
NVIDIA BlueField DPU (データ プロセシング ユニット) は、ネットワーク機能の高速化に利用できます。このネットワークの負荷軽減は、DPDK と NVIDIA DOCA ソフトウェア フレームワークを利用することで可能になります。
このシリーズでは、DPDK と NVIDIA DOCA SDK ライブラリを使用することでアプリを構築し、2 とおりの方法で負荷を軽減しました。各手順を個別のコード パッチとして記録し、各シリーズで完全な手順を提供しました。BlueField DPU のプログラミングに必要なものと、個々のユースケースに最適な選択肢がわかります。パート 2 については、「NVIDIA BlueField DPU と NVIDIA DOCA によるアプリケーション開発」をご覧ください。
ユース ケース
まず、DPU にアプリケーションを展開するための、シンプルでありながら有意義なユース ケースが必要でした。レイヤー 3 とレイヤー 4 のパケット属性に基づいて異なるゲートウェイにトラフィックを誘導するため、ポリシーベースのルーティング (PBR) を選択しました。X86 ホストによって選択されるゲートウェイをオーバーライドします (補完します)。実環境では、さまざまな理由によってこのような経路指定が行われます。たとえば、次のような例があります。
- 追加の監査のために、一部のホスト トラフィックを外部ファイアウォールに送信する
- エニーキャスト サーバーに高性能な手法で負荷を分散する
- QoS を適用する
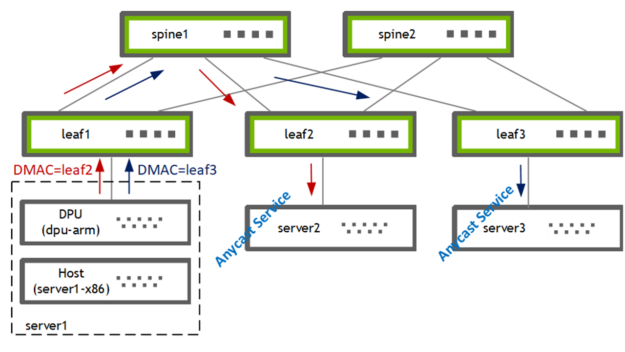
DPU (bf2-arm) で PBR を使用し、ホスト (server1-x86) から 2 つのゲートウェイ [leaf2、leaf3] の 1 つにトラフィックを誘導しました。リーフ スイッチはその後、ローカルに接続されているエニーキャスト サービス プロバイダー [server2、server3] にトラフィックを転送します。
アプリケーションのビルド
最初の質問: まったく新しいアプリを開発するか、既存のアプリの負荷を軽減するか。
お気に入りのオープンソース ルーティング スタック FRRouting (FRR) の PBR 機能の負荷を軽減することにしました。それにより、既存のコードベースが延長され、既存のサンプル アプリとの良い対比ができます。FRR には複数のデータプレーン プラグインのインフラストラクチャがあり、DPDK と DOCA を新しい FRR プラグインとして簡単に追加できます。
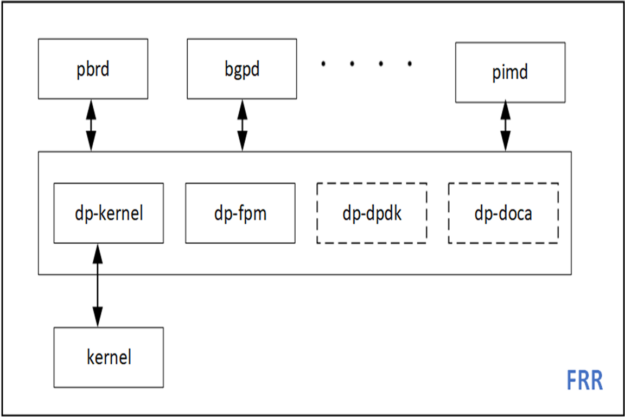
DPU アプリケーションの試作
このセクションでは、DPU ハードウェア アクセラレーションを使用してアプリを開発するために必要な準備作業について説明します。
DPU ハードウェア
BlueField-2 DPU を X86 サーバーでホストしています。この DPU には 2 つの 25G アップリンクと 8G RAM 搭載の Arm CPU があります。ハードウェア取り付けの詳細情報、DOCA SDK ドキュメントを参照してください。あるいは、DPU PocKit を利用してセットアップを起動できます。
BlueField 起動ファイル (BFB) をインストールしました。このファイルは DPU の Ubuntu OS イメージを提供し、また、DOCA-1.2 と DPDK-20.11.3 のライブラリを付属しています。
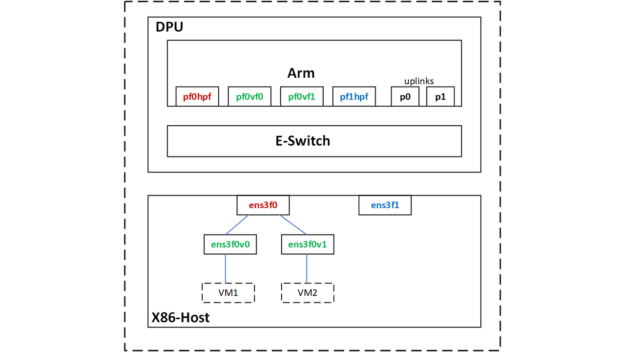
SR-IOV を利用し、2 つの VM のためにホスト上で 2 つの仮想関数 (VF) インターフェイスを作成しました。
root@server1-x86:~# echo 2 > /sys/class/net/ens3f0/device/sriov_numvfsホストの物理機能と仮想機能が DPU-Arm CPU 上の次の netdev リプレゼンターにマッピングされます。
| Netdev タイプ | ホスト netdev | DPU netdev |
| PF | ens3f0 [vf0, vf1] | pf0hpf |
| VF | ens3f0v0 | pf0vf0 |
| VF | ens3f0v1 | pf0vf1 |
DPDK testpmd アプリを利用した試作
まず、DPDK の testpmd を利用してユース ケースを試作しました。この testpmd は DPU の /opt/mellanox/ ディレクトリにあります。
