推荐系统驱动你在网上采取的每一个行动,从你现在正在阅读的网页的选择到更明显的例子,如网上购物。它们在推动用户参与在线平台、从成倍增长的可用选项中选择一些相关商品或服务方面发挥着关键作用。在一些最大的商业平台上,推荐占据了高达 30% 的收入。推荐质量提高 1% 就可以带来数十亿美元的收入。
随着行业数据集规模的快速增长,深度学习( Deep Learning , DL )推荐模型利用了大量的训练数据,与传统的基于内容、邻域和潜在因素的推荐方法相比,具有越来越大的优势。 DL 推荐模型是建立在现有技术的基础上的,例如 embeddings 用来处理分类变量,以及 factorization 用来建模变量之间的相互作用。然而,他们也利用大量快速增长的关于新型网络架构和优化算法的文献来构建和训练更具表现力的模型。
因此,更复杂的模型和快速数据增长的结合提高了培训所需计算资源的门槛,同时也给生产系统带来了新的负担。为了满足大规模 DL 推荐系统训练和推理的计算需求, NVIDIA 引入了 Merlin 。
Merlin 是一个基于 – GPU 框架的端到端推荐程序,旨在提供快速功能工程和高训练吞吐量,以实现 DL 推荐程序模型的快速实验和生产再训练。 Merlin 还支持低延迟、高吞吐量和生产推断。
在深入研究 Merlin 之前,我们将进一步讨论大规模推荐系统目前面临的挑战。
推荐系统概述
图 1 显示了一个端到端推荐系统体系结构示例。
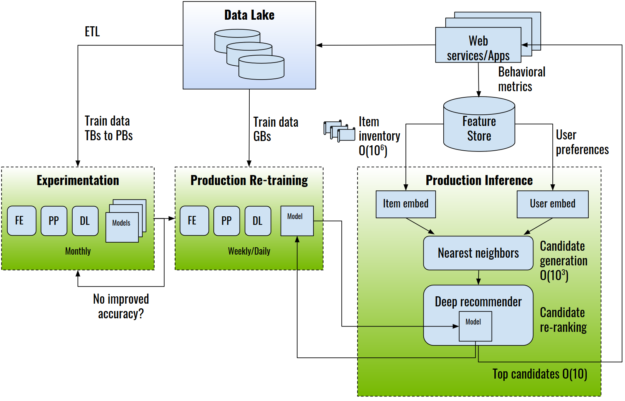
推荐系统是使用收集到的关于用户、项目及其交互(包括印象、点击、喜欢、提及等等)的数据来训练的。这些信息通常存储在数据湖或数据仓库中。
在实验阶段,提取 – 转换 – 加载( ETL )操作准备并导出用于培训的数据集,通常以表格数据的形式,可以达到 TB 或 PB 级别。这种类型的一个示例公共数据集是 Criteo-Terabyte 点击日志 dataset ,它包含 24 天内 40 亿次交互的点击日志。行业数据集可以大几个数量级,包含多年的数据。
在实验过程中,数据科学家和机器学习工程师使用特征工程,通过转换现有特征来创建新的特征;以及预处理,为模型使用工程特征做准备。然后使用 DL 框架(如 TensorFlow 、 PyTorch 或 NVIDIA 推荐者特定的训练框架 HugeCTR )执行训练。
模型经过离线培训和评估后,可以进入生产环境进行在线评估,通常是通过 A / B 测试。推荐系统的推理过程包括根据用户与候选项交互的预测概率对候选项进行选择和排序。
对于大型商业数据库来说,选择一个项目子集是必要的,因为有数百万个项目可供选择。选择方法通常是一种高效的算法,例如近似最近邻、随机林或基于用户偏好和业务规则的过滤。 DL 推荐模型对候选对象进行重新排序,并将预测概率最高的候选对象呈现给用户。
推荐系统面临的挑战
