
本文是加速数据分析系列文章的一部分。
可视化使数据栩栩如生,通过可访问的视觉效果揭示隐藏的模式和见解,并使您和您的组织能够感知无形的事物,做出明智的决策,并充分利用您的数据。
特别是在处理大型数据集时,交互可能会变得非常困难,因为渲染和计算时间变得太长。切换到 RAPIDS cuDF 等库,支持 GPU 加速,通过熟悉的类似 pandas 的 API 解锁对数据见解的访问。这篇文章解释道:
- 为什么速度对于可视化很重要,尤其是对于大型数据集
- 如何在 RAPIDS 中使用 pandas 类特征进行可视化
- 如何使用 hvPlot 、 datashader 、 cuxfilter 和 Plotly Dash
为什么速度对可视化很重要
虽然数据可视化是在项目结束时解释数据见解的有效工具,但理想情况下,应在整个数据探索和丰富过程中使用它们。可视化擅长于通过发现纯分析方法不容易出现的异常值、异常和模式来增强数据理解,这已经被证明,例如Anscombe’s quartet以及臭名昭著的Datasaurus Dozen。
有效的图表应遵循数据可视化设计原则,利用先前注意力可视处理,这种可视化风格本质上是大脑快速理解大量信息的一种技巧。然而,过滤、选择或重新绘制超过7-10秒的点等交互会破坏用户的短期记忆和思路,从而在分析过程中产生摩擦。想要了解更多信息,请参阅10的幂:用户体验中的时间尺度。
将亚秒级的速度与易于集成相结合的RAPIDS一套开源软件库非常适合用于补充探索性数据分析(EDA)工作——推动流畅、一致的见解,从而在分析项目中获得更好的结果。

大型数据分析工作流需要更多的计算能力
