
你有没有试过在你的口音上微调语音识别系统,结果发现,虽然它能很好地识别你的声音,但却无法检测到别人说的话?这在经过数十万小时语音训练的语音识别系统中很常见。
在大规模 自动语音识别 ( ASR )中,系统可能在许多但不是所有场景中都表现良好。例如,在嘈杂的环境中,它可能需要更高的精度。或者,它可能需要为具有浓重口音或独特方言的用户进行调整。
在这种情况下,一种简单的方法是根据特定领域的样本对模型进行微调。尽管如此,这个过程可能会严重损害模型在一般语音上的准确性,因为它会过度填充新的域。
本文提出了一种选择模型的简单方法,该模型可以在 adapter modules 和 基于传感器的语音识别系统 的帮助下平衡普通语音的识别精度,并改进自适应域上的识别。
基于适配器模块和传感器的语音识别系统
神经网络通常由多个模块组成;例如在语音识别或自然语言处理( NLP )中通常使用的编码器和解码器模块。虽然可以微调这些模块中的所有数百万个参数,但使用适配器模块的参数高效训练可以减少灾难性遗忘的影响,并仍然提供强大的结果。
图 1 显示了基于传感器的语音识别系统的三个主要模块,包括 conformer 编码器、 LSTM 解码器(称为传感器解码器)和多层感知器接头(也称为传感器接头)。它还显示了适配器如何应用于这些组件。
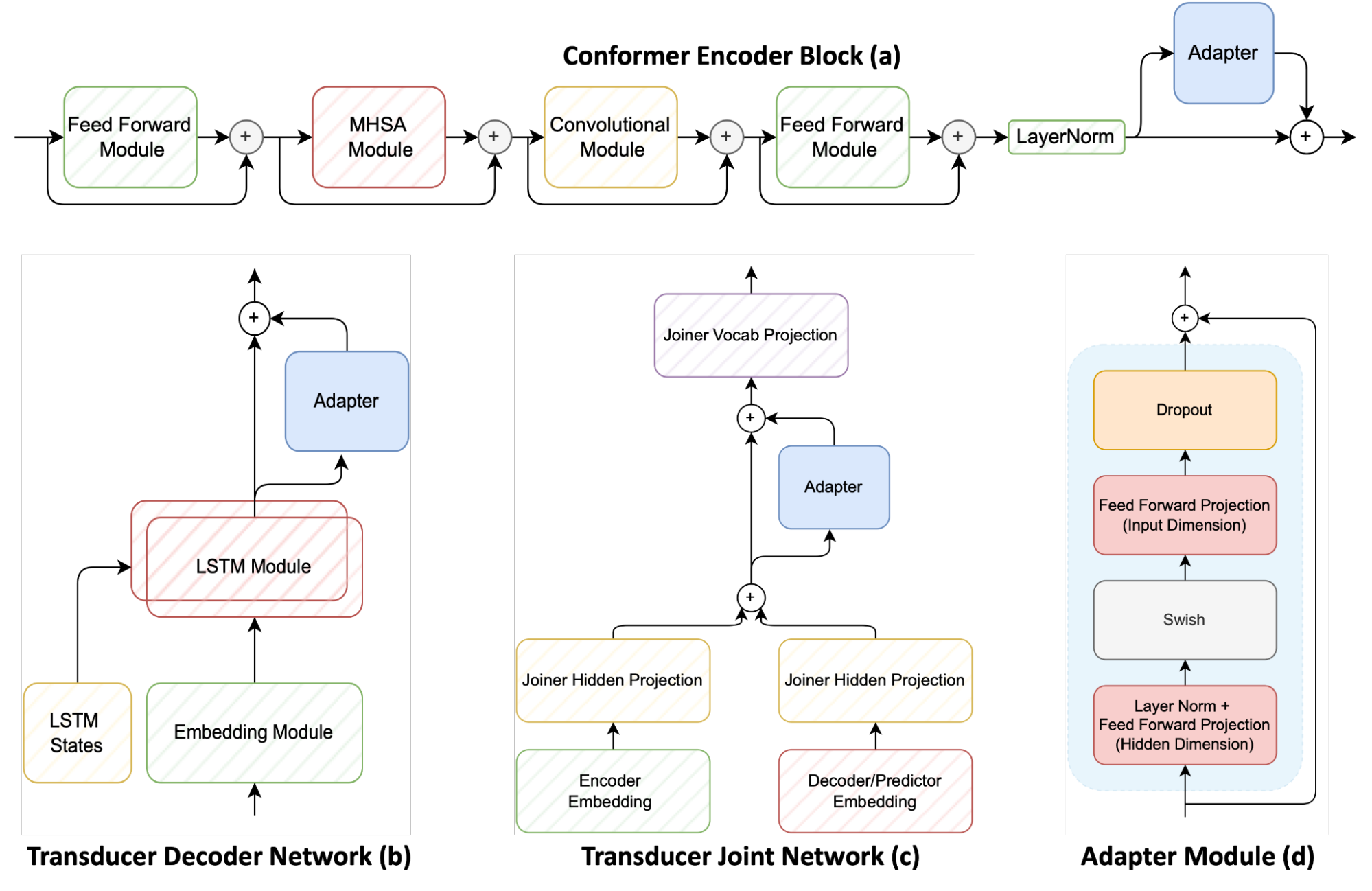
适配器模块( d )可以是连接到预训练神经网络的简单前馈网络。这样做会将其他模型参数添加到原始模型中。然后冻结原始模型参数并仅训练适配器参数。
适配器网络通常放置在每个编码器一致性层( a )上。然而,该方法建议将适配器添加到换能器解码器( b )和换能器联合网络( c ),以提供与普通语音相比在适应新域之间的精细控制。
在训练多个候选模型之后,有必要确定哪个模型在新域(例如,具有新方言、口音或噪声环境)的识别精度和通用语音的精度方面具有最佳折衷。
在原始域和新域的评估数据集上测量模型适应前后的精度的简单方法如下:
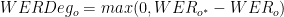
- o* , a* 表示在适配过程之后对原始和适配域的评估
- o 、 a 表示在适配过程之前相同
首先,将 WERDeg 定义为自适应前后的单词错误率( WER )之间的差异。还要确保模型在适应后必须改进 WER 。否则,该值应为 0 。

