
NVIDIA GPU 持续提升的计算吞吐量为优化视觉 AI 工作负载带来了新的机遇:让硬件持续高效地处理数据。随着 GPU 性能的不断增强,传统的数据流水线环节——如来自存储的 I/O、主机与设备间的数据传输(PCIe),以及依赖 CPU 的解码和图像缩放等处理——往往难以跟上步伐。这种性能不匹配可能导致加速器因等待数据而空转,形成所谓的 GPU 饥饿问题。要弥合数据与张量之间的鸿沟,亟需构建更智能的数据流水线,其设计必须与现代高性能硬件的能力相匹配,以实现端到端的高效协同。
本文将介绍 SMPTE VC-6(ST 2117-1)的 NVIDIA CUDA 加速实现。VC-6 是一款专为大规模并行计算设计的编解码器,其原生特性(如分层结构、多分辨率支持以及选择性解码与数据获取)天然契合 GPU 的并行架构。通过将编解码器内在的并行性直接映射到 GPU 架构,我们能够构建一条从压缩数据到模型就绪张量的高效处理路径。本文还将展示从 CPU 和 OpenCL 实现转向 CUDA 实现所带来的性能提升,说明该方法如何助力高性能 AI 应用更便捷地实现加速解码。
VC-6 是什么?
SMPTE VC-6 是一项为图像和视频编码设计的国际标准,从底层架构上便针对现代计算平台(尤其是 GPU)实现了直接且高效的交互。与将图像编码为单一平面像素块的传统方法不同,VC-6 能够生成高效的多分辨率层次结构。图 1 展示了一个示例,呈现了在 8K、4K 和全高清等不同分辨率之间实现的二阶降采样过程。
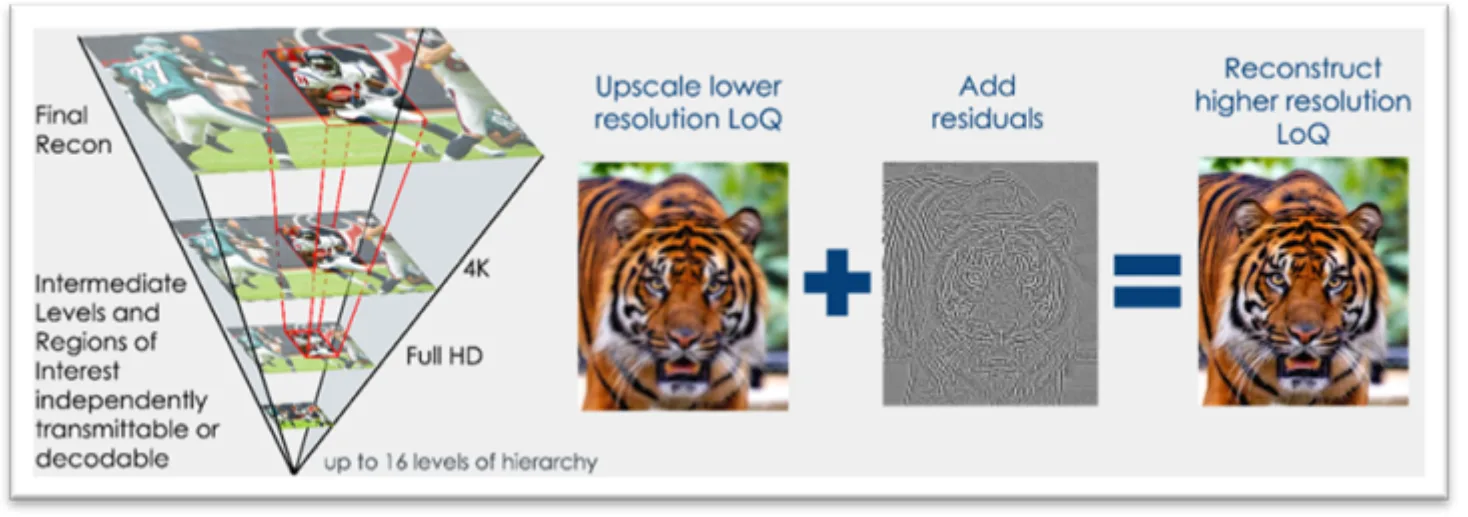
编码过程的工作原理如下:
- 源图像会递归下采样以创建多个层,称为梯队,每个层代表不同的质量级别 (LoQ) 。
- 最小梯队用作低分辨率,即根 LoQ,并直接编码。
- 编码器然后向上重建。对于每个更高的级别,它会对低分辨率版本进行上采样,并从原始版本中减去该版本,以捕获差值或残差。
- 最后一个比特流包含根 LoQ 和这些连续的残差层。
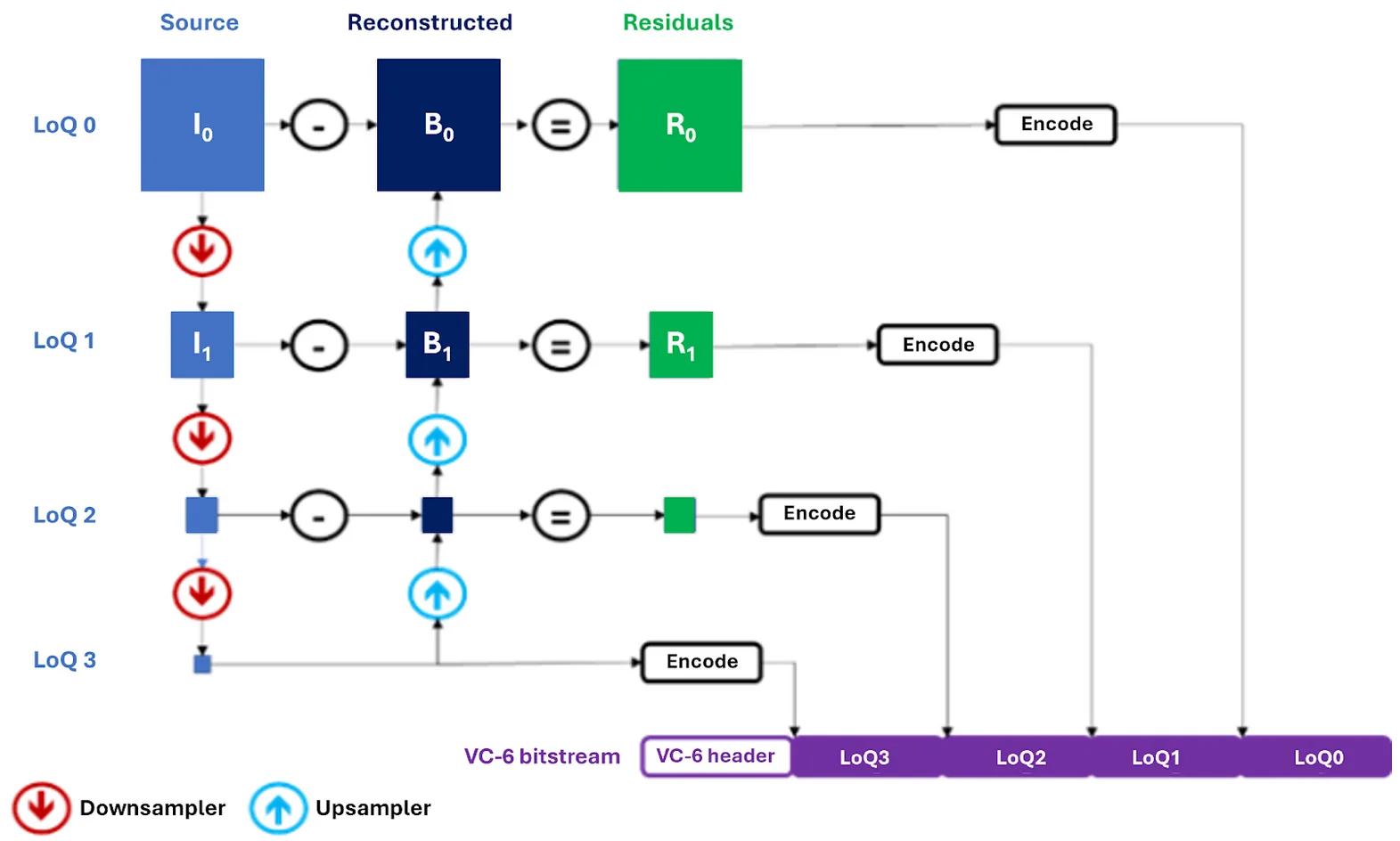