培训大规模推荐系统时面临许多挑战:
- 庞大的数据集: 商业推荐系统通常是在大数据集(通常是 TB 或更多)上训练的。在这种规模下,数据 ETL 和预处理步骤通常比训练 DL 模型花费更多的时间。
- 复杂的数据预处理和特征工程管线: 需要对数据集进行预处理,并将其转换为与 DL 模型和框架一起使用的适当形式。同时,特征工程试验从现有特征中创建了许多新特征集,然后对这些特征集进行有效性测试。此外,列车时刻的数据加载可能成为输入瓶颈,导致 GPU 未充分利用。
- 大量重复实验: 整个数据 ETL 、工程、培训和评估过程可能必须在许多模型体系结构上重复多次,这需要大量的计算资源和时间。然而,在部署之后,推荐系统还需要定期进行再培训,以了解新用户、项目和最新趋势,以便随着时间的推移保持较高的准确性。
- 巨大的嵌入表: 嵌入是当今处理分类变量的一种普遍使用的技术,尤其是用户和项目 ID 。在大型商业平台上,用户和项目库很容易达到数亿甚至数十亿的数量,与其他类型的 DL 层相比,需要大量的内存。同时,与其他 DL 操作不同,嵌入查找是内存带宽受限的。虽然 CPU 通常提供更大的内存池,但与 GPU 相比,它的内存带宽要低得多。
- 分布式培训: 正如 MLPerf benchmark 所反映的那样,分布式训练在视觉和自然语言领域的 DL 模型训练中不断创造新的记录,但由于与其他领域和大型模型相比,大数据的独特组合,分布式训练对于推荐系统来说仍然是一个相对较新的领域。它要求模型并行和数据并行,因此很难实现高的扩展效率。
在生产中部署大规模推荐系统的一些显著挑战包括:
- 实时推断: 对于每个查询用户,即使在候选缩减阶段之后,要评分的用户项对的数量也可能多达几千个。这给 DL 推荐系统推理服务器带来了极大的负担,它必须处理高吞吐量以同时为许多用户提供服务,同时还必须处理低延迟以满足在线商务引擎严格的延迟阈值。
- 监测和再培训: 推荐系统在不断变化的环境中运行:新用户注册、新项目可用以及热点趋势出现。因此,推荐系统需要不断的监测和再培训,以确保高效率。推理服务器还必须能够同时部署不同版本的模型,并动态加载/卸载模型,以便于 a / B 测试。
NVIDIA Merlin :在 NVIDIA GPU 上的端到端推荐系统
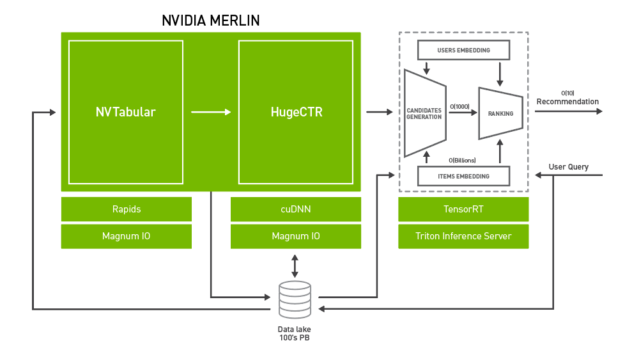
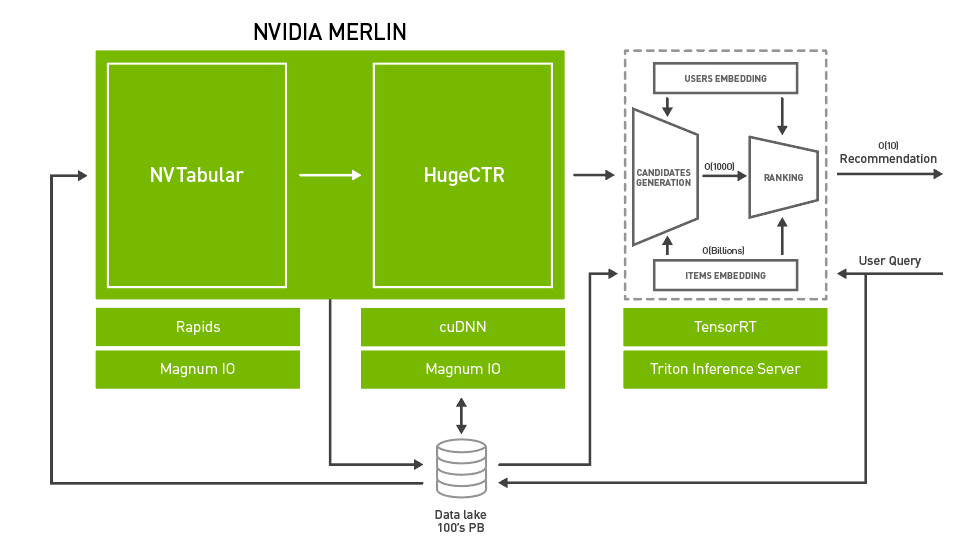
为了系统地解决上述挑战,NVIDIA 引入了 Merlin。 NVIDIA Merlin 是一个应用程序框架和生态系统,旨在促进推荐系统开发的所有阶段,从实验到生产,并在 NVIDIA GPU 上加速。图 2 显示了 Merlin 的架构图,包含三个主要组件:
- Merlin ETL 公司: 一组用于在 GPU 上进行快速推荐系统功能工程和预处理的工具。 NVTabular 提供高速的、在 GPU 上的数据预处理和转换功能,以处理 TB 级的表格数据集。 NVTabular 的输出可以通过 NVTabular 数据加载器扩展以高吞吐量提供给训练框架,例如 NVTabular 、 PyTorch 或 TensorFlow ,从而消除输入瓶颈。
- Merlin 培训: DL 推荐系统模型和培训工具的集合:
- HugeCTR 是一种高效的 C ++推荐系统专用培训框架。它具有多点 GPU 和多节点训练,并支持模型并行和数据并行扩展。 HugeCTR 涵盖了常见和最新的推荐系统架构,如 宽而深 ( W & D )、 深交叉网络 和 DeepFM ,深度学习推荐模型( DLRM )支持即将推出。
- DLRM 、 宽深( W & D ) 、 神经协同滤波 和 可变自动编码器( VAE ) 构成了 NVIDIA GPU – 加速 DL 模型组合 的一部分,它涵盖了除推荐系统之外的许多不同领域的广泛网络体系结构和应用,包括图像、文本和语音分析。这些模型是为训练而设计和优化的 TensorFlow 和 PyTorch 。
- Merlin 推论: NVIDIA TensorRT 和 NVIDIA Triton ®声波风廓线仪推断服务器 (以前的 TensorRT 推理服务器)。
- NVIDIA TensorRT 是一个用于高性能 DL 推理的 SDK 。它包括一个 DL 推理优化器和运行时,为 DL 推理应用程序提供低延迟和高吞吐量。
- Triton Server 提供了一个全面的 GPU 优化推断解决方案,允许使用各种后端的模型,包括 PyTorch 、 TensorFlow 、 TensorRT 和开放式神经网络交换( ONNX )运行时。 Triton Server 自动管理和利用所有可用的 GPU ,并提供为模型的多个版本提供服务和报告各种性能指标的能力,从而实现有效的模型监控和 a / B 测试。
在接下来的部分中,我们将依次探讨这些组件中的每一个。
NVTabular :快速表格数据转换和加载
对推荐系统数据集执行特征工程和预处理所花费的时间常常超过训练模型本身所花费的时间。作为一个具体的例子,使用开源提供的脚本处理 Criteo-Terabyte 点击日志 dataset 需要 5 . 5 天才能完成,而在单个 V100 GPU 上对已处理数据集上的 DLRM 进行培训则需要不到一个小时的时间。
NVTabular 是一个功能工程和预处理库,旨在快速方便地操作 TB 级数据集。它特别适用于推荐系统,推荐系统需要一种可伸缩的方式来处理附加信息,例如用户和项目元数据以及上下文信息。它提供了一个高级抽象,以简化代码并使用 cuDF cuDF 库加速 GPU 上的计算。使用 NVTabular ,只需 10-20 行高级 API 代码,就可以建立一个数据工程管道,与优化的基于 CPU 的方法相比,可以实现高达 10 倍的加速,同时不受数据集大小的限制,而不管 GPU / CPU 内存容量如何。
