
近年、大規模言語モデル (LLM) の進化は目覚ましく、その能力をさらに拡張する「AI エージェント」が注目を集めています。AI エージェントは、LLM が自律的に意思決定を行い、外部ツールを利用してタスクを遂行することを可能にする枠組みです。これにより、単なるテキスト生成にとどまらず、複雑な問題解決や実世界とのインタラクションが可能になります。
AI エージェントについてなんとなく知ってはいるものの、AI エージェントが実際にどのように実装されていて動作しているのかがわからない、という声をよく聞きます。そこで本記事では、そういった方を対象に AI エージェントの概念を簡潔に解説し、特に「ReAct エージェント」に焦点を当てて、その仕組みと実装方法について解説します。また、エージェントの開発には、評価や可観測性が非常に重要になりますが、NVIDIA NeMo Agent Toolkit を用いることで、ReAct エージェントがどのような挙動をしているかなどを簡単に可視化することができます。
ReAct (Reasoning and Acting) は、LLM がリーズニング (Reason) と行動 (Act) を繰り返しながら目標を達成する強力な手法です。それでは ReAct エージェントがどのように動作し、LangGraph や NeMo Agent Toolkit といったツールを使ってどのように実装できるのかを詳しく見ていきましょう。
ReAct エージェント
ReAct エージェントの概要
現在最も広く用いられている AI エージェントの 1 つに ReAct (Reasoning and Acting) があります。元は 2022 年の論文で発表された、LLM のプロンプト テクニックです。このテクニックを用いることで、LLM は「リーズニング (推論)」と「アクション (行動)」を交互に繰り返しながら複雑なタスクを効率的に解決し、最終的な回答を生成できるようになります。
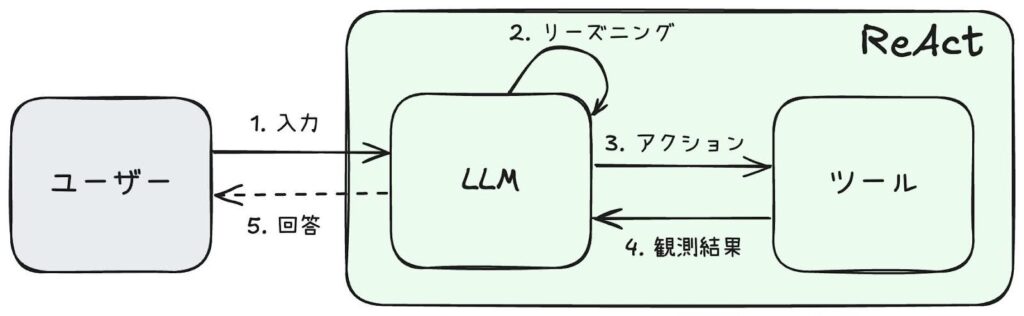
ReAct のプロセスは、以下のステップで進行します。
- ユーザーから LLM にプロンプト (タスクなど) を入力
- LLM がリーズニングを行い、ツールを利用するかどうか決定
- LLM がツールを実行
- ツールの実行結果 (観測結果) を LLM に入力
- 最終的な回答をユーザーに返す (または、2 に戻る)
ReAct の実装方法は多岐にわたりますが、本記事ではツール実行時に LLM の「Tool Calling」機能を利用する実装方法に焦点を当てて解説します。
Tool Calling
LLM がツールを利用する際に重要な機能として Tool Calling (Function Calling とも呼ばれる) があります。Tool Calling とは、LLM は入力プロンプトとツールのリストを受け取り、出力として最適なツールとその引数を返す機能です (ツールを使う必要がない場合は、通常の LLM と同様に返答文を返す)。Tool Calling という名前から、あたかも LLM がツールを直接実行するように誤解されることもありますが、実際にはそうではなく、LLM がおこなうのは「実行すべきツールの選択」のみです。ツールの実行自体は別途プログラムで実行します。
Tool Calling を図で表したのが以下の図になります。
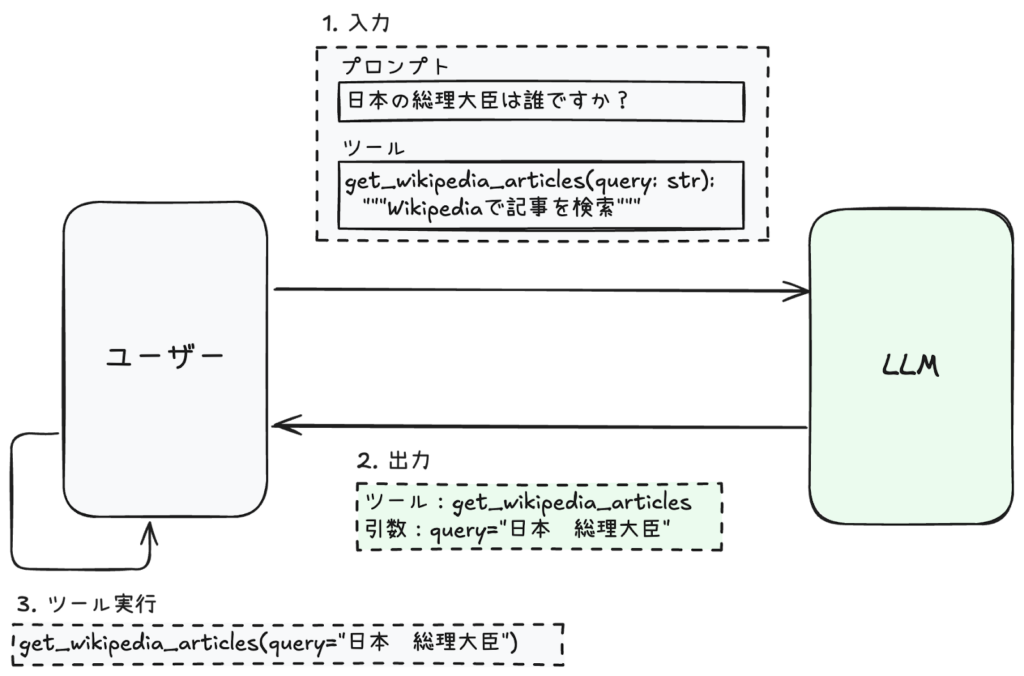
まずはユーザーからの入力ですが、プロンプトとツールがあります。ユーザーは日本の総理大臣の名前を聞いています。また、ツールとして Wikipedia 検索 (get_wikipedia_articles 関数) を指定したとします。続いて LLM は、「get_wikipedia_articles を query=”日本 総理大臣” で使いますよ」と返答します。(分かりやすさのために LLM の思考過程をあえて書き出すと、LLM は「ユーザーは日本の総理大臣を知りたいらしい。でも現在の総理大臣が誰かは確証を得られない。ツールとして Wikipedia 検索があるようだ。それならまずは ”日本 総理大臣” で Wikipedia 検索をしよう」というような考えから上記の出力をしたと捉えると Tool Calling がより分かりやすいです。ただし、この思考過程は LLM が実際に行っているものではなく、わかりやすさのために筆者があえて書いていることにご留意ください。) そして、ユーザー側では LLM の出力に従って、get_wikipedia_articles(query=”日本 総理大臣”) を実行します。あとは Wikipedia の検索結果をプロンプトに追加して再度 LLM に入力文を送ることで、最終的な回答を得ることができます。
このように Tool Calling によって、あたかも LLM がツールを使用しているような挙動、というのを実現することができます。この機能により、LLM は外部のツールや API と連携し、情報の検索、計算、データ操作など、LLM 単体では難しい複雑なタスクを遂行することが可能になります。これにより、LLM の能力が大幅に拡張され、より実用的なアプリケーションへの応用が可能となります。
ReAct エージェントの実装
ReAct は、「リーズニング (推論)」と「アクション」という 2 つのプロセスを繰り返すことで機能します。リーズニング フェーズでは、LLM は目標を達成させるための思考をおこないます。例えば、LLM は目標を達成するために、タスクをいくつかのプロセスに分解したり、検索クエリを考えたりします。このようなプロセスは通常、LLM に与えるプロンプトを通して実装されます。一方、アクション フェーズでは上記で登場した Tool Calling を活用します。
今回は 2 つのツールを持つ ReAct エージェントを実装します。LLM として OpenAI の GPT-5 を利用します。
- LLM
- GPT-5
- ツール
get_current_datetime(): 現在の日付を取得get_wikipedia_articles(): Wikipedia検索
実装には、エージェント フレームワークとして広く用いられている LangGraph を使用します。LangGraph は、LLM のオーケストレーション ツールとして有名な LangChain から派生したものです。