VC-6 解码器能够在每个 LoQ 中连续执行逆向过程:从根 LoQ 开始,依次上采样至下一个 LoQ,并叠加相应的残差,直至达到目标分辨率或指定的 LoQ。重要的是,各个组件——无论是彩色平面、梯队,还是特定的图像图块——均可独立访问并并行解码。该架构为开发者提供了更高的灵活性与处理效率。
- 仅传输重要的字节,从而减少 I/ O、带宽、内存使用量和内存访问,同时更大限度地提高吞吐量。
- 在任何 LoQ 下,仅对所需内容进行解码,生成的张量更接近模型所需的输入大小,而无需完全解码和调整大小。
- 访问每个 LoQ 内的特定关注区域 (RoI) ,而不是处理整个帧,从而节省大量计算,
下表总结了 VC-6 架构的主要优势:
| 特征 | SMPTE VC-6 (ST 2117) |
| 核心架构 | 分层、S-Tree 预测、并行。 |
| 选择性数据召回 | 原生支持。 位流结构仅允许获取部分请求所需的字节。 |
| 选择性分辨率 (LoQ) 解码 | 原生支持。 作为分层 LoQ 结构的内在特性,生成接近目标大小的表面,而不完全解码 = resize。 |
| RoI 解码 | 原生支持。 作为可导航 S 树结构的一部分,只提取对模型阶段至关重要的图块。 |
| 并行解码能力 | 大规模并行。 独立于平面/ LoQ/ 平铺残差可实现精细的 GPU 并行。 |
| 最大位深度 | 每个组件最多支持 31 位。 |
| 多平面支持 | 原生,最多支持 255 个平面 (例如 RGB、alpha、深度) 。 |
如表所示,VC-6 原生支持选择性分辨率、感兴趣区域(RoI)解码,特别是选择性数据召回,因此非常适用于对效率和针对性数据访问要求较高的 AI 工作流。
通过部分数据调用减少 I/ O
除了解码速度之外,VC-6 的选择性数据调用能力还显著降低了 I/O 开销。传统编解码器通常需要读取整个文件,即使只需要生成低分辨率输出也不例外。而使用 VC-6 时,只需读取目标 LoQ(质量层级)、RoI(感兴趣区域)或特定平面(如特定色彩分量)所需的字节即可。对于 CPU 解码而言,这意味着从网络或存储传输到内存的数据量大幅减少;在 GPU 解码场景中,同样有助于缓解 PCIe 带宽压力并降低显存占用。
如图3所示,在DIV2K数据集的前100张图像(其中一维为2040像素,另一维尺寸可变)上,我们观察到:
- LoQ1 (中等分辨率,1020 像素) 传输约占文件总字节数的 ~63%。
- LoQ2 (低分辨率,510 像素) 传输率约为 ~27%。
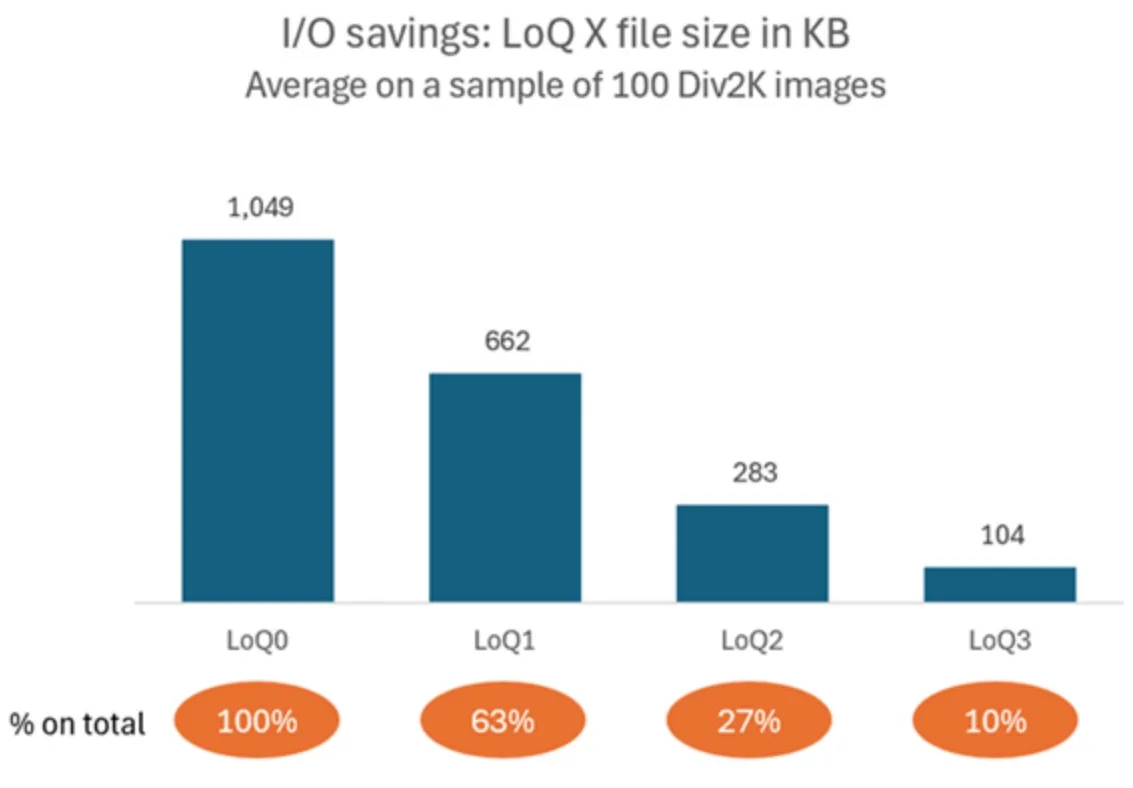
与全分辨率相比,这种方法可分别节省 37% 和 72% 的 I/O 成本,相应地降低了 网络、存储、PCIe 和内存的流量。随后,您可以按需加载其余层,若感兴趣区域(RoI)较小,则只需获取对应的图块,而无需对整个文件进行后处理。对数据加载器而言,这是一种无需修改模型代码即可提升吞吐量或增大批量大小的高效方法。
将 VC-6 映射到 GPU:并行性的自然拟合
VC-6 的架构与 GPU 的单指令多线程(SIMT)执行模型高度契合。其设计有意减少模块间的依赖关系,以支持大规模并行计算。
- 独立于组件: 图像数据分为图块、平面和梯级,可独立处理。VC-6 编码独立图块解码所需的信息,支持并行处理数十万个图块,同时对压缩效率的影响微乎其微。
- 简单的本地操作: 与使用基于块的 DCT 或小波的编解码器不同,VC-6 的核心像素转换在独立的小型 2 × 2 像素邻域上运行,从而简化 GPU 内核设计。
- 显存效率: 编码本质上是大规模并行的,并且查找具有非常低的显存占用,其中的表足够小,可以容纳共享内存甚至寄存器,因此该过程非常适合 SIMT 执行。
尽管“层次结构”一词可能暗示串行处理,但VC-6通过整合两个在很大程度上相互正交的维度上运行的层次结构,构建了独特的并发处理架构,从而显著降低了各部分之间的相互依赖性。
这种架构并行最初应用于 CPU 和 OpenCL 版本中,以支持低延迟、随机访问的视频编辑工作流,同时也非常契合 AI 对高吞吐量的需求。
AI 训练流程旨在最大化吞吐量,通常借助 PyTorch DataLoader 等框架生成并行进程,以掩盖数据加载延迟。与高级图像编辑系统类似,这些 AI 工作流也需要能够快速、按需访问图像的不同分辨率和局部区域。为满足这一需求,加速相关功能成为开发专用 CUDA 实现的核心驱动力。通过原生 CUDA 库的支持,可实现针对性优化,充分释放 VC-6 在 AI 生态系统中的架构优势,进一步提升整体吞吐能力。