testpmd など、DPDK アプリケーションの場合、hugepages をセットアップする必要があります。
root@dpu-arm:~# echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages必要に応じて、DPU 再起動後も維持されるように設定を永続化します。
root@dpu-arm:~# echo "vm.nr_hugepages = 1024" > /etc/sysctl.d/99-hugepages.conftestpmd を起動します。
root@dpu-arm:~# /opt/mellanox/dpdk/bin/dpdk-testpmd -- --total-num-mbufs=100000 --flow-isolate-all -itestpmd はメモリを大量に使用します。既定では正味で 3.5G が割り当てられます。CPU のデータ トラフィックを処理する必要がなかったので、total-mem 値 200M を割り当てました。内訳は total-mem = total-num-mbufs * mbuf-size (既定の mbuf-size は 2048 バイト) です。また、flow-isolation を使用しました。PBR ネクストホップ解決のために ARP パケットを DPU 上のカーネル ネットワーキング スタックに送信する必要があったためです。-i オプションを指定すると、初期化の完了後、testpmd インタラクティブ シェルが表示されます。
testpmd によって行われる rte_eal 初期化の一環として、mlx5_pci デバイスが調べられ、DPDK ポートにデータが入力されます。
testpmd> show port summary all
Number of available ports: 6
Port MAC Address Name Driver Status Link
0 04:3F:72:BF:AE:38 0000:03:00.0 mlx5_pci up 25 Gbps
1 4A:6B:00:53:79:E5 0000:03:00.0_representor_vf4294967295 mlx5_pci up 25 Gbps
2 62:A1:93:8D:68:C4 0000:03:00.0_representor_vf0 mlx5_pci up 25 Gbps
3 0A:8E:97:F5:C0:41 0000:03:00.0_representor_vf1 mlx5_pci up 25 Gbps
4 04:3F:72:BF:AE:39 0000:03:00.1 mlx5_pci up 25 Gbps
5 D2:0B:15:45:94:E8 0000:03:00.1_representor_vf4294967295 mlx5_pci up 25 Gbps
testpmd>ここの DPDK ポートは、PF/VF リプレゼンターと 2 つのアップリンクに対応します。
| DPDK ポート | DPU netdev | コメント |
| 0 | p0 | leaf1 に接続された 25G アップリンク |
| 1 | pf0hpf | |
| 2 | pf0vf0 | VM1 |
| 3 | pf0vf1 | VM2 |
| 4 | p1 | |
| 5 | pf1hpf |
フロー作成
次に、ingress ポート、送信元 IP、送信先 IP、プロトコル、ポートを定義し rte_flow として PBR ルールを設定します。それに加え、一致するパケットに実行するアクションを定義しました。送信元と送信先の MAC が書き換えられ、TTL がデクリメントされます。egress ポートが物理アップリンク p0 に設定されます。
In-port=pf0vf0, match [SIP=172.20.0.8, DIP=172.30.0.8, IP-proto=UDP, UDP-dport=53], actions [dec-ttl, set-src-mac=p0-mac, set-dst-mac=leaf2-MAC, out-port=p0]この PBR ルールでは、UDP と DNS のトラフィックを VM1 から受信し、特定の GW (leaf2、server2) に送信します。また、問題を簡単に解決するため、フローにカウンター処理を追加しました。