执行 ETL 所用的总时间是运行代码所用时间和编写代码所用时间的混合。 RAPIDS 团队在 GPU 上加速了 Python 数据科学生态系统,并通过 cuDF 、 Apache Spark 3 . 0 和 Dask- cuDF 提供了加速。
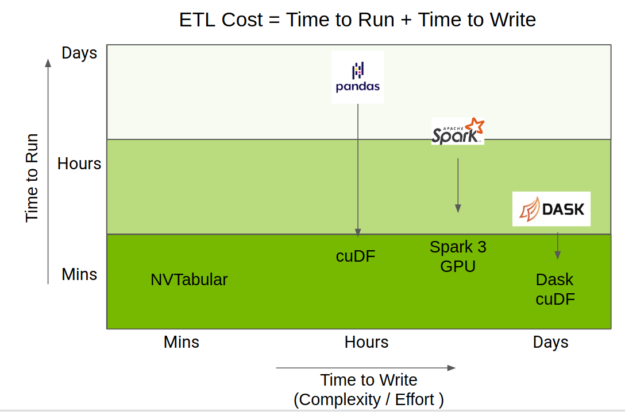
NVTabular 使用了这些加速,但提供了一个更高级别的 API ,重点放在推荐系统上,这大大简化了代码复杂性,同时仍然提供相同级别的性能。图 3 显示了 NVTabular 相对于其他数据帧库的位置。
下面的代码示例显示了转换 1-TB Criteo Ads 数据集所需的实际预处理工作流,使用 NVTabular 只需十几行代码即可实现。简单地说,指定了数字列和分类列。接下来,我们定义一个 NVTabular 工作流,并提供一组训练和验证文件。然后,将预处理操作添加到工作流中,并将数据持久化到磁盘。相比之下,定制的处理代码,比如 Facebook 的 DLRM 实现中基于 NumPy 的 有用数据 ,在同一管道中可以有 500-1000 行代码。
import nvtabular as nvt
import glob
cont_names = ["I"+str(x) for x in range(1, 14)] # specify continuous feature names
cat_names = ["C"+str(x) for x in range(1, 27)] # specify categorical feature names
label_names = ["label"] # specify target feature
columns = label_names + cat_names + cont_names # all feature names
# initialize Workflow
proc = nvt.Worfklow(cat_names=cat_names, cont_names=cont_names, label_name=label_names)
# create datsets from input files
train_files = glob.glob("./dataset/train/*.parquet")
valid_files = glob.glob("./dataset/valid/*.parquet")
train_dataset = nvt.dataset(train_files, gpu_memory_frac=0.1)
valid_dataset = nvt.dataset(valid_files, gpu_memory_frac=0.1)
