지난 수개월 사이 많은 이들이 주치의와 화상 전화로 만나는 일에 익숙해졌습니다. 이는 확실히 편리하기는 하지만 일단 통화가 끝나고 나면 주치의가 했던 조언들이 헷갈리기 시작하죠. 새로 복용을 권한 약이 무엇이었는지, 주의해야 할 부작용이 있었는지 잊어버리기 십상입니다.
대화형 AI로 음성을 전사(transcript)하고, 전사본의 핵심 구문을 강조해주는 애플리케이션을 구축할 수 있습니다. NVIDIA Riva는 이 같은 작업에 사용될 최첨단 딥 러닝 모델의 구축과 배포에 소요되는 시간을 단축하는 SDK입니다.
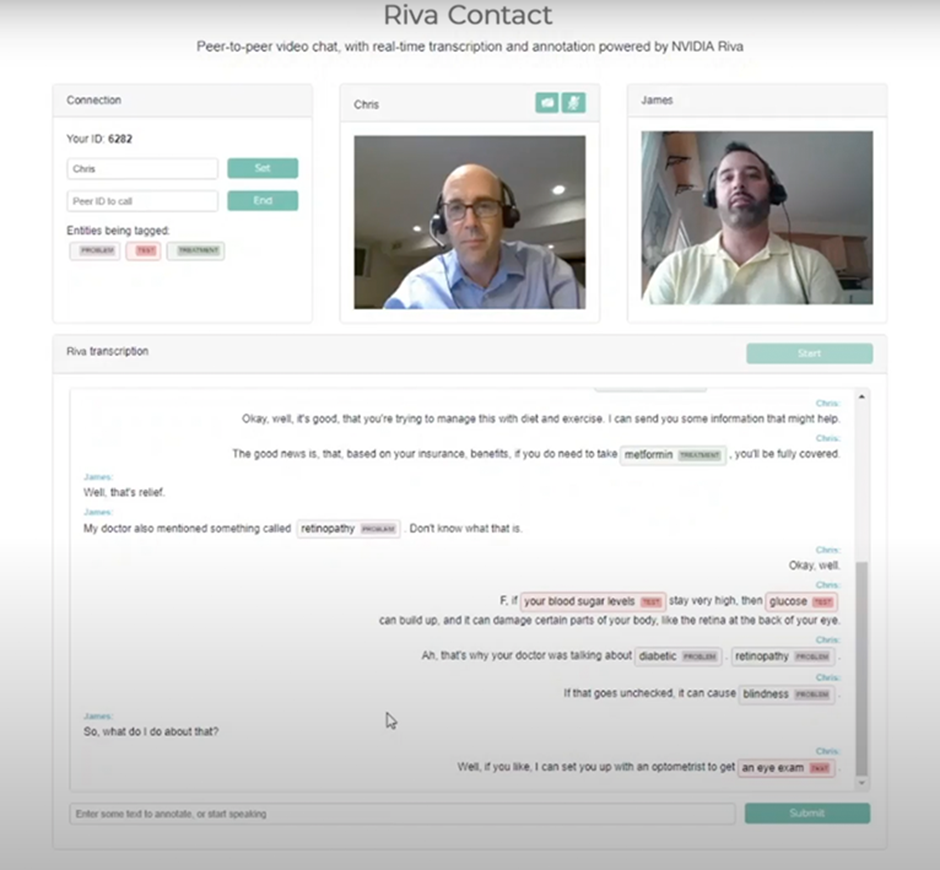
이번 포스팅에서는 실시간 화상 대화에서 음성을 전사하고 전사본의 핵심 구문에 태그를 지정하는 웹 애플리케이션의 구축법을 살펴봅니다. 예제의 화상 대화는 WebRTC 기반 피어-투-피어(peer-to-peer) 방식의 오픈 소스 채팅 프레임워크인 PeerJS를 사용합니다. 실시간 전사의 경우, Riva의 자동 음성 인식(ASR)을 활용합니다. 전사본의 핵심 구문 태그에 사용되는 개체명 인식(NER)도 Riva에 기반합니다. 이와 더불어 의료 분야 데이터로 NER 모델을 훈련하는 방법도 함께 소개하겠습니다. 본 포스팅에 코드 예제가 포함되어 있기는 하지만 명확성을 높이고자 기술적 세부 사항 일부를 생략하였으므로 Riva 샘플(Riva Samples) 도커 컨테이너를 확인할 것을 권장합니다.