testpmd> flow create 2 ingress transfer pattern eth / ipv4 src is 172.20.0.8 dst is 172.30.0.8 proto is 17 / udp dst is 53 / end actions dec_ttl / set_mac_src mac_addr 00:00:00:00:00:11 / set_mac_dst mac_addr 00:00:5e:00:01:fa / port_id id 0 / count / end
Flow rule #0 created
testpmd>DPU は DPU-switch または DPU-NIC モードで作動します。このユースケースでは、いくつかのパケット変更後、X86-host から 25G-uplink にトラフィックをリダイレクトする必要がありました。そのため、私はコンセプト上、スイッチまたは FDB モードでそれを使用しました。このモードのセットアップには、適切な rte_flow 属性、この場合は transfer を使用すること以外に追加の構成はありません。
フロー検証
testpmd フロー クエリ <port-id, flow-id> コマンドで作成したフローに一致したか確認するため、VM1 からトラフィックをいくつか送信しました。
testpmd> flow query 2 0 count
COUNT:
hits_set: 1
bytes_set: 1
hits: 22
bytes: 2684
testpmd>フローは一致し、トラフィックが leaf2/server2 で確認されますが、パケット ヘッダーが変更されています。誘導されているトラフィックは DNS です。そのため、フローをテストするため、DNS 要求を VM1 から送信しました。トラフィック レートやその他のパケット フィールドをいくらか制御するために、テスト トラフィック生成のための mz を使用しました。
ip netns exec vm1 mz ens3f0v0 -a 00:de:ad:be:ef:01 -b 00:de:ad:be:ef:02 -A 172.20.0.8 -B 172.30.0.8 -t udp "sp=25018, dp=53" -p 80 -c 0 -d 1s追加のサニティ チェックによって、このフローの負荷が実際に軽減されているか確認します。それは 2 とおりの方法で行います。
- Arm CPU で
tcpdumpを使用し、このパケット フローがカーネルで受信されないことを確認します。 - ハードウェア eSwitch がフローでプログラミングされているか確認します。
mlx_steering_dump では、ハードウェアでプログラミングされたフローを確認できます。git を使用し、ツールをダウンロードし、インストールします。
root@dpu-arm:~# git clone https://github.com/Mellanox/mlx_steering_dumpMlx_steering_dump_parser.py スクリプトを利用し、ハードウェアでプログラミングされたフローの有効性を確認します。
root@dpu-arm:~# ./mlx_steering_dump/mlx_steering_dump_parser.py -p `pidof dpdk-testpmd` -f /tmp/dpdkDump
domain 0xbeb3302, table 0xaaab23e69c00, matcher 0xaaab23f013d0, rule 0xaaab23f02650
match: outer_l3_type: 0x1, outer_ip_dst_addr: 172.30.0.8, outer_l4_type: 0x2, metadata_reg_c_0: 0x00030000, outer_l4_dport: 0x0035, outer_ip_src_addr: 172.20.0.8
action: MODIFY_HDR, rewrite index 0x0 & VPORT, num 0xffff & CTR(hits(154), bytes(18788)),このコマンドでは、testpmd アプリによってプログラミングされたすべてのフローがダンプされます。また、外側の IP ヘッダーがセットアップ [SIP=172.20.0.8, DIP=172.30.0.8, IP-proto=UDP, UDP-dport=53] に一致します。フロー カウンターがダンプの一部として読み取られ、消去されます。