LangGraph の最大の特徴は、エージェントをグラフとして構築する点です。ここでのグラフとは、「ノードとエッジで構成されるグラフ」のことです。AI エージェントはユーザーの入力を起点に、状況に応じてリーズニングとアクションを選択しながらタスクを遂行します。エージェントの挙動が直列に進行していく場合は LangChain のチェーンで実装できます。ただし、一般的なエージェントには、ループや枝分かれなどの挙動を多く含みます。この場合、LangChain でエージェントを実装しようとすると、実装が複雑になってしまいます。一方で、LangGraph はグラフ構造を採用することで、このようなループ構造などを手軽に実装することができます。
また、LangChain との連携が強固であることも LangGraph の特徴のひとつです。今回は各ノードのロジックを LangChain で実装し、ノード間を LangGraph で接続することで、ReAct エージェントを実装します。
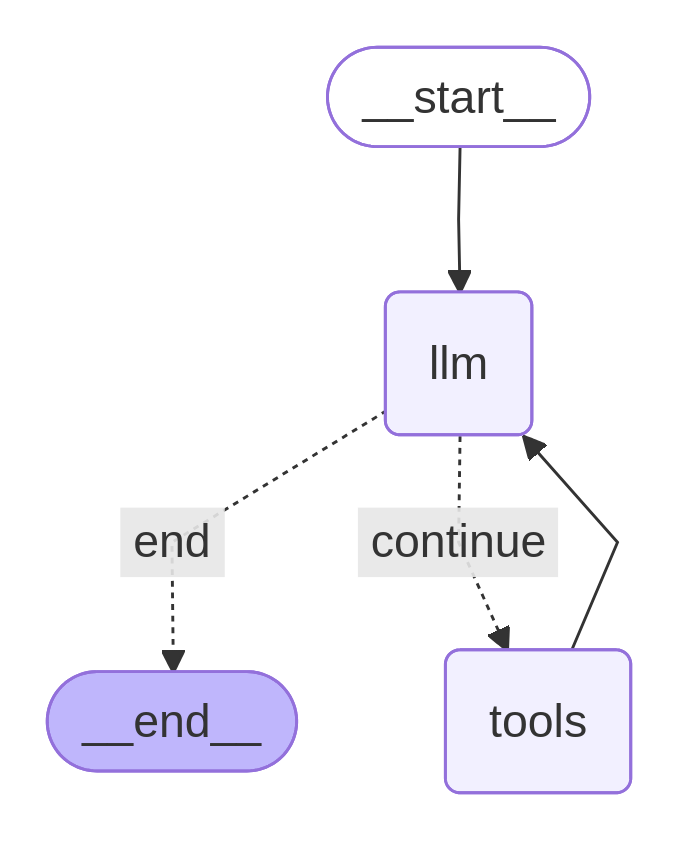
いまから実装する ReAct エージェントをグラフで実装します。視覚的には以下の図にあるようなグラフになります。__start__ ノードから開始し、llm ノードが条件分岐しています。LLM がツールを使う場合 (continue エッジ) は tools ノードに行きツールを実行したら、また llm ノードに戻ります。一方で、LLM がツールを使わない場合 (end エッジ) は __end__ ノードで終了します。
環境構築
実行環境は、CPU のみでよく、GPU は必要ありません。また、Python はバージョン 3.11 以上である必要があります (筆者の環境は Python 3.12.9)。
まずは必要なライブラリをインストールします。ここでは OpenAI の LLM を用いることにします。
pip install langgraph==0.6.8 langchain-community==0.3.30 wikipedia==1.4.0 langchain-openai==0.3.33 pyppeteer==2.0.0
続いて、環境変数を設定します。 (ここでは実装をシンプルにするため、API キーをコード内に直接記述しています。.env ファイルで管理するなど、API キーの管理には十分注意してください。)
import os
os.environ["OPENAI_API_KEY"] = #<OpenAIのAPI KEYをここに記載>
LLM とツール
ツールの定義
ツールとして「現在時刻ツール」と「Wikipedia 検索ツール」の 2 つを実装します。これらのツールは、Python で関数を定義して実装しています。LangChain の @tool デコレーターを用いることで、LLM にツールとして認識させることができます。また、@tool デコレーターでラップした関数は、docstring (下のコードだと、"""今日の日付を取得""") の記述が必須になります。LLM は各ツールの docstring を受け取り、どのツールを利用するかを選択します。
from datetime import datetime
from langchain_core.tools import tool
@tool(return_direct=True)
def get_current_datetime():
"""今日の日付を取得"""
return datetime.now().strftime("%Y-%m-%d")
続いて Wikipedia 検索ツールです。まずはツールへの入力として、SearchInput クラスを定義しています。Wikipedia 検索ツール自体は、現在時刻ツールと同様に Python の関数で定義し、@tool デコレーターでラッピングしています。docstring の記述も忘れないようにしてください。
from langchain_community.retrievers.wikipedia import WikipediaRetriever
from pydantic import BaseModel, Field
class SearchInput(BaseModel):
query: str = Field(description="Wikipedia検索で用いるクエリ。自然文よりも単語の方が良い検索結果が得られる。")
language: str = Field(description="Wikipedia検索で用いる言語", default="ja")
@tool(args_schema=SearchInput, return_direct=True)
def get_wikipedia_article(query: str, language: str):
"""Wikipediaの記事を検索"""
wiki_retriever = WikipediaRetriever(
lang=language,
top_k_results=3,
)
articles = wiki_retriever.invoke(query)
if articles:
try:
return articles
except Exception as e:
return {"error": str(e)}
else:
return {"error": "記事が見つかりません"}
これでツールの作成は完了です。
Tool Calling
上記で定義したツールを用いて、LLM の Tool Calling 機能を試してみます。LangChain では llm.bind_tools(tools) とするだけで、LLM (今回は GPT-5) が Tool Calling 機能を用いて適切なツールを選択してくれるようになります。
from langchain_openai import ChatOpenAI
tools = [get_wikipedia_article, get_current_datetime]
# LLMインスタンスを作成
model_name = "gpt-5"
llm = ChatOpenAI(
model=model_name,
temperature=0.0,
)
# LLMにツールを紐づける
model = llm.bind_tools(tools)
# ツールを紐づけたLLMを試す
res = model.invoke("日本の首相の出身地はどこですか?")