이 애플리케이션은 단순형 피어-투-피어 화상 전화 웹 애플리케이션으로 시작합니다. 여기에는 다음의 리소스가 포함됩니다.
- HTML 페이지 1개
- 클라이언트 자바스크립트 파일 1개
- 서버 자바스크립트 파일 1개(에셋 호스팅과 피어-투-피어 연결 설정용)
튜토리얼은 가장 기본적인 내용만 포함할 뿐이며, 실제 애플리케이션은 훨씬 더 복잡해야 한다는 점을 잊지 마세요. ID와 세션 관리, 알림, 분석, 보다 강력한 네트워크 처리 등의 사항들이 추가될 것입니다.
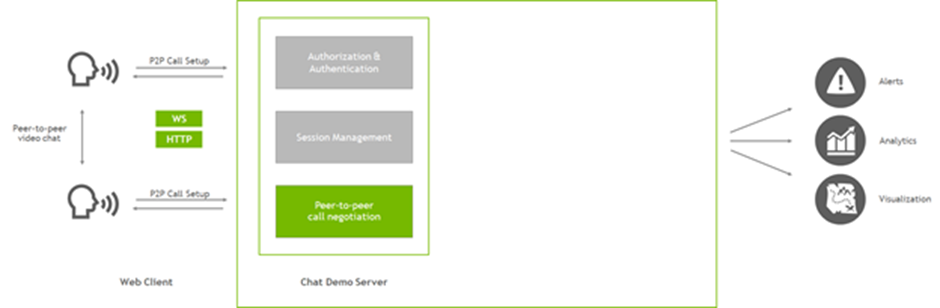
본 포스팅은 웹 애플리케이션에 ASR과 자연어 처리(NLP) 기능을 추가하는 법을 집중적으로 다루며, 해당 애플리케이션 구조의 세부 사항 일부는 건너뜁니다. 이 애플리케이션을 간단히 표현하자면, Node.js로 구현되고 익스프레스(Express)로 웹 에셋을 호스팅하는 단순형 서버입니다. 피어-투-피어 방식의 WebRTC 화상 대화에서 클라이언트들의 연결은 PeerJS가 지원하죠. 클라이언트의 브라우저는 웹 페이지를 로드한 다음, 서버와 통신해 피어와 연결 설정을 돕습니다. 피어 연결 설정을 마치면 두 클라이언트는 서로 직접 통신하게 됩니다. 서버를 통한 영상 라우팅이 더는 필요 없죠.
이를 시작으로 사용자는 웹페이지를 로드하고, 다른 사용자와 접속하며, 실시간 화상 대화를 진행할 수 있습니다.
ASR과 NLP 추가하기
NVIDIA Riva는 고성능 대화형 AI 서비스의 신속한 배포를 지원하는 SDK입니다. Riva의 빠른 시작 리소스가 제공하는 간단한 지시에 따라 Riva 추론 서버에 서비스를 신속히 배포할 수 있습니다. 이 리소스를 서버에 다운로드한 뒤 다음의 기본 과정을 수행합니다.
- config.sh로 배포를 구성합니다.
- riva_init.sh를 실행해 모델의 다운로드와 최적화, 준비를 진행합니다.
- riva_start.sh.로 Riva 스킬 서버를 시작합니다.
서버가 시작되면 애플리케이션과 Riva의 통신을 도울 gRPC 엔드포인트가 생성됩니다. 모든 것이 제대로 작동 중인지 확인하려면 Riva를 설치한 서버의 클라이언트 컨테이너를 실행해보세요. riva_start_client.sh 호출로 예제 클라이언트를 확인하고 노트북을 탐색하면서 Riva가 제공하는 기능들을 파악할 수 있습니다.