アプリの デザインを考える最終段階であるプロトタイピングはこれで完了しました。これで DPDK で PBR ルールを構築できるようになりました。このルールはハードウェアに組み込まれ、パケットに対してアクションを実行します。次のセクションで DPDK データプレーンを追加します。
DPDK データプレーン プラグインのビルド
このセクションでは、DPDK データプレーン プラグインを Zebra に追加し、DPU の PBR ハードウェア アクセラレーションの手順を説明します。この手順は個別のコード コミットに分解してあります。パッチセット全体は参照として利用できます。
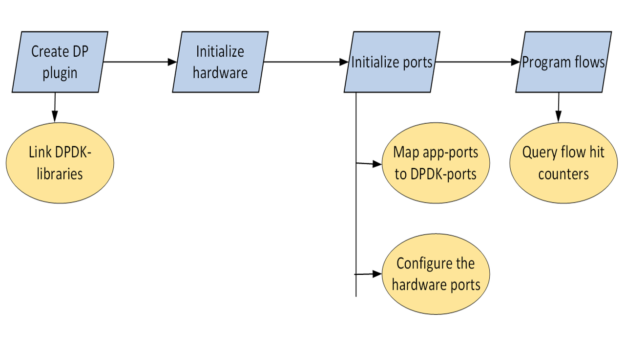
開発環境
ターゲット アーキテクチャは DPU-Arm であるため、Arm CPU で直接ビルドすること、X86 CPU でクロスコンパイルすること、クラウドでビルドすることができます。この投稿では、DPU Arm CPU でコードを書き、直接構築しました。
root ユーザーでアプリを実行する
FRR は通常、root 以外のユーザーで実行されます。FRR では、インターネット ルーティング テーブル全体をダウンロードし、アップロードできます。それに関して、何か問題が発生することがあるでしょうか。DPDK アプリはほとんどすべて、root ユーザーとして実行されます。DPDK のライブラリとドライバーにもそれが想定されます。
多くの実験の後、FRR を root 以外のユーザーでは機能させることができず、root ユーザーを選択して再コンパイルしました。安全な空間である DPU-Arm CPU で FRR を実行していたため、これは許容できます。
Zebra に新しいプラグインを追加する
Zebra は FRR のデーモンであり、ルーティング プロトコル デーモンからの更新を統合し、転送テーブルを構築します。また、Zebra には、転送テーブルを Linux カーネルのようなデータプレーンにプッシュするためのインフラストラクチャがあります。
DPDK 共有ライブラリを Zebra にリンクする
FRR には独自のビルド システムがあり、外部 make ファイルの直接インポートが制限されています。簡潔な pkg-config のおかげで、関連ライブラリを Zebra に簡単にリンクできました。
libdpdk.pc を見つけ、それを PKG_CONFIG_PATH 値に追加しました。
root@dpu-arm:~# find /opt/mellanox/ -name libdpdk.pc
/opt/mellanox/dpdk/lib/aarch64-linux-gnu/pkgconfig/libdpdk.pc
root@dpu-arm:~# export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/opt/mellanox/dpdk/lib/aarch64-linux-gnu/pkgconfigPkg-config からは以下の情報を抽出できます。
libs— DPDK 共有ライブラリの一覧を取得します。cflags— DPDK ヘッダー ファイルの場所を取得します。
root@dpu-arm:~# pkg-config --libs libdpdk
-L/opt/mellanox/dpdk/lib/aarch64-linux-gnu -Wl,--as-needed -lrte_node -lrte_graph -lrte_bpf -lrte_flow_classify -lrte_pipeline -lrte_table -lrte_port -lrte_fib -lrte_ipsec -lrte_vhost -lrte_stack -lrte_security -lrte_sched -lrte_reorder -lrte_rib -lrte_regexdev -lrte_rawdev -lrte_pdump -lrte_power -lrte_member -lrte_lpm -lrte_latencystats -lrte_kni -lrte_jobstats -lrte_gso -lrte_gro -lrte_eventdev -lrte_efd -lrte_distributor -lrte_cryptodev -lrte_compressdev -lrte_cfgfile -lrte_bitratestats -lrte_bbdev -lrte_acl -lrte_timer -lrte_metrics -lrte_cmdline -lrte_pci -lrte_ethdev -lrte_meter -lrte_ip_frag -lrte_net -lrte_mbuf -lrte_mempool -lrte_hash -lrte_rcu -lrte_ring -lrte_eal -lrte_telemetry -lrte_kvargs -lbsd