支持 CUDA 加速的 VC-6 Python 库
V-Nova 与 NVIDIA 合作,针对 CUDA 平台优化了 VC-6,充分认可其在 AI 生态系统中的广泛影响力。将 VC-6 从 OpenCL 移植至 CUDA,不仅实现了与 PyTorch 等主流工具的无缝集成,也更好地融入了完整的 AI 工作流,避免了额外的 CPU 数据复制和同步开销。
将 VC-6 迁移到 CUDA 具备以下几项关键优势:
- 更大限度地减少开销: 它避免了 AI 工作负载和 OpenCL 实现之间昂贵的上下文切换开销。
- 增强互操作性: 可与 CUDA Tensor 生态系统直接集成。CUDA 流无需 CPU 同步即可实现内存交换。
- 解锁高级分析: 它支持使用 NVIDIA Nsight Systems 和 NVIDIA Nsight Compute 等强大工具来识别和解决性能瓶颈。
- GPU 硬件内部函数: 借助 CUDA,您可以使用 NVIDIA GPU 上所有可用的硬件内部函数。
当前的 VC-6 CUDA 路径处于 Alpha 版本,支持原生批处理,并依托 CUDA 实现了路线图中的多项优化,这些进展得益于不断增长的 AI 需求推动。即便在现阶段,其性能已显著优于 OpenCL 和 CPU 的实现,为后续的开发与优化奠定了坚实基础。
安装和使用
VC-6 Python 包以预编译的 Python wheel 形式发布,可通过 pip 直接安装。安装完成后,您即可创建 VC-6 编解码器对象,并开始进行编码、解码和转码操作。以下展示了如何对 VC-6 码流进行编码和解码的示例(更多完整示例请访问我们的 GitHub 仓库):
from vnova.vc6_cuda12 import codec as vc6codec # for CUDA
# from vnova.vc6_opencl import codec as vc6codec # for OpenCL
# from vnova.vc6_metal import codec as vc6codec # for Metal
# setup encoder and decoder instances
encoder = vc6codec.EncoderSync(1920, 1080, vc6codec.CodecBackendType.CPU, vc6codec.PictureFormat.RGB_8, vc6codec.ImageMemoryType.CPU)