- N 是原始域中评估数据集的数量
- K 是原始域上字错误率的最大容许绝对降级
接下来,计算原始数据集上模型的有效相对退化。首先为 K 选择一个值,即可以接受的最大容许退化。在本例中, 3% 是最大容许降解率。
然后计算原始数据集上 K 和 WERDeg 之间的相对差值( o )。最后,将原始域中 N 个评估数据集的所有得分相加。如果在任何数据集上,模型超过退化极限 K ,则将该数据集的得分设置为 0 。
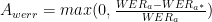
- 新领域 WER 的相对改进
- 下标指的是在将模型训练到自适应数据集之前( a )还是之后( a* )在自适应数据集上计算度量
接下来,在自适应数据集上计算模型的相对改进。在本例中,选择了相对权重,因为在某些情况下,在已优化的生产系统中,即使是很小的改进也可能是显著的。

然后将得分度量计算为两个度量的简单乘法。在最大化时对度量进行评分会产生在新域上获得最大改进、在旧域上退化最小的候选。
适配器对方言适应的有效性
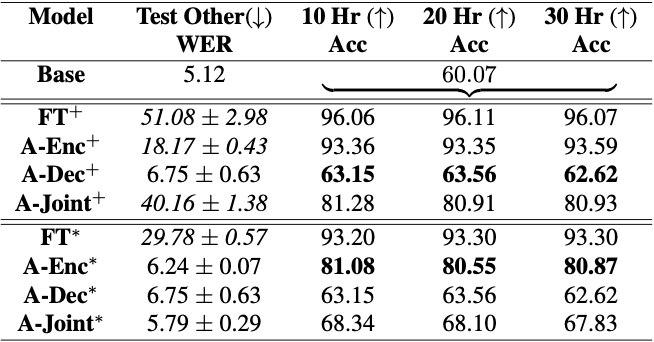
为了评估适配器在这种受限域适配设置中的有效性,在英国和爱尔兰英语方言数据集上适配一个 1.2 亿参数的 conformer 传感器模型。结果如图 2 所示。
虽然简单的微调会快速损害普通语音的识别精度,但适配器可以提供与模型的完全微调类似的结果,而不会对普通语音造成显著恶化。
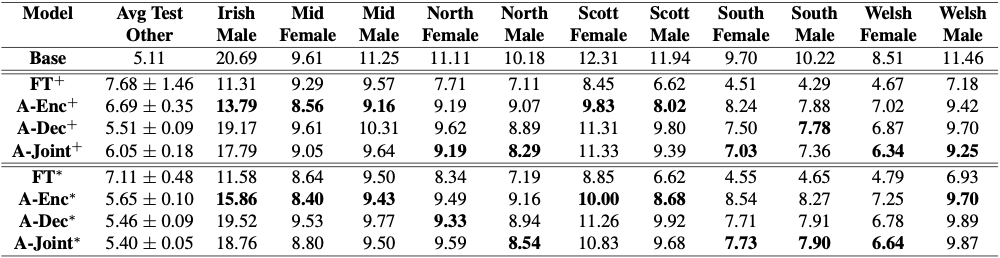
在图 2 中,+表示模型无约束自适应(无限制微调),*表示受限域自适应。完全微调在新领域获得最佳结果,但严重损害了通用语音识别。
粗体单元格表示最大化先前定义的评分度量的候选项,从而在新域上获得强大的结果,同时最小化对一般语音识别的损害。在开放词汇语音命令识别这一具有挑战性的任务中,受限域自适应的效果更为明显。
语音命令识别
接下来,语音识别模型适用于 Google 语音命令数据集中的 35 个命令词。这 35 个命令是执行动作的常用词,例如“走”、“停止”、“开始”和“离开”这些命令词都是 Librispeech 训练数据集的一部分,因此一个高度鲁棒的 ASR 模型应该很容易对这些词进行分类。然而,与最先进的语音分类模型相比,该模型的准确率大约只有 60% ,而最先进的语言分类模型可以达到接近 97% 。