root@dpu-arm:~#
root@dpu-arm:~# pkg-config --cflags libdpdk
-include rte_config.h -mcpu=cortex-a72 -I/opt/mellanox/dpdk/include/dpdk -I/opt/mellanox/dpdk/include/dpdk/../aarch64-linux-gnu/dpdk -I/opt/mellanox/dpdk/include/dpdk -I/usr/include/libnl3
root@dpu-arm:~#FRR makefile (configure.ac) に DPDK の pkg check-and-define マクロを追加しました。
if test "$enable_dp_dpdk" = "yes"; then
PKG_CHECK_MODULES([DPDK], [libdpdk], [
AC_DEFINE([HAVE_DPDK], [1], [Enable DPDK backend])
DPDK=true
], [
AC_MSG_ERROR([configuration specifies --enable-dp-dpdk but DPDK libs were not found])
])
fiDPDK libs と cflags を抽出し zebra-dp-dpdk make マクロ (zebra/subdir.am) に含めました。
zebra_zebra_dplane_dpdk_la_LIBADD = $(DPDK_LIBS)
zebra_zebra_dplane_dpdk_la_CFLAGS = $(DPDK_CFLAGS)そうすることで、プラグインを構築するために必要なすべてのヘッダーとライブラリが与えられました。
ハードウェアを初期化する
最初の手順はハードウェアを初期化することでした。
char*argv[] = {"/usr/lib/frr/zebra", "--"};
rc = rte_eal_init(sizeof(argv) / sizeof(argv[0]), argv);それにより PCIe デバイスが調べられ、DPDK rte_eth_dev データベースにデータが入力されます。
ポートを初期化する
次に、ハードウェア ポートをセットアップします。
アプリのポート マッピングをセットアップする
FRR には、Linux netdevs テーブルに基づく独自のインターフェイス (ポート) テーブルがあります。このテーブルには NetLink アップデートと ifIndex を利用してデータが入力されます。PBR ルールはこのテーブルのインターフェイスに固定されます。PBR データプレーン エントリをプログラミングするには、Linux ifIndex 値と DPDK port-id 値の間のマッピング表が必要になります。netdev 情報は DPDK ドライバーで既に利用できます。rte_eth_dev_info_get から問い合わせできます。
struct rte_eth_dev_info *dev_info
RTE_ETH_FOREACH_DEV(port_id) {
/* dev_info->if_index is used for setting up the dpdk port_id<=>if_index mapping table
* in zebra */
rte_eth_dev_info_get(port_id, dev_info);
}ハードウェア ポートを構成する
また、すべてのポートをフロー分離モードにして開始する必要があります。
rte_flow_isolate(port_id, 1, &error);フロー分離によってフローミス パケットがカーネル ネットワーキング スタックに送信されます。ARP 要求などを処理できます。
rte_eth_dev_start(port_id);rte_flow API を使用して PBR ルールをプログラミングする
PBR ルールは、rte_flow リストとしてプログラミングしなければならなくなりました。サンプル ルールは次のようになります。
