エージェント型 AI システムは、リトリーバー、プランナー、ツール実行者、検証者といった複数の協調エージェントが、大規模なコンテキストと長い時間にわたるタスクを横断して動作する形へと進化しています。これらのシステムには、高速なスループット、優れた推論精度、そして大規模入力に対しても一貫性を維持できる持続的なコヒーレンスを提供するモデルが求められています。さらに、開発者が運用環境を問わずモデルをカスタマイズ、拡張、デプロイできるようにする高いオープン性も必要とされます。
NVIDIA Nemotron 3 ファミリのオープンモデル (Nano、Super、Ultra)は、データセットや各種手法とともに、この新時代に向けた特化型エージェント AI を構築するために設計されました。
本ファミリでは、ハイブリッド型 Mamba-Transformer による Mixture-of-Experts (MoE) アーキテクチャ、インタラクティブ環境における強化学習 (RL: Reinforcement Learning)、100 万 トークンのネイティブなコンテキスト ウィンドウを導入しています。これにより、マルチエージェント アプリケーションにおける高スループットかつ長期推論を可能にします。
Nemotron 3 の新機能
Nemotron 3 は、エージェント型システムの要件に直接応える複数の技術的イノベーションを導入しています。
- テスト時の効率性と長距離リーズニング性能に優れたハイブリッドな Mamba-Transformer MoE バックボーン。
- 実世界のエージェント型タスクを想定して設計されたマルチ環境強化学習
- 最大 100 万 トークンのコンテキスト長に対応し、ディープ マルチドキュメント推論と長時間実行エージェント メモリをサポートします。
- データ、モデル重み、トレーニング レシピを含む、オープンで透明性の高いトレーニング パイプライン。
- Nemotron 3 Nano はすでに利用可能で、すぐに活用できるクックブック (cookbook) を提供ています。Super と Ultra が続きます。
簡単なプロンプトの例
Nemotron 3 モデル向けの主要テクノロジ
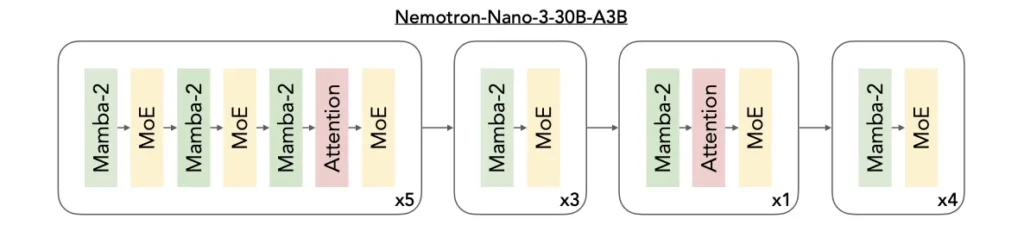
ハイブリッド Mamba-Transformer MoE
Nemotron 3 は、3 つのアーキテクチャを単一のバックボーンに統合します。
- 効率的なシーケンス モデリング向け Mamba レイヤー
- 精度の高い推論向け Transformer レイヤー
- MoE ルーティングにより、スケーラブルなコンピューティング効率を実現します。
Mamba は、最小限のメモリ オーバーヘッドで長距離依存関係を追跡することに優れており、数十万トークンを処理する場合でも、持続的な性能をします。 これに対し、Transformer レイヤーは、コード操作、数理推論、複雑な計画などのタスクに必要な構造的および論理的な関係性を捉える詳細なアテンション メカニズムでこれを補完します。