pandas 简化了数据工作,有助于建立强大的 Python 可视化生态系统,例如 Bokeh 、 Plotly 和 Matplotlib 等工具,使更多的人能够定期使用视觉效果进行数据分析。
但是,当 EDA 工作流处理大于 2GB 的数据,并且需要计算密集型任务时,基于 CPU 的解决方案可以开始约束迭代探索过程。
使用 RAPIDS 加速数据可视化
将基于 CPU 的库替换为类似 RAPIDS GPU 的加速库(如 cuDF )意味着,随着数据大小在 2 到 10 GB 之间的增加,您可以保持 EDA 过程的快速步伐。可视化计算和渲染时间降低到交互速度,从而解锁发现过程。此外,由于 RAPIDS 库无缝协作,您可以使用简单、熟悉的 Python 代码绘制多种类型的数据(时间序列、地理空间、图表),以将其纳入整个工作流程。
RAPIDS 可视化指南
在 GitHub 上,这个RAPIDS Visualization Guide演示了可视化库协同工作的功能和好处。基于公开的Divvy bike share 历史行程数据,笔记本电脑展示了以可视化为重点的 EDA 方法如何使用以下支持 GPU 的库进行改进:
- hvPlot:一款用于快速可视化的库。
- Datashader
- cuxfilter
- Plotly Dash
使用 hvPlot 实现简单的数据交互
hvPlot 是一个类似 pandas 的绘图 API ,但具有内置的交互性,如图 1 所示。
df.hvplot.hist(y='duration_min', bins=20, title="Trips Duration Histogram")