encoder.set_generic_preset(vc6codec.EncoderGenericPreset.LOSSLESS)
decoder = vc6codec.DecoderSync(1920, 1080, vc6codec.CodecBackendType.CPU, vc6codec.PictureFormat.RGB_8, vc6codec.ImageMemoryType.CPU)
encoded_image = encoder.read("example_1920x1080_rgb8.rgb")
decoder.write(encoded_image.memoryview, "recon_example_1920x1080_rgb8.rgb")
GPU 显存输出
对于 CUDA 包(vc6_cuda12),解码器输出支持生成 CUDA 数组接口。要启用该功能,请在创建解码器时将输出显存类型指定为 GPU_DEVICE。此时,输出图像将具备 __cuda_array_interface__ 属性,可与 CuPy、PyTorch 和 nvImageCodec 等其他库无缝协作。
from vnova.vc6_cuda12 import codec as vc6codec # for CUDA only
import cupy # setup GPU decoder instances with CUDA device output
decoder = vc6codec.DecoderSync(1920, 1080, vc6codec.CodecBackendType.CPU, vc6codec.PictureFormat.RGB_8, vc6codec.ImageMemoryType.CUDA_DEVICE)
# decode from file
decoded_image = decoder.read("example_1920x1080_rgb8.vc6")
# Make a cupy array from decoded image, download to cpu and write to file
cuarray = cupy.asarray(decoded_image)
with open("reconstruction_example_1920x1080_rgb8.rgb") as
decoded_file.write(cuarray.get(),
"reconstruction_example_1920x1080_rgb8.rgb")
对于同步和异步解码器,访问 __cuda_array_interface__ 时会受到阻碍,系统将默认等待图像结果准备就绪。
__cuda_array_interface__ 始终包含一维的无符号 8 位类型数据,与 CPU 版本类似。用户可根据需要调整尺寸(若为 10 位格式,则需相应调整数据类型)。
部分解码与 I/O 操作
若要执行部分解码,解码器函数需要支持可选参数,以指定目标区域。以下示例中,解码器将仅读取并处理解码四分之一分辨率图像所需的数据。
# Read and decode quarter resolution (echelon 1) FrameRegion can also be used to describe a target rectangle
decoded_image = decoder.read("example_1920x1080_rgb8.vc6", vc6codec.FrameRegion(echelon=1)
其他解码函数在内存而非文件路径上运行,同样可实现部分数据的调用。为此,我们在 VC6 库中提供了实用工具函数,用于单独读取文件头并返回目标 LoQ 所需的内存大小。具体用法参见 GitHub 上的示例。
性能基准测试:CPU 与 OpenCL 和 CUDA 的比较
我们采用 DIV2K 数据集(共 800 张图像),在 NVIDIA RTX PRO Blackwell 服务器上对 VC 6 进行了评估,测量了 CPU、OpenCL(GPU)和 CUDA 实现下不同 LoQ 的单图像解码耗时。在批量测试中,我们采用“伪批量”方法,通过并行执行多个异步的单图像解码器来模拟本地批处理,以充分提升吞吐量。相同的测试环境可用于结果复现,如图 4 所示。
