Jupyter 笔记本使用 RAPIDS 的最佳实践
一家全球领先的零售商已经投入巨资成为 世界上最具竞争力的科技公司之一。

准确 而且及时 需要 预测数以百万计的商品组合对服务至关重要 他们的 每周有数百万的客户。他们成功预测的关键是 RAPIDS ,一个 GPU 加速库的开源套件 RAPIDS 帮助他们撕破了大规模数据,并将预测精度提高了几个百分点——它现在在减少基础设施 GPU 占用的基础上运行速度快了几个数量级。 这使他们能够对购物者的趋势作出实时反应,并有更多的正确的产品上架,减少缺货情况,并增加销售。
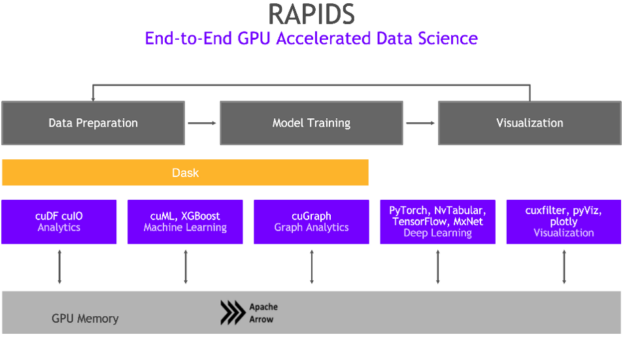
使用 RAPIDS ,数据从业者可以加速 NVIDIA GPU 上的管道,将数据操作(包括数据加载、处理和培训)从几天减少到几分钟。 RAPIDS 通过构建 论与整合 流行的 分析生态系统,如 PyData 公司 和 Apache Spark ,使用户能够立即看到好处。 与类似的基于 CPU 的实现相比, RAPIDS 提供 50 倍的性能 改进 对于经典的数据分析和机器学习( ML )过程 按比例 这大大降低了大型数据科学操作的总体拥有成本( TCO )。
为了学习和解决复杂的数据科学和人工智能挑战, 零售业领导者经常利用一个叫做“ Kaggle 竞赛 ”。 Kaggle 是一个平台,汇集了数据科学家和其他开发人员,以解决公司发布的具有挑战性和有趣的问题。 事实上,在过去的一年里,已经有超过 20 个解决零售业挑战的竞赛。
利用 RAPIDS 和最佳实践进行预测竞赛, NVIDIA Kaggle 大师 Kazuki Onodera 在启动市场篮分析卡格尔竞赛中获得第二名,采用复杂特征工程、梯度增强树模型和比赛 F1 评价指标的特殊建模。 一路上,我们记录了最佳实践 对于 ETL ,特征工程, 建筑 以及为建立基于人工智能的零售预测定制最佳模型 解决方案。
这篇博文将引导读者了解 Kaggle 竞赛 解释提高零售业预测的数据科学最佳实践。 具体来说,这篇博客文章解释了 Instacart 市场篮子分析 Kaggle 的竞争目标,介绍了 RAPIDS ,然后提供了一个工作流,展示了如何直观地浏览数据、开发功能、训练模型和运行预测。然后,本文将深入探讨一些先进的特征工程技术,包括模型可解释性和超参数优化( HPO )。
要更详细地了解该方法,请参阅小野寺五典( Kazuki Onodera )对 Medium.com 的精彩访谈。
在 NVIDIA GTC 2021 年 加入 Paul Hendricks ,在那里他主持了一个关于 使用 NVIDIA RAPIDS 数据科学库进行零售预测的 ETL 、特征工程和模型开发的最佳实践 的会议。
访问此 Jupyter 笔记本 ,我们将在 Instacart 市场篮子分析 Kaggle 竞争的背景下分享这些 GPU 加速预测的最佳实践。
预测挑战
Instacart 市场篮子分析竞争面临挑战 Kaggle 预测哪种食品是消费者会在何时再次购买。举例来说,想象一下,当你用完牛奶的时候,或者你知道的时候,牛奶已经准备好要加入你的购物车了 是的 是时候再储备你最喜欢的冰淇淋了。
这种对理解时态行为模式的关注使得这个问题与标准项目推荐有很大的不同,标准项目推荐要求用户 需要 而且偏好通常被认为在短时间内是相对恒定的。而 Netflix MIG 如果你想看另一部电影,那就没问题了 喜欢 你刚才看的那个, 是的 不太清楚的是,如果你昨天买的话,你会想重新订购一批新鲜的杏仁黄油或卫生纸。
问题概述
这项竞争的目标是预测杂货店的再订购:给定用户的购买历史(一组订单,以及每个订单中购买的产品),他们以前购买的哪些产品将在下一个订单中重新购买?