In-port=pf0vf0, match [SIP=172.20.0.8, DIP=172.30.0.8, IP-proto=UDP, UDP-dport=53], actions [set-src-mac=p0-mac, set-dst-mac=leaf2-MAC, dec-ttl, out-port=p0]これらのパラメーターには rte_flow_attributes、rte_flow_item (match)、rte_flow_action データ構造からデータが入力されます。
フロー属性
このデータ構造は、PBR フローがパケット リダイレクトまたは転送フロー用であることを示すために使用されます。
static struct rte_flow_attr attrs = {.ingress = 1, .transfer = 1};フロー一致項目
DPDK では、Ethernet、IP、UDP など、パケット ヘッダーの各層に対して {key, mask} の一致構造が使用されます。
struct rte_flow_item_eth eth, eth_mask;
struct rte_flow_item_ipv4 ip, ip_mask;
struct rte_flow_item_udp udp, udp_mask;これらのデータ構造を埋めるには、ほとんど繰り返しとなるコードが相当な量、必要となります。
フロー アクション
DPDK では、アクションごとに個別のデータ構造を使用し、フロー作成時に可変長配列としてすべてのアクションを提供できます。関連アクションは次のとおりです。
struct rte_flow_action_set_mac conf_smac, conf_dmac;
struct rte_flow_action_port_id conf_port;
struct rte_flow_action_count conf_count;これらのデータ構造を埋めることは、繰り返しになりますが、機械的なものです。
フローの有効性検証と作成
必要に応じて、rte_flow_attr、rte_flow_item、rte_flow_action リストの有効性を検証できます。
rc = rte_flow_validate(port_id, &attrs, items, actions, &error);フローの有効性検証は通常、基になる DPDK ドライバーで特定のフロー構成をサポートできるか確認するために使用されます。フローの有効性検証は任意の手順であり、最終的なコードでは、フローの作成に直接進むことができます。
flow_ptr = rte_flow_create(port_id, &attrs, items, actions, &error);Rte_flow コマンドは、受信ポートに固定されます。フロー エントリのグループを作成し、グループを連結することができます。フロー エントリが group-0 ではなく、チェーンの最初のエントリでない場合でも、フロー エントリは受信ポートに固定する必要があります。その group-0 にはパフォーマンス制限があります。
フロー挿入レートは group-0 で制限されます。この制限を回避するために、group-0 にデフォルト フローをインストールして「group-1 にジャンプし」、group-1 でアプリの誘導フローをプログラミングできます。
フローの削除
フロー作成 API からは、後続のフロー削除のためにキャッシュする必要があるフロー ポインタが返されます。
rc = rte_flow_destroy(port_id, flow_ptr, &error);FRR-PBR デーモンは、PBR フローを解決、追加、削除するためのステート マシンを管理します。そのため、DPDK ネイティブ関数を使用してエージアウト処理する必要がありません。
フロー統計値
フロー作成時に、フローにカウントアクションを接続しました。これは、フローの統計値とヒット数の問合せに使用できます。
struct rte_flow_query_count query;
rte_flow_query(port_id, flow_ptr, actions, &query, &error);その統計表示を FRR の vtysh CLI に接続し、テストと有効性検証を簡単にしました。
アプリのテスト
/etc/frr/daemons ファイルを利用し、FRR をルート ユーザーとして起動しました。新しく追加して DPDK プラグインを有効にしています。
zebra_options= " -M dplane_dpdk -A 127.0.0.1"DPDK-port マッピング表の FRR インターフェイスにデータが入力されます。