res.tool_calls
上記を実行すると、出力 res.tool_calls には呼ぶべきツールがリストで格納されます。出力結果はここに示したものと変わる可能性がありますが、この出力から各要素に「ツール名」および「引数」が含まれていることが分かります。
[{'name': 'get_current_datetime',
'args': {},
'id': 'call_RNquPfXMO51JRWII2kFY00DB',
'type': 'tool_call'},
{'name': 'get_wikipedia_article',
'args': {'query': '内閣総理大臣 現職', 'language': 'ja'},
'id': 'call_aO98YOd501bplsoZ8kU1bNIo',
'type': 'tool_call'}]
上記の出力結果を見ると、まずは get_current_datetime() を実行し、続いて get_wikipedia_article(query=”内閣総理大臣 現職”, language=”ja”) を実行するように LLM が指定していることがわかります。現在時刻と総理大臣のページさえとれればまずは今の総理大臣の名前が分かりそうなので、LLM のこの出力は正しそうです。OpenAI の Tool Calling (Function Calling) の仕様はこちらのドキュメントをご参照ください。
ついでに LLM がツールを使わないパターンも見てみましょう。LLM がツールを使わずとも答えられそうな質問として “日本の首都はどこですか?” を入力してみます。
# ユーザーの入力
user_input = "日本の首都はどこですか?"
# (任意)エージェントの挙動を簡易的なシステムプロンプトで指定
prompt_template = "ユーザーの質問に答えるために必要に応じて与えられているツールを使ってください。\n\n{input}"
user_input = prompt_template.format(input=user_input)
# ツールを紐づけたLLMにクエリを入力する
res = model.invoke(user_input)
print(f"{res.tool_calls = }")
res.pretty_print()
以下の出力にあるように、res.tool_calls は空になっています。そして、モデルはツールを使わずに回答を直接出力しています。つまり、モデルがツールを使わず回答を行う際は res.tool_calls は空のリストになるということです。これは、ReAct エージェントの終了条件に使うので覚えておいてください。
res.tool_calls = []
================================== Ai Message ==================================
日本の首都は東京(東京都)です。厳密な法的明記はありませんが、国会・内閣・皇居など中枢機関が集中しており、事実上の首都とされています。
エージェント
ここからエージェントを実装していきます。LangGraph では、「エージェントをグラフとして記述する」と説明しました。グラフにはノードとそれらをつなぐエッジが必要です。そのため、LangGraph のエージェントにも「ノード」と「エッジ」が必要となります。
エージェントの実行時は、グラフの START ノードから開始し、END ノードに到達したら終了になります。この際にノード間を伝達していくものとして「ステート」があります。ステートとは、AI エージェントが実行される際に、ノード間で情報を共有するための伝言板のようなものです。実態は型を指定した辞書 (TypedDict) になっています。たとえば、ステートにはユーザーと LLM のチャット履歴などを保存します。
つまり、LangGraph でエージェントを実装するには以下の 3 つが必要になります。
- ステート: グラフのノード間を伝達していくもの
- ノード: ステートを受け取り、ステートに何かしら変化を加える関数
- エッジ: ノード間をつなぐもの
まずはステートから実装していきます。
ステート
グラフの中を巡っていくステートには、ユーザーと LLM のやりとりを保存します。このやりとりは messages という変数に格納することにします。LangGraph では typing.Annotated を用いることで、値の更新方法を指定することができます (詳しくはドキュメントをご参照ください)。ここでは LangGraph に用意されている add_messages() を使います。add_messages() は、ユーザー (または LLM など) のメッセージを現在のメッセージに追加してくれる便利な関数です (ドキュメント)。
from typing import Annotated, TypedDict
from langchain_core.messages import BaseMessage
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
messages: Annotated[list[BaseMessage], add_messages]
ノード
続いてノードを作っていきます。ノードとは、ステートの中身を更新する関数でした。ReAct エージェントは「LLM の実行」と「ツールの実行」を繰り返すことでタスクを遂行するエージェントです。そのため、ノードもそれぞれ必要になります。
まずは「LLM の実行」を行うノードとして call_model 関数を定義します。call_model 関数 (ノード) は AgentState クラスのステートを入力として受け取り、現在の messages の情報をもとに LLM で推論を行い、推論結果を返す関数です。call_model 関数 (ノード) によって、state の messages だけを更新したいので、返り値が {“messages”: [response]} としています。あとは、AgentState.messages の add_messages() がこれを受け取り、AgentState.messages に推論結果を追加、保存します。
# LLMを実行するためのノード
def call_model(state: AgentState):
response = model.invoke(state["messages"])
return {"messages": [response]}
一方「ツールの実行」を行うノードは LangGraph で用意されている ToolNode を用います。これを call_tools という名前で定義します。このノードは、ToolCalling によって選ばれたツールのリスト (=上記で見た res.tool_calls) を順に実行していく関数になります。
from langgraph.prebuilt import ToolNode
# ツールを実行するためのノード
call_tools = ToolNode(tools)
エッジとグラフ
グラフを定義していきます。このグラフがまさにエージェントになります。まずはグラフのビルダーとして StateGraph を定義し、ノードを追加します。
from langgraph.graph import StateGraph
# グラフのビルダーを作成
graph_builder = StateGraph(state_schema=AgentState)
# ノードを追加
# 第1引数がノードの名前、第2引数がノードが呼ばれた時に実行する関数
graph_builder.add_node(node="llm", action=call_model)
graph_builder.add_node(node="tools", action=call_tools)
続いてエッジでノード間を繋ぐのですが、終了条件のためのエッジを実装していないので、まずは条件付きエッジを実装します。上述の Tool Calling で、LLM がツールを使わずに回答をする場合は、.tool_calls が空になると説明しました。この場合、LLM が最終的な回答をしているとみなせるため、これを終了条件とします。
from typing import Literal
def should_continue(state: AgentState) -> Literal["continue", "end"]:
if not state["messages"][-1].tool_calls:
return "end" # ツール実行がなければ終了
return "continue"
あとは、ノード同士を結んでいきます。.add_edge() を用います。終了条件のところは条件付きエッジとして .add_conditional_edges() を使います。また、開始ノードと終了ノードはそれぞれ START と END で表します。
from langgraph.graph import START, END
# エッジを追加
# 第1引数が始点のノード、第2引数が終点のノード
graph_builder.add_edge(start_key=START, end_key="llm")
graph_builder.add_conditional_edges(
source="llm",
path=should_continue, # 判定関数
path_map={
"continue": "tools", # "continue"ならtoolsノードに遷移
"end": END # "end"なら終了ノードに遷移
}
)
graph_builder.add_edge(start_key="tools", end_key="llm")
# ReActエージェントのグラフを作成
graph = graph_builder.compile()
作成したエージェントを図 3 でも確認します。
# ノートブック環境の場合に必要
import nest_asyncio
nest_asyncio.apply()
from IPython.display import Image, display
from langchain_core.runnables.graph_mermaid import MermaidDrawMethod
try:
display(Image(graph.get_graph().draw_mermaid_png(draw_method=MermaidDrawMethod.PYPPETEER)))
except Exception as e:
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception as e:
print(e)
実装の冒頭でも書きましたが、__start__ ノードから始まり、llm ノードがツールを使う場合 (continue エッジ) は tools ノードを実行したあと llm ノードに戻り、ツールを使わない場合 (end エッジ) は __end__ ノードで終了するようなグラフになっています。
ReAct エージェントの実行
ではここまで実装した ReAct エージェントを実行してみます。graph.stream() メソッドでエージェントを実行することができます。
inputs = {"messages": [("user", "日本の首相の出身地はどこですか?")]}
for state in graph.stream(inputs, stream_mode="values"):
last_message = state["messages"][-1]
last_message.pretty_print()
出力結果は以下です。ユーザーのプロンプトに対して、LLM が考えながらツールを使うことで回答をしていることが分かります。ちなみに、これは高市早苗議員が総理大臣に就任されてから数時間後に実行したものですが (2025 年 10 月 21 日)、すでに最新の情報を引っ張って正確な回答をしていることが分かります。
================================ Human Message =================================
日本の首相の出身地はどこですか?