这个问题与一般的推荐问题有点不同,在一般的推荐问题中,我们经常面临一个冷启动的问题,即为新用户和需要的新项目进行预测 我们已经 从未见过。例如,电影网站可能需要推荐新电影并为新用户提供建议。
这个问题的连续性和基于时间的性质也让它变得有趣:我们如何考虑用户上次购买商品以来的时间?用户是否有特定的购买模式,他们是否在一天的不同时间购买不同种类的商品?
首先, 我们会的 首先加载一些我们将在本笔记本中使用的模块,并为任何模块设置随机种子 随机数发生器 我们会用的。
RAPIDS 概述
数据科学家通常处理两种类型的数据:非结构化数据和结构化数据。非结构化数据通常以文本、图像或视频的形式出现。结构化数据——顾名思义——以结构化的形式出现,通常由表或 CSV 表示。我们将把大部分教程的重点放在处理这些类型的数据上。
Python 生态系统中有许多用于结构化表格数据的工具,但很少有工具像 pandas 那样被广泛使用 pandas 表示表中的数据,允许数据科学家操作数据以执行许多有用的操作,如过滤、转换、聚合、合并、可视化等等。
更多关于 pandas ,请查看此处的优秀文档: [http://pandas.pydata.org/pandas-docs/stable/]
pandas 非常适合处理适合系统内存的小型数据集。然而,数据集越来越大,数据科学家正在处理越来越复杂的工作负载,因此需要加速计算。
cuDF 是 RAPIDS 生态系统中的一个包,使数据科学家能够轻松地将现有的 pandas 工作流程从 CPU 迁移到 GPU,计算可以利用 GPU 提供的巨大平行性。
熟悉数据
本次竞争的数据集包含多个文件,这些文件捕获了 Instacart 用户一段时间内的订单,竞争的目标是预测用户是否会重新订购产品,特别是这些客户将重新订购哪些产品。从 Kaggle 数据描述( https://www.kaggle.com/c/instacart-market-basket-analysis/data )中,我们看到我们有超过 300 万份杂货订单,客户群超过 200000 名 Instacart 用户。对于每个用户,我们提供 4 到 100 个订单,每个订单中购买的产品的顺序,以及他们订单的时间和订单之间时间的相对度量。 还提供了 下订单当天的星期和小时,以及订单之间的相对时间度量。
我们的 产品, 过道,和 部门 数据集由关于我们的产品、通道和 部门 分别。每个数据集(产品、通道、部门和订单等)都有该数据集中每个实体的唯一标识符映射,例如订单 id 表示订单数据集中的唯一订单,产品 id 表示产品数据集中的唯一产品,稍后我们将使用这些唯一标识符将所有这些单独的数据集组合成一个一致的视图,用于探索性数据分析、特征工程和建模。
