
这篇文章介绍了 NVIDIA GPU s 上异步计算和重叠的最佳实践。要在应用程序中获得高且一致的帧速率,请参阅所有高级 API 性能提示.
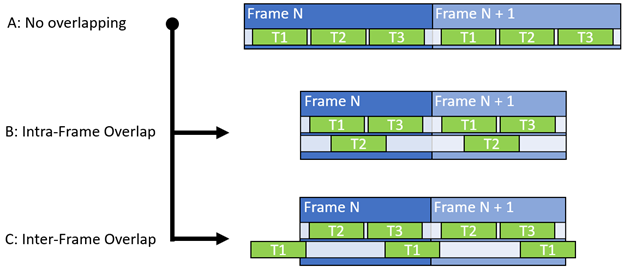
异步计算背后的一般原则是通过减少未使用的扭曲插槽的数量来提高整体单元吞吐量,并促进同时使用非冲突数据路径。 GPU 最基本的通信设置使用单个队列同步推送和执行图形、计算和复制工作负载(图 1-a )。
在理想情况下,所有工作负载都会产生较高的单位吞吐量(图 2-A ),并使用所有可用的扭曲插槽(图 2-B )和不同的数据路径。实际上,只有一小部分最大单位吞吐量被真正使用。异步计算通过并行处理多个工作负载并有效提高总体处理吞吐量,为您提供了增加硬件单元使用的机会。
一个典型的错误是只关注 SM 占用(未使用的扭曲插槽)来识别潜在的异步计算工作负载。 GPU 是一个复杂的庞然大物,其他指标,如最高单位吞吐量( SOL )发挥着与 SM 占用率同等甚至更重要的作用。有关更多信息,请参阅优化任何 GPU 工作负载的峰值性能百分比分析方法。
因此,除了 SM 占用之外,还应该考虑单位吞吐量、登记文件占用、组共享内存和不同数据通路。在确定理想对之后,计算工作负载被移动到异步队列(图 1 、 B 和 C )。它使用围栏与同步/主队列同步,以确保正确的执行顺序。
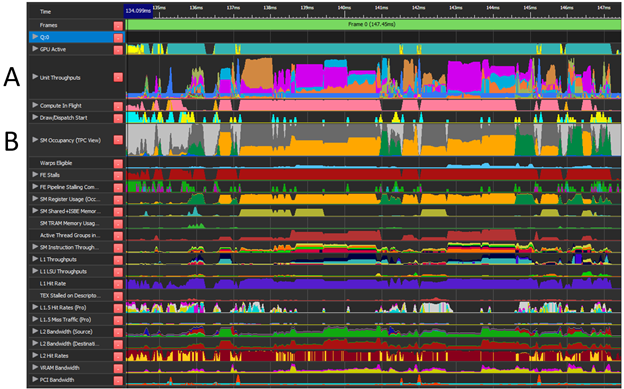
NSight Graphics 提供了 GPU 跟踪功能(图 2 ),它提供了在整个帧中采样的各种 GPU 单元的详细性能信息。此性能信息对于确定潜在的工作负载重叠至关重要。
知道从哪里开始寻找是识别潜在重叠机会的关键。总是首先考虑单位吞吐量,因为它代表某一单元类型可以操作的理论最大百分比( SOL )。它还有助于识别正在使用的数据路径的类型。
试图将工作负载和单位吞吐量叠加到最大百分比( 100% )上不仅不起作用,还会降低总体性能。
当你在寻找单位吞吐量和 SM 占用时,也考虑资源障碍和管道变化。 GPU 完全能够跨不同的 SMs 同时处理一批微小的 draw 呼叫,其中每个呼叫分别负责少量的扭曲。如果条件合适,它甚至可以将它们合并成一个块。
更改图形、计算或复制工作负载类型(也称为子通道开关)或在同一队列上使用 UAV 屏障会触发等待空闲( WFI )任务。 WFI 强制将同一队列上的所有扭曲完全排空,从而在单位吞吐量和 SM 占用率中留下工作负载间隙。
如果 WFI 是不可避免的,并且会导致很大的吞吐量缺口,那么使用异步计算来填补这一缺口可能是一个很好的解决方案。屏障和 WFI 的共同来源如下:
- 绘制、分派或复制调用之间的资源转换(障碍)
- 无人机屏障
- 光栅状态更改
- 在同一队列上背对背混合使用 draw 、 dispatch 和 copy 调用
- 描述符堆更改
推荐
- 使用 NSight NVIDIA 图形提供的 GPU 轨迹识别潜在的重叠对:
- 寻找低顶层单元吞吐量指标的组合。
- 如果 SM 占用显示了大量未使用的扭曲槽,那么它可能是一个有效的重叠。 SM Idle% 在没有冲突的高通量单元的情况下几乎总是一个有保证的改进。
- 捕获另一个 GPU 跟踪以确认结果。
- 尝试重叠不同的数据路径。例如, FP 、 ALU 、内存请求、 RT 核、张量核、图形管道。
- FP 、 ALU 和 Tensor 共享不同的寄存器文件。