================================== Ai Message ==================================
Tool Calls:
get_current_datetime (call_zvgYG7LViONdBKI03AqlqFzQ)
Call ID: call_zvgYG7LViONdBKI03AqlqFzQ
Args:
get_wikipedia_article (call_gNda1CnXQK7k4KlCKBWA4VVW)
Call ID: call_gNda1CnXQK7k4KlCKBWA4VVW
Args:
query: 内閣総理大臣 現職
language: ja
================================= Tool Message =================================
.....(省略).....
================================== Ai Message ==================================
2025年10月現在の日本の首相・高市早苗さんの出身地は奈良県です。
ここまでで、Tool Calling と ReAct エージェントの紹介をいたしました。LangGraph で Tool Calling を用いた ReAct エージェントを実装することで、簡単なエージェントの実装方法を学びました。このエージェントを用いることで様々なタスクを実行することができますが、ここから質の高いエージェント システムを構築するにはまだまだ実験や改良が必要になります。次の章ではエージェントの構築からデプロイメントまで、エージェント システムの構築過程の全体をカバーしたオープンソースとして NeMo Agent Toolkit の使い方をご紹介します。
NeMo Agent Toolkit
前のセクションでは LangChain, LangGraph を用いて ReAct エージェントおよび Wikipedia 検索ツール/現在時刻ツールを実装し、エージェント システムを実行しました。この章では NVIDIA が提供するエージェント開発/運用ツールキットである NeMo Agent Toolkit を使ってエージェント システムを実行する方法について説明します (ドキュメント)。
NeMo Agent Toolkit には汎用的なエージェントやツールがあらかじめ組み込まれており、それらを簡単に呼び出して使うことができます。そこで、今回は NeMo Agent Toolkit に実装されている ReAct agent および current_datetime (現在時刻)、wiki_search (Wikipedia 検索) ツールを呼び出してエージェント システムを実行します。
自作のエージェントおよびツールを NeMo Agent Toolkit に登録して利用する方法についてはまた別のブログで改めて紹介したいと思います。NeMo Agent Toolkit で実装されている ReAct エージェントおよび WikiSearch ツールは GitHub 上で公開されていますので、ご興味がある方は確認してみてください。 (ReAct, WikiSearch)
具体的な実行方法に移る前に、まずはエージェント開発と運用の課題について触れながら、NeMo Agent Toolkit の特徴について説明します。
エージェント開発の課題と NeMo Agent Toolkit の概要
LangChain に代表されるように、生成 AI アプリケーション ロジックを実装するフレームワークが浸透してきたことで、アプリケーション開発のハードルは大きく下がりました。シンプルな構成のエージェントであれば、プログラミングに慣れている人であれば 1 日で構築して動かすことも可能です。
しかし、実際の業務要件を満たすようなエージェントシステムを設計および開発し、実運用して継続的に使われるためには、エージェント ロジックの実装以外にも様々な機能が必要になります。開発フェーズと運用/管理フェーズに分けて説明します。
エージェントの開発フェーズ
- 様々なエージェント構成を迅速に試すための機能 (デバッグ、評価、構成管理)
- フレームワークに依存しない開発体制
実際のビジネス現場で活用されるエージェントを開発するためには、プロジェクト メンバーと連携や分担してトライアル アンド エラーを繰り返しながら開発を続けていくことになります。その際、各メンバーが好きなフレームワーク、好きな書き方で実装をしてしまうと、開発全体として整合性が取れなくなったり、他のプロジェクトへの流用性も下がります。とはいえ、逆に 1 つのフレームワークに強制的に縛り付けることも、フレームワークの隆盛が激しい状況下ではリスクとなります。このような問題はすでに開発現場で顕在化しています。
余談ですが、筆者は 2010 年中盤〜終盤に ML/DL のフレームワークが出てきた時に同じような問題が起きたことを思い出します。scikit-learn や、TensorFlow、PyTorch、Chainer など複数のフレームワークが出てきて機械学習の実装のハードルは下がった一方、フレームワークの互換性の問題が出てきました。また、ML パイプラインの粒度も統一されておらず、ある人は前処理と学習を一緒に書く一方、ある人は学習と評価を繋げて書いたりと、プロジェクト間の再利用性が担保できなくなってきました。そのような問題を解決するために、ML/DL フレームワークをラッピングして機械学習の開発工程全体を管理するようなサービスが出てきたり、MLOps の重要性が認識されるようになってきました。NeMo Agent Toolkit はエージェントの開発における同様の問題を解決するために開発されたフレームワークとも言えます。
エージェントの運用/管理フェーズ
- スループットやレスポンス性能などのパフォーマンスの最適化
- インシデント対応や継続改善のための情報取得 (オブザーバビリティ) 機能
- システムの改善効果や経年劣化を測るための評価機能
運用/管理フェーズには開発フェーズとは違った機能が必要になります。実際の業務要件に即した形で、アプリケーションが安定かつパフォーマンスを発揮した状態で稼働し続けることが必要です。また、1 度導入したシステムがそのまま使われ続ける保証は全くありません。ユーザーの要望は使用しているうちにどんどん高まっていきます。また、ユーザーのクエリや使用データが開発時と変わり、システムが対応できずに結果として劣化することがあり、継続的な改善が必要です。