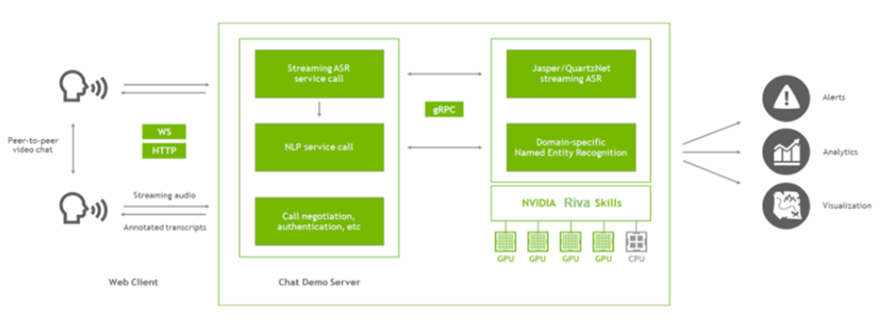
그림3은 Riva가 추가된 애플리케이션의 주요 구성 요소를 보여줍니다. 채팅 데모 서버(Node.js 애플리케이션)는 화상 전화의 설정을 담당하면서 이제 Riva 서버와도 통신합니다.
이 애플리케이션에서 Riva의 기능은 두 가지입니다. 대화의 스트리밍 전사본을 만들고 이 전사본의 핵심 구문(개체명)에 태그를 지정하는 것이죠. 이를 위해 클라이언트에서 오디오 스트림을 추출한 다음, 이 오디오를 Node.js 서버에 전달합니다. 이 서버는 gRPC로 Riva를 호출해 전사본과 개체명을 확보하고 그 결과를 클라이언트에게 다시 전달합니다. 클라이언트가 브라우저에서 렌더링한 전사본을 피어-투-피어 연결로 전달하면 두 사용자가 전체 대화를 눈으로 볼 수 있게 됩니다.
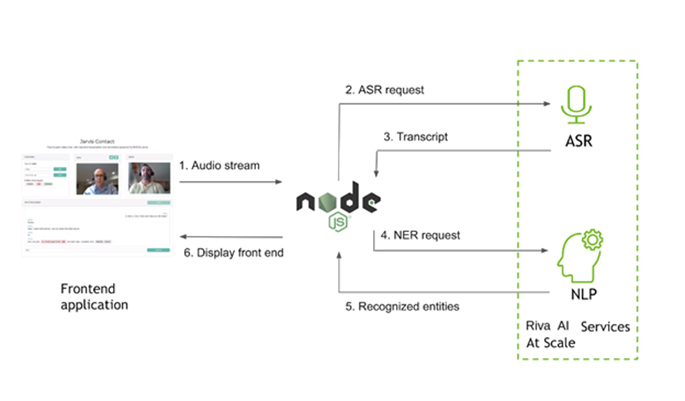
웹 클라이언트에서 오디오 가져오기
화상 대화를 위해 피어로 전송되는 로컬 WebRTC 스트림을 활용하면 클라이언트에서 오디오 스트림에 액세스할 수 있습니다. 클라이언트 자바스크립트 파일에서 사용자가 Start를 선택하면 서버와 Riva 연결이 초기화됩니다. 소켓 연결을 통해 오디오 데이터를 전송하고 있으므로 소켓이 활성 상태인지부터 확인하세요.
socket = socketio.on('connect', function() {
console.log('Connected to speech server');
});
WebRTC 오디오는 프로세싱 그래프(graph)의 개념으로 작동합니다. 브라우저에서 오디오 관련 작업을 수행하려면 다음을 실행하세요.
- 오디오 소스에 연결합니다. 본 예제의 경우에는 로컬 화상-대화 스트림에서 소스를 얻습니다.
- 이 오디오로 작업할 프로세싱 노드를 생성합니다.
- 새 노드를 해당 오디오가 원래 향하려던 도달점에 연결합니다.
새로운 프로세싱 노드에 풀 버퍼의 오디오가 들어올 때마다 웹 워커(web worker)로 이를 리샘플링(resampling)하고 소켓 연결을 통해 서버로 보냅니다. 오디오 소스 연결을 설정하고 리샘플러(resampler)를 초기화하세요.
audio_context = new AudioContext();
sampleRate = audio_context.sampleRate;
let audioInput = audio_context.createMediaStreamSource(localStream);
let bufferSize = 4096;
let recorder = audio_context.createScriptProcessor(bufferSize, 1, 1);
let worker = new Worker(resampleWorker);
worker.postMessage({
command: 'init',
config: {
sampleRate: sampleRate,
outputSampleRate: 16000
}
});
브라우저는 오디오 버퍼가 찰 때마다 이벤트를 발생시킵니다. 이를 활용해 수행할 작업을 프로세서 노드에 지정해주세요. 버퍼를 워커 스레드로 리샘플링한 뒤 소켓 연결을 사용해 서버로 전달합니다.