MoE コンポーネントは、密な計算に伴うコストを増大させることなく、効果的なパラメーター数を拡張します。 各トークンに対して一部のエキスパートのみに動的にアクティブになるため、遅延を削減し、スループットを向上させることができます。 このアーキテクチャは、多くの軽量エージェントが同時に動作する必要があるエージェント クラスターに特に適しています。各エージェントは、計画の生成、コンテキストの精査、ツール ベースのワークフローの実行といった処理を効率的に行うことを可能にします。
マルチ環境強化学習 (RL: Reinforcement Learning) トレーニング
Nemotron 3 を実際のエージェントの挙動に整合させるため、本モデルは オープンソースの強化学習環境構築およびスケーリング ライブラリである NeMo Gym 上の多くの環境で、強化学習を用いたポストトレーニングが行われます。これらの環境では、正しいツール コールの生成、実行可能なコードの記述、検証可能な条件を満たすマルチパート プランの生成など、単一ターンの応答を超えた一連のアクションを実行するモデルの能力を評価します。
この軌跡ベースの強化学習により、Nemotron 3 はマルチステップのワークフローにおいても安定した挙動を示し、推論のドリフトを低減するとともに、エージェント型パイプラインで一般的に求められる構造化されたオペレーションを適切に処理できるモデルとなっています。NeMo Gym はオープンであるため、開発者は、ドメイン固有のタスク向けけのモデルをカスタマイズする際に、独自の環境を再利用、拡張、さらには作成することもできます。
これらの環境及び RL データセットは、NeMo Gym と併せて公開予定であり、自身のモデルをトレーニングする目的でこれらの環境を利用したい開発者も活用できるようになります。
100 万トークンのコンテキスト長
Nemotron 3 は最大 100 万 トークンのコンテキスト長に対応しており、大規模なコードベース、長文ドキュメント、長時間の会話、検索結果を集約したコンテンツに対して持続的な推論を可能にします。断片的なチャンク分割 (chunking) に依存する従来の手法とは異なり、エージェント セット全体、履歴バッファ、マルチステージの計画を単一のコンテキスト ウィンドウ内に保持できます。
この長文コンテキストのウィンドウは、極めて大きなシーケンスを効率的に処理できる Nemotron 3 のハイブリッド型 Mamba-Transformer アーキテクチャによって実現されています。さらに、MoE によるルーティングにより、トークンあたりの計算コストが抑えられ、推論時においてもこうした大規模シーケンスの実用性が確保されています。
エンタープライズ規模の検索拡張生成、コンプライアンス分析、数時間に及ぶエージェント セッション、モノリシック リポジトリの理解といったユースケースにおいて、などのために、100 万トークンのウィンドウは、事実性の担保を大幅に向上させ、コンテキストの断片化を低減します。
Nemotron 3 Super と Ultra に搭載される主要技術
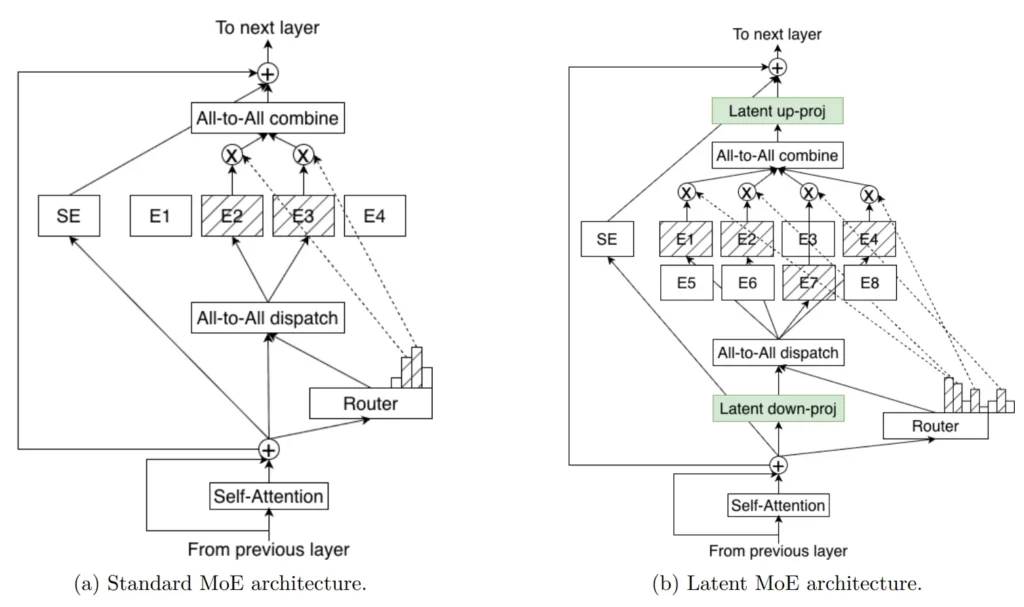
Latent MoE
