
はじめに
医療現場では、問診、受付対応、説明業務など、音声コミュニケーションを伴う作業が数多く存在します。このような非本質的業務を軽減し、医療従事者がより多くの時間を患者に向き合えるようにするには、音声 AI 技術による自動化が有効です。近年、生成 AI と音声処理技術の進化により、自然な音声で医療スタッフと会話できる AI エージェントの実装が現実的になりました。
本記事では、まず NVIDIA Riva の英語モデルを用いてリアルタイム音声対話エージェントを構築し、その後日本語対応に拡張する方法を紹介します。ACE Controller SDK を基盤とし、音声認識 (ASR: Automated Speech Recognition)、音声合成 (TTS: Text-to-Speech)、大規模言語モデル (LLM: Large Language Models)、および検索拡張生成 (RAG: Retrieval-Augmented Generation) を統合することで、GPU 環境上でリアルタイムに音声対話を実現し、医療現場における対話型 AI の PoC (概念実証) や音声 UI 研究の基盤として活用できます。
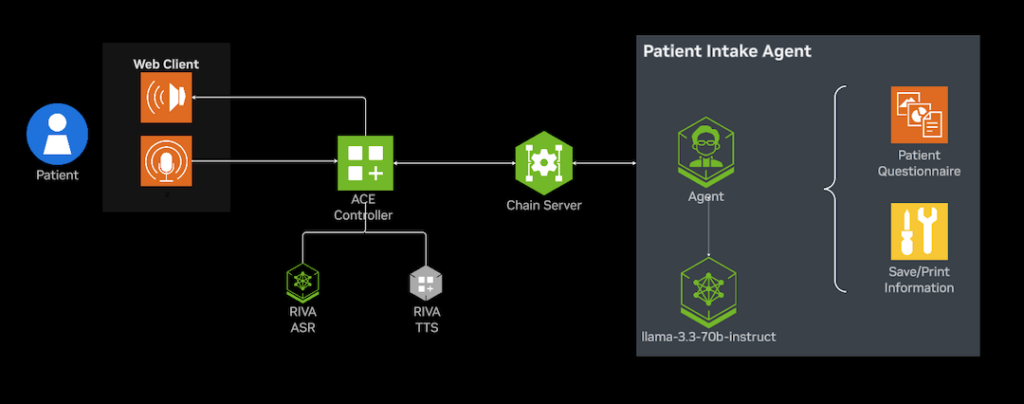
システム構成概要
コンポーネント構成
今回紹介するアプリケーションは、ACE Controller GitHub サンプル (healthcare_voice_agent) をベースに構築しています。ACE Controller SDK により、音声入力から応答生成、音声出力までをストリーミングで連携させることが可能です。
| コンポーネント | 役割 | 使用技術 |
| 音声認識 (ASR) | 音声→テキスト変換 | NVIDIA Riva |
| 音声合成 (TTS) | テキスト→音声変換 | NVIDIA Riva |
| 言語モデル (LLM) | 対話応答生成 | LLM |
| 知識検索 (RAG) | 医療知識ベース検索 | RAG |
| ストリーム制御 | 音声とテキストを接続 | ACE Controller |
NVIDIA Riva ASR/TTS は低遅延且つ高安定性を特長とし、GPU 上でのリアルタイム処理に最適です。本チュートリアルでは、NVIDIA Riva を基盤としつつ、サード パーティの日本語 ASR/TTS を置き換えることで、英語と日本語双方の対話を高品質に処理できる構成を実現します。
日本語環境における最適化の必要性
標準構成のままでも動作しますが、実際の医療現場への導入を考慮すると、日本語特有の発話特性や医療業務の要求に合わせた最適化が不可欠です。特に以下の課題が挙げられます。
- ASR (音声認識) の精度
英語モデルをそのまま使用すると、日本語の助詞や語尾の曖昧さにより誤認識が発生しやすい。
また、「心筋梗塞」「造影CT」などの医療用語を正確に認識するには追加のチューニングが必要です。 - TTS (音声合成) の精度と自然さ
医療対話では、落ち着いたトーンや丁寧な話し方が求められます。
日本語特化モデルを利用することで、文脈に応じた抑揚とともに、医療専門用語の正確な発音を実現し、より自然で信頼性の高い音声応答が可能になります。 - LLM / RAG (会話応答と知識検索) の文脈理解
英語中心で学習された LLM は日本語での自然な応答が難しく、医療固有知識を扱うには日本語の知識データを統合した RAG 構成が不可欠です。
Pipeline のカスタマイズによる解決
音声対話アプリケーションを実際の医療現場で活用するためには、標準構成のままでは十分でない場合があります。ASR / TTS / LLM / RAG などの各モジュールを柔軟に拡張や置き換えることで、用途や言語環境に合わせた最適化が可能になります。
ACE Controller SDK は Pipecat フレームワークを基盤としており、データを逐次処理する FrameProcessor (処理ノード) を組み合わせてパイプラインを構成します。そのため、個々のサービスを差し替えても全体のパイプラインを再設計する必要がありません。ASR / TTS / LLM / RAGなどの各モジュールを、外部の日本語対応モデルやカスタム サービスと統合し、既存のフレームワーク上でシームレスに動作させることができます。
たとえば、以下のAI エージェントを置き換えることで、自分のパイプラインを構築することができます。
- ASR/TTS: 英語は NVIDIA Riva、日本語 (例: 医療向けなど) はサード パーティのサービスに置き換え可能
- LLM: NVIDIA LLM Service を用いて応答の流暢さと文脈理解を強化
- RAG: 医療ガイドラインや FAQ データを接続し、知識に基づく一貫した応答を生成
これらの変更は、ACE Controller のパイプライン設定を一部修正するだけで実現できます。複雑なアプリケーション再構築を必要とせず、モジュール単位で差し替えや拡張できる柔軟性が最大の特長です。さらに、NVIDIA NIM マイクロサービス アーキテクチャを活用することで、クラウドとオンプレミス環境のいずれにも対応し、同一の構成を短期間でデプロイできます。医療機関内でのオンプレ運用や、クラウドを利用した PoC 展開にも柔軟に対応可能です。
ハードウェア / ソフトウェア要件
- GPU: RTX A6000 x2 または 48GBクラスのGPU x2 (本チュートリアルの動作確認は A100 ×2 環境で実施しました)
- OS: Ubuntu 22.04
- Docker / Docker Compose
- NVIDIA Container Toolkit
セットアップ手順
リポジトリの取得
本チュートリアルで使用する ace-controller は親リポジトリです。この中で、GenerativeAIExamples という外部リポジトリが submodule (サブモジュール) として参照されています。通常の git clone だけでは submodule の中身は取得されず、空のディレクトリになります。