# add feature engineering and preprocessing ops to Workflow
proc.add_cont_feature([nvt.ops.ZeroFill(), nvt.ops.LogOp()])
proc.add_cont_preprocess(nvt.ops.Normalize())
proc.add_cat_preprocess(nvt.ops.Categorify(use_frequency=True, freq_threshold=15))
# compute statistics, transform data, export to disk
proc.apply(train_dataset, shuffle=True, output_path="./processed_data/train", num_out_files=len(train_files))
proc.apply(valid_dataset, shuffle=False, output_path="./processed_data/valid", num_out_files=len(valid_files))
图 5 显示了 NVTabular 相对于原始 DLRM 预处理脚本的相对性能,以及在单节点集群上运行的 Spark 优化的 ETL 进程。值得注意的是培训占用的时间与 ETL 占用的时间的百分比。在基线情况下, ETL 与训练的比率几乎完全符合数据科学家花费 75% 时间处理数据的普遍说法。在 NVTabular 中,这种关系被翻转了。
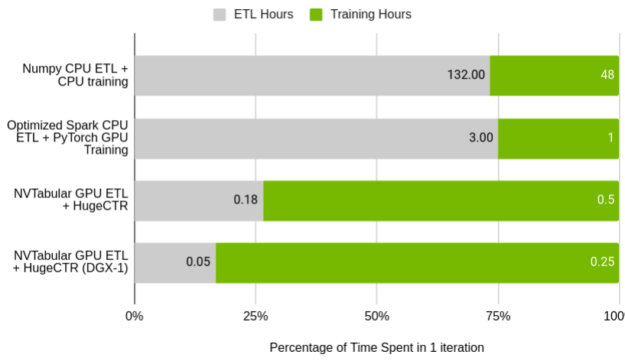
GPU ( Tesla V100 32 GB )与 CPU ( AWS r5d . 24xl , 96 核, 768 GB RAM )
使用原始脚本在 CPU 上处理数据集和训练模型所花费的总时间超过一周。通过大量的努力,使用 Spark 进行 ETL 和 GPU 上的培训可以减少到四个小时。使用本文后面将介绍的 NVTabular 和 HugeCTR ,您可以将单个 GPU 的迭代时间缩短到 40 分钟,将 DGX-1 集群的迭代时间缩短到 18 分钟。在后一种情况下, 40 亿个交互数据集只需 3 分钟即可处理完毕。
HugeCTR : GPU ——大型 CTR 机型加速训练
HugeCTR 是一个高效的 GPU 框架,设计用于推荐模型训练,目标是高性能和易用性。它既支持简单的深层车型,也支持最先进的混合动力车型,如 W&D 、 深交叉网络 和 DeepFM 。我们还致力于使用 HugeCTR 启用 DLRM 。模型细节和超参数可以用 JSON 格式轻松指定,允许从一系列常见模型中快速选择。