- 将计算工作负载与其他计算工作负载重叠。这种方案在 NVIDIA 安培结构 GPU 上非常有效。
- 考虑将一些图形工作(如后处理传递)转换为计算:这可以提供新的重叠机会。
- 考虑在帧之间运行异步工作(图 1-C )。
- 如果实现了帧内异步计算,则测量整个帧上的性能差异或多个帧上的平均性能差异。
- 验证不同 GPU 层之间的行为。高端 GPU 有更多的 SM 单元,因此重叠的可能性更大。
- 验证不同分辨率下的行为。低分辨率通常意味着更少的像素扭曲,因此 SMs 的空闲时间更长,重叠可能性更大。
不推荐
- 不要只关注 SM warp 的占用率,从查看单位吞吐量开始。
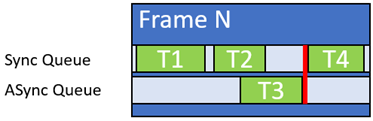
- 不要使用长异步计算工作负载,除非它们可以在依赖同步队列之前轻松完成(图 3 )。
- 不要重叠使用相同资源进行读写的工作负载,因为这会导致数据危险。
- 不要将工作负载与高 L1 和 L2 使用率以及 VRAM 吞吐量指标重叠。过度订阅或缓存命中率降低将导致性能下降。
- 如果硬件加速 GPU 调度被禁用,请小心使用两个以上的队列。来自两个以上队列(复制队列除外)的软件计划工作负载可能会导致工作负载序列化。
- 小心计算工作负载重叠,两者都会导致 WFI 。在两个队列上同时进行计算期间, WFI 会导致跨工作负载的同步。异步队列上频繁的描述符堆更改可能会导致额外的 WFI 。
- 不要使用 DX12 命令队列优先级来影响异步和同步工作负载优先级。该接口仅指示首先使用命令的队列,并且不会以任何有意义的方式影响扭曲优先级。
- 不要重叠 RTCore 工作负载。两者共享相同的吞吐量单元,并且由于干扰会降低性能。
GPU 视图示例
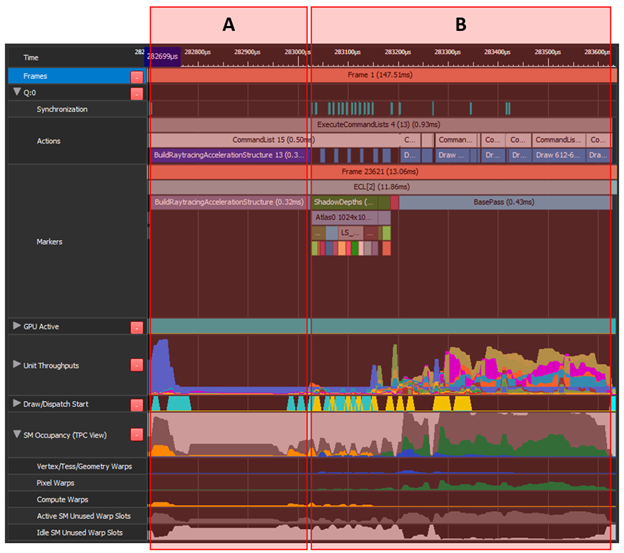
将“ A ”(构建加速结构)移动到“ B ”(阴影映射和 gbuffer )上的异步计算。“ A ”具有较低的顶部单元吞吐量和许多未使用的翘曲插槽。这同样适用于“ B ”的前约 40% ,组合起来可以是有效的重叠。
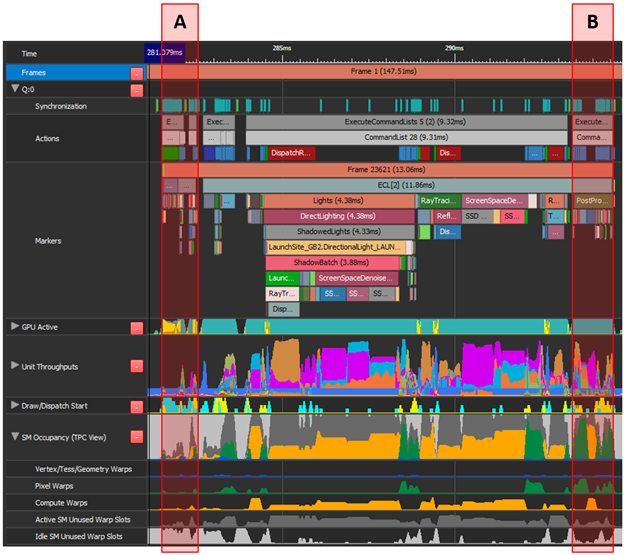
“ A ”由角色蒙皮、复制调用和一些图形组成。最高吞吐量单元为 PCI 12 . 7% 。“ B ”执行后处理,即图形和计算工作的混合,最高平均吞吐量指标为 37 . 6% 。
这两个区域没有冲突的最高吞吐量单元,并且在下一帧的“ A ”上重叠的“ B ”也利用了帧之间浪费的扭曲槽。然而,具有挑战性的部分是将所有图形工作转换为计算并触发异步队列中存在的帧。
潜在重叠组合
表 1 显示了一些常见的重叠组合和提供的 rational 。在执行这些应用程序之前,首先要考虑应用程序的单位吞吐量。
| Workload A | Workload B | Rational |
| Math-limited compute | Shadow map rasterization | Shadow maps are usually graphics-pipe dominated (CROP, PROP, ZROP, VPC, RASTER, PD, VAF, and so on) and have little interference with heavy compute work. |