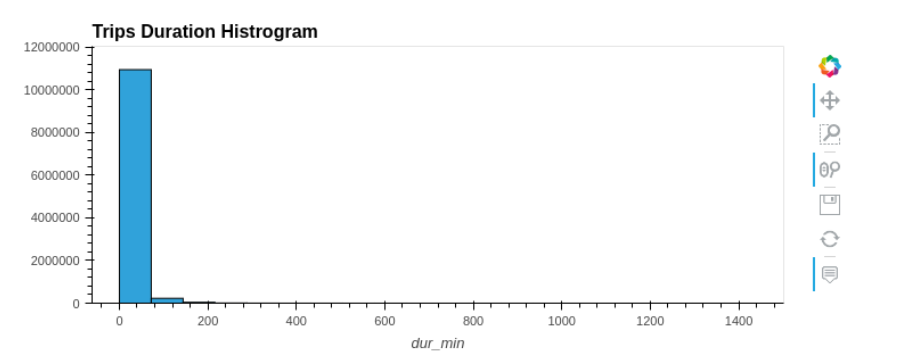
在这种情况下,绝大多数的自行车旅行时间都在 20 分钟以内。由于能够放大,您还可以在不创建其他查询的情况下检查持续时间的长尾。使用 RAPIDS cuSpatial 对数据进行扩充以快速计算距离,也表明大多数行程相对较短。
一些 hvPlot 附加功能
hvPlot 中的图表可以使用 Bokeh 和 Plotly 扩展进行交互显示,也可以使用 Matplotlib 扩展进行静态显示。多个图表可以使用*运算符共享轴,也可以使用+运算符进行并行基本布局。可以使用HoloViz Panel创建更复杂的仪表板布局。
您还可以自动添加简单的小部件。例如,当通过操作使用内置组时:
df.hvplot.heatmap(x='day_of_week', y='hour', C='count', groupby='month', widget_location='left_top')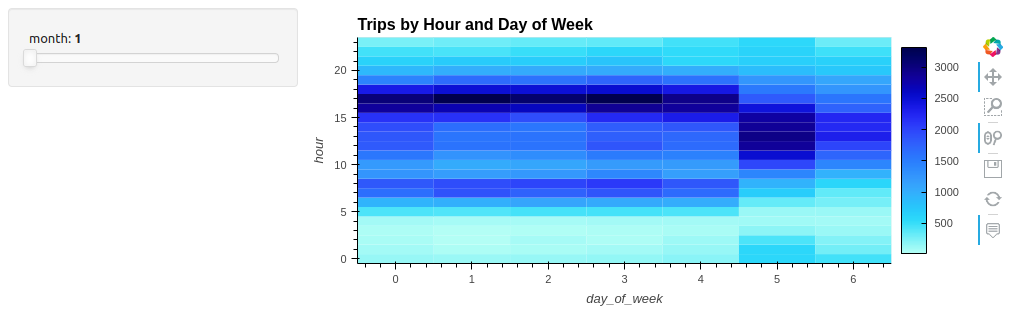
添加一个用于交互的小部件可以在几个月内搜索一整年的模式(图 2 )。在可视化中,“一个滑块值一千个查询”,或者在本例中是 12 。
轻松绘制地理空间
可以通过简单地指定geo=True来使用具有多个选项的地理空间图底层瓦片地图:
df.hvplot.hexbin(x='start_lng', y='start_lat', geo=True, tiles="OSM")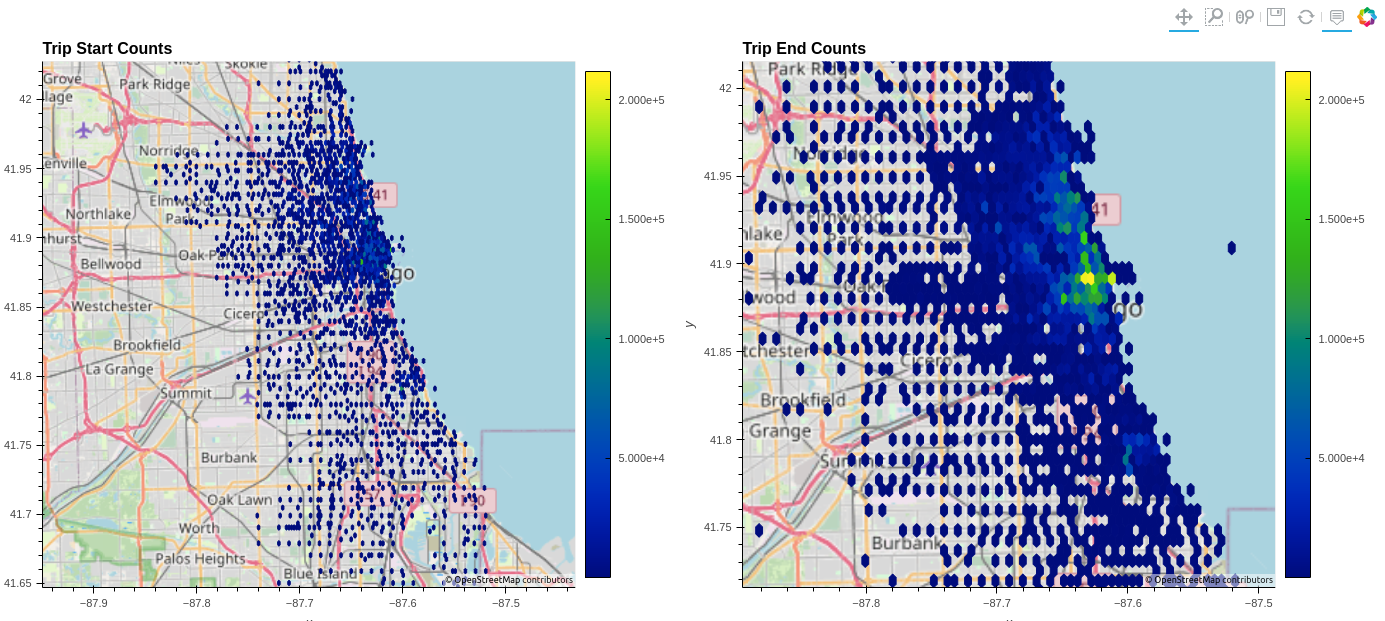