recorder.onaudioprocess = function(audioProcessingEvent) {
let inputBuffer = audioProcessingEvent.inputBuffer;
worker.postMessage({
command: 'convert',
// You only need the first channel
buffer: inputBuffer.getChannelData(0)
});
worker.onmessage = function(msg) {
if (msg.data.command == 'newBuffer') {
socket.emit('audio_in', msg.data.resampled.buffer);
}
};
};
오디오를 Riva로 보내기 전의 리샘플링이 필수는 아닙니다. Riva가 자체 리샘플링을 진행할 수 있기 때문이죠. 그러나 리샘플링을 브라우저에서 수행하면 대역폭 요구 사항이 줄고 리코딩 소스간 차이도 어느 정도 단순화됩니다. 이제 새 프로세서 노드를 오디오 그래프(소스 오디오와 도달점)에 연결할 수 있습니다.
audioInput.connect(recorder);
recorder.connect(audio_context.destination);
이때 애플리케이션은 사용자의 마이크에서 오디오를 가져와 스트림을 리샘플링한 뒤 소켓을 통해 서버로 보냅니다. 지금부터 이 오디오를 서버에서 활용하는 방법을 살펴보겠습니다.
오디오를 Riva로 라우팅하기
Node.js에 구현된 메인 서버 스크립트는 익스프레스 서버와 Socket.IO를 사용해 착신 접속(incoming connection)을 처리합니다. 소켓의 첫 연결 시에 Riva 연결을 설정해줍니다.
io.on('connect', (socket) => {
console.log('Client connected from %s', socket.handshake.address);
// Initialize Riva
socket.handshake.session.asr = new ASRPipe();
socket.handshake.session.asr.setupASR();
socket.handshake.session.asr.mainASR(function(result){
var nlpResult;
if (result.transcript == undefined) {
return;
}
// Final transcripts also get sent to NLP before returning
if (result.is_final) {
nlp.getRivaNer(result.transcript)
.then(function(nerResult) {
result.annotations = nerResult;
socket.emit('transcript', result);
}, function(error) {
result.annotations = {err: error};
socket.emit('transcript', result);
});
} else {
socket.emit('transcript', result);
}
});
});
이 과정에서 살펴볼 몇 가지 사항이 있습니다. ASRPipe를 새로 생성하고 소켓의 handshake.session 오브젝트에 연결하면 각 클라이언트의 연결과 관련한 별도의 Riva 스트림이 생깁니다. setupASR로 기본적인 Riva 설정을 수행한 뒤 ASR 청취 루프(loop)를 시작하세요.
ASR 청취 루프는 비동기적(asynchronous)입니다. 사용자가 오디오 데이터 배치(batch)를 주기적으로 보내주면 그 결과를 콜백 함수로 전송하는 방식이죠. 콜백은 mainASR에 전달되는 함수입니다. 스트리밍 모드에서 Riva가 내놓는 결과는 두 종류입니다. 더 많은 오디오가 유입됨(즉, 더 많은 맥락이 제공됨)에 따라 변화하는 중간 예측본과 최종 전사본입니다. 화자가 잠시 숨을 고를 때처럼 오디오에 짧은 공백이 생기면 전사본이 ‘최종’으로 파악되어 돌아오는 경향이 있는데요. 두 종류의 결과 모두가 클라이언트에게 전송되지만, 최종 결과를 얻을 때는 전사본을 NLP 서비스로도 보내 NER을 진행합니다. 둘 중 어느 쪽이든 결과를 클라이언트에게 보낼 시에는 transcript 이벤트를 써서 동일한 소켓 연결을 사용합니다.
Socket.IO로 특정 이벤트의 리스너(listener)를 설정할 수 있습니다. 이러한 이벤트의 하나를 앞에서 언급한 바 있죠. 클라이언트가 오디오 데이터 번들을 보낼 때마다 발생하는 audio_in 이벤트인데요. 서버 쪽에서는 리스너를 Riva 초기화에 사용한 것과 동일한 io.on(‘connect’) 스코프에 추가해주세요.
socket.on('audio_in', (data) => {
socket.handshake.session.asr.recognizeStream.write({audio_content: data});
});
이 부분은 구성이 간단하며 그리 많은 작업이 필요하지 않습니다. 소켓에 연결할 때 Riva 스트림을 이미 설정했으므로 새로운 오디오 콘텐츠는 그냥 전달만 하면 됩니다.