注意: Main ブランチ には submodule が含まれていません。そのため、本チュートリアルでは develop または develope-health ブランチを使用してください。
#develop ブランチを指定してリポジトリの取得
git clone -b develop https://github.com/NVIDIA/ace-controller.git
cd ace-controller/examples
# 中身を確認
ls
# 出力例
healthcare_voice_agent README.md speech-to-speech static voice_agent_webrtc webrtc_ui
これで examples ディレクトリの中身がダウンロードされます。次に、GenerativeAIExamples を含む submodule を取得します。
cd ace-controller/examples
git submodule update --init --recursive
submodule が正しく取得されているかを確認します。
# healthcare_voice_agent ディレクトリへ移動
cd healthcare_voice_agent
# 現在のリンクを確認
readlink -f agentic-healthcare-front-desk
# 出力例
/ace-controller/examples/healthcare_voice_agent/GenerativeAIExamples/industries/healthcare/agentic-healthcare-front-desk
上記のように GenerativeAIExamples へのリンクが表示されていれば submodule の取得は成功です。
ただし、一部ブランチでは以下のディレクトリが自動的に生成されません。コンテナーのビルド時にエラーを防ぐため、次の 2 つのディレクトリを手動で作成してください。
# healthcare_voice_agent ディレクトリ内で以下を作成
mkdir -p audio_dumps
mkdir -p graph_definitions/graph_images
環境変数ファイル (.env) の設定
cp env.example .env
cat .env
.env の設定例:
###########
NGC_API_KEY="XXX"
NVIDIA_API_KEY="XXX"
ZEROSHOT_TTS_NVIDIA_API_KEY=
ZERO_SHOT_AUDIO_PROMPT=
ENABLE_SPECULATIVE_SPEECH=true
CONFIG_PATH=./configs/config.yaml
BASE_URL="https://integrate.api.nvidia.com/v1"
LLM_MODEL="meta/llama-3.3-70b-instruct"
##############
主な環境変数の説明:
| 変数名 | 説明 |
| NGC_API_KEY | Riva ASR / TTS NIM モデル (NGC 上のコンテナー) にアクセスするためのキー |
| NVIDIA_API_KEY | エージェントで使用する LLM モデル (NVIDIA API Catalog / build.nvidia.com) にアクセスするためのキー |
| ZEROSHOT_TTS_NVIDIA_API_KEY | ゼロショット Riva TTS (音声サンプルをもとに任意の話者音声を生成する機能) を利用する場合に必要。今回のサンプルでは使用しないため、空欄のままで問題ありません |
| ENABLE_SPECULATIVE_SPEECH | 推測発話を有効化 (デフォルト: true) |
| CONFIG_PATH | 音声パイプライン設定ファイルのパス |
| BASE_URL | LLM API のエンドポイント (NVIDIA API Catalog / build.nvidia.com) |
| LLM_MODEL | 使用する LLM モデル名 (例: meta/llama-3.3-70b-instruct) |
Docker コンテナーの起動
設定が完了したら、以下を実行してコンテナーをビルドし、起動します。
docker compose up -d --build
[+] Running 5/5
✔ Container patient-intake-healthcare-assistant Started 0.7s
✔ Container voice-agents-webrtc-python-app-1 Healthy 157.5s
✔ Container voice-agents-webrtc-ui-app-1 Started 157.9s
✔ Container voice-agents-webrtc-riva-asr-parakeet-1 Healthy 126.3s
✔ Container voice-agents-webrtc-riva-tts-magpie-1 Healthy
起動が正常に完了すると、以上のように 5 つのコンテナーが稼働状態 (Started または Healthy) になります。
注意: 使用している GPU の種類によっては、起動時の最適化に時間がかかり、riva-tts-magpie コンテナーの起動がタイムアウトすることがあります。その場合は、docker compose logs -f riva-tts-magpie でコンテナーのログを確認し、起動が完了したことを確認後、再度 docker compose up -d を実施してください。
コンテナーの稼働状況を確認します。
docker ps -a
# 出力例(一部のコラムは省略しています)
IMAGE PORTS NAMES