Nemotron 3 Super と Ultra は、Latent MoE が導入されています。これは、エキスパートがトークン空間へ投影される前の共有された潜在表現 (latent representation) 上で動作するアーキテクチャです。このアプローチにより、モデルは同じ推論コストで 4 倍のエキスパートを呼び出すことができます。これにより、微細な意味構造、ドメイン固有の抽象化、マルチホップ推論パターンに対するより優れた専門化が可能になります。
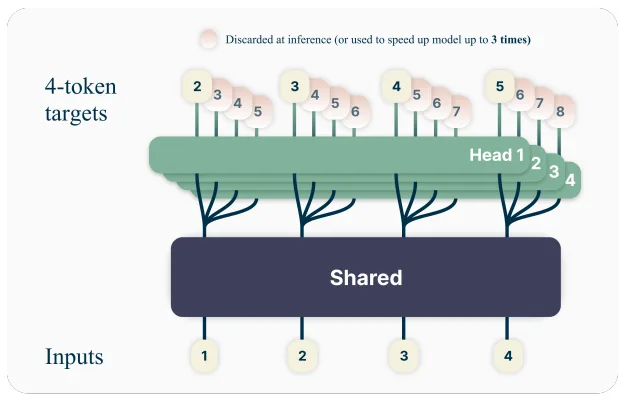
マルチトークン予測 (MTP: Multi-token Prediction)
MTP により、モデルは単一のフォワード パスで複数の将来のトークンを予測でき、長い推論シーケンスや構造化された出力におけるスループットを大幅に向上させます。計画生成、軌跡生成、拡張された
思考連鎖、コード生成といったユースケースにおいて、MTP は遅延を削減し、エージェントの応答性を向上させます。
NVFP4 トレーニング
Super と Ultra は、NVIDIA の 4 ビット浮動小数点形式である NVFP4 で事前学習され、トレーニングと推論にクラス最高のコスト精度を提供します。 Nemotron 3 向けに設計された NVFP4 レシピは、25T トークンの事前学習データセットで、正確かつ安定した事前学習を確保します。事前学習中の浮動小数点の乗算積算演算の大部分は、NVFP4 で行われます。
オープン モデルへの継続的な取り組み
Nemotron 3 は、透明性と開発者のエンパワーメントに対する NVIDIA の取り組みを強化します。 モデルの重みは、NVIDIA Open Model License の下で公開されています。NVIDIA の合成事前学習コーパスは、約 10 兆トークンに相当し、検査や再利用が可能です。 また、開発者は、Nemotron GitHub リポジトリから詳細なトレーニングとポストトレーニングのレシピにアクセスできるため、完全な再現性とカスタマイズが可能になります。
Nemotron 3 Nano は、ハイスループットで長文コンテキストを扱えるエージェント型システムの基盤を形成し、現在入手可能です。2026 年上半期に登場する予定の Super と Ultra は、より深い推論と効率的なアーキテクチャの改良により、この基盤を拡張します。
Nemotron 3 Nano: 現在利用可能
このシリーズの最初のモデル、Nemotron 3 Nano が本日利用可能です。総パラメーター 300 億、アクティブ パラメーター数 30 億のこのモデルは、DGX Spark、H100、B200 GPU 向けに特別に設計されたものです。Nemotron 3 ファミリで最も効率的なモデルで構築できます。
Nemotron 3 Nano の技術的な詳細については、Hugging Face のブログ記事を参照するか、こちらから入手可能な技術レポートをご覧ください。
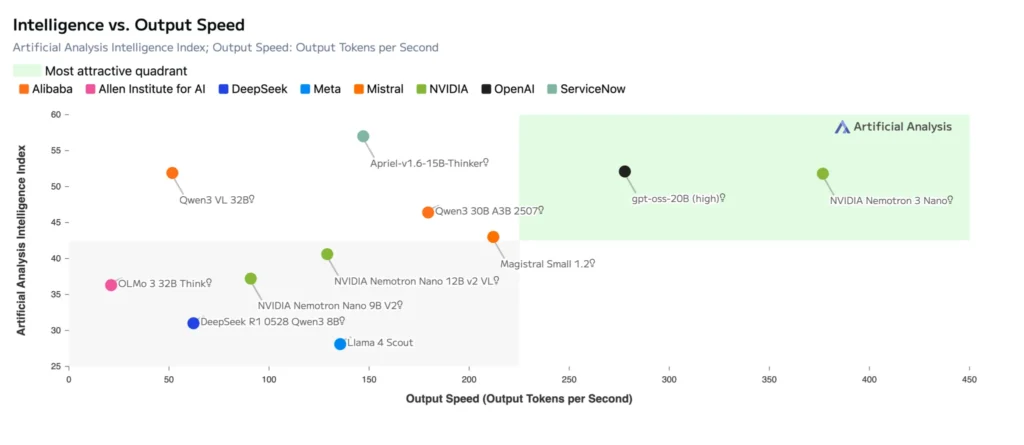
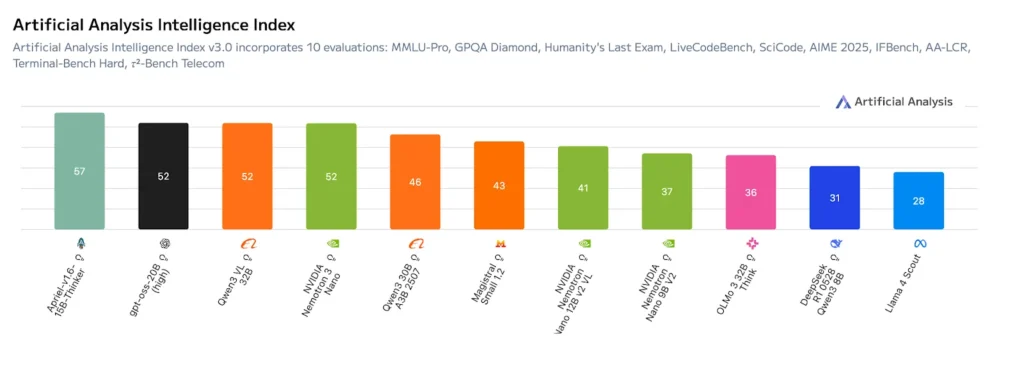
このモデルは、最高水準のスループット効率性を実現し、Artificial Analysis Intelligence Index で最高スコアを達成するとともに、NVIDIA Nemotron Nano V2 が達成した Artificial Analysis Openness Index スコアを維持します。 これは、マルチエージェント タスクに対する有効性を示しながら、透明性とカスタマイズ性を維持します。