人们会认为,仅限于 35 个单词的语音识别比学习转录数千小时的语音更容易。事实上,这可以扩展到“开放词汇语音命令识别”,这是一项任务,在该任务中,语言中的任何单词都可以成为模型识别的命令。
例如,假设您希望一个模型识别一个用户,并在该用户说“打开芝麻”时激活。在这种情况下收集数据非常困难,但这些单词在大型 ASR 数据集中可能足够常见,因此 ASR 模型应该高精度地识别这些单词。然而,这远比预期的更具挑战性。
适应开放词汇关键词检测的语音识别模型
这一挑战的原因是,与特定命令相比,转录一般语音的准确性存在巨大差异。这是因为模型的训练方式与评估方式不同。
训练语音识别模型需要使用包含几十个单词的 15-20 秒长的样本。然而,当执行语音命令识别时,这些模型仅用 1 秒的音频进行训练和评估。训练和评估团的这一大规模转变严重影响了模型,导致了通用语音识别的灾难性退化。
如果你试图进行不受约束的改编,模型几乎忘记了如何转录一般语音。然而,当使用适配器在受限场景下进行训练时,您可以快速提高命令的识别精度,同时保持对普通语音的强大识别能力。
开放词汇命令识别的约束自适应
图 3 显示了使语音识别系统适应开放词汇命令识别数据的困难。只要对整个模型进行微调, WER 就会从 5% 增加到近 30-50% ,从而使模型完全无法使用。尽管如此,它在数据集上的准确性从 60% 显著提高到 96% 。然后施加约束自适应,并获得在其先前的一般语音识别知识与准确检测语音命令之间取得平衡的候选。
Conclusion
在受限域自适应的情况下,只需少量数据即可自适应任何预训练模型。使用适配器进行参数有效训练可以减少一般语音识别中灾难性遗忘的影响。这一点可以通过适应大量的英语和爱尔兰方言来体现。此外,使用这些技术可以提高开放词汇语音命令识别的准确性。
语音识别系统适应其部署的定制需求是一项重要的努力。获得更有效的方法来动态适应大型模型将实现高效的语音识别。很快有一天,可能只需要几分钟的适应数据就可以为每个用户个性化语音识别系统,同时保持其总体准确性而不会显著降低。
有关此工作的更多信息,请参见 基于传感器的自动语音识别领域自适应过程中的损伤控制 。
要了解有关如何使用适配器使 ASR 模型适应新域的更多信息,请访问 GitHub 上的 ASR_with_Adapters.ipynb NVIDIA NeMo 教程。