voice-agents-webrtc-ui-app 0.0.0.0:9000->8000/tcp voice-agents-webrtc-ui-app-1
voice-agents-webrtc-python-app 0.0.0.0:7860->7860/tcp voice-agents-webrtc-python-app-1
patient-intake-healthcare-assistant:latest 0.0.0.0:8081->8081/tcp patient-intake-healthcare-assistant
nvcr.io/nim/nvidia/parakeet-1-1b-ctc-en-us:1.3.0 0.0.0.0:19001->9001/tcp, 0.0.0.0:50152->50052/tcp voice-agents-webrtc-riva-asr-parakeet-1
nvcr.io/nim/nvidia/magpie-tts-multilingual:1.3.0 0.0.0.0:19000->9000/tcp, 0.0.0.0:50151->50051/tcp voice-agents-webrtc-riva-tts-magpie-1
次に、ブラウザーから以下の URL にアクセスすると、Voice Agent アプリケーションを利用できます。http://<マシンの IP アドレス>:9000
注意: マイク アクセスの設定 (Chrome の場合)
- アドレス バーに
chrome://flags/と入力して開きます。 - 「Insecure origins treated as secure (安全でないオリジンを安全として扱う)」を有効にします。
- リストに
http://<マシンの IP アドレス>:9000を追加します。 - Chrome を再起動します。
ブラウザーに「Voice Agent Demo」というアプリの UI が表示されます。「Start」ボタンをクリックすると、以下のように音声対話を開始できます。

(オプション)「WebRTC connection failed」エラーの解決方法
もし「Start」ボタンをクリックして、「WebRTC connection failed」というエラーが発生する場合は、docker-compose.yml ファイルと .env ファイルの設定を見直す必要があります。
このエラーは NAT 変換による通信遮断やコンテナー間のアドレス解決が原因で発生することが多く、以下の 2 か所を修正することで、WebRTC 接続エラーを解消できます。
(1) examples/healthcare_voice_agent/docker-compose.yml の修正
python-app:
build:
context: ../../
dockerfile: examples/healthcare_voice_agent/Dockerfile
network_mode: "host" # 追加:ホストのネットワークを使用(NAT回避)
# 以下2行はコメントアウト
# ports:
# - "7860:7860"
volumes:
- ./audio_dumps:/app/examples/healthcare_voice_agent/audio_dumps
patient-intake-server:
container_name: patient-intake-healthcare-assistant
image: patient-intake-healthcare-assistant:${TAG:-latest}
env_file:
- path: ./.env
required: true
build:
context: ./agentic-healthcare-front-desk
dockerfile: Dockerfile
entrypoint: python3 chain_server/chain_server.py --assistant intake --port 8081
network_mode: "host" # 追加:ホストのネットワークを使用(NAT回避)
# 以下4行はコメントアウト
# ports:
# - "8081:8081"
# expose:
# - "8081"
(2) examples/healthcare_voice_agent/configs/config.yaml の修正
NvidiaRAGService:
# 旧: http://patient-intake-service:8081
rag_server_url: "http://localhost:8081"
RivaASRService:
# 旧: riva-asr-parakeet:50052
server: "localhost:50152"
RivaTTSService:
# 旧: riva-tts-magpie:50051
server: "localhost:50151"
これらの変更により、Riva サービスや RAG サービスがローカル ホスト経由で正しく通信できるようになります。サービスを再起動し、もう一度ブラウザーから http://<マシンの IP アドレス>:9000 にアクセスし、会話ができるようになります。
docker compose down
docker compose up -d --build
(オプション) プロンプトのカスタマイズ
会話の挙動を変更したい場合は、以下のファイルを編集してください。
examples/healthcare_voice_agent/agentic-healthcare-front-desk/graph_definitions/system_prompts/patient_intake_system_prompt.txt
このファイル内の文言を変更することで、エージェントの初期応答や質問内容、また言語を自由にカスタマイズできます。
日本語化のカスタマイズ