与 PyTorch 和 TensorFlow 等其他通用 DL 框架相比, HugeCTR 专门设计用于加速大规模 CTR 模型的端到端训练性能。为了防止数据加载成为训练中的主要瓶颈,它实现了一个专用的数据读取器,该读取器本质上是异步的和多线程的,因此数据传输时间与 GPU 计算重叠。
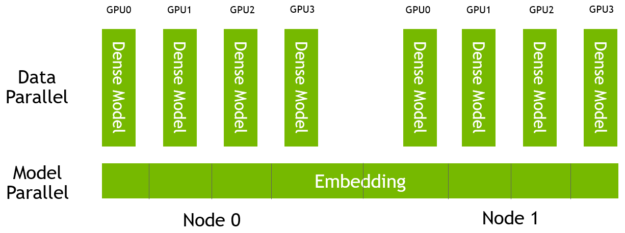
HugeCTR 中的嵌入表是模型并行的,分布在一个由多个节点和多个 GPU 组成的集群中的所有 GPU 上。这些模型的密集组件是数据并行的,每个模型上有一个副本 GPU (图 6 )。
对于高速可扩展的节点间和节点内通信, HugeCTR 使用 NCCL 。对于有许多输入特征的情况, HugeCTR 嵌入表可以分割成多个槽。将属于同一时隙的特征独立地转换为相应的嵌入向量,然后将其降为单个嵌入向量。它允许您有效地将每个插槽中有效功能的数量减少到可管理的程度。
图 7a 显示了 W & D 网络的训练性能, HugeCTR 在 Kaggle 数据集 上的单个 V100 GPU 上,与相同 GPU 上的 TensorFlow 和双 20 核 Intel Xeon CPU E5-2698 v4 上的 HugeCTR 相比, HugeCTR 的加速比 TensorFlow CPU 高达 54 倍,是 TensorFlow GPU 的 4 倍。为了重现结果, HugeCTR repo 中提供了 宽深样品 ,包括指令和 JSON 模型配置文件。
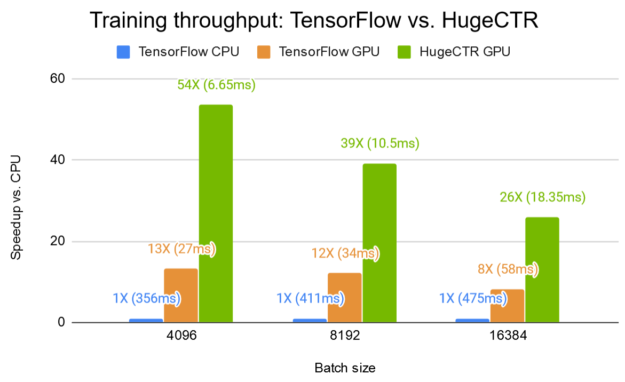
图 7b 显示了 HugeCTR 在 DGX-1 上对全精度模式( FP32 )和混合精度模式( FP16 )采用更深入的 W & D 模型的强缩放结果。
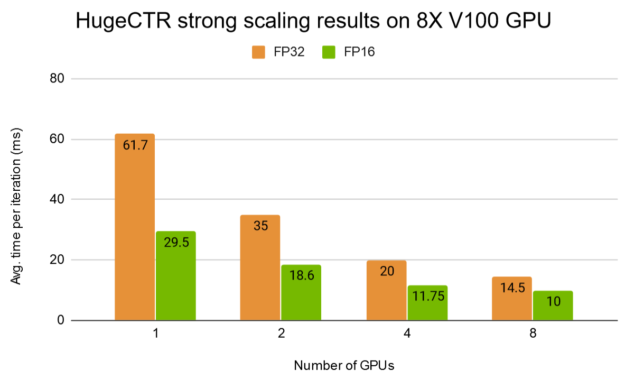
NVIDIA 推荐系统模型组合
DLRM 、 宽而深 、 NCF 和 VAE 构成较大的 NVIDIA GPU – 加速 DL 模型组合 的一部分。在本节中,我们将展示 DLRM 的参考实现。
与其他基于 DL 的方法一样, DLRM 被设计成同时使用分类和数字输入,这通常存在于推荐系统的训练数据中。模型架构如图 8 所示。
为了处理分类数据,嵌入层将每个分类映射到一个密集的表示,然后再将其输入多层感知器( MLP )。数字特征可以直接输入 MLP 。在下一级,通过计算所有嵌入向量对和处理后的密集特征之间的点积,显式地计算不同特征的二阶交互作用。这些成对交互被输入到顶级 MLP 中,以计算用户和项目对之间交互的可能性。
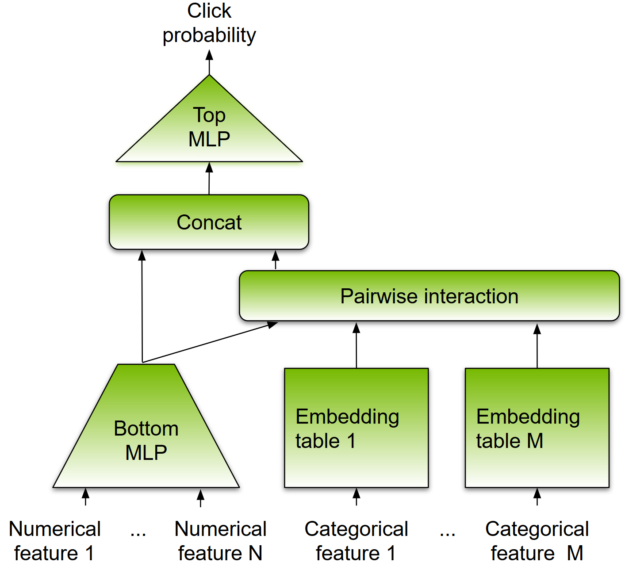
与其他基于 DL 的推荐方法相比, DLRM 在两个方面有所不同。首先,它显式计算特征交互,同时将交互顺序限制为成对交互。其次, DLRM 将每个嵌入的特征向量(对应于分类特征)视为一个单元,而其他方法(如 Deep 和 Cross )将特征向量中的每个元素视为一个新单元,该单元应产生不同的交叉项。这些设计选择有助于降低计算和内存成本,同时保持具有竞争力的准确性。