このように、エージェント開発/運用とは、単にロジックやシステムを実装しておしまいではなく、開発や運用/管理に関わる工程や機能までをケアすることが求められます。しかし、これらの工程や機能を自分達で整備し、仕組み化することは非常に手間がかかります。また、このような取り組み自体は、開発するエージェントの機能自体の差別化には直接繋がらない重労働です。皆さんがこのような悩みから解き放たれ、車輪の再発明を防ぐためのツールが NeMo Agent Toolkit です。
NeMo Agent Toolkit の概要
NeMo Agent Toolkit はエージェント システムの開発/運用におけるプロファイリング、評価などを提供するオープンソースのライブラリです。
システムにおける、エージェントやツール、会話記憶メモリなどの構成を YAML を通じて管理/実行することができます。テレメトリを通じたデータのトレーサビリティ機能や、リソースのプロファイリング機能、評価ジョブ実行機能を備えており、先にあげたようなエージェント システムの実運用のための様々な機能を提供します。
また、使用するエージェント フレームワークに依存せずに使うことができます。逆にいえば、エージェント自体を記述/実装するフレームワークではなく、様々なフレームワークで作られたエージェントの差異を吸収しつつ、統一されたプラットフォーム上でエージェントを開発することを可能にするフレームワークです。
お待たせしました。それでは実際の ReAct エージェントの実行を通じて、NeMo Agent Toolkit の使用方法やメリットについて具体的に見ていきましょう。
NeMo Agent Toolkit を使った ReAct エージェント システムの実行
NeMo Agent Toolkit のインストール
ここからは前章の Jupyter Notebook ではなく、ターミナル上でコマンドを実行していきます。NeMo Agent Toolkit をインストールする最も簡単な手法は pip でインストールすることです。
注記: NeMo Agent Toolkit は旧バージョンでは AI-Q Agent Toolkit という呼称でした。そのため過去のバージョンの記事やドキュメントでは AI-Q という表記は aiq コマンドが使用されているものもあります。
pip install nvidia-nat nvidia-nat-langchain nvidia-nat-phoenix matplotlib
これで、Python 上で NeMo Agent Toolkit のライブラリを呼び出してエージェントの各機能の実装を行うことができます。
また、実際に構築したエージェントシステム自体を実行したり、評価するためには nat というシェル コマンドを実行します (pip install 時に nat コマンドもインストールされます)。
nat コマンドには代表的なものとして下記のような機能があります。
nat run: 定義したエージェントを実行し、単発のクエリを入力して結果を出力するコマンド。開発/検証フェーズでワークフローをローカル実行するときに使うnat eval: 評価用データセットを指定してバッチ的に実行し、評価結果を出力するコマンド。プロファイリングを実行する際にも用いるnat serve: エージェントを API サーバーとして立ち上げるコマンド。提供されている GUI と連携して使うこともできる
YAML ファイルの準備
ReAct + tool (wiki_search, current_datetime) の構成でエージェントを定義して実行してみましょう。
GitHub 上にその例が用意されていますが、LLM モデルとして NVIDIA の開発者用 API エンドポイント (もしくはお手持ちの GPU でセルフホストしたエンドポイント) を使う構成になっているため、ここではより馴染みのある OpenAI の API を利用する形式に書き換えて紹介します。前のセクションと同様に OpenAI の API キーを用意し、環境変数として登録してください。実運用では API キーは .env ファイルなどで安全に管理してください。
# OpenAI API Keyを入力
export OPENAI_API_KEY="sk-proj..."
API キーの準備ができたら、YAML ファイルをみていきます。下記リンクの YAML ファイルを参考に以下のような YAML ファイルを作成し、openai_config.yml という名前で保存します。今回は config ディレクトリ以下に保存しています。
general:
use_uvloop: true
llms:
openai_llm:
_type: openai
model_name: gpt-5
max_tokens: 10000
#_type: nim ### ↑↓オリジナルのファイルとの変更部分
#model_name: meta/llama-3.3-70b-instruct
#temperature: 0.0
#max_tokens: 250
functions:
wikipedia_search:
_type: wiki_search
max_results: 3
current_datetime:
_type: current_datetime
workflow:
_type: tool_calling_agent
tool_names: [wikipedia_search, current_datetime]
llm_name: openai_llm
verbose: true
parse_agent_response_max_retries: 2
この構成はシンプルなエージェントのシステム構成です。まずは設定ファイル内の一番下の workflow のところから見ていきましょう。
ここでシステム全体の構成を定義しています。_type フィールドで tool_calling_agent (これは NeMo Agent Toolkit に登録されている一意なコンポーネントの名前) を使うことを宣言しています。モデルには GPT-5 モデルを使用しています。このモデルは thinking (いわゆるリーズニング) を行うモデルであるため、max_tokens の値を引き上げています。