图 3 显示了六角图,该图将行程开始和结束位置聚合到可管理的数量,验证了数据是否与共享单车系统地图准确无误。与加号运营商并排设置两张图表说明了自行车网络的辐射性质。
对大数据和高精度图表使用 Datashader
Datashader 库直接支持 cuDF ,可以快速渲染数百万个聚合点。您可以单独使用它来渲染各种精确和高密度的图表类型。通过指定datashade=True:
df.hvplot.points(x='start_lng', y='start_lat', geo=True, tiles="CartoDark", datashade=True, dynspread=True)
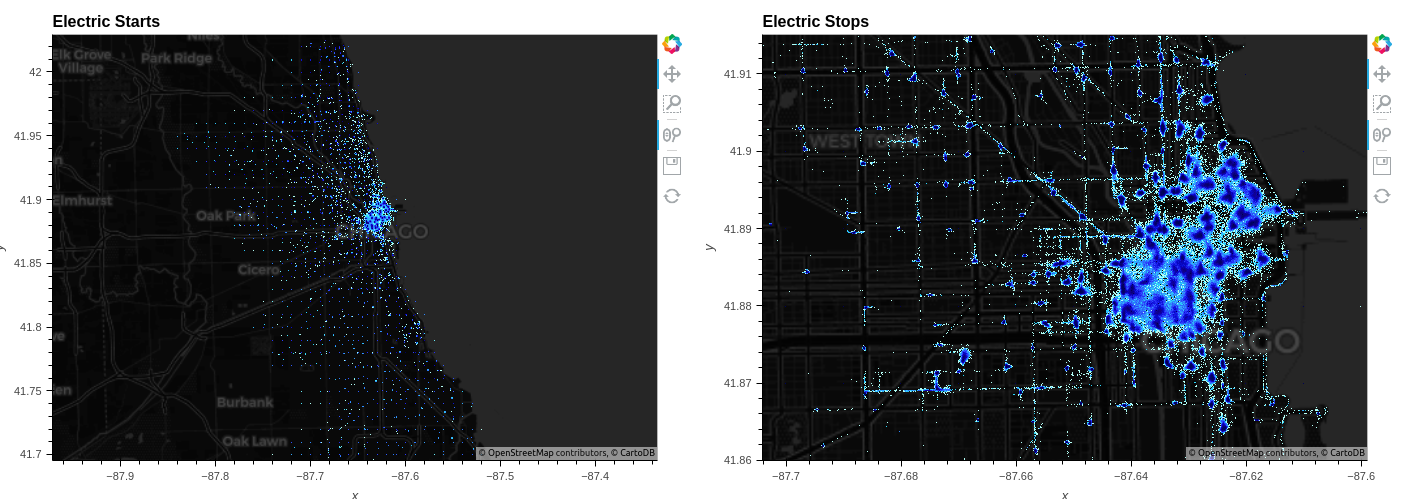
显示高分辨率图案的数据点渲染正是 Datashader 的设计初衷。在图 4 中,它清楚地表明,虽然自行车往往会聚集在一起,但不能保证自行车会在指定的车站开始或结束旅程。
将 cuxfilter 用于加速交叉过滤的仪表板
cuxfilter 仪表板可以简单地交叉链接多个图表,以快速查找模式或异常,而不是创建几个单独的分组和查询操作(图 5 )。
只需几行代码即可启动并运行仪表板:
cux_df = cuxfilter.DataFrame.from_dataframe(df)
# Specify charts
charts = [
cuxfilter.charts.bar('dist_m', data_points=20 , title='Distance in M'),
cuxfilter.charts.bar('dur_min', data_points=20 , title='Duration in Min'),