음성 인식 요청 보내기
이제 ASR을 시작으로 gRPC 인터페이스를 살펴보겠습니다. Node.js를 사용하는 gRPC 서비스와의 연결은 크게 다음의 3단계를 거칩니다.
- 프로토콜 버퍼로 Riva API 가져오기.
- 이 API 위주로 편의 함수(convenience function) 작성하기.
- 클라이언트와 Riva 함수 사이에 데이터 개입시키기.
앞서 호출된 ASRPipe 클래스를 정의하는 asr.js 모듈에서 먼저 Riva API를 가져오기 합니다.
const jAudio = require('./protos/src/riva_proto/audio_pb');
var asrProto = 'src/riva_proto/riva_asr.proto';
var protoOptions = {
keepCase: true,
longs: String,
enums: String,
defaults: true,
oneofs: true,
includeDirs: [protoRoot]
};
var asrPkgDef = protoLoader.loadSync(asrProto, protoOptions);
var jAsr = grpc.loadPackageDefinition(asrPkgDef).nvidia.riva.asr;
ASRPipe 클래스와 함께 앞서 호출된 설정 함수를 정의해줍니다.
class ASRPipe {
setupASR() {
// the Riva ASR client
this.asrClient = new jAsr.RivaSpeechRecognition(process.env.RIVA_API_URL, grpc.credentials.createInsecure());
this.firstRequest = {
streaming_config: {
config: {
encoding: jAudio.AudioEncoding.LINEAR_PCM,
sample_rate_hertz: 16000,
language_code: ‘en-US’,
max_alternatives: 1,
enable_automatic_punctuation: true
},
interim_results: true
}
};
}
}
여기서 Riva ASR 클라이언트를 생성하고 일부 구성 파라미터를 정의해두면 스트림이 열릴 때 최초 요청으로 전송됩니다. 동일한 클래스 정의에서 mainASR 함수를 지정해 실제 ASR 스트림을 설정하세요.
async mainASR(transcription_cb) {
this.recognizeStream = this.asrClient.streamingRecognize()
.on('data', function(data){
if (data.results == undefined || data.results[0] == undefined) {
return;
}
// transcription_cb is the result-handling callback
transcription_cb({
transcript: data.results[0].alternatives[0].transcript,
is_final: data.results[0].is_final
});
})
.on('error', (error) => {
console.log('Error via streamingRecognize callback');
console.log(error);
})
.on('end', () => {
console.log('StreamingRecognize end');
});
// First request to the stream is the configuration
this.recognizeStream.write(this.firstRequest);
}
streamingRecognize 함수는 비동기적입니다. 데이터 이벤트는 Riva 가 전송할 결과가 있을 때마다 발생하며, 이 결과를 리패키지(repackage)해 앞서 언급한 콜백 함수로 전달합니다.
NER 요청 보내기
Riva NER 서비스의 호출은 더 간단합니다. 이전과 마찬가지로 NLP API를 로드한 다음, ClassifyTokens 함수와 함께 처리할 텍스트의 각 라인을 호출합니다. 개별 요청들은 텍스트와 더불어 Riva가 배포된 모델을 전송합니다. 필요에 따라 computeSpans 함수로 후처리를 진행한 뒤 결과를 전달합니다.
function getRivaNer(text) {
var entities;
req = { text: , model: {model_name: process.env.RIVA_NER_MODEL} };
return new Promise(function(resolve, reject) {
nlpClient.ClassifyTokens(req, function(err, resp_ner) {
if (err) {
reject(err);
} else {
entities = computeSpans(text, resp_ner.results[0].results);
resolve({ner: entities});
}
});
});
};
이 지점에서 Riva로의 gRPC 호출이 완료됩니다. 클라이언트에서 오디오를 캡처하고 스트리밍 연결로 Riva에 전송해 전사본을 확보하는 한편, 텍스트 내 개체명에 태그를 지정할 수 있죠. Riva가 내놓는 결과는 transcript 이벤트와 함께 소켓을 통해 사용자의 웹 클라이언트로 전달됩니다. 이제 브라우저에서 이 결과를 처리해 해당 서킷(circuit)을 완성합니다.
