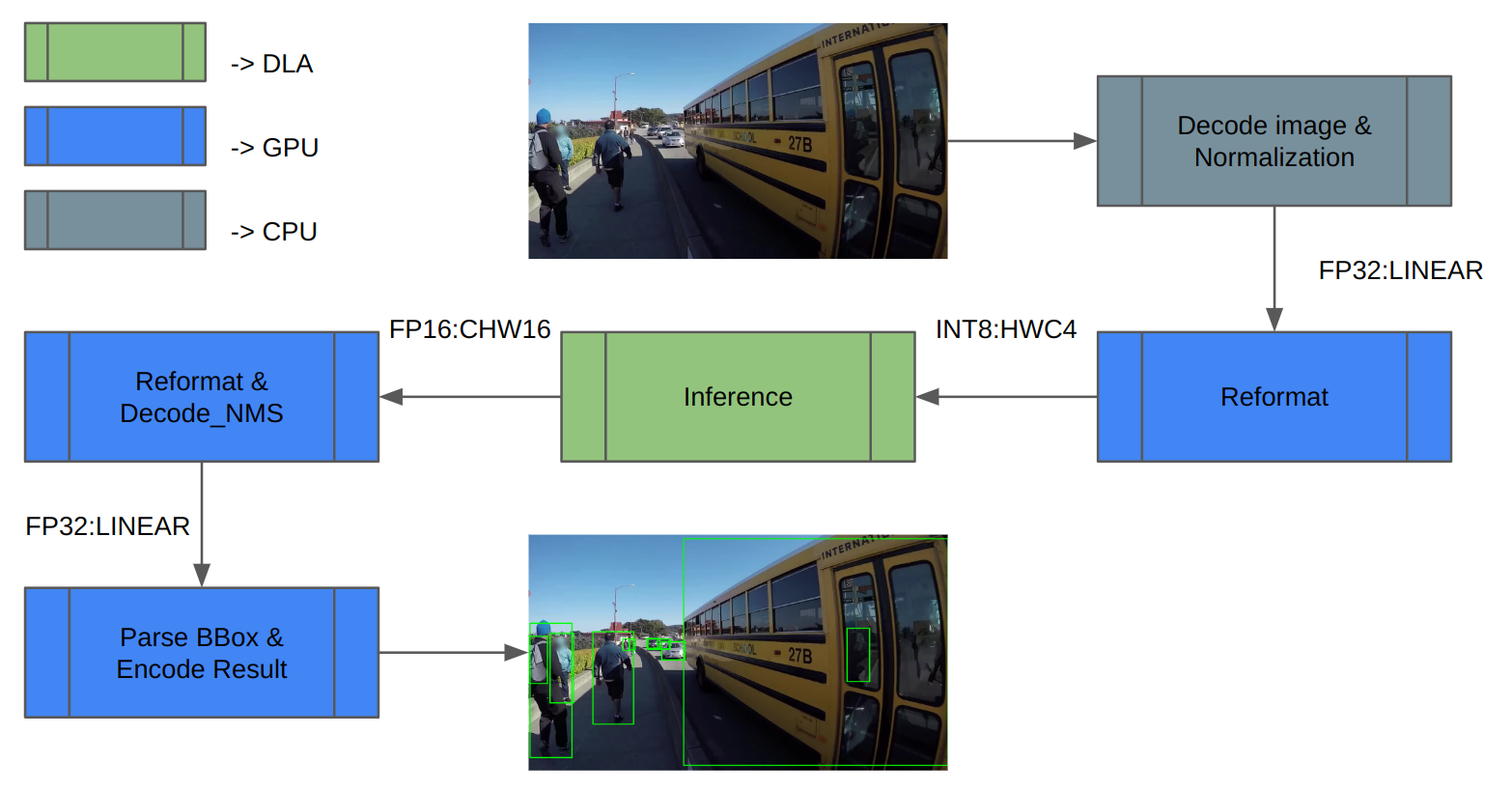
我们使用 COCO 数据集进行验证。图 3 显示了推理管道体系结构。首先,加载图像数据并对其进行归一化。由于 DLA 仅支持 INT8/FP16,因此需要对推理输入和输出进行额外的重新格式化。
推理后,对推理结果进行解码,并执行 NMS(非最大值抑制)以获得检测结果。最后,保存结果并计算 mAP。
在 YOLOv5 的情况下,最后三个卷积层的特征图对最终检测信息进行编码。当量化为 INT8 时,与 FP16/FP32 相比,边界框坐标的量化误差变得明显,从而影响最终的 mAP。
我们的实验表明,在 FP16 中运行最后三个卷积层将最终 mAP 从 35.9 提高到 37.1。Orin DLA 具有针对 INT8 高度优化的特殊硬件设计,因此当这三个卷积在 FP16 中运行时,我们观察到性能下降。
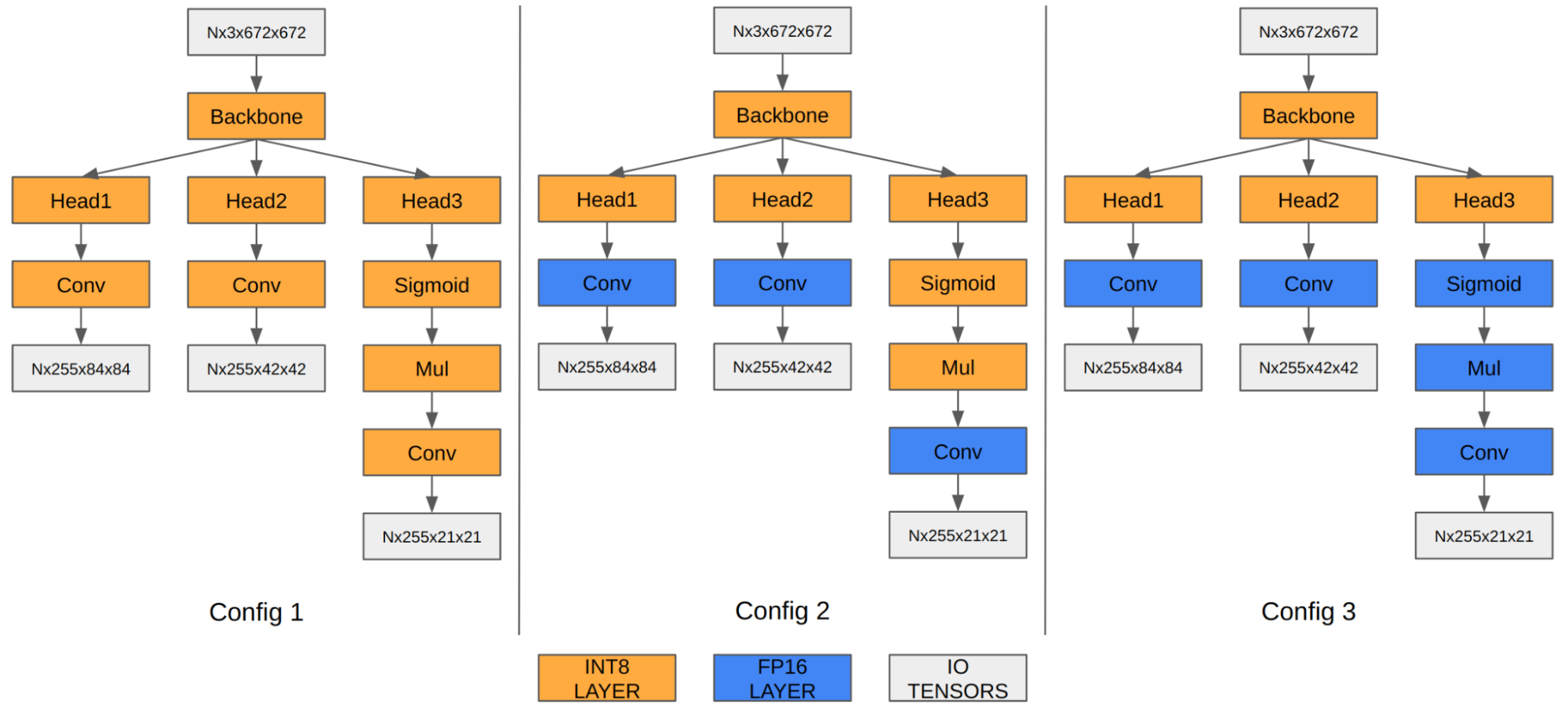
| 配置 1 | 配置 2 | 配置 3 | |
| 输入张量格式 | INT8:DLA_HWC4 | INT8:DLA_HWC4 | INT8:DLA_HWC4 |
| 输出张量格式 | INT8:chh32 | FP16:CHW16 | FP16:CHW16 |
| COCO Val mAP | 35.9 | 37.1 | 37.3 |