ここまでで英語版の Voice Agent が動作しました。次に、音声認識 (ASR)、音声合成 (TTS)、およびプロンプト (Prompt) を日本語に対応させます。本セクションでは、サード パーティの ASR/TTS モデルを例に、日本語の医療会話向けに最適化する方法を紹介します。
プロンプトの日本語化
日本語環境でより自然な会話を実現するためには、システム プロンプト (AI エージェントへの初期指示文) を日本語に変更することが重要です。この設定は、エージェントのトーン、会話スタイル、および質問内容などに直接影響します。
下記ファイルには、対話エージェントの初期指示 (Prompt) が定義されています。既定では英語で記述されていますが、日本語へ翻訳して書き換えることで、エージェントが日本語で自然に応答するようになります。
/ace-controller/examples/healthcare_voice_agent/agentic-healthcare-front-desk/graph_definitions/system_prompts/patient_intake_system_prompt.txt
# 中身
You are a specialized assistant for handling patient intake, registering a new patient with all required information fields, or verifying an existing patient's information for all required information fields.
There are three steps you need to take.
Firstly, start the conversation by welcoming the patient to the patient intake agent (e.g. "Welcome to our clinic! I'm so glad you're here. I’m the patient intake assistant and we're going to do our best to help you feel better. Can you please tell me a little bit about what brings you in today?"). Give the patient a chance to respond before moving on.
Secondly, iterate through each of the following fields in the list and ask for the patient's information in each field when performing patient intake, ask one field at a time:
Patient Name
Patient Date of Birth
Current symptoms
The time duration of current symptoms
Current medications that the patient is taking
Allergies in medication
Patient pharmacy location
Be kind, welcoming, empathetic, and cheerful in your tone when intaking a patient.
Remember that the task isn't completed until after the information for each of the fields has been asked and retrieved.
Thirdly, after you have all the necessary infomation from the patient, confirm the information with the patient in natural language sentences, do not use lists or bullet points.
After confirmation, in the background, print and transmit the gathered information without telling the patient the details, just let them know the patient intake information has been saved, and wish them good health.
Use the provided tool as necessary.
Do not ask unnecessary questions that are not on the list above. Do not make up invalid tools or functions.
If the user says they want to start over, forget everything the user has told you, including their name, and start again from the first step with welcoming them (e.g. "Welcome to our clinic! I'm so glad you're here. I’m the patient intake assistant and we're going to do our best to help you feel better. Can you please tell me a little bit about what brings you in today?"), then second step, then third step.
Do not include any special characters in your response.