下面,我们将读取数据并使用 cuDF 检查不同的表。

另外, 我们会的 读入我们的 [orders] 数据集。 第一个 表示 订单所属的集合(之前、训练、测试)。 附加 文件指定每个订单中购买的产品。 同样,从数据的 Kaggle 描述中,我们可以看到 order_products__prior.csv 包含所有客户的先前订单内容。“ reordered ”列表示客户有包含该产品的上一个订单。我们被告知有些订单没有重新订购的商品。
探索数据
当我们考虑数据科学工作流程时,最重要的步骤之一是 探索性数据分析。这是我们检查数据并寻找线索和见解的地方 特征 我们可以使用(或需要创建) 喂 我们的模型。 探索数据的方法有很多种,每个问题的每个探索性数据分析都是不同的 – 然而,它仍然非常重要,因为它通知我们的功能工程流程,最终确定我们的模型有多准确。
在 这个 笔记本,我们看一天中几个不同的横截面。具体来说,我们 检查订单数量的分布、一周中的天数和客户通常下订单的时间、订单数量的分布 数 自上次订单以来的天数,以及所有订单和唯一客户中最受欢迎的项目(重复数据消除) 为了 忽略那些拥有“最喜欢”的商品并重复订购的客户)。
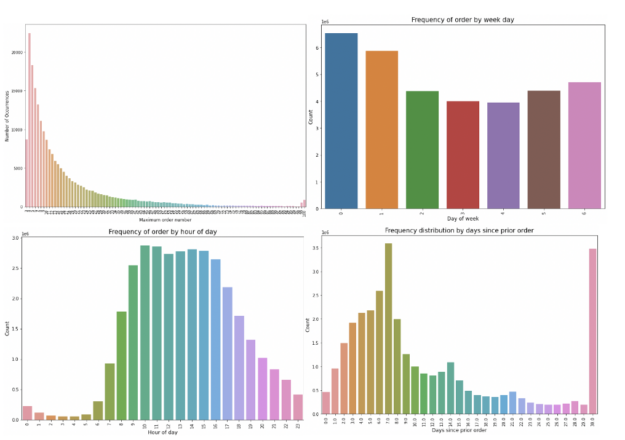
从这里我们看到 分别地 那就是:
- 订单不少于 4 个,最多 100 个。
- 订单很高 星期六和星期日 0 和 1 )和低。
- 大多数 订单是在 白天。 和客户 主要是每周或每月订购一次 ( 见第 7 天和第 30 天的峰值)。
对产品流行度进行了类似的探索性分析 [ 在笔记本中提供 。
特征工程
如果说探索性数据分析是我们数据科学工作流程中最重要的部分,那么特征工程则是紧随其后的第二部分。在这里,我们确定哪些特性应该输入到模型中,并在需要的地方创建特性 相信 他们 MIG 能够帮助模型更好地进行预测。
我们首先确定我们的唯一用户 X 项 组合 把它们分类。 我们会的 创建一个数据集,其中每个用户映射到他们最近的订单号、星期几和小时数,以及自该订单以来的天数。 以及 我们会的 延伸 我们的 数据集,创建标签 和特点 稍后将在我们的机器学习模型中使用,例如:
- 用户订购了多少种产品?
- 用户在一个购物车中订购了多少产品?
- 用户从哪些部门订购了产品?
- 用户何时订购产品(星期几)?
- 此用户以前是否至少订购过一次此产品?
- 一个用户下了多少包含此项的订单?