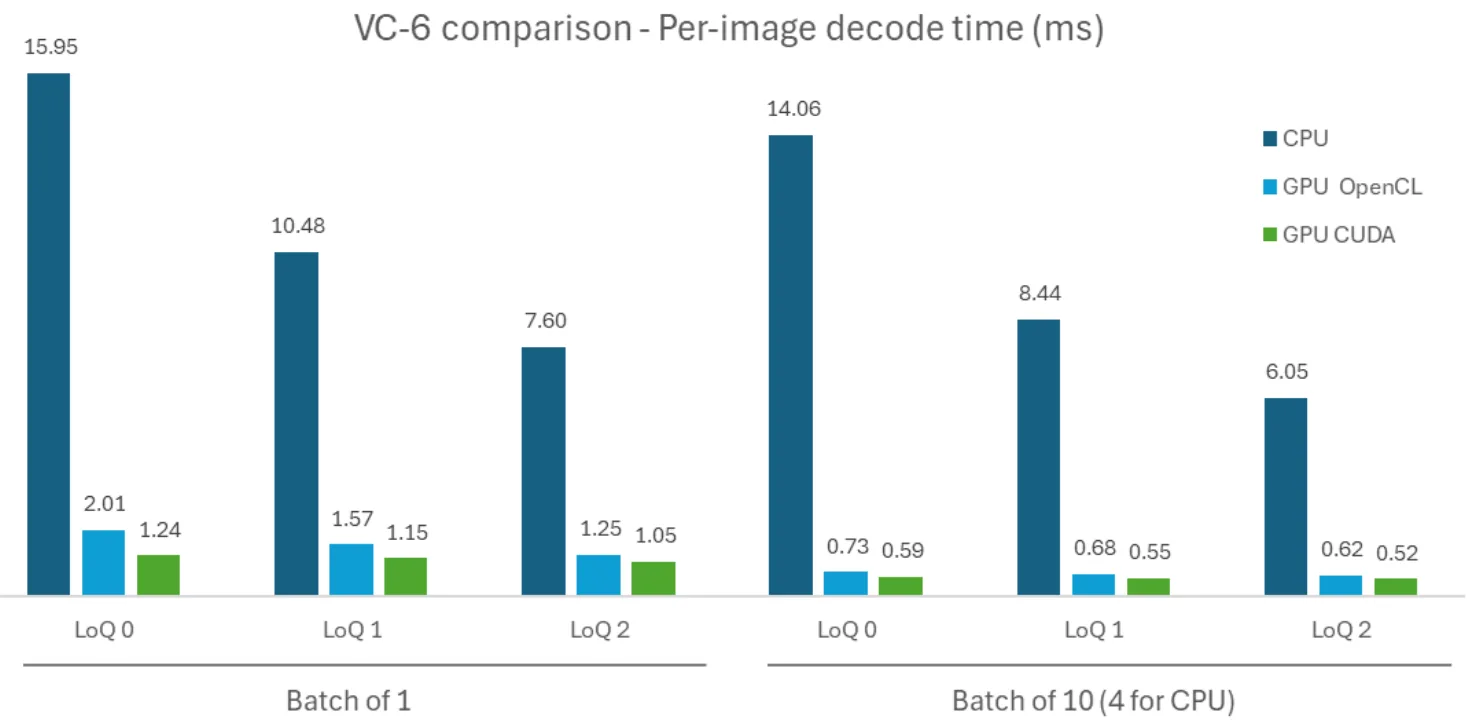
转向 CUDA 之后,性能得到了显著提升。
- 对于单图像解码,CUDA 的速度比 CPU 快 13 倍 (分别为 1.24 毫秒和 15.95 毫秒) 。
- 与现有 GPU 实现相比,CUDA 版本的速度比 OpenCL 快 1.2 到 1.6 倍。未来,CUDA 将使更多人能够访问可利用的专用硬件内部函数。
- 随着在所有平台上进行批处理,效率得到提高,我们希望原生批量解码器能进一步提高。
使用 Nsight 进行分析以及未来发展方向
Nsight Systems 展示了 CPU(位流解析、根节点)与 GPU (平铺残差解码、重建)之间的解码任务划分。低延迟设计通过优化单图像处理路径,充分发挥 GPU 的优势,而在吞吐量模式下,CUDA 的性能表现尤为突出。我们的优化方案以三个关键瓶颈为指导。
- 内核 = 上采样链中的启动用度: 在低 LoQ 下,小型内核与启动用度交错。CUDA 图形原型可显著缩小内核之间的差距。我们还在探索从未使用过中间体的早期 LoQ 中的核聚变。
- 内核效率: 在某些阶段,Nsight Compute 会标记分支差异、寄存器溢出和非合并 IO。清理这些数据将会提高占用率和吞吐量。
- 内核级并行: 目前,每次解码都会启动自己的内核链,与扩展启动网格维度相比,这还不够。每个镜像都会启动一系列内核,但由于 GPU 上并发内核的限制,这些内核无法完美扩展。
上采样链
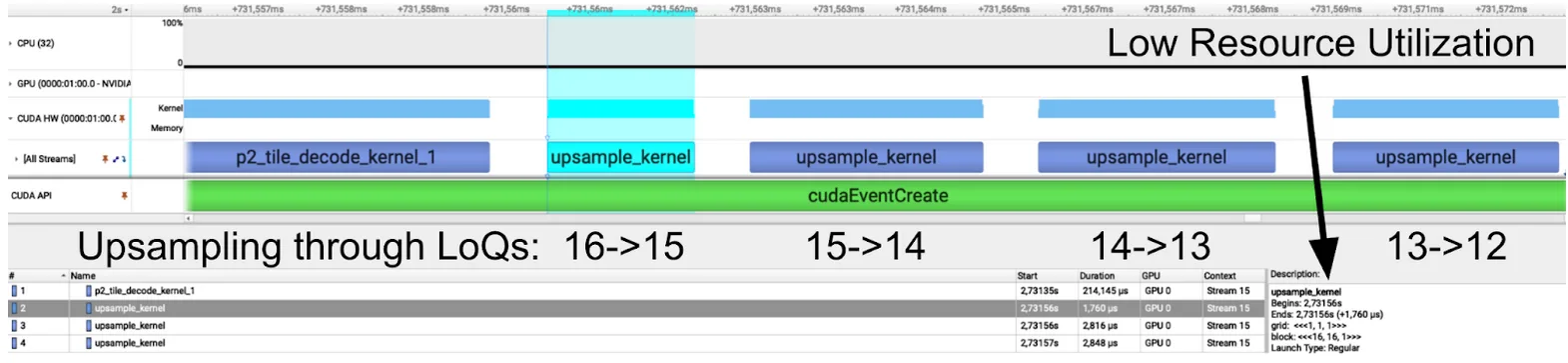
核函数的上采样链(图5)能够在连续较高的LoQ下实现图像重建。在较低的LoQ下,有用计算(蓝色)与用度(白色)的比例尤为显著。通过采用CUDA图形或内核融合等技术,可减少各内核之间的用度,从而加快计算速度。
由于网格尺寸较小,Nsight 追踪显示 GPU 利用率偏低。特别是第一个上采样核函数仅启动了一个线程块,而该线程块只占用了一个流多处理器(SM)。在拥有 188 个 SM 的 RTX PRO 6000 上运行时,解码单张图像几乎仅使用了 1/188th 的 GPU 资源。