| FPS(DLA 3.14.0,1.33 GHz 时为 1x DLA,3.2 GHz 时为 EMC) | 410 | 255 | 252 |
注意,mAP 结果基于前面关于添加 Q/DQ 节点的部分中描述的选项 1。您也可以将相同的原则应用于选项 2。
YOLOv5 DLA 性能
得益于两个 DLA 核心,DLA 在 Orin AGX 平台上提供了三分之一的人工智能计算能力。如果您想了解有关 Orin DLA 性能的一般基线,请参阅 Deep-Learning-Accelerator-SW 在 GitHub 上的信息。
在最新版本 DLA 3.14.0(DOS 6.0.8.0 和 JetPack 6.0)中,DLA 编译器添加了几个性能优化,专门适用于基于 INT8 CNN 体系结构的模型:
- 原生 INT8 Sigmoid(之前在 FP16 中运行,必须在 INT8 之间铸造;也适用于 Tanh)
- INT8 SiLU 融合到单个 DLA 硬件操作中(而不是独立的 Sigmoid 加上独立的 elementwise Mul)
- 将 INT8 SiLU 硬件操作与之前的 INT8 Conv 硬件操作融合(也适用于独立的 Sigmoid 或 Tanh)
与之前的版本相比,这些改进可以为 YOLO 架构提供 6 倍的加速。例如,在 YOLOv5 的情况下,INT8 中的推理性能从 13ms 提升到 2.4ms(FP16 中运行了一些层),这是 5.4 倍的改进。此外,您可以使用 cuDLA 示例 以逐层分析 DNN,识别瓶颈,并修改网络以提高其性能。
DLA 入门
这篇文章解释了如何在 Orin 的专用深度学习加速器上使用 YOLOv5 以最有效的方式运行整个对象检测管道。请记住,其他 SoC 组件,如 GPU ,要么处于空转状态,要么在非常小的负载下运行。如果您有一个以每秒 30 帧的速度产生输入的相机,那么一个 DLA 实例将仅以大约 10%的速度加载。因此,有足够的空间为您的应用程序添加更多的功能。
准备好潜水了吗?YOLOv5 示例复制了这里讨论的整个工作流程。您可以将其用作您自己的用例的参考点。
对于初学者来说,在 GitHub 上的 Jetson_dla_tutorial 展示了一个基本的 DLA 工作流程,以帮助您开始部署一个简单的 DLA 模型。
如需获取更多关于如何最大限度地利用 DLA 的示例和资源,请访问 NVIDIA DRIVE 或 NVIDIA Jetson,或者访问在 GitHub 上的 Deep-Learning-Accelerator-SW。有关 cuDLA 的更多信息,请访问 Deep-Learning-Accelerator-SW/samples/cuDLA。