解决业务问题(培训和预测)
许多机器学习算法的数学运算通常是矩阵乘法。这些类型的操作是高度并行化的,并且可以使用 GPU 大大加速 RAPIDS 使以加速方式构建机器学习模型变得很容易,同时仍然使用几乎相同的界面 学习和 XGBoost 。
创建模型的方法有很多种——可以使用线性回归模型、支持向量机、基于树的模型(如 Random Forest 和 XGBoost ),甚至可以使用神经网络。一般来说,基于树的模型往往比神经网络更好地处理用于预测的表格数据。神经网络的工作原理是将输入(特征空间)映射到另一个复杂的边界空间,并确定哪些值应该属于该边界空间中的那些点(回归、分类)。另一方面,基于树的模型通过获取数据、识别列,然后在该列中找到一个分割点来映射值,同时优化精度。我们可以使用不同的列创建多棵树,甚至在每棵树中创建不同的列。
有关基于树的模型 XGBoost 的更详细描述,请参阅以下文档: https://xgboost.readthedocs.io/en/latest/tutorials/model.html
基于树的模型除了具有更好的精度性能外,还非常容易实现 解释 ( 对预测或决策很重要 结果 根据预测 必须 可能出于合规性和法律原因,需要解释和证明 例如 金融、保险、医疗)。基于树的模型非常健壮,即使在 有 一小组数据点。
在下面的部分中, 我们会的 为我们的 XGBoost 模型设置不同的参数,并训练五个不同的模型——每个模型都在不同的用户子集上,以避免对特定的用户集进行过度拟合。
import xgboost as xgb
NFOLD = 5
PARAMS = {
'max_depth':8,
'eta':0.1,
'colsample_bytree':0.4,
'subsample':0.75,
'silent':1,
'nthread':40,
'eval_metric':'logloss',
'objective':'binary:logistic',
'tree_method':'gpu_hist'
}
models = []
for i in range(NFOLD):
train_ = train[train.user_id % NFOLD != i]
valid_ = train[train.user_id % NFOLD == i]
dtrain = xgb.DMatrix(train_.drop(['user_id', 'product_id', 'label'], axis=1), train_['label'])
dvalid = xgb.DMatrix(valid_.drop(['user_id', 'product_id', 'label'], axis=1), valid_['label'])
model = xgb.train(PARAMS, dtrain, 9999, [(dtrain, 'train'),(dvalid, 'valid')],
early_stopping_rounds=50, verbose_eval=5)
models.append(model)
break有 几个 在 XGBoost 可以运行之前应该设置的参数。
- 一般参数与我们使用哪个助推器进行助推器有关,通常是树模型或线性模型。
- 助推器参数取决于您选择的助推器。
- 学习任务参数决定了学习场景。例如,回归任务可以对排序任务使用不同的参数。
有关 XGBoost 模块中可配置参数的更多信息,请参阅以下文档: https://xgboost.readthedocs.io/en/latest/parameter.html
特征重要性
一次 我们已经 通过训练我们的模型,我们或许想看看内部的工作原理,并了解哪些我们精心设计的特性对预测的贡献最大。这称为特征重要性。基于树的预测模型的优点之一是了解 不同的 重要性 我们的特色很简单。
与 理解力 如果我们的特征有助于模型的准确性,我们可以选择删除 不是吗 重要或尝试迭代和创建新特性,重新训练和重新评估这些新特性是否更重要。 最终,能够快速迭代并在此工作流中尝试新事物将导致最精确的模型和最大的投资回报率(对于预测,通常是由于减少缺货和库存不足而节省成本)。 传统上,由于计算强度的原因,迭代会花费大量的时间。 RAPIDS 允许用户通过 NVIDIA 加速计算进行模型迭代,因此用户可以快速迭代并确定性能最佳的模型。
在笔记本的功能重要性部分 , 我们定义了方便代码来访问每个模型中特性的重要性。然后,我们传入我们训练的模型列表,逐一迭代,并平均所有模型中每个变量的重要性。最后,我们想象 特征 使用水平条形图的重要性。
我们特别看到,我们的三个特征对我们的预测贡献最大:
- user \ u product \ u size –用户下了多少个包含此项目的订单?
- 用户\ u 产品\ u t-1 –此用户以前是否至少订购过一次此产品?