결과를 브라우저에서 렌더링하기
주석화되어 웹 클라이언트로 돌아오는 전사본을 브라우저에 표시합니다. 클라이언트-서버 통신 일체가 Socket.IO 연결을 통해 이뤄지므로 결과를 전달하는 transcript 이벤트용 리스너를 설정해야 한다는 사실을 잊지 마세요.
socket.on('transcript', function(result) {
document.getElementById('input_field').value = result.transcript;
if (result.is_final) {
// Erase input field
$('#input_field').val('');
showAnnotatedTranscript(username, result.annotations, result.transcript);
// Send the transcript to the peer to render
if (peerConn != undefined && callActive) {
peerConn.send({from: username, type: 'transcript', annotations: result.annotations, text: result.transcript});
}
}
});
input_field는 웹 UI에서 중간 전사본을 표시하기에 편리한 위치로, 발화에 맞춰 실시간으로 업데이트됩니다. 애플리케이션 전체에서 동일한 필드를 사용해 텍스트 전용 요청을 보냅니다. 전사본이 ‘최종’으로 표시되면 이를 별도의 상자로 표시하고 해당 전사본의 복사본을 통화 상대에게 보내 두 사람의 대화 모두를 눈으로 볼 수 있게 됩니다.
전사본 자체의 렌더링은 표준 HTML과 CSS로 진행합니다. 작업을 보다 손쉽게 하려면 우수한 displaCy-ENT로 텍스트에 맞춰 개체명을 표시하세요.
의료 NER용 모델 미세 조정하기
기본적으로 Riva는 지명(Location), 인명(Person), 기관명(Organization), 시간(Time) 등의 개체명을 처리하는 NER 모델을 제공합니다. 이 모델은 뉴스 기사의 이해나 챗봇 구축 등의 다양한 애플리케이션에 아주 유용하죠. 본 포스팅의 도입부에서 우리는 대화형 AI가 원격 의료 애플리케이션에 기여할 수 있다고 논했는데요. 지금부터 리바토(Rivato) 의료 개체명 태그를 위한 NER 모델의 훈련법을 살펴보겠습니다.
모델을 완전히 처음부터 새로 훈련시키려면 대개 상당한 시간이 소요됩니다. 새로운 모델로 시작하는 대신 이미 훈련을 마친 기존 모델을 사용해 커스텀 데이터로 미세 조정하는 방법이 있습니다. NVIDIA TAO Toolkit는 파이썬(Python) 기반의 AI 툴키트로, 사전 훈련 모델의 미세 조정과 커스터마이징에 드는 시간을 단축하도록 특수 설계됐습니다.
의료 데이터는 민감한 정보를 포함하기 때문에 온라인에서 찾기 힘들 때가 있습니다. 2010년 i2b2/VA 챌린지 당시 아주 우수한 NER 데이터세트가 개발됐는데요. 여기에는 문제(질병 또는 증상)와 치료(약물 처방 포함), 검사를 태그로 지정하고 의료진의 신원은 삭제한 기록들이 포함돼 있습니다. 이 데이터세트는 의료 NLP 커뮤니티에서 표준 벤치마크로 사용되고 있으며 여러분도 액세스를 신청할 수 있습니다.
NER 데이터는 대개 IOB 태깅 형태로 제공되며, 텍스트 내 각 토큰(token)은 개체 시작(Beginning an entity)이나 개체(첫 단어 아님) 내(Inside an entity), 또는 외(Outside) 중 하나로 라벨링됩니다. 의료 텍스트의 경우 다음과 같은 형태로 보일 수 있습니다.
텍스트:
DISCHARGE DIAGNOSES :
Coronary artery disease , status post coronary artery bypass graft .
라벨:
O O O
B-problem I-problem I-problem O O O B-treatment I-treatment I-treatment I-treatment O
이것이 TAO Toolkit에 인풋으로 사용할 데이터입니다. TAO를 사용해 NER 모델을 훈련하는 방법에 대한 추가 정보는 TAO-Riva NER 컬렉션의 훈련용 노트북을 참고하세요. 본 예제의 경우 사전 훈련된 언어 모델 체크포인트인 ‘bert-base-uncased’에서 시작하며, 전처리를 진행한 i2b2 데이터로 NER 작업에 맞게 미세 조정합니다.