開発者は、複数のデプロイと開発のワークフローで、Nemotron 3 Nano を今すぐ使用し始めることができます。
NVIDIA クックブックでモデルを起動
いくつかの主要な推論エンジン向けの、すぐに利用できるクックブックを提供しています。
- vLLM クックブック: 高スループットの連続バッチ処理とストリーミングを備えた Nemotron 3 Nano をデプロイします。
- SGLang クックブック: マルチエージェントのツール呼び出しワークロード向けに最適化された高速かつ軽量な推論を実行します。
- TRT-LLM クックブック: 低遅延の本番環境向けに、完全に最適化された TensorRT-LLM エンジンをデプロイします。
各クックブックには、構成テンプレート、パフォーマンスのヒント、リファレンス スクリプトが含まれているため、Nemotron 3 Nano を数分で実行できるようになります。
さらに、GeForce RTX デスクトップやノート PC から、RTX Pro ワークステーション、DGX Spark、あらゆる NVIDIA GPU 上で、Llama.cpp、LM Studio、Unsloth などの主要なフレームワークとツールを使用して、Nemotron の使い方を今すぐ始めましょう。
Nemotron オープン トレーニング データセットで構築
また、NVIDIA は、モデル開発全体で使用されるオープン データセットをリリースし、高性能で信頼性の高いモデルの構築方法について、前例のない透明性を提供します。
新しいデータセットのハイライトは、以下を含みます。
- Nemotron-pretraining: コード、計算、推論をより豊富にカバーする 3 兆のトークンからなる新しいデータセット。合成拡張とアノテーション パイプラインを通じて強化されました。
- Nemotron-post-training 3.0: 教師ありファインチューニング (SFT: Supervised Fine-tuning) と強化学習 (RL: Reinforcement Learning) 向け 13 ミリオンサンプルからなるコーパスで、Nemotron 3 Nano のアライメントと推論を強化します。
- Nemotron-RL データセット: ツールの使用、計画、マルチステップ 推論向けの RL データセットと環境のキュレーションされたコレクションです。
- Nemotron エージェント型セーフティ データセット: 約 1 万 1,000 件の AI エージェント ワークフロー トレースのコレクションで、エージェント システムに発生する新たな安全性とセキュリティ リスクを評価し、軽減するために役立つように設計されています。
NVIDIA NeMo Gym、RL、Data Designer、Evaluator といったオープン ライブラリと組み合わせることで、これらのオープン データセットを活用して、開発者は独自の Nemotron モデルをトレーニング、強化、評価することができます。
Nemotron GitHub を詳しく見る: 事前学習と RL レシピ