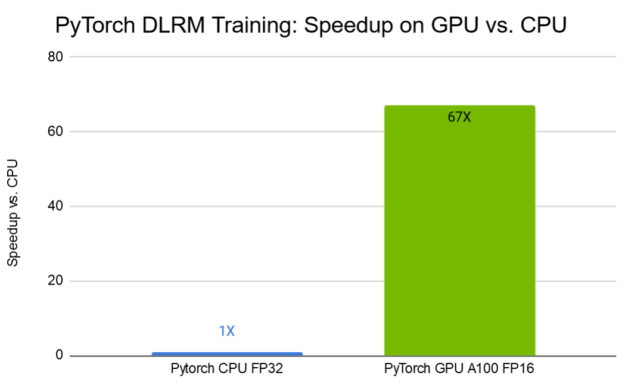
图 9 显示了 TB 数据集 上的 DLRM 训练结果。在采用第三代张量核技术的 NVIDIA A100 GPU 上,采用混合精度训练,与 CPU 上的训练相比,训练时间缩短了 67 倍。
TensorRT 和 Triton Server 进行推断
NVIDIA TensorRT 是一个用于高性能 DL 推理的 SDK 。它包括一个 DL 推理优化器和运行时,为推理应用程序提供低延迟和高吞吐量。 TensorRT 可以使用一个公共接口,即开放式神经网络交换格式( ONNX ),从所有 DL 框架接受经过训练的神经网络。
TensorRT 可以使用垂直和水平层融合等操作,并使用降低的精度( FP16 , INT8 )利用了 NVIDIA GPU s 上张量核的高混合精度算术吞吐量。 TensorRT 还根据手头的任务和目标 GPU 体系结构自动选择最佳内核。对于进一步的特定于模型的优化, TensorRT 是高度可编程和可扩展的,允许您插入自己的插件层。
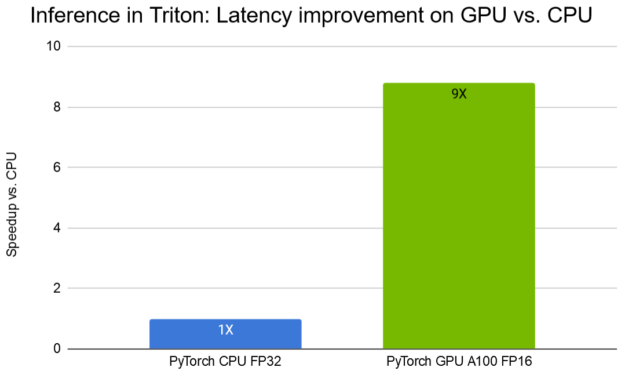
NVIDIA Triton 推断服务器提供了一个针对 NVIDIA GPU s 优化的云推断解决方案。服务器通过 HTTP 或 gRPC 端点提供推断服务,允许远程客户端请求对服务器管理的任何模型进行推断。 Triton Server 可以使用多种后端为 DL 推荐程序模型提供服务,包括 TensorFlow 、 PyTorch ( TorchScript )、 ONNX 运行时和 TensorRT 运行时。使用 DLRM ,我们展示了如何使用 Triton ®声波风廓线仪部署预训练的 PyTorch 模型,与 CPU 相比, A100 GPU 的延迟减少了 9 倍,如图 10 所示。
在最近发表在 在 GPU s 上加速 Wide & Deep 推荐推理 上的文章中,作者详细介绍了优化方法,使用 TensorFlow 估算器 API 训练的 W & D 模型适合大规模生产部署。通过实现融合嵌入查找内核来利用 GPU 高内存带宽,运行在 Triton Server 自定义后端, GPU W & D TensorRT 推理管道与同等的 CPU 推理管道相比,延迟减少了 18 倍,吞吐量提高了 17 . 6 倍。所有这些都是使用 Triton Server 部署的,以提供生产质量指标并确保生产健壮性。
结论
NVIDIA Merlin 的组件已作为开源项目提供:
这只是一段激动人心的旅程的开始。我们诚挚地邀请您试用我们新开发的推荐系统应用工具并从中受益。您的问题和功能请求将有助于指导未来的开发。