ちなみに NeMo Agent Toolkit には react_agent というコンポーネントもあります。前章で実装した ReAct エージェントは、LLM の Tool Calling 機能 (function calling と呼ばれたりもします) を使う方式でした。NeMo Agent Toolkit で用意しているエージェントのうち、react_agent よりも tool_calling_agent の実装に近いため、今回はこちらを採用しています。混乱しやすいですが、以下このブログで NeMo Agent Toolkit で ReAct を実行する、と言及している際は tool_calling_agent を使っている、という風に解釈してください。
この ReAct エージェントは連携するツールを指定する必要があるため、wikipedia_search, current_datetime というツール名をリスト形式で指定しています (この名前に関しては後ほど説明します)。また ReAct を行うための LLM の名前として openai_llm を指定しています。
次に上の llms、 functions の項目もみていきます。
llms フィールドでは、エージェント システムの中で用いる LLM を定義しています。ここでは openai_llm という名前をつけた LLM を定義しています。また、OpenAI のモデルを使用するタイプであることを _type フィールドの openai にすることで宣言しています。モデルはここでは gpt-5 を設定しています。
openai タイプは、OpenAI が直接提供しているモデルのみならず、OpenAI API エンドポイントに準拠しているサーバーであればいずれでも指定が可能です。そのため、vLLM などでデプロイしたモデルを利用する場合は、openai タイプを指定することで使用することができます (ドキュメント)。その他にも現在以下のタイプの LLM が利用可能です。
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.3-70b-instruct
openai_llm:
_type: openai
model_name: gpt-4o-mini
aws_bedrock_llm:
_type: aws_bedrock
model_name: meta/llama-3.3-70b-instruct
region_name: us-east-1
nim は NVIDIA の推論マイクロサービスである NIM を用いるLLM。aws_bedrock は Amazon Bedrock のモデルを使用する LLM です。
functions フィールドでは、エージェント システムの中で用いるツールを定義しています。例えば、_type フィールドに組み込みのツールである wiki_search を指定し、それをこの YAML 上で wikipedia_search という名前でインスタンス化し、前述した workflow に渡しています。つまり同じツールを複数のファンクションとしてインスタンス化し、役割を変えて使うこともできます。
エージェントの定義はこれで終了です。組み込み式のエージェントやツールを使うだけであれば、コーディングによる実装をせずに YAML ファイルを設定するだけでエージェントを実行することができます。それでは実際に実行してみましょう。
ターミナルから下記のコマンドを実行してください。(YAML ファイルのパスは実際のパスに設定しなおしてください)
nat run --config_file configs/openai_config.yml --input "2025年に東京で行われた世界陸上 男子100mの金メダリストは誰?そのタイムは? Think and search in English, answer in Japanese"
nat run コマンドで単発のユーザー クエリをエージェントに入力して実行しています。--config_file で YAML ファイルのパスを、--input でユーザーのクエリを入力しています。
質問に加えて “Think in English, answer in Japanese” と指定しているのは、今回利用した組み込みの wiki_search ツールが英語記事の検索のみに対応しているために内部で検索が進むようにするための対処です。エージェント (および裏側で使われている LLM) 自体は日本語でもうまく機能します。結果の最終出力とスクリーンショットを示します。
Workflow Result:
['- 金メダリスト:オブリーク・セビル(ジャマイカ)\n- タイム:9秒77']
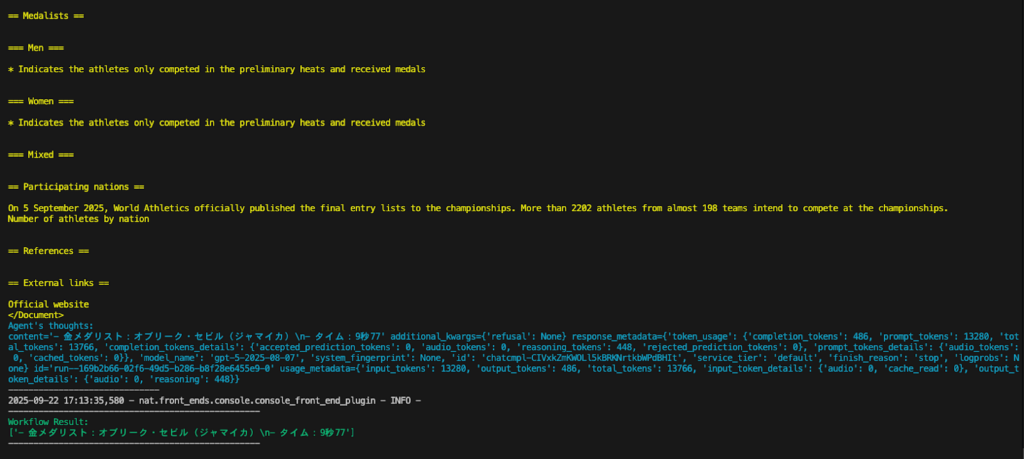
質問内容をうまく汲み取って Wikipedia (黄色いログ) を検索し、金メダリストの名前とタイムを答えることができています。
このように NeMo Agent Toolkit では使いたいエージェントの構成と、ツールおよび LLM を指定すれば YAML のみで簡単にエージェントを組んで実行することができます。
NeMo Agent Toolkit では、エージェント自体もツールであるため、エージェントを入れ子のように配置してマルチエージェント構成を組むことも可能です。興味がある方は example を参照してみてください。
この章では、YAMLファイルを通じてエージェントを簡単に実行する方法について説明しました。次のセクションではエージェント開発に必要となる評価やプロファイリング、オブザーバビリティ機能を YAML ファイルに追加して実行していく方法について説明します。
評価機能の実行
評価用データセットの準備
NeMo Agent Toolkit はエージェントを簡単に定義して実行できるだけでなく、エージェント アプリの本番導入/実運用を支援する様々な機能を持っています。ここでは nat eval コマンドによるエージェントの評価方法を実行しましょう。
まず、評価ジョブを行うためのデータセットを用意します。LLM 単体が知らないような 2025 年最新の情報を含む QA データセットを作成しました。
[
{"id": "1","question": "2025年に東京で開催される世界陸上競技選手権の開催期間はいつですか? Think in English, answer in Japanese","answer": "9月13日〜9月21日"},
{"id": "2","question": "2025年東京マラソン男子の優勝者は誰ですか? Think in English, answer in Japanese","answer": "タデセ・タケレ (Tadese Takele)"},
{"id": "3","question": "大阪・関西万博(Expo 2025)はいつ開幕しましたか? Think in English, answer in Japanese","answer": "2025年4月13日"},