root@dpu-arm:~# systemctl restart frr
root@dpu-arm:~# vtysh -c "show dplane dpdk port"
Port Device IfName IfIndex sw,domain,port
0 0000:03:00.0 p0 4 0000:03:00.0,0,65535
1 0000:03:00.0 pf0hpf 6 0000:03:00.0,0,4095
2 0000:03:00.0 pf0vf0 15 0000:03:00.0,0,4096
3 0000:03:00.0 pf0vf1 16 0000:03:00.0,0,4097
4 0000:03:00.1 p1 5 0000:03:00.1,1,65535
5 0000:03:00.1 pf1hpf 7 0000:03:00.1,1,20479
root@dpu-arm:~#次に PBR ルールを設定しました。frr.conf を利用し、VM1 からの DNS トラフィックを照合し、leaf2 にリダイレクトするようにしました。
!
interface pf0vf0
pbr-policy test
!
pbr-map test seq 1
match src-ip 172.20.0.8/32
match dst-ip 172.30.0.8/32
match dst-port 53
match ip-protocol udp
set nexthop 192.168.20.250
!VM1 からエニーキャスト DNS サーバーに DNS クエリを送信しました。
root@dpu-arm:~# vtysh -c "show dplane dpdk pbr flows"
Rules if pf0vf0
Seq 1 pri 300
SRC IP Match 172.20.0.8/32
DST IP Match 172.30.0.8/32
DST Port Match 53
Tableid: 10000
Action: nh: 192.168.20.250 intf: p0
Action: mac: 00:00:5e:00:01:fa
DPDK: installed 0x40
DPDK stats: packets 14 bytes 1708
root@dpu-arm:~#フローが一致し、トラフィックが宛先である leaf2/server2 に転送されます。パケット ヘッダーが変更されます。この動作は、フローに接続されているカウンターと、mlx_steering_dump を使用したハードウェア ダンプによって確認できます。
root@dpu-arm:~# ./mlx_steering_dump/mlx_steering_dump_parser.py -p `pidof zebra` -f /tmp/dpdkDump
domain 0x32744e02, table 0xaaab07849cf0, matcher 0xffff20011010, rule 0xffff20012420
match: outer_l3_type: 0x1, outer_ip_dst_addr: 172.30.0.8, outer_l4_type: 0x2, metadata_reg_c_0: 0x00030000, outer_l4_dport: 0x0035, outer_ip_src_addr: 172.20.0.8
action: MODIFY_HDR(hdr(dec_ip4_ttl,smac=04:3f:72:bf:ae:38,dmac=00:00:5e:00:01:fa)), rewrite index 0x0 & VPORT, num 0xffff & CTR(hits(33), bytes(4026)), index 0x806200これで FRR は DPDK データプレーン プラグインが完全に機能し、DPU ハードウェアで PBR ルールの負荷が軽減されます。
まとめ
この投稿では、DPDK rte_flow ライブラリを使用して BlueField で PBR ルールをハードウェア高速化するための FRR データプレーン プラグインを作成する方法を確認しました。次の投稿では、FRR DOCA データプレーン プラグインの作成について段階的に説明します。新しい DOCA フロー ライブラリを利用し、PBR ルールを負荷軽減する方法をご覧いただきます。詳細については、「NVIDIA BlueField DPU と NVIDIA DOCA ライブラリによるアプリケーション開発」をご覧ください。