cuxfilter.charts.bar('day_of_week', title='Day of Week'),
cuxfilter.charts.bar('hour', title='Trips per Hour'),
cuxfilter.charts.bar('day', title='Trips per Day'),
cuxfilter.charts.bar('month', title='Trips per Month')
]
# Specify side panel widgets
widgets = [
cuxfilter.charts.multi_select('year')
]
# Generate the dashboard and select a layout
d = cux_df.dashboard(charts, sidebar=widgets, layout=cuxfilter.layouts.two_by_three, theme=cuxfilter.themes.rapids, title='Bike Trips Dashboard')
# Update the yaxis ticker to an easily readable format
for i in charts:
if hasattr(i.chart, 'yaxis'):
i.chart.yaxis.formatter = NumeralTickFormatter(format="0,0")
# Show generates a full dashboard in another browser tab
d.show()
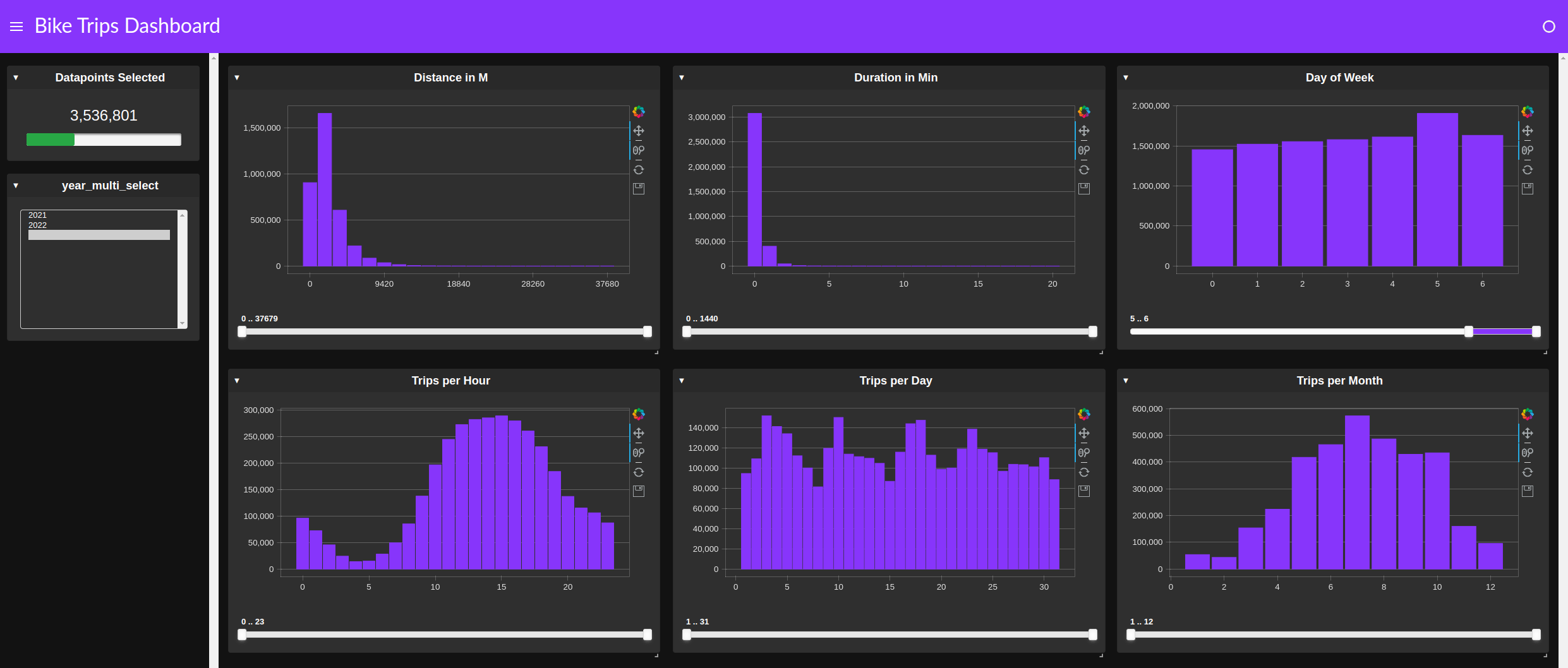
使用 cuxfilter 进行快速、基于交叉滤波器的探索是另一种可以节省时间的技术。这种方法用 GUI 工具代替了数据帧查询。如图 5 所示,在工作日和周末旅行之间,以及白天和晚上之间,出现了一种明显的模式。
使用 Plotly Dash 构建强大的分析应用程序
在通过 EDA 流程对数据进行正确格式化和增强后,使其能够更广泛地被您的组织访问和理解可能是一个挑战。 Plotly Dash 使数据科学家能够将复杂的数据机器学习工作流重新构建为更易于访问的 web 应用程序。
因此,这款笔记本的发现被封装在一个简单易用、可访问和可部署的 Plotly Dash 应用程序中。该应用程序使用 RAPIDS 提供的强大分析功能,但通过简单的 GUI 进行控制。
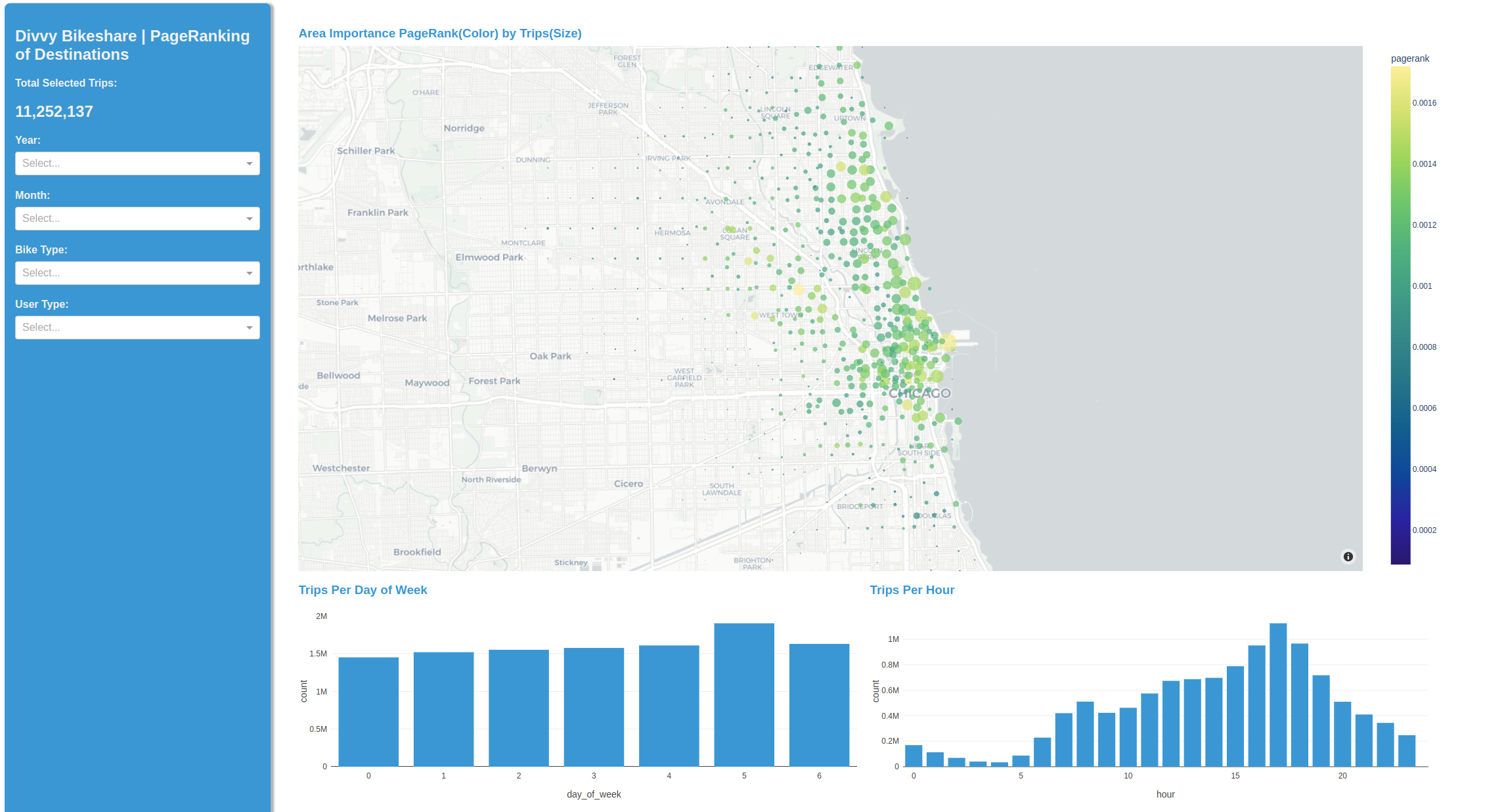
该实例使用 cuML K-means 将自行车起点和终点聚类为节点,并使用 cuGraph 的 PageRank 显示每个节点的相对重要性。后者是针对每个周末工作日和之前发现的昼夜模式实时计算的。我们从原始的使用模式开始,现在提供了对特定用户类型及其首选城市区域的交互式见解。
300M +人口普查数据点与 Plotly Dash 的亚秒交互