커스텀 모델의 훈련과 배포는 몇 가지 단계를 거칩니다. 사전 훈련된 체크포인트로 시작할 때는 TAO Toolkit와 커스텀 데이터로 미세 조정합니다. 역시 TAO를 이용해 이 모델을 Riva에 최적화된 모델로 내보내기 할 수도 있죠. Riva에 기본적인 배포 설정을 일부 제공해 구성을 아우르는 중간형을 구축하세요. 그런 다음 이 패키지를 배포해 활성 Riva 서버를 생성합니다. 더 자세한 정보는 NVIDIA Riva Speech Skills을 참고하세요.
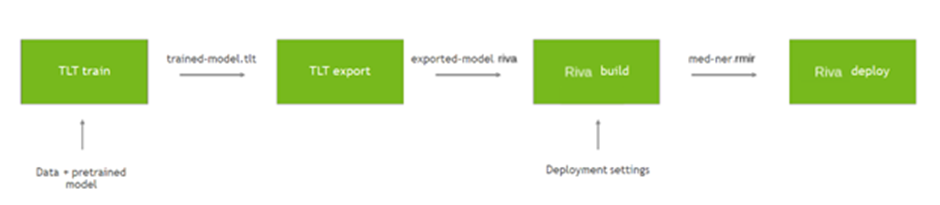
다음 명령은 TAO Toolkit를 사용해 사전 훈련 모델을 커스텀 데이터로 미세 조정합니다.
!tlt token_classification train \
-e $SPECS_DIR/train.yaml \ # Specification file
-g 1 \
-k $KEY \
-r $RESULTS_DIR/medical_ner \
data_dir={destination_mount}/data/i2b2 \
model.label_ids={destination_mount}/data/i2b2/label_ids.csv \
trainer.max_epochs=10
이 작업이 완료된 뒤 TAO Toolkit는 모델을 trained-model.tlt라는 이름의 파일에 저장합니다. 다음 단계에서는 이 모델을 Riva가 배포에 사용할 수 있는 .riva 형식으로 내보내기 합니다.
!tlt token_classification export \
-e $SPECS_DIR/export.yaml \ # Specification file
-g 1 \
-m $RESULTS_DIR/medical_ner/checkpoints/trained-model.tlt \
-k $KEY \
-r $RESULTS_DIR/medical_ner \
export_format=RIVA
이 모델은 이제 Riva에서 사용할 수 있는 exported-model.riva로 내보내기 됩니다.
Riva ServiceMaker Docker 이미지를 사용해 새로운 모델을 구축/배포하세요.
docker pull nvcr.io/riva/riva-speech:1.0.0b1-rc5-servicemaker
docker run --gpus all -it --rm
-v $RESULTS_DIR/medical_ner:/servicemaker-dev
-v $RIVA_REPO_DIR:/data
--entrypoint="/bin/bash"
nvcr.io/ea-riva-stage/riva-service-maker:1.0.0b1-rc5
riva-build token_classification
--IOB=true
/data/med-ner.jmir
/servicemaker-dev/exported-model.riva
riva-deploy /data/med-ner.jmir /data/models -f
–IOB 플래그는 모델 아웃풋을 ‘IOB 태그 NER 모델’로 해석하도록 지시해 모델 아웃풋을 간소화합니다. $RIVA_REPO_DIR은 빠른 시작 스크립트에서 riva_init.sh를 실행할 때 생성된 Riva 저장소의 위치입니다. 이 저장소에는 디폴트 상태의 일반 도메인 NER 등 배포 모델 일체의 모델 하위 디렉터리가 포함돼 있습니다. riva-deploy를 호출하면 Riva는 그 위치에 새로운 NER 모델을 삽입합니다.
이 새로운 NER 모델이 적용되면 이제 애플리케이션에서 대화 내내 실시간으로 표시되는 의료 도메인 태그를 경험할 수 있습니다.

프로덕션 배포
Riva는 고도의 확장성을 보장하도록 설계됐으며, Riva SDK로 개발된 애플리케이션들은 클라우드나 온프레미스 환경의 쿠버네티스 클러스터에 배포가 가능합니다. 시작 시에 활용이 가능한 핼름 차트(Helm chart) 샘플도 함께 제공됩니다.
