
生成 AI が急成長する中、そのコミュニティは、最新の基盤モデルを速やかに公開する、そのモデルをアプリケーションの開発と本番環境に合理的に統合する、という 2 つの重要な方法でこの成長を支えています。
NVIDIA は、パフォーマンスを強化するよう、基盤モデルを最適化することでこの取り組みを支援しており、企業は NVIDIA NIM を利用することでトークンをより素早く生成し、モデルを実行するコストを削減し、ユーザー体験を向上することができます。
NVIDIA NIM
NVIDIA NIM 推論マイクロサービスは、クラウド、データ センター、ワークステーションなどの場所を問わず、NVIDIA により高速化されたインフラで生成 AI モデルのデプロイを合理化し、加速するように設計されています。
NIM は TensorRT-LLM 推論最適化エンジン、業界標準の API、事前構築されたコンテナーを活用し、需要に応じて拡張可能な低レイテンシ、高スループットの AI 推論を提供します。Llama 3、Mixtral 8x22B、Phi-3、Gemma など、幅広い LLM に加え、発話、画像、動画、ヘルスケアなどでドメイン固有のアプリケーションの最適化をサポートします。
NIM はスループットに優れ、企業は最大 5 倍の速さでトークンを生成できます。生成 AI アプリケーションでは、トークン処理が重要なパフォーマンス指標であり、トークン スループットが増えることはすなわち、企業にとって収益が増えることを意味します。
統合とデプロイのプロセスを簡素化することにより、NIM は、企業が AI モデルの開発から本番環境に速やかに移行できるようにし、効率を高め、運用コストを削減し、事業が変革と成長に集中できるようにします。
そして今、NVIDIA は Hugging Face と共に一歩前進し、開発者がほんの数分でモデルを実行できるようにします。
数回のクリックで Hugging Face に NIM をデプロイ
Hugging Face は AI モデルのための主要なプラットフォームであり、AI モデルのアクセシビリティを強化しており、AI 開発者にとって頼りになる存在となっています。