- 订单号–用户创建的订单数。
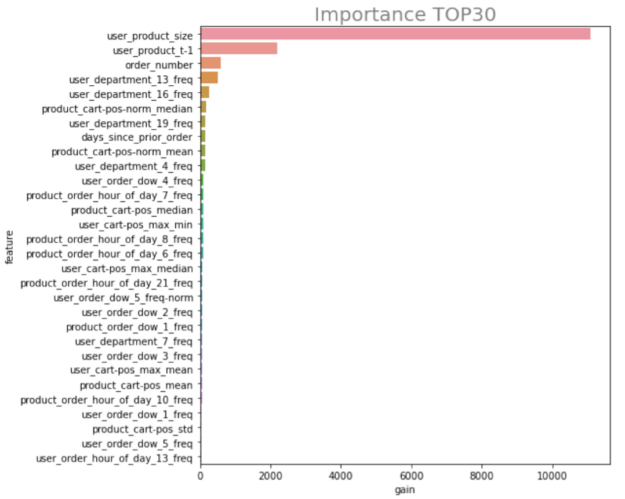
所有这些都是有道理的,符合我们对问题的理解。以前下过订单的客户更可能重复该产品的订单,而多次下该产品订单的用户更可能重新订购。此外,客户创建的订单数量与其重新订购的可能性相关。
代码使用了特性重要性的默认 XGBoost 实现——但是我们可以自由选择任何实现或技术。 一种奇妙的技术(也是由 NVIDIA Kaggle 大师艾哈迈特发明的) Erdem )称为 LOFO 。
从 LOFO GitHub 页面的描述中,我们可以看到 LOFO ( Leave One Feature Out ) Importance 根据选择的度量来计算一组特征的重要性,对于选择的模型,通过迭代地从集合中删除每个特征,并评估模型的性能,以及选择的验证方案,基于选定的指标。 LOFO 首先评估包含所有输入特性的模型的性能,然后一次迭代删除一个特性,重新编译模型,并在验证集上评估其性能。
这种方法使我们能够有效地确定哪些特性对模型很重要。与其他重要类型相比, LOFO 有几个优点:
- 它不支持颗粒特征。
- 它 概括 以及看不见的测试集。
- 它是模型不可知论的。
- 它对包含时影响性能的特性给予负面的重视。
有关 LOFO 的更多信息,请参见: [[第 21 页]
超参数 优化( HPO )
在培训 XGBoost 模型时,我们使用了以下参数:
PARAMS = { 'max_depth':8, 'eta':0.1, 'colsample_bytree':0.4, 'subsample':0.75, 'silent':1, 'nthread':40, 'eval_metric':'logloss', 'objective':'binary:logistic', 'tree_method':'gpu_hist' }
其中,只有少数可能会改变并影响我们模型的准确性: [最大深度, eta ,,, ColSample , bytree ,] 和 subsample 。然而,这些可能不是最理想的参数。用最优化模型识别和训练模型的艺术和科学 超参数 称为超参数优化。
虽然没有可以按下的魔法按钮来自动识别最佳超参数,但是有一些技术可以让您探索所有可能的超参数值的范围,快速测试它们,并找到最接近的值。
对这些技术的全面探索超出了本笔记本的范围。然而, RAPIDS 集成到许多 云 ML 框架 做 HPO 以及许多不同的 开源 工具。能够使用 RAPIDS 提供的令人难以置信的加速,可以让您非常快速地完成 ETL 、特性工程和模型培训工作流程 实验 – 最终通过大的超参数空间实现快速的 HPO 探索,并显著降低总体拥有成本( TCO )。
结论
在这个博客里,我们 浏览了 Kaggle 竞赛的各个部分,解释了数据科学在改善零售业预测方面的最佳实践。 具体来说,博文解释道 Instacart Market Basket Analysis Kaggle 的竞争目标介绍了 RAPIDS ,然后提供了一个工作流,展示了如何可视化地探索数据、开发功能、训练模型和运行预测。 然后 检验过的 具有模型可解释性和超参数优化( HPO )的特征工程技术。
要了解更多信息,请确保:
- See this Jupyter 笔记本 论预测
在这里,我们展示了在 Instacart 市场篮子分析 Kaggle 竞争的背景下, GPU 加速预测的最佳实践,其中 NVIDIA 是 Kaggle Grandmaster 仓石一树 小野寺五郎赢了 2 分nd地点,采用复杂特征工程,梯度增强树模型和特殊建模的比赛的 F1 评价指标。
- 在 NVIDIA GTC 2021 和 使用 NVIDIA RAPIDS 数据科学库进行零售预测的 ETL 、特征工程和模型开发的最佳实践 加入 Paul Hendricks 。
- 阅读 Kazuki Onodera’s 详细访谈 Medium.com .
- 然后去 这个 Rapids.ai open-source website 。