从理论上讲,这将使我们能够利用 GPU 额外的第 187 或第 188 个核心并行解码其他图像。但在实践中,这种方式被称为“内核级并行”,并非充分利用 NVIDIA GPU 的理想方法。
内核级并行
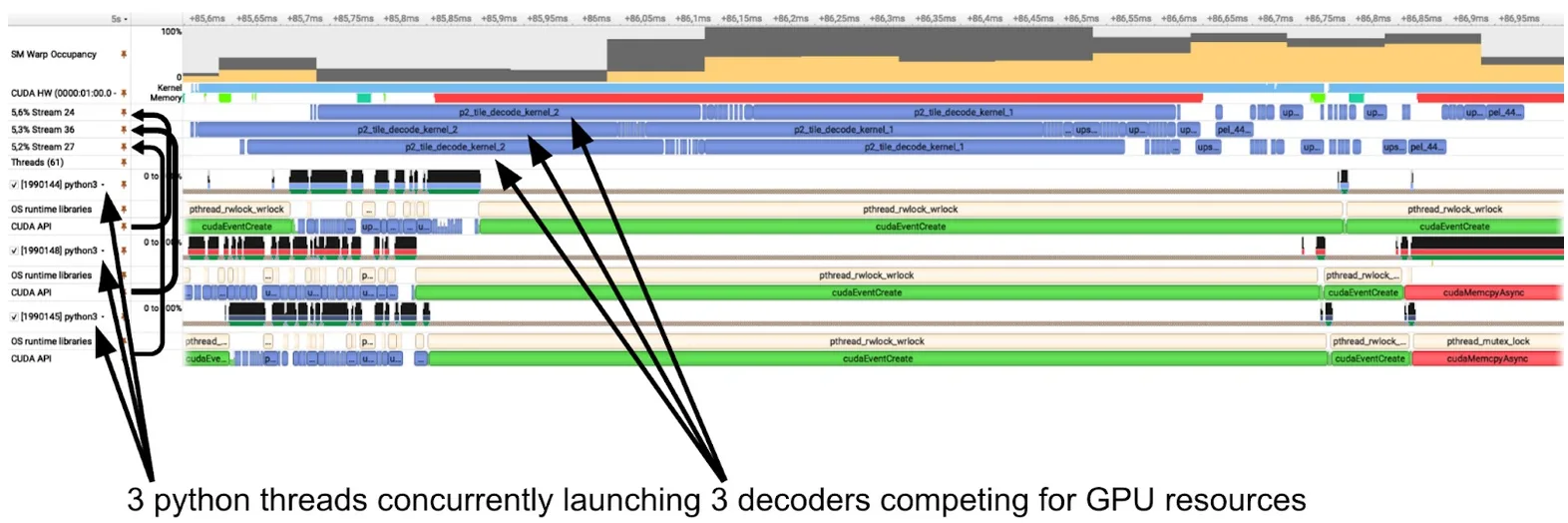
图6中的Nsight Systems追踪显示了在CPU上作为Python线程启动的三个并发解码器(底部)及其对应的GPU活动(顶部)。每个解码任务(蓝色)在独立的流上运行。尽管这种方式允许GPU调度器并行启动这些内核,但从效率角度看,将任务合并为单个更大的网格在GPU上执行更为高效。细粒度的内核级并行可能引发调度冲突和资源争用,且受限于GPU的计算能力,可并发执行的内核数量也存在硬性限制。此外,合并内核还能显著降低三个并发线程对CPU资源的占用。
总结
AI 工作流不仅需要更高效的模型,还需匹配 AI 处理速度的数据供给能力。通过将 VC-6 的分层选择性架构与 CUDA 强大的并行计算能力相结合,可显著加速从存储到张量的传输路径。该方法为支持选择性 LoQ/ROI 解码和 GPU 驻留数据等特定工作负载,提供了高效的 AI 原生解决方案,有效补充了现有库的功能。
CUDA 实现作为一个实用的构建模块,现已可用于提升数据流水线的速度与效率。尽管当前的 alpha 版本已展现出显著优势,但通过与 NVIDIA 工程师在本地批处理和内核优化方面的持续协作,未来有望进一步提升吞吐性能。接下来,这一初步的 CUDA 实现将逐步实现与主流 AI SDK 及数据加载管道的深度集成。对于正在构建高吞吐、多模态 AI 系统的开发者而言,现在正是探索基于 CUDA 的 VC-6 如何加速工作流程的合适时机。
开始使用
VC-6 SDK 支持 CUDA(alpha)、OpenCL 和 CPU,可通过 C++ 和 Python API 使用。
- SDK 和文档:通过 V-Nova 访问 SDK 门户和 文档。
- 试用访问:请通过 ai@v-nova.com 联系 V-Nova,获取 CUDA Alpha wheel 和基准测试脚本
- GitHub 上的示例