{"id": "4","question": "2025年のアカデミー賞(第97回)で作品賞を受賞した映画は何ですか? Think in English, answer in Japanese","answer": "Anora"},
{"id": "5","question": "2025年の全豪オープン女子シングルス優勝者は誰ですか? Think in English, answer in Japanese","answer": "マディソン・キーズ (Madison Keys)"}
]
データセットは各設問ごとに id, question, answer をキー名として持つような JSON です。このファイルを今回は eval_dataset.json として保存しておきます。
評価ジョブ用の設定
評価ジョブを実行するための YAML ファイルを作成します。
openai_config_with_eval.yml
general:
use_uvloop: true
llms:
agent_llm:
_type: openai
model_name: gpt-5
max_tokens: 10000
eval_llm:
_type: openai
model_name: gpt-5-chat-latest
max_tokens: 10000
functions:
wikipedia_search:
_type: wiki_search
max_results: 3
current_datetime:
_type: current_datetime
workflow:
_type: tool_calling_agent
tool_names: [wikipedia_search, current_datetime]
llm_name: agent_llm
verbose: true
parse_agent_response_max_retries: 2
eval:
general:
output_dir: .tmp/nat/examples/react_agent/ # 出力させたいディレクトリを指定
dataset:
_type: json
file_path: examples/agents/data/eval_dataset.json # 作成したデータセットのパスを指定
evaluators:
rag_accuracy:
_type: ragas
metric: AnswerAccuracy
llm_name: eval_llm
単純なエージェント実行との違いとして、eval フィールドが追加されています。ここに評価用の設定を記述しておくと、nat eval コマンドが実行された時に、この設定に応じた評価ジョブが実行されます。output_dir および file_path のフィールドはご自身の状況に応じて書き換えてください。
今回は評価手法として、RAG システムの評価用ライブラリである Ragas を呼び出しています。NeMo Agent Toolkit では評価器として Ragas Evaluator および Trajectory Evaluator を持っています (Ver 1.2 現在) 。
そのうち、今回用いる Ragas Evaluator で使用できる評価指標は AnswerAccuracy, ContextRelevance, ResponseGroundedness の 3 種類です。今回は QA データセットの評価にマッチした指標である AnswerAccuracy を使用しています。
AnswerAccuracy はエージェント (や LLM) の回答文とあらかじめ用意した正解文 (Ground Truth) を比較して、回答文の正解度合いを LLM に判定させるメトリクスです (いわゆる LLM-as-a-Judge))。そのため、evaluators: の llm_name フィールドで LLM を設定しています。今回はエージェント用の LLM と LLM-as-a-Judge 用の LLM を、それぞれ agent_llm, eval_llm と名前をつけて設定しています。LLM-as-a-judge 用のモデルをテスト用のモデルと同じにすることには議論の余地がありますが、ここではどちらも gpt-5 としています。
評価の実行
評価を実行するには下記のコマンドを実行します。YAML ファイルのパスは適宜書き換えてください
nat eval --config_file configs/openai_config_with_eval.yml
評価ジョブが終了すると、YAML ファイルの output_dir に指定したフォルダーに評価結果が格納されています。rag_accuracy_output.json というファイルが生成されているので、中身を確認します。
{
"average_score": 1.0,
"eval_output_items": [
{
"id": 1,
"score": 1.0,
"reasoning": {
"user_input": "2025年に東京で開催される世界陸上競技選手権の開催期間はいつですか? Think in English, answer in Japanese",
"reference": "9月13日〜9月21日",
"response": "2025年9月13日から9月21日までです。",
"retrieved_contexts": [.. (略)
各設問に対して評価結果が格納されていることがわかります。また平均スコアも算出されています。
プロファイラーの実行
NeMo Agent Toolkit のプロファイリング機能を使うことで、LLM の遅延 (レイテンシ) やスループットなどのパフォーマンスを計測したり、エージェント システムの中のプロセスでボトルネックになっている箇所を特定することができます。シンプルな例として、先ほどの wiki_search エージェントの応答においてどこに時間がかかっているかをプロファイリングしてみましょう。
プロファイリング機能の一覧についてはこちらのドキュメントを参照してください
プロファイリングは評価機能の一環として実行されます。先ほど評価ジョブを設定した YAML の eval フィールドの下の general フィールドに下記のように profiler 以下のフィールドを追加してください。ここでは eval フィールドのみを示しています。
eval:
general:
profiler:
bottleneck_analysis:
enable_nested_stack: true