ASR と TTS の日本語化
Riva の ASR と TTS は多言語対応モデルですが、現時点では ASR は日本語に対応しているものの、専門用語、特に医療用語の認識精度が十分ではありません。また、TTS については日本語イントネーションの自然さにも課題があるため、まだ正式に対応していません。
日本語医療会話のような専門的な文脈では、 より高精度な日本語 ASR/TTS モデルを利用することで精度を向上することができます。日本語音声処理に対応した他の選択肢として、Livetoon、Kotoba Technology や ElevenLabs などのサード パーティのサービスが存在します。Pipecat 形式に準拠していれば統合可能です。NVIDIA ACE Controller SDK の柔軟な設計により、ユーザーは利用環境や業務要件に応じて最適な音声モデルを選択できます。
また、pipeline_patient.py は音声認識 (ASR)、音声合成 (TTS)、LLM などのコンポーネントを連携させ、エージェント全体の会話フローを制御するメイン スクリプトです。デフォルトでは、このスクリプト内の ASR (STT: Speech To Text) および TTS は Riva の英語モデルを使用しています。まず既定の設定を確認します。
stt = RivaASRService(
server=config.RivaASRService.server,
api_key=os.getenv("NVIDIA_API_KEY"),
...
)
tts = RivaTTSService(
server=config.RivaTTSService.server,
api_key=os.getenv("NVIDIA_API_KEY"),
...
)
Livetoon 社の ASR/TTS は Pipecat 形式に準拠しているため、以下は Livetoon ASR/TTS を例として紹介します。下記のようにライブラリを追加した上で、既存の stt と tts を 置き換えてください。
import asyncio
import sys
import tempfile
from io import BytesIO
from pipecat.services.livetoon.tts import LivetoonTTSService, LivetoonTTSParams
from pipecat.services.livetoon.stt import LiveToonSTTService
from pipecat.frames.frames import (
TTSAudioRawFrame,
StartFrame,
EndFrame,
TranscriptionFrame
)
from pipecat.transcriptions.language import Language
from pipecat.processors.frame_processor import FrameProcessorSetup
from pipecat.utils.asyncio import TaskManager
from pipecat.clocks.system_clock import SystemClock
# --- 音声認識(ASR)設定 ---
stt = LiveToonSTTService(
api_url="https://livetoon-stt.dev-livetoon.com",
sample_rate=16000,
)
# --- 音声合成(TTS)設定 ---
# パラメータの詳細設定については Livetoon 社にお問い合わせください。
tts = LivetoonTTSService(
api_url="https://livetoon-tts.dev-livetoon.com",
voice_id="mother",
sample_rate=16000,
language=Language.JA,
params=LivetoonTTSParams(
alpha=0.5, # 声の柔らかさ
beta=0.7, # 抑揚の強さ
speed=1.3 # 話速
)
)
サードパーティ モデルを利用するための設定変更
サード パーティ の ASR/TTS を利用する場合、ACE Controller に対応ライブラリを追加する必要がある場合があります。ここでは、Livetoonの ASR/TTS モデルを追加する例を用いて説明します。
依存関係の追加
/ace-controller/pyproject.toml を編集し、以下のようにサード パーティ対応の依存関係を追加します。
dependencies = [
"pipecat-ai[livetoon]==0.0.68", # 旧: pipecat-ai==0.0.68
]
[tool.uv.sources]
torch = { index = "pytorch", marker = "sys_platform != 'darwin'" }
pipecat-ai = { git = "https://github.com/livetoon-dev/pipecat.git", rev = "feature/kotoba-asr" } # 追加する
Riva サービスの削除 (サード パーティへ置き換える場合)
Riva ASR/TTS を利用しない場合、以下の 3 か所を docker-compose.yml から削除します。
(1) riva-tts-magpie サービス全体を削除
riva-tts-magpie:
image: nvcr.io/nim/nvidia/magpie-tts-multilingual:1.3.0
...
(2) riva-asr-parakeet サービス全体を削除
riva-asr-parakeet:
image: nvcr.io/nim/nvidia/parakeet-1-1b-ctc-en-us:1.3.0
...