NVIDIA は、以下を含むオープン Nemotron GitHub リポジトリを維持しています。
- Nemotron 3 Nano のトレーニング方法を示す事前学習レシピ (すでに利用可能)
- マルチ環境最適化のための RL アライメント レシピ
- データ処理パイプライン、トークナイザーの構成、長文コンテキストの設定
- 今後のアップデートには、追加のポストトレーニングとファインチューニングのレシピが含まれる予定です。
独自の Nemotron のトレーニング、Nano の拡張、分野に特化したバリアントの生成などを行う場合には、GitHub リポジトリがドキュメント、構成、ツールを提供し、主要な手順をエンドツーエンドで再現できます。
このオープン性により、一連の流れを完結させます。モデルの実行、デプロイ、モデルの構築方法の検査、さらには独自のトレーニングさえもできます。すべて NVIDIA のオープン リソースを使用して行えます。
Nemotron 3 Nano は、現在入手可能です。 NVIDIA オープン モデル、オープン ツール、オープン データ、オープン トレーニング インフラストラクチャを使用して、長文コンテキストかつ高スループットのエージェント システムの構築を今すぐ始めましょう。
Nemotron Model Reasoning Challenge にご参加ください
オープン リサーチを加速させることは Nemotron チームの中核的な優先事項です。 そのことを念頭に置いて、Nemotron のオープン モデルとデータセットを使用して、Nemotron の推論パフォーマンスを向上させることに焦点を当てた新しいコミュニティ コンテストを発表できることを嬉しく思います。
こちらから登録すると、詳細が公開され次第、いち早くお知らせします。
NVIDIA ニュースを購読し、LinkedIn、X、Discord、YouTube で NVIDIA AI をフォローすることで、NVIDIA Nemotron の最新情報を入手できます。
- Nemotron 開発者ページをご覧ください。最もオープンで、コンピューティングごとに最もスマートな推論モデルを始めるために必要なすべての要素をご覧ください。
- build.nvidia.com の Hugging Face、NIM マイクロサービス、Blueprints で、新しいオープン Nemotron モデルとデータセットをご覧ください。
- アイデアを共有し、機能に投票して、Nemotron の未来づくりにご参加ください。
- 今後開催予定の Nemotron ライブ配信に参加し、Nemotron 開発者フォーラムや Discord の Nemotron チャンネルを通じて NVIDIA 開発者コミュニティとつながりましょう。
- 動画のチュートリアルとライブ配信をご覧いただき、NVIDIA Nemotron を最大限に活用してください。
翻訳に関する免責事項
この記事は、「Inside NVIDIA Nemotron 3: Techniques, Tools, and Data That Make It Efficient and Accurate」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。