output_dir: .tmp/nat/examples/react_agent/
dataset:
_type: json
file_path: examples/agents/data/eval_dataset.json
evaluators:
rag_accuracy:
_type: ragas
metric: AnswerAccuracy
llm_name: eval_llm
後で示すようなガントチャートを出力させるために enable_nested_stack は true にしておきます。修正したら再び評価ジョブを実行します。
nat eval --config_file configs/openai_config_with_eval.yml
output_dir フォルダーに、プロファイリング関連の結果が追加されているのがわかります。(nat eval を実行するごとに評価結果が上書きされることに注意してください)
出力結果の中に gantt_chart.png が作成されているので確認します。
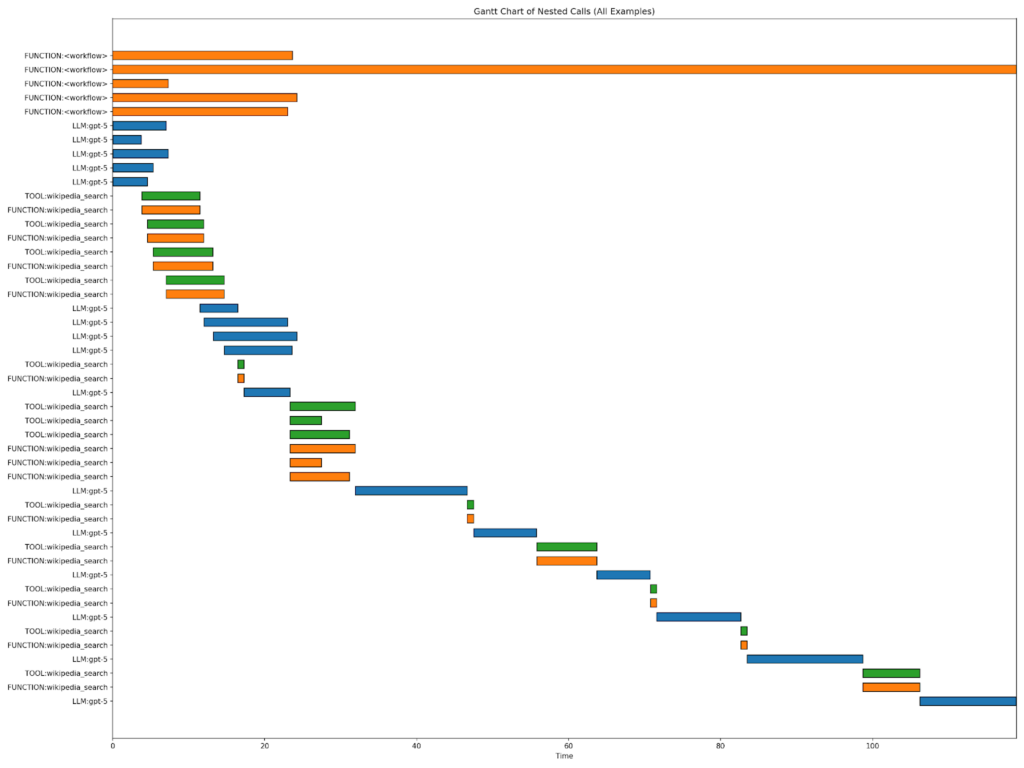
凡例がなく小さくて見にくいですが、上の 5 つのオレンジのバーが、各 5 つの評価データセットの実行時間です。青色のバーが LLM (gpt-5) の実行時間、緑 (もしくはその下のオレンジ) のバーがツールの実行時間です。1 問だけ、実行時間が突出して多いサンプルがあります。
ガント チャートを見ると緑色 (もしくはオレンジ色) で示した wiki_search の実行時間と青色で示した LLM の実行時間は同じくらい、もしくは LLM の方に時間がかかっていることがわかります。このモデルはリーズニングを行うモデルのため、特定の質問 (2 つ目) でリーズニングを繰り返し、実行時間が長くなっていることがわかります。
オブザーバビリティ機能の実行
最後に、オブザーバビリティ機能について触れます。オブザーバビリティとは、システム内部の状態をログ、メトリクス、トレースなど外部から得られる情報で把握できる能力です。
エージェント システムの利用ログやテレメトリ データを保持しておくことは、様々な面で重要です。思考の過程をユーザーに表示するような UI/UX を作ったり、トラブルやエラーが発生した時の原因究明に必要です。また、システムの改善 (例えば LLM モデルのファインチューニング) や開発時のデバッグにも役立ちます。
NeMo Agent Toolkit では W&B Weave や LangSmith など様々なトレーシング ツールに対応しています。ここでは OSS である Phoenix を使って NeMo Agent Toolkit のテレメトリ データを保存します。
前提条件: あらかじめ Phoenix サーバーを立ち上げ、アドレスできる endpoint url を取得しておいてください。
docker run --rm -p 6006:6006 -p 4317:4317 -i -t arizephoenix/phoenix:latest
オブザーバビリティ機能を有効化するためには、YAML ファイルの general フィールドに下記のトレーシング情報を追記します。ここでは追加箇所だけを表示しています。Phoenix のエンドポイント url およびプロジェクト名は適宜変更してください。
general:
use_uvloop: true
telemetry:
tracing:
phoenix:
_type: phoenix
endpoint: http://localhost:6006/v1/traces
project: "observability_test"
YAML を修正したら nat eval コマンドを実行します。
nat eval --config_file configs/openai_config_with_eval.yml
実行が終了したら、Phoenix サーバーにアクセスして、テレメトリ ログを確認します。
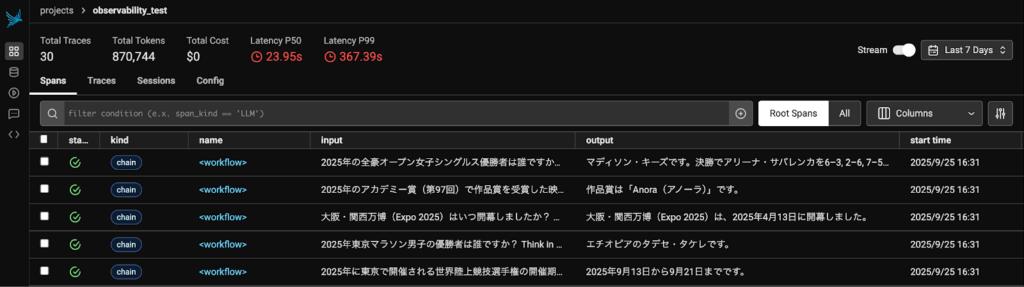
評価データのバッチ実行全体の統計情報や各評価項目 (質問) ごとの応答も保存されていることがわかります。例として、1 番目の応答ログの詳細を確認してみます。
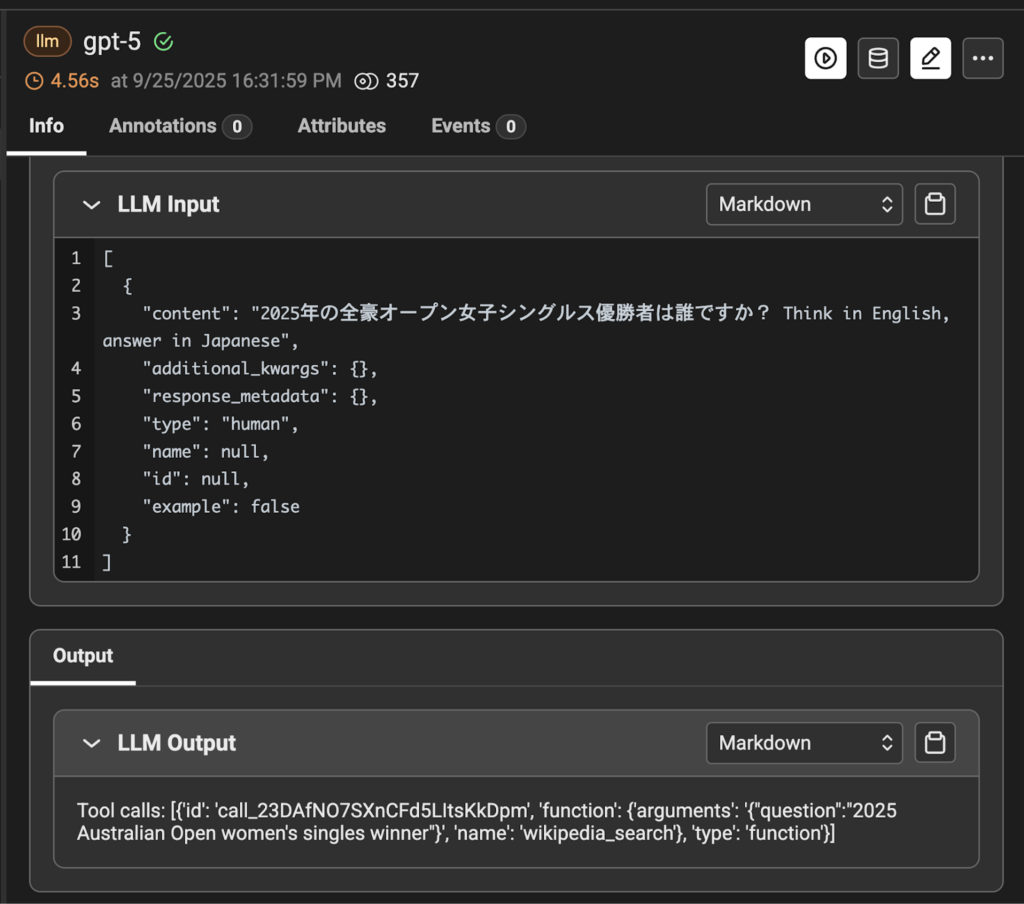
質問を受け取って、wikipedia_search ツールを選択していることが確認できます。
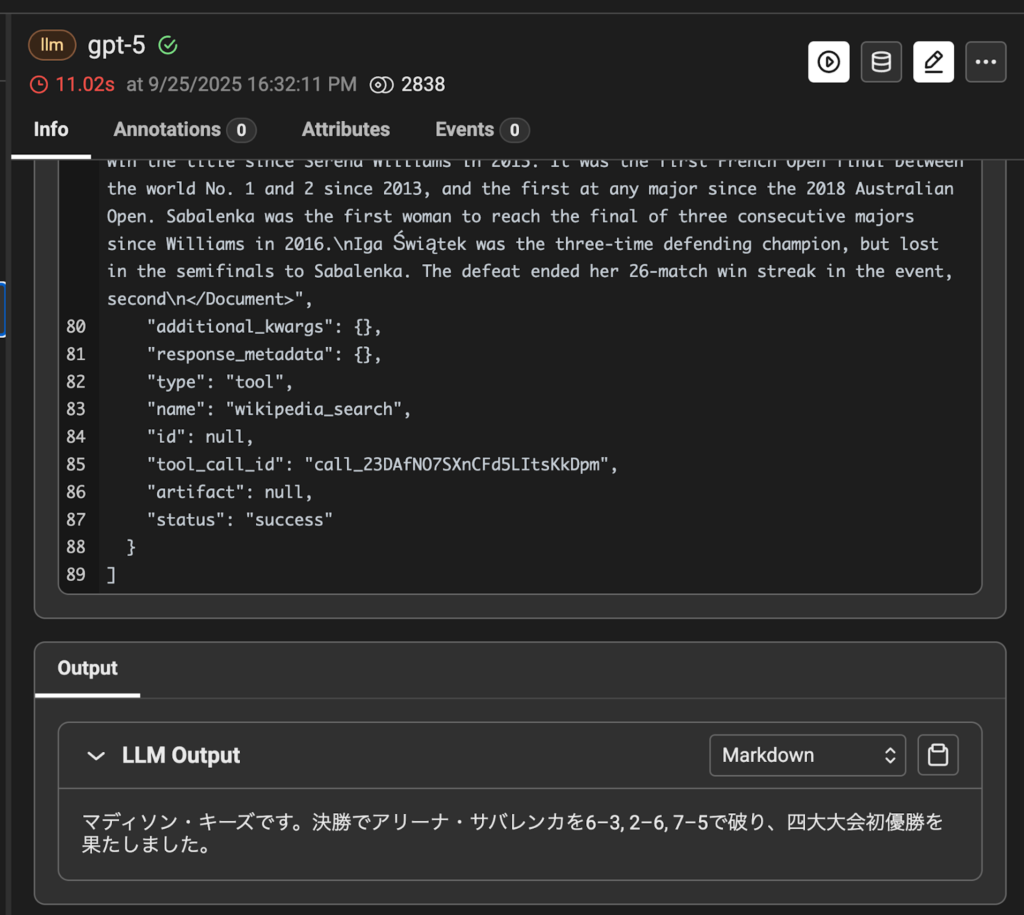
Wikipedia の検索結果を元に正しく回答できていることが確認できました。
反対に、不正解だった設問を詳細にみることで、正解に至らなかった原因がわかります。例えば、ツールを使わずに自分の知識で回答してしまう (その結果間違える)、検索結果に回答が含まれていない、ReAct の形式通りに Action を指定できていない、などがあります。
この問題を改善するためには例えば、1/ プロンプトを改善する、2/ ReAct の構成を変更する、3/ LLM を変更する、4/ 検索ツールを変更する、などが考えられます。Traceability ログを活用することで課題点を洗い出し、開発工程にフィードバックすることができます。
この章では、NeMo Agent Toolkit を活用してシンプルな ReAct + Tool の構成のエージェントを YAML で記述し、実行しました。すでに NeMo Agent Toolkit に組み込まれているエージェントやツールを簡単に呼び出し、実行後の評価やプロファイリングを迅速に実行できることを実感していただけたと思います。
もちろん NeMo Agent Toolkit では皆さんが独自に実装したエージェントやツールを持ち込んで、今回のシンプル ReAct のように YAML で呼び出して実行することができます。ご興味ある方はドキュメントをご参照ください。独自エージェントやツールの実装および登録方法の詳細については次回の記事で取り上げたいと思います。
まとめ
この記事では、LangGraph による ReAct エージェントの実装から始まり、エージェント システムの構築に役立つ NeMo Agent Toolkit の基本的な使い方について解説しました。NeMo Agent Toolkit を使用することで、このような ReAct エージェントの思考プロセスのトレーシングやプロファイリング、さらに評価などを容易に定義し、実装することができます。NeMo Agent Toolkit はオープンソースとして公開しておりますので、ぜひお気軽にお試しください。