お好きなクラウド サービス プロバイダーで、まずは Llama 3 8B と Llama 3 70B から、NVIDIA NIM のシームレスなデプロイのパワーを活用してください。すべて Hugging Face から直接アクセスできます。
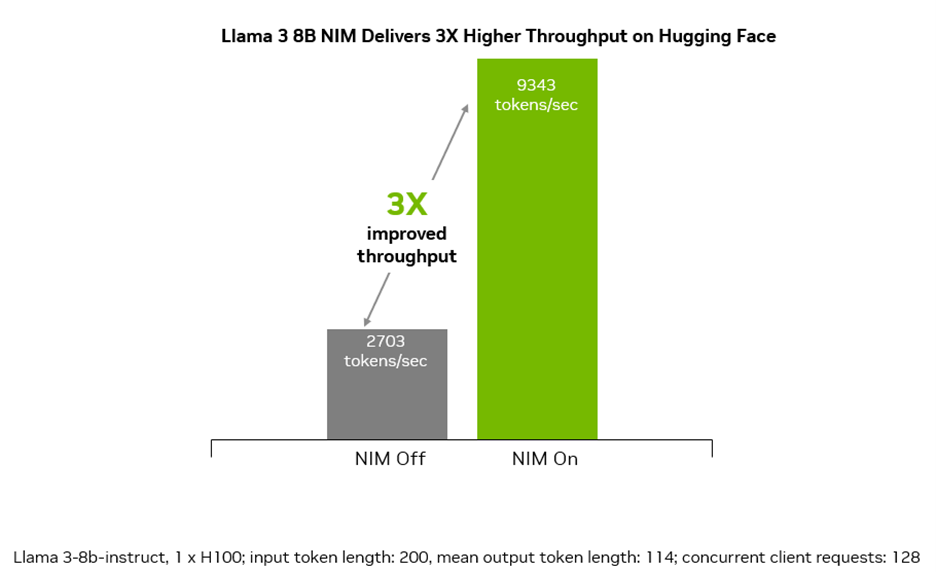
NIM はスループットに優れ、複数の要求を同時に処理することで、ほぼ 100% の利用率を達成するので、企業は 3 倍の速さでテキストを生成できます。生成 AI アプリケーションでは、トークン処理が重要なパフォーマンス指標であり、トークン スループットが増えることはすなわち、企業にとって収益が増えることを意味します。
Hugging Face の専用 NIM エンドポイントは、お好きなクラウドでインスタンスを起動し、NVIDIA で最適化されたモデルを自動的にフェッチし、デプロイし、わずか数回のクリックで推論を開始します。すべて数分程度しかかかりません。
詳しく見ていきましょう。
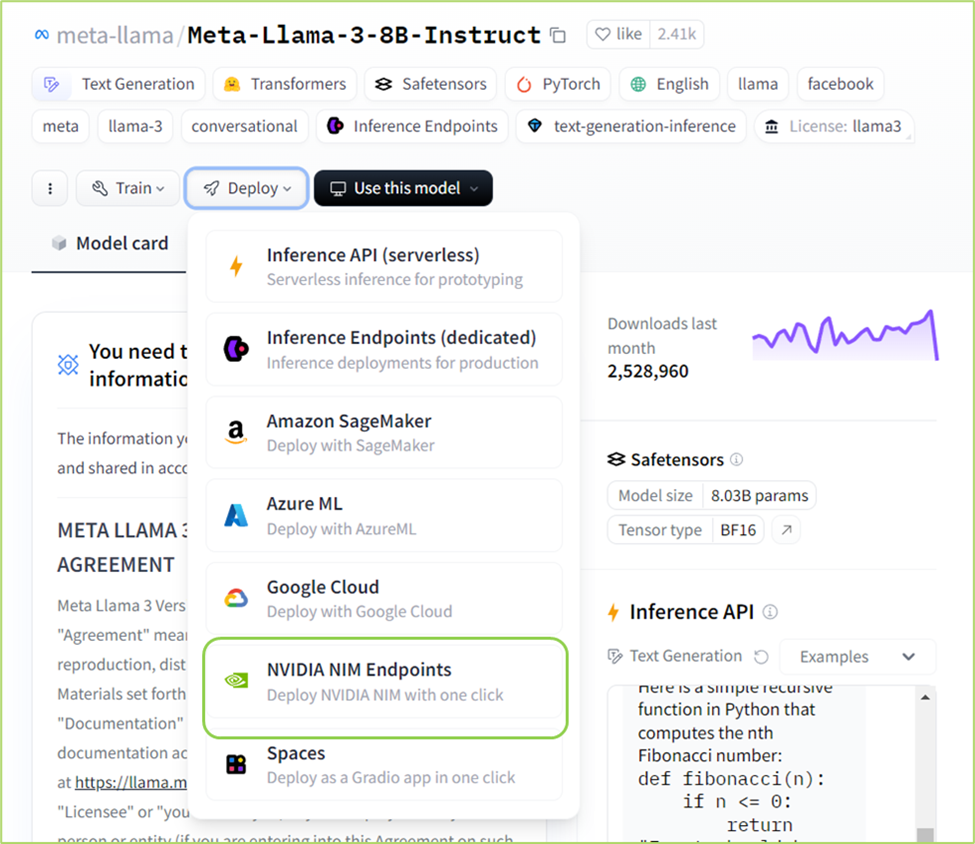
Step 1: Hugging Face で Llama 3 8B または 70B instruct モデル ページに移動し、[Deploy (デプロイ)] ドロップダウンをクリックし、メニューから [NVIDIA NIM Endpoints (NVIDIA NIM エンドポイント)] を選択します。
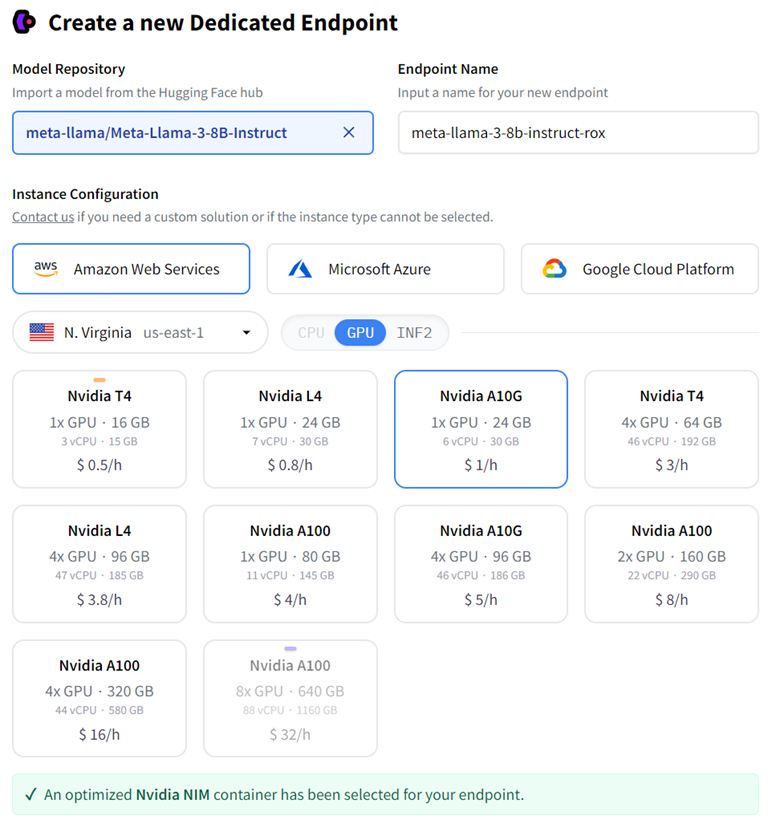
Step 2: NVIDIA NIM で「Create a new Dedicated Endpoint (専用エンドポイントを新規作成する)」の新しいページが表示されます。モデルを実行する任意の CSP インスタンス タイプを選択します。 AWS の A10G/A100 と GCP インスタンスの A100/H100 では、NVIDIA の最適化されたモデル エンジンを活用し、最良のパフォーマンスを実現します。
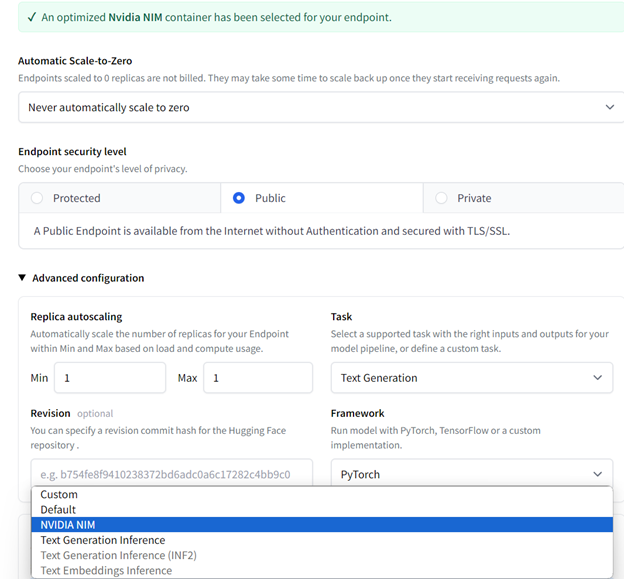