여러분의 클러스터에 쿠버네티스, 헬름 3.0, 쿠버네티스용 NVIDIA GPU Operator를 설치하세요. 그런 다음 NGC에서 Riva AI 서비스의 헬름 차트를 다운로드합니다.
export NGC_API_KEY=<your_api_key>
helm fetch https://helm.ngc.nvidia.com/ea-riva/charts/riva-api-0.1-ea.tgz --username='$oauthtoken' --password=<YOUR API KEY>
폴더의 압축을 푼 뒤 /riva-api에서 배포에 필요한 파일들을 찾습니다.
riva-api
├── Chart.yaml
├── templates
│ ├── deployment.yaml
│ ├── _helpers.tpl
│ └── service.yaml
└── values.yaml
Chart.yaml 파일에는 이름과 버전 등 헬름 배포 정보가 들어 있습니다. 배포 구성을 변경하려면 values.yaml 파일에서 필요에 맞춰 구성을 바꿔주세요.
- replicaCount: Riva 서비스 복제본의 수.
- speechServices [asr | nlp | tts]: 음성 서비스 활성화를 위한 세 개의 불 방식(Boolean) 파라미터.
- ngcModelConfigs: NGC에서 다운로드할 모델 구성.
- service: 프로덕션에 배포할 로드 밸런싱 서비스.
values.yaml 파일에서 값을 읽어들이는 쿠버네티스 배포 파일은 탬플릿 폴더에 있습니다. 쿠버네티스 클러스터의 Riva 샘플 배포는 다음의 과정을 따릅니다.
- GPU 노드를 찾고 사전 훈련 모델이 포함된 Riva Speech Docker 컨테이너를 가져오기 합니다.
- 모델 디렉터리가 포함된 도커 볼륨을 마운트합니다.
- Triton Inference Server를 가져와 설정/실행합니다.
- 인바운드 추론 요청과 아웃바운드 응답을 위한 포트를 엽니다.
- GPU와 추론 메트릭을 가져오기 위한 프로메테우스(Prometheus) 서비스를 설정합니다.
마지막으로 Riva 서버를 배포하기 위해 다음의 명령을 실행하세요.
helm install riva_server riva-api또는 –set 옵션을 사용해 values.yaml 파일을 수정 없이 설치할 수도 있습니다. NGC_API_KEY와 ngcCredentials.email, model_key_string 값을 적절히 설정했는지 확인하세요. 기본적으로 model_key_string 옵션은 tlt_encode로 설정돼 있습니다.
helm install riva-api --set ngcCredentials.password=`echo -n $NGC_API_KEY | base64 -w0` --set ngcCredentials.email=your_email@your_domain.com --set modelRepoGenerator.modelDeployKey=`echo -n model_key_string | base64 -w0`
> NAME: riva-api
LAST DEPLOYED: Thu Jan 28 12:05:36 2021
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
로그를 확인해 Riva 서버가 오류 없이 배포됐는지 확인합니다.
kubectl get pods
kubectl logs <pod name>
Riva 서버에 추론을 요청하려면 로드 밸런서의 IP 주소를 확보해야 합니다.
kubectl get services
> NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
riva-api LoadBalancer 10.100.194.170 ac51c23e62d094aa68ac2adb98edb7eb-798330929.us-east-2.elb.amazonaws.com 8000:30034/TCP,8001:31749/TCP,8002:30708/TCP,50051:30513/TCP,60051:31739/TCP 2m19s
kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 123m
EXTERNAL-IP 값은 env.txt에서 external endpoint로 사용할 수 있습니다.
RIVA_API_URL= <external-IP> 이상적인 마이크로서비스 배포 아키텍처라면 샘플 웹 애플리케이션이 헬름 배포에도 포함돼야 합니다. 그러나 본 포스팅의 클러스터 환경에서는 Node.js 애플리케이션을 무시합니다. 샘플 애플리케이션에서 이전 명령의 클러스터 IP 주소를 사용해 Riva ASR과 NLP 기능을 규모에 맞춰 검증합니다.
결론
여러분의 활용 사례에 맞춰 커스터마이징한 대화형 AI 애플리케이션이 우수한 성능과 확장성까지 겸비하기는 쉬운 일이 아닙니다. 이번 포스팅에서 우리는 NVIDIA Riva를 사용해 기존의 애플리케이션에 오디오 전사와 개체명 인식 기능을 손쉽게 추가하는 방법을 논했습니다. 또한 TAO Toolkit를 사용해 애플리케이션을 커스터마이징하고, 헬름 차트로 규모에 맞춰 배포하는 방법을 살펴보았습니다. 지금 Riva를 다운로드하고 작업을 시작하세요.