| Ray tracing | Math-limited compute | If RT is RTCore dominated, the time spent traversing triangles in the BVH can be overlapped with something like denoising for the previous ray tracing pass or some other math-limited post-processing pass. |
| DLSS | Build Acceleration Structure | The majority of the DLSS workload is executed on Tensor Cores, leaving the FP and ALU datapaths mostly unused. Building acceleration structures usually has a low throughput impact and mostly depends on FP and ALU datapaths, making it an ideal overlap-candidate for DLSS. |
| Any long workload | Many short workloads with back-to-back resource synchronization or UAV barriers. | Back-to-back resource synchronization is usually damaging for efficient unit throughput and SM warp occupancy, which provides an opportunity to be overlapped with async compute. |
| Post-process at the end of previous frame | G-buffer fills at the start of next frame | Inter-frame overlap can provide substantial perf gains, provided the application is able to invoke Present() from the compute queue. |
| Build acceleration structure | G-Buffer, shadow maps, and so on | Both workloads A and B are common to underuse the throughput units or to use non-conflicting paths. In addition, build acceleration structure is a compute workload and is fairly easy to move onto the async queue. |
| Ray tracing | Shadow map rasterization | RTCore / FP overlaps Graphics (ZROP/PROP/RASTER) datapath. See Example 1. |
致谢
特别感谢您审阅并向 Alexey Pantelev 、 Leroy Sikkes 、 Louis Bavoil 和 Patrick Neill 提供宝贵反馈。