Step 3: [Advanced configuration (詳細設定)] セクションで、[Container Type (コンテナーの種類)] ドロップダウンから [NVIDIA NIM] を選択し、[Create Endpoint (エンドポイントの作成)] をクリックします。
Step 4: ものの数分で推論エンドポイントが稼働します。

今すぐ始める
Hugging Face から Llama 3 8B と 70B NIM をデプロイすると、生成 AI ソリューションを市場に投入するまでの時間が短縮され、高いトークン スループットで収益が大幅に増加し、推論コストを削減することができます。
40 を超えるマルチモーダル NIM と共にアプリケーションを今すぐ体験し、プロトタイプを作成するには、ai.nvidia.com にアクセスしてください。
無料の NVIDIA クラウド クレジットを利用することで、NVIDIA がホストする API エンドポイントを数行のコードで統合し、プロトタイプ アプリケーションを構築し、テストできます。
関連情報
- GTC セッション: Building Accelerated AI With Hugging Face and NVIDIA (Hugging Face と NVIDIA による高速 AI の構築)
- GTC セッション: Building an End-to-End Solution for Enterprise-Ready Generative AI (企業に対応した生成 AI のエンドツーエンド リューションの構築)
- GTC セッション: Navigating Generative AI Challenges and Harnessing Potential: Insights from NVIDIA’s Enterprise Deployments (生成 AI の課題をナビゲートし、可能性を活用する: NVIDIA のエンタープライズ展開からの洞察)
- NGC コンテナー: GenAI SD NIM
- SDK: NeMo
- ウェビナー: Fast-Track to Generative AI With NVIDIA