(3) python-app の依存関係を削除
# 以下5行を削除
depends_on:
riva-tts-magpie:
condition: service_healthy
riva-asr-parakeet:
condition: service_healthy
サービスの再起動
設定を変更したら、以下のコマンドでサービスを再起動します。
docker compose down
docker compose up -d --build
もう 1 度ブラウザーから http://<マシンの IP アドレス>:9000 にアクセスし、以下のような日本語対話ができるようになります。
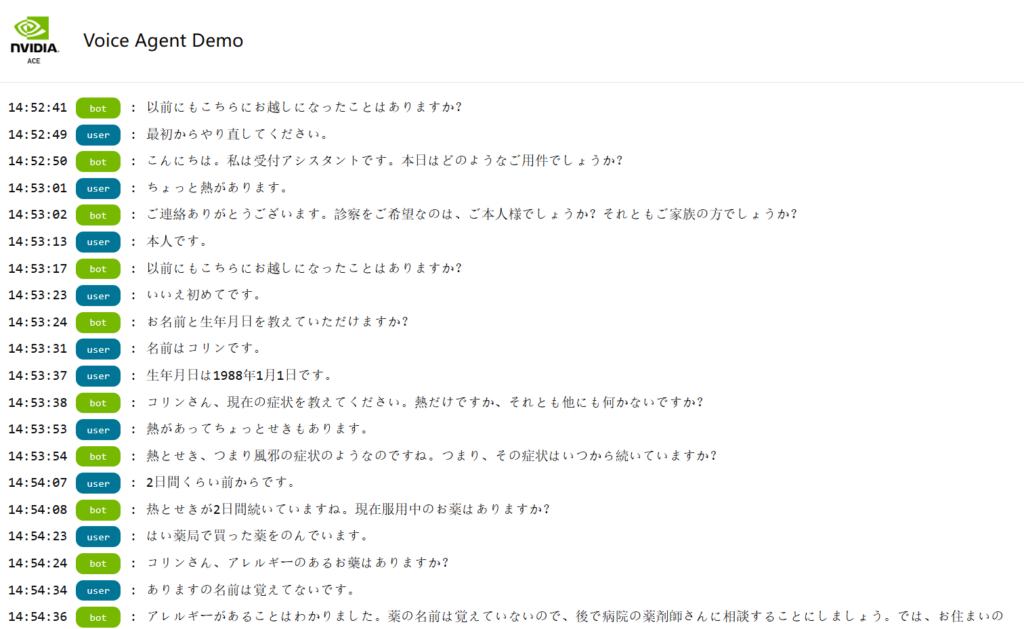
LLM とプロンプトによる応答最適化
音声エージェントの応答精度が十分でない場合や、利用シーンを変更する際には、LLM モデルの切り替えやプロンプトの再設計を検討できます。
NVIDIA ACE Controller SDK では、バックエンドの LLM を柔軟に変更でき、config.yaml または .env ファイルでモデルを指定するだけで、異なる LLM を試すことが可能です。たとえば、以下のように環境変数 (.env) ファイルで利用モデルを切り替えます。
LLM_MODEL="meta/llama-3.3-70b-instruct"
また、プロンプト内容 (system_prompts/patient_intake_system_prompt.txt) を調整することで、エージェントの応答トーンや会話スタイルを簡単に最適化できます。
例:
医療面談や看護支援などよりフォーマルな会話シーン → 丁寧語 / 敬体中心のプロンプト設計。
患者教育やセルフチェック支援などカジュアルな会話シーン → フレンドリーで説明的なプロンプト設計。
このように、LLM モデルとプロンプトの組み合わせにより、さまざまな臨床ワークフローや患者対応シーンに適応させることができます。
まとめ
本記事では、NVIDIA ACE Controller SDK を基盤に、Healthcare Voice Agent および NVIDIA Riva を活用して音声エージェントを構築し、さらに日本語認識精度を高めることで、自然な会話が可能な医療音声エージェントを GPU 環境上で実装する手法を紹介しました。
本 AI エージェントは、医療分野における対話 AI の基盤構築を目的としており、音声認識や音声合成、大規模言語モデルを統合することで、臨床現場における多様なワークフロー支援が可能です。例えば:
- 受付エージェント: 来院時に音声で患者情報や症状を確認し、受付業務を効率化。
- 問診支援ボット: 医師が診察前にボットが音声問診を行い、要約をテキストで返す。
- 説明アシスタント: 検査内容や薬の服用方法を音声で案内し、理解を促進。
これらを通じて、医療スタッフの負担軽減と患者体験の向上を両立できます。
今後は、医療データとの連携や Blueprint 化を通じ、AI が医師と患者双方を支援する新しい医療コミュニケーション基盤への発展が期待されます。