为了获得更全面的 Plotly Dash 示例,我们使用 2020 年和移民数据更新了流行的人口普查可视化。图 7 显示了使用 cuDF 而不是 pandas 在数百万个数据点上的交互性能优势。要查看示例演示,请访问 Google Colab 上的 Census 2020 可视化(使用 Plotly-Dash + RAPIDS)。要观看完整的 3 亿多数据集交互,请观看 使用 RAPIDS cuDF 和 Plotly Dash 可视化人口普查数据。
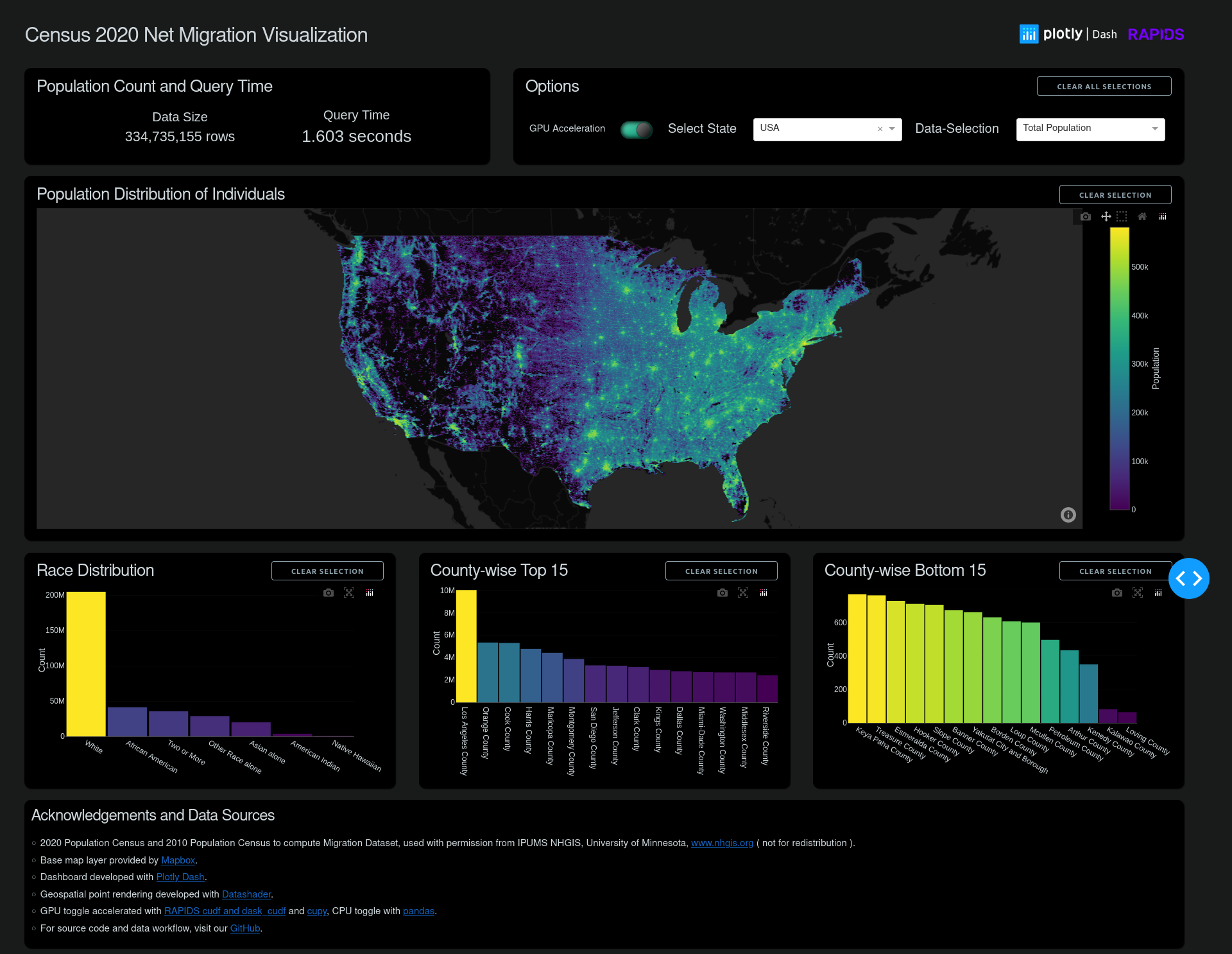
2020 年和 2010 年的人口普查数据来源于IPUMS NHGIS,明尼苏达大学。为了更准确地反映美国全国人口的分布,将块级数据扩展为随机放置在其块区域内的每个点,并进行计算以匹配块级分布。表中列出了这些数据的几种观点,包括总人口和净移民值。更多关于格式化数据的详细信息,请访问Plotly-Dash + RAPIDS Census 2020 Visualization GitHub 页面。
使用强大的可视化功能,您可以忘记该工具,沉浸在探索数据中。在这种情况下出现了一些有趣的模式:
- 人口普查区块边界发生了变化,导致大型道路有自己的独立区块。这可能是一项新的努力的结果,以更好地反映未被使用的人口。
- 除了一些热点地区外,东部各州的总体移民人数远低于中西部和西部各州。
- 新的发展,特别是大型发展,特别容易发现,可以作为影响增长、土地利用和人口密度的区域政策之间的快速视觉比较。
以思维速度实现数据可视化
通过用 cuDF 等 RAPIDS 框架取代 pandas ,并利用其简单性集成加速可视化框架,数据分析工作流程可以变得更快、更具洞察力、更高效,(只是可能)更令人愉快。
要了解有关加快数据科学工作流程的更多信息,请查看以下资源:



