Revision History
Chapter 2 Updates
| Date | Summary of Change |
|---|---|
| January 17, 2023 | Added a footnote to the Types and Precision topic. |
| May 2, 2023 | Added additional precisions to the Types and Precision topic. |
Chapter 3 Updates
| Date | Summary of Change |
|---|---|
| January 17, 2023 | Updated the Performing Inference topic regarding executing a network. |
Chapter 4 Updates
| Date | Summary of Change |
|---|---|
| January 17, 2023 |
|
Chapter 5 Updates
| Date | Summary of Change |
|---|---|
| January 19, 2023 | Added a new topic called Runtime Options. |
| January 24, 2023 | Rewrote the existing CUDA Lazy Loading topic. |
| March 8, 2023 | Added a new topic called Compatibility. |
Chapter 6 Updates
| Date | Summary of Change |
|---|---|
| January 24, 2023 |
|
| February 14, 2023 | Rewrote the existing Compatibility Checks topic. |
| March 8, 2023 | Added a new topic called Using Version Compatibility with the ONNX Parser. |
Chapter 7 Updates
| Date | Summary of Change |
|---|---|
| January 17, 2023 | Added a new topic called Q/DQ Interaction with Plugins. |
Chapter 8 Updates
| Date | Summary of Change |
|---|---|
| January 24, 2023 | Added a new topic called Dimension Constraint using IAssertionLayer. |
Chapter 9 Updates
| Date | Summary of Change |
|---|---|
| January 28, 2023 | Added a new section called Plugin Shared Libraries. |
Chapter 13 Updates
| Date | Summary of Change |
|---|---|
| January 29, 2023 |
|
Appendix Updates
| Date | Summary of Change |
|---|---|
| January 17, 2023 | Added more flags to the build and inference phase sections of the Commonly Used Command-line Flags topic. |
Abstract
This NVIDIA TensorRT 8.6.11 Developer Guide for DRIVE OS demonstrates how to use the C++ and Python APIs for implementing the most common deep learning layers. It shows how you can take an existing model built with a deep learning framework and build a TensorRT engine using the provided parsers. The Developer Guide also provides step-by-step instructions for common user tasks such as creating a TensorRT network definition, invoking the TensorRT builder, serializing and deserializing, and how to feed the engine with data and perform inference; all while using either the C++ or Python API.
1. Introduction
1.1. Structure of This Guide
Chapter 2 provides a broad overview of TensorRT capabilities.
Chapters three and four contain introductions to the C++ and Python APIs respectively.
Subsequent chapters provide more detail about advanced features.
The appendix contains a layer reference and answers to FAQs.
1.2. Samples
1.3. Complementary GPU Features
1.4. Complementary Software
NVIDIA DALI® provides high-performance primitives for preprocessing image, audio, and video data. TensorRT inference can be integrated as a custom operator in a DALI pipeline. A working example of TensorRT inference integrated as a part of DALI can be found here.
TensorFlow-TensorRT (TF-TRT) is an integration of TensorRT directly into TensorFlow. It selects subgraphs of TensorFlow graphs to be accelerated by TensorRT, while leaving the rest of the graph to be executed natively by TensorFlow. The result is still a TensorFlow graph that you can execute as usual. For TF-TRT examples, refer to Examples for TensorRT in TensorFlow.
Torch-TensorRT (Torch-TRT) is a PyTorch-TensorRT compiler that converts PyTorch modules into TensorRT engines. Internally, the PyTorch modules are first converted into TorchScript/FX modules based on the Intermediate Representation (IR) selected. The compiler selects subgraphs of the PyTorch graphs to be accelerated by TensorRT, while leaving the rest of the graph to be executed natively by Torch. The result is still a PyTorch module that you can execute as usual. For examples, refer to Examples for Torch-TRT.
The TensorFlow-Quantization Toolkit provides utilities for training and deploying Tensorflow 2-based Keras models at reduced precision. This toolkit is used to quantize different layers in the graph exclusively based on operator names, class, and pattern matching. The quantized graph can then be converted into ONNX and then into TensorRT engines. For examples, refer to the model zoo.
The PyTorch Quantization Toolkit provides facilities for training PyTorch models at reduced precision, which can then be exported for optimization in TensorRT.
In addition, the PyTorch Automatic SParsity (ASP) tool provides facilities for training models with structured sparsity, which can then be exported and allows TensorRT to use the faster sparse tactics on NVIDIA Ampere Architecture GPUs.
TensorRT is integrated with NVIDIA’s profiling tools, NVIDIA Nsight™ Systems and NVIDIA Deep Learning Profiler (DLProf).
A restricted subset of TensorRT is certified for use in NVIDIA DRIVE® products. Some APIs are marked for use only in NVIDIA DRIVE and are not supported for general use.
1.5. ONNX
The GitHub version may support later opsets than the version shipped with TensorRT refer to the ONNX-TensorRT operator support matrix for the latest information on the supported opset and operators. For TensorRT deployment, we recommend exporting to the latest available ONNX opset.
The ONNX operator support list for TensorRT can be found here.
PyTorch natively supports ONNX export. For TensorFlow, the recommended method is tf2onnx.
A good first step after exporting a model to ONNX is to run constant folding using Polygraphy. This can often solve TensorRT conversion issues in the ONNX parser and generally simplify the workflow. For details, refer to this example. In some cases, it may be necessary to modify the ONNX model further, for example, to replace subgraphs with plugins or reimplement unsupported operations in terms of other operations. To make this process easier, you can use ONNX-GraphSurgeon.
1.6. Code Analysis Tools
1.7. API Versioning
- MAJOR version when making incompatible API or ABI changes
- MINOR version when adding functionality in a backward compatible manner
- PATCH version when making backward compatible bug fixes
Note that semantic versioning does not extend to serialized objects. To reuse plan files, and timing caches, version numbers must match across major, minor, patch, and build versions (with some exceptions for the safety runtime as detailed in the NVIDIA DRIVE OS 6.0 Developer Guide). Calibration caches can typically be reused within a major version but compatibility is not guaranteed.
1.8. Deprecation Policy
For any APIs and tools specifically deprecated in TensorRT 7.x, the 12-month migration period starts from the TensorRT 8.0 GA release date.
1.9. Hardware Support Lifetime
1.10. Support
In addition, you can access the NVIDIA DevTalk TensorRT forum at https://devtalk.nvidia.com/default/board/304/tensorrt/ for all things related to TensorRT. This forum offers the possibility of finding answers, making connections, and getting involved in discussions with customers, developers, and TensorRT engineers.
1.11. Reporting Bugs
2. TensorRT’s Capabilities
2.1. C++ and Python APIs
For more information, refer to the NVIDIA TensorRT 8.6.11 API Reference for DRIVE OS.
2.2. The Programming Model
2.2.1. The Build Phase
- Create a network definition.
- Specify a configuration for the builder.
- Call the builder to create the engine.
The NetworkDefinition interface is used to define the model. The most common path to transfer a model to TensorRT is to export it from a framework in ONNX format, and use TensorRT’s ONNX parser to populate the network definition. However, you can also construct the definition step by step using TensorRT’s Layer and Tensor interfaces.
Whichever way you choose, you must also define which tensors are the inputs and outputs of the network. Tensors that are not marked as outputs are considered to be transient values that can be optimized away by the builder. Input and output tensors must be named, so that at runtime, TensorRT knows how to bind the input and output buffers to the model.
The BuilderConfig interface is used to specify how TensorRT should optimize the model. Among the configuration options available, you can control TensorRT’s ability to reduce the precision of calculations, control the tradeoff between memory and runtime execution speed, and constrain the choice of CUDA® kernels. Since the builder can take minutes or more to run, you can also control how the builder searches for kernels, and cached search results for use in subsequent runs.
After you have a network definition and a builder configuration, you can call the builder to create the engine. The builder eliminates dead computations, folds constants, and reorders and combines operations to run more efficiently on the GPU. It can optionally reduce the precision of floating-point computations, either by simply running them in 16-bit floating point, or by quantizing floating point values so that calculations can be performed using 8-bit integers. It also times multiple implementations of each layer with varying data formats, then computes an optimal schedule to execute the model, minimizing the combined cost of kernel executions and format transforms.
- By default, engines created by TensorRT are specific to both the TensorRT version with which they were created and the GPU on which they were created. Refer to the Version Compatibility and Hardware Compatibility sections for how to configure an engine for forward compatibility.
- TensorRT’s network definition does not deep-copy parameter arrays (such as the weights for a convolution). Therefore, you must not release the memory for those arrays until the build phase is complete. When importing a network using the ONNX parser, the parser owns the weights, so it must not be destroyed until the build phase is complete.
- The builder times algorithms to determine the fastest. Running the builder in parallel with other GPU work may perturb the timings, resulting in poor optimization.
2.2.2. The Runtime Phase
- Deserialize a plan to create an engine.
- Create an execution context from the engine.
- Populate input buffers for inference.
- Call enqueueV3() on the execution context to run inference.
The Engine interface represents an optimized model. You can query an engine for information about the input and output tensors of the network - the expected dimensions, data type, data format, and so on.
The ExecutionContext interface, created from the engine is the main interface for invoking inference. The execution context contains all of the state associated with a particular invocation - thus you can have multiple contexts associated with a single engine, and run them in parallel.
When invoking inference, you must set up the input and output buffers in the appropriate locations. Depending on the nature of the data, this may be in either CPU or GPU memory. If not obvious based on your model, you can query the engine to determine in which memory space to provide the buffer.
After the buffers are set up, inference can be enqueued (enqueueV3). The required kernels are enqueued on a CUDA stream, and control is returned to the application as soon as possible. Some networks require multiple control transfers between CPU and GPU, so control may not return immediately. To wait for completion of asynchronous execution, synchronize on the stream using cudaStreamSynchronize.
2.3. Plugins
TensorRT ships with a library of plugins, and source for many of these and some additional plugins can be found here.
You can also write your own plugin library and serialize it with the engine.
Refer to the Extending TensorRT with Custom Layers chapter for more details.
2.4. Types and Precision
TensorRT supports FP32, FP16, INT8, INT32, UINT8, and BOOL data types.1
Refer to the TensorRT Operator documentation for layer I/O data type specification.
- FP32, FP16
- Unquantized higher precision types.
- INT8
- UINT8
- Data type only usable as a network I/O type.
- Network level inputs in UINT8 must be converted from UINT8 to either FP32 or FP16 using a CastLayer before the data is used in other operations.
- Network-level outputs in UINT8 must be produced by a CastLayer that has been explicitly inserted into the network (will only support conversions from FP32/FP16 to UINT8).
- UINT8 quantization is not supported.
- The ConstantLayer does not support UINT8 as an output type.
- BOOL
- A boolean type used with supported layers.
-
To control precision at the model level, BuilderFlag options can indicate to TensorRT that it may select lower-precision implementations when searching for the fastest (and because lower precision is generally faster, if allowed to, it typically will).
Therefore, you can easily instruct TensorRT to use FP16 calculations for your entire model. For regularized models whose input dynamic range is approximately one, this typically produces significant speedups with negligible change in accuracy.
- For finer-grained control, where a layer must run at higher precision because part of the network is numerically sensitive or requires high dynamic range, arithmetic precision can be specified for that layer.
Refer to the Reduced Precision section for more details.
2.5. Quantization
Dynamic range information can be calculated by the builder (this is called calibration) based on representative input data. Or you can perform quantization-aware training in a framework and import the model to TensorRT with the necessary dynamic range information.
Refer to the Working with INT8 chapter for more details.
2.6. Tensors and Data Formats
Note that tensors are limited to at most 2^31-1 elements.
While optimizing the network, TensorRT performs transformations internally (including to HWC, but also more complex formats) to use the fastest possible CUDA kernels. In general, formats are chosen to optimize performance, and applications have no control over the choices. However, the underlying data formats are exposed at I/O boundaries (network input and output, and passing data to and from plugins) to allow applications to minimize unnecessary format transformations.
Refer to the I/O Formats section for more details.
2.7. Dynamic Shapes
TensorRT creates an optimized engine for each profile, choosing CUDA kernels that work for all shapes within the [minimum, maximum] range and are fastest for the optimization point - typically different kernels for each profile. You can then select among profiles at runtime.
Refer to the Working with Dynamic Shapes chapter for more details.
2.8. DLA
Refer to the Working with DLA chapter for more details.
2.9. Updating Weights
Refer to the Refitting an Engine section for more details.
2.10. trtexec Tool
- benchmarking networks on random or user-provided input data.
- generating serialized engines from models.
- generating a serialized timing cache from the builder.
Refer to the trtexec section for more details.
2.11. Polygraphy
- Run inference among multiple backends, like TensorRT and ONNX-Runtime, and compare results (for example API,CLI).
- Convert models to various formats, for example, TensorRT engines with post-training quantization (for example API,CLI).
- View information about various types of models (for example CLI)
- Modify ONNX models on the command line:
- Isolate faulty tactics in TensorRT (for example CLI).
For more details, refer to the Polygraphy repository.
3. The C++ API
#include “NvInfer.h” using namespace nvinfer1;
Interface classes in the TensorRT C++ API begin with the prefix I, for example ILogger, IBuilder, and so on.
A CUDA context is automatically created the first time TensorRT makes a call to CUDA, if none exists before that point. It is generally preferable to create and configure the CUDA context yourself before the first call to TensorRT.
In order to illustrate object lifetimes, code in this chapter does not use smart pointers; however, their use is recommended with TensorRT interfaces.
3.1. The Build Phase
class Logger : public ILogger
{
void log(Severity severity, const char* msg) noexcept override
{
// suppress info-level messages
if (severity <= Severity::kWARNING)
std::cout << msg << std::endl;
}
} logger;
IBuilder* builder = createInferBuilder(logger);
3.1.1. Creating a Network Definition
uint32_t flag = 1U << static_cast<uint32_t>
(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
INetworkDefinition* network = builder->createNetworkV2(flag);
The kEXPLICIT_BATCH flag is required in order to import models using the ONNX parser. Refer to the Explicit Versus Implicit Batch section for more information.
3.1.2. Importing a Model Using the ONNX Parser
#include “NvOnnxParser.h” using namespace nvonnxparser;
IParser* parser = createParser(*network, logger);
parser->parseFromFile(modelFile,
static_cast<int32_t>(ILogger::Severity::kWARNING));
for (int32_t i = 0; i < parser.getNbErrors(); ++i)
{
std::cout << parser->getError(i)->desc() << std::endl;
}
An important aspect of a TensorRT network definition is that it contains pointers to model weights, which are copied into the optimized engine by the builder. Since the network was created using the parser, the parser owns the memory occupied by the weights, and so the parser object should not be deleted until after the builder has run.
3.1.3. Building an Engine
IBuilderConfig* config = builder->createBuilderConfig();
config->setMemoryPoolLimit(MemoryPoolType::kWORKSPACE, 1U << 20);
IHostMemory* serializedModel = builder->buildSerializedNetwork(*network, *config);
delete parser; delete network; delete config; delete builder;
delete serializedModel
Since building engines is intended as an offline process, it can take significant time. Refer to the Optimizing Builder Performance section for how to make the builder run faster.
3.2. Deserializing a Plan
3.3. Performing Inference
IExecutionContext *context = engine->createExecutionContext();
An engine can have multiple execution contexts, allowing one set of weights to be used for multiple overlapping inference tasks. (A current exception to this is when using dynamic shapes, when each optimization profile can only have one execution context, unless the preview feature, kPROFILE_SHARING_0806, is specified.)
context->setTensorAddress(INPUT_NAME, inputBuffer); context->setTensorAddress(OUTPUT_NAME, outputBuffer);
context->enqueueV3(stream);
A network will be executed asynchronously or not depending on the structure and features of the network. A non-exhaustive list of features that can cause synchronous behavior are data dependent shapes, DLA usage, loops, and plugins that are synchronous, for example. It is common to enqueue data transfers with cudaMemcpyAsync() before and after the kernels to move data from the GPU if it is not already there.
To determine when the kernels (and possibly cudaMemcpyAsync()) are complete, use standard CUDA synchronization mechanisms such as events or waiting on the stream.
4. The Python API
import tensorrt as trt
4.1. The Build Phase
logger = trt.Logger(trt.Logger.WARNING)
class MyLogger(trt.ILogger):
def __init__(self):
trt.ILogger.__init__(self)
def log(self, severity, msg):
pass # Your custom logging implementation here
logger = MyLogger()
builder = trt.Builder(logger)
Since building engines is intended as an offline process, it can take significant time. Refer to the Optimizing Builder Performance section for how to make the builder run faster.
4.1.1. Creating a Network Definition in Python
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
The EXPLICIT_BATCH flag is required in order to import models using the ONNX parser. Refer to the Explicit Versus Implicit Batch section for more information.
4.1.2. Importing a Model Using the ONNX Parser
parser = trt.OnnxParser(network, logger)
success = parser.parse_from_file(model_path)
for idx in range(parser.num_errors):
print(parser.get_error(idx))
if not success:
pass # Error handling code here
4.1.3. Building an Engine
config = builder.create_builder_config()
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 20) # 1 MiB
serialized_engine = builder.build_serialized_network(network, config)
with open(“sample.engine”, “wb”) as f:
f.write(serialized_engine)
4.2. Deserializing a Plan
runtime = trt.Runtime(logger)
engine = runtime.deserialize_cuda_engine(serialized_engine)
with open(“sample.engine”, “rb”) as f:
serialized_engine = f.read()
4.3. Performing Inference
context = engine.create_execution_context()
An engine can have multiple execution contexts, allowing one set of weights to be used for multiple overlapping inference tasks. (A current exception to this is when using dynamic shapes, when each optimization profile can only have one execution context, unless the preview feature, PROFILE_SHARING_0806, is specified.)
context.set_tensor_address(name, ptr)
Several Python packages allow you to allocate memory on the GPU, including, but not limited to, the official CUDA Python bindings, PyTorch, cuPy, and Numba.
After populating the input buffer, you can call TensorRT’s execute_async_v3 method to start inference using a CUDA stream. A network will be executed asynchronously or not depending on the structure and features of the network. A non-exhaustive list of features that can cause synchronous behavior are data dependent shapes, DLA usage, loops, and plugins that are synchronous, for example.
First, create the CUDA stream. If you already have a CUDA stream, you can use a pointer to the existing stream. For example, for PyTorch CUDA streams, that is, torch.cuda.Stream(), you can access the pointer using the cuda_stream property; for Polygraphy CUDA streams, use the ptr attribute; or you can create a stream using CUDA Python binding directly by calling cudaStreamCreate().
context.execute_async_v3(buffers, stream_ptr)
It is common to enqueue asynchronous transfers (cudaMemcpyAsync()) before and after the kernels to move data from the GPU if it is not already there.
To determine when inference (and asynchronous transfers) are complete, use the standard CUDA synchronization mechanisms such as events or waiting on the stream. For example, with PyTorch CUDA streams or Polygraphy CUDA streams, issue stream.synchronize(). With streams created with CUDA Python binding, issue cudaStreamSynchronize(stream).
5. How TensorRT Works
5.1. Object Lifetimes
An important exception to this rule is creating an engine from a builder. After you have created an engine, you may destroy the builder, network, parser, and build config and continue using the engine.
5.2. Error Handling and Logging
An API call to an object will use the logger associated with the corresponding top-level interface. For example, in a call to ExecutionContext::enqueueV3(), the execution context was created from an engine, which was created from a runtime, so TensorRT will use the logger associated with that runtime.
The primary method of error handling is the ErrorRecorder interface. You can implement this interface, and attach it to an API object to receive errors associated with that object. The recorder for an object will also be passed to any others it creates - for example, if you attach an error recorder to an engine, and create an execution context from that engine, it will use the same recorder. If you then attach a new error recorder to the execution context, it will receive only errors coming from that context. If an error is generated but no error recorder is found, it will be emitted through the associated logger.
Note that CUDA errors are generally asynchronous - so when performing multiple inferences or other streams of CUDA work asynchronously in a single CUDA context, an asynchronous GPU error may be observed in a different execution context than the one that generated it.
5.3. Memory
5.3.1. The Build Phase
Even with relatively little workspace however, timing requires creating buffers for input, output, and weights. TensorRT is robust against the operating system (OS) returning out-of-memory for such allocations. On some platforms the OS may successfully provide memory, which then the out-of-memory killer process observes that the system is low on memory, and kills TensorRT. If this happens free up as much system memory as possible before retrying.
During the build phase, there will typically be at least two copies of the weights in host memory: those from the original network, and those included as part of the engine as it is built. In addition, when TensorRT combines weights (for example convolution with batch normalization) additional temporary weight tensors will be created.
5.3.2. The Runtime Phase
An engine, on deserialization, allocates device memory to store the model weights. Since the serialized engine is almost all weights, its size is a good approximation to the amount of device memory the weights require.
You may optionally create an execution context without scratch memory using ICudaEngine::createExecutionContextWithoutDeviceMemory() and provide that memory yourself for the duration of network execution. This allows you to share it between multiple contexts that are not running concurrently, or for other uses while inference is not running. The amount of scratch memory required is returned by ICudaEngine::getDeviceMemorySize().
[08/12/2021-17:39:11] [I] [TRT] Total Host Persistent Memory: 106528 [08/12/2021-17:39:11] [I] [TRT] Total Device Persistent Memory: 29785600 [08/12/2021-17:39:11] [I] [TRT] Total Scratch Memory: 9970688
By default, TensorRT allocates device memory directly from CUDA. However, you can attach an implementation of TensorRT’s IGpuAllocator interface to the builder or runtime and manage device memory yourself. This is useful if your application wants to control all GPU memory and suballocate to TensorRT instead of having TensorRT allocate directly from CUDA.
TensorRT’s dependencies (NVIDIA cuDNN and NVIDIA cuBLAS) can occupy large amounts of device memory. TensorRT allows you to control whether these libraries are used for inference by using the TacticSources attribute in the builder configuration. Note that some plugin implementations require these libraries, so that when they are excluded, the network may not be compiled successfully.
In addition, PreviewFeature::kDISABLE_EXTERNAL_TACTIC_SOURCES_FOR_CORE_0805 is used to control the usage of cuDNN, cuBLAS, and cuBLASLt in the TensorRT core library. When this flag is set, the TensorRT core library will not use these tactics even if they are specified by IBuilderConfig::setTacticSources(). This flag will not affect the cudnnContext and cublasContext handles passed to the plugins using IPluginV2Ext::attachToContext() if the appropriate tactic sources are set. This flag is set by default.
The CUDA infrastructure and TensorRT’s device code also consume device memory. The amount of memory varies by platform, device, and TensorRT version. You can use cudaGetMemInfo to determine the total amount of device memory in use.
[MemUsageChange] Init CUDA: CPU +535, GPU +0, now: CPU 547, GPU 1293 (MiB)
CUDA Lazy Loading
5.3.4. L2 Persistent Cache Management
Cache allocation is per-execution context, enabled using the context’s setPersistentCacheLimit method. The total persistent cache among all contexts (and other components using this feature) should not exceed cudaDeviceProp::persistingL2CacheMaxSize. Refer to the NVIDIA CUDA Best Practices Guide for more information.
5.4. Threading
The expected runtime concurrency model is that different threads will operate on different execution contexts. The context contains the state of the network (activation values, and so on) during execution, so using a context concurrently in different threads results in undefined behavior.
- Nonmodifying operations on a runtime or engine.
- Deserializing an engine from a TensorRT runtime.
- Creating an execution context from an engine.
- Registering and deregistering plugins.
There are no thread-safety issues with using multiple builders in different threads; however, the builder uses timing to determine the fastest kernel for the parameters provided, and using multiple builders with the same GPU will perturb the timing and TensorRT’s ability to construct optimal engines. There are no such issues using multiple threads to build with different GPUs.
5.5. Determinism
In general, different implementations will use a different order of floating point operations, resulting in small differences in the output. The impact of these differences on the final result is usually very small. However, when TensorRT is configured to optimize by tuning over multiple precisions, the difference between an FP16 and an FP32 kernel can be more significant, particularly if the network has not been well regularized or is otherwise sensitive to numerical drift.
Other configuration options that can result in a different kernel selection are different input sizes (for example, batch size) or a different optimization point for an input profile (refer to the Working with Dynamic Shapes section).
The AlgorithmSelector interface allows you to force the builder to pick a particular implementation for a given layer. You can use this to ensure that the same kernels are picked by the builder from run to run. For more information, refer to the Algorithm Selection and Reproducible Builds section.
After an engine has been built, except for IFillLayer, it is deterministic: providing the same input in the same runtime environment will produce the same output.
5.5.1. IFillLayer Determinism
5.6. Runtime Options
The lean runtime contains fewer operator implementations than the default runtime. Since TensorRT chooses operator implementations at build time, you need to specify that the engine should be built for the lean runtime by enabling version compatibility. It may be slightly slower than an engine built for the default runtime.
The lean runtime contains all the functionality of the dispatch runtime, and the default runtime contains all the functionality of the lean runtime.
- tensorrt
- A Python package. It is the Python interface for the default runtime.
- tensorrt_lean
- A Python package. It is the Python interface for the lean runtime.
- tensorrt_dispatch
- A Python package. It is the Python interface for the dispatch runtime.
Python applications that run TensorRT engines should import one of the above packages to load the appropriate library for their use case.
5.7. Compatibility
6. Advanced Topics
6.1. Version Compatibility
Version compatibility is supported from version 8.6; that is, the plan must be built with a version at least 8.6 or higher, and the runtime must be 8.6 or higher.
When using version compatibility, the API supported at runtime for an engine is the intersection of the API supported in the version with which it was built, and the API of the version used to run it. TensorRT removes APIs only on major version boundaries so this is not a concern within a major version. However, users wishing to use TensorRT 8 engines with TensorRT 9 must migrate away from deprecated APIs.
- C++
builderConfig.setFlag(BuilderFlag::kVERSION_COMPATIBLE); IHostMemory* plan = builder->buildSerializedNetwork(network, config);
- Python
builder_config.set_flag(tensorrt.BuilderFlag.VERSION_COMPATIBLE) plan = builder.build_serialized_network(network, config)
This flag is not supported with implicit batch mode. The network must be created with NetworkDefinitionCreationFlag::kEXPLICIT_BATCH.
- C++
runtime->setEngineHostCodeAllowed(true);
- Python
runtime.engine_host_code_allowed = True
The flag for trusted plans is also required if you are packaging plugins in the plan (refer to Plugin Shared Libraries).
6.1.1. Manually Loading the Runtime
- C++
builderConfig.setFlag(BuilderFlag::kVERSION_COMPATIBLE); builderConfig.setFlag(BuilderFlag::kEXCLUDE_LEAN_RUNTIME); IHostMemory* plan = builder->buildSerializedNetwork(network, config);
- Python
builder_config.set_flag(tensorrt.BuilderFlag.VERSION_COMPATIBLE) builder_config.set_flag(tensorrt.BuilderFlag.EXCLUDE_LEAN_RUNTIME) plan = builder.build_serialized_network(network, config)
- C++
IRuntime* v9Runtime = createInferRuntime(logger); IRuntime* v8ShimRuntime = v9Runtime->loadRuntime(v8RuntimePath); engine = v8ShimRuntime->deserializeCudaEngine(v8plan);
- Python
v9_runtime = tensorrt.Runtime(logger) v8_shim_runtime = v9_runtime.load_runtime(v8_runtime_path) engine = v8_shim_runtime.deserialize_cuda_engine(v8_plan)
The runtime will translate TensorRT 9 API calls for the TensorRT 8.6 runtime, checking to ensure that the call is supported and performing any necessary parameter remapping.
6.1.2. Loading from Storage
6.1.3. Using Version Compatibility with the ONNX Parser
- C++
auto *parser = nvonnxparser::createParser(network, logger); parser->setFlag(nvonnxparser::OnnxParserFlag::kNATIVE_INSTANCENORM);
- Python
parser = trt.OnnxParser(network, logger) parser.set_flag(trt.OnnxParserFlag.NATIVE_INSTANCENORM)
In addition, the parser may require the use of plugins in order to fully implement all ONNX operators used in the network. In particular, if the network is used to build a version-compatible engine, some plugins may need to be included with the engine (either serialized with the engine, or provided externally and loaded explicitly).
- C++
auto *parser = nvonnxparser::createParser(network, logger); parser->setFlag(nvonnxparser::OnnxParserFlag::kNATIVE_INSTANCENORM); parser->parseFromFile(filename, static_cast<int>(ILogger::Severity::kINFO)); int64_t nbPluginLibs; char const* const* pluginLibs = parser->getUsedVCPluginLibraries(nbPluginLibs);
- Python
parser = trt.OnnxParser(network, logger) parser.set_flag(trt.OnnxParserFlag.NATIVE_INSTANCENORM) status = parser.parse_from_file(filename) plugin_libs = parser.get_used_vc_plugin_libraries()
Refer to Plugin Shared Libraries, for how to use the resulting library list to serialize the plugins or package them externally.
6.2. Hardware Compatibility
config->setHardwareCompatibilityLevel(nvinfer1::HardwareCompatibilityLevel::kAMPERE_PLUS);
When building in hardware compatibility mode, TensorRT excludes tactics that are not hardware compatible, such as those that use architecture-specific instructions or require more shared memory than is available on some devices. Thus, a hardware-compatible engine may have lower throughput and/or higher latency than its non-hardware-compatible counterpart. The degree of this performance impact depends on the network architecture and input sizes.
6.3. Compatibility Checks
TensorRT also records the compute capability (major and minor versions) in the plan, and checks it against the GPU on which the plan is being loaded. If they do not match, the plan will fail to deserialize. This ensures that kernels selected during the build phase are present and can run. When using hardware compatibility, the check is relaxed; with HardwareCompatibilityLevel::kAMPERE_PLUS, the check will ensure that the compute capability is greater than or equal to 8.0 rather than checking for an exact match.
- Global memory bus width
- L2 cache size
- Maximum shared memory per block and per multiprocessor
- Texture alignment requirement
- Number of multiprocessors
- Whether the GPU device is integrated or discrete
If GPU clock speeds differ between engine serialization and runtime systems, the chosen tactics from the serialization system may not be optimal for the runtime system and may incur some performance degradation.
If the device memory available during deserialization is smaller than the amount during serialization, deserialization may fail due to memory allocation failures.
If optimizing a single TensorRT engine for use on multiple devices in the same architecture, the recommended approach is to run the builder on the smallest device. Alternatively, you can build the engine on the larger device with limited compute resources (refer to the Limiting Compute Resources section). This is because when building small models on large devices, TensorRT may choose kernels that are less efficient but scale better across the available resources. In addition, the APIs that TensorRT uses to select and configure kernels from cuDNN and cuBLAS do not support cross-device compatibility, so disable the use of these tactic sources in the builder configuration.
The safety runtime is able to deserialize engines generated in an environment where the major, minor, patch, and build version of TensorRT does not match exactly in some cases. Refer to the NVIDIA DRIVE OS 6.0 Developer Guide for more information.
6.4. Refitting an Engine
... config->setFlag(BuilderFlag::kREFIT) builder->buildSerializedNetwork(network, config);
ICudaEngine* engine = ...; IRefitter* refitter = createInferRefitter(*engine,gLogger)
Weights newWeights = ...;
refitter->setWeights("MyLayer",WeightsRole::kKERNEL,
newWeights);
The new weights should have the same count as the original weights used to build the engine. setWeights returns false if something went wrong, such as a wrong layer name or role or a change in the weights count.
Because of the way the engine is optimized, if you change some weights, you might have to supply some other weights too. The interface can tell you what additional weights must be supplied.
Weights newWeights = ...;
refitter->setNamedWeights("MyWeights", newWeights);
setNamedWeights and setWeights can be used at the same time, that is, you can update weights with names using setNamedWeights and update those unnamed weights using setWeights.
const int32_t n = refitter->getMissing(0, nullptr, nullptr);
std::vector<const char*> layerNames(n);
std::vector<WeightsRole> weightsRoles(n);
refitter->getMissing(n, layerNames.data(),
weightsRoles.data());
const int32_t n = refitter->getMissingWeights(0, nullptr); std::vector<const char*> weightsNames(n); refitter->getMissingWeights(n, weightsNames.data());
for (int32_t i = 0; i < n; ++i)
refitter->setWeights(layerNames[i], weightsRoles[i],
Weights{...});
The set of missing weights returned is complete, in the sense that supplying only the missing weights does not generate a need for any more weights.
bool success = refitter->refitCudaEngine(); assert(success);
If refit returns false, check the log for a diagnostic, perhaps about weights that are still missing.
delete refitter;
The updated engine behaves as if it had been built from a network updated with the new weights.
To view all refittable weights in an engine, use refitter->getAll(...) or refitter->getAllWeights(...); similarly to how getMissing and getMissingWeights were used previously.
6.5. Algorithm Selection and Reproducible Builds
Sometimes it is important to have a deterministic build, or to recreate the algorithm choices of an earlier build. By providing an implementation of the IAlgorithmSelector interface and attaching it to a builder configuration with setAlgorithmSelector, you can guide algorithm selection manually.
The method IAlgorithmSelector::selectAlgorithms receives an AlgorithmContext containing information about the algorithm requirements for a layer, and a set of Algorithm choices meeting those requirements. It returns the set of algorithms which TensorRT should consider for the layer.
The builder selects from these algorithms the one that minimizes the global runtime for the network. If no choice is returned and BuilderFlag::kREJECT_EMPTY_ALGORITHMS is unset, TensorRT interprets this to mean that any algorithm may be used for this layer. To override this behavior and generate an error if an empty list is returned, set the BuilderFlag::kREJECT_EMPTY_ALGORITHMSS flag.
After TensorRT has finished optimizing the network for a given profile, it calls reportAlgorithms, which can be used to record the final choice made for each layer.
To build a TensorRT engine deterministically, return a single choice from selectAlgorithms. To replay choices from an earlier build, use reportAlgorithms to record the choices in that build, and return them in selectAlgorithms.
- The notion of a "layer" in algorithm selection is different from ILayer in INetworkDefinition. The "layer" in the former can be equivalent to a collection of multiple network layers due to fusion optimizations.
- Picking the fastest algorithm in selectAlgorithms may not produce the best performance for the overall network, as it may increase reformatting overhead.
- The timing of an IAlgorithm is 0 in selectAlgorithms if TensorRT found that layer to be a no-op.
- reportAlgorithms does not provide the timing and workspace information for an IAlgorithm that are provided to selectAlgorithms.
6.6. Creating a Network Definition from Scratch
The following examples create a simple network with Input, Convolution, Pooling, MatrixMultiply, Shuffle, Activation, and SoftMax layers.
For more information regarding layers, refer to the NVIDIA TensorRT Operator’s Reference.
6.6.1. C++
auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));
const auto explicitBatchFlag = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatchFlag));
Refer to the Explicit Versus Implicit Batch section for more information about the kEXPLICIT_BATCH flag.
auto data = network->addInput(INPUT_BLOB_NAME, datatype, Dims4{1, 1, INPUT_H, INPUT_W});auto conv1 = network->addConvolution(
*data->getOutput(0), 20, DimsHW{5, 5}, weightMap["conv1filter"], weightMap["conv1bias"]);
conv1->setStride(DimsHW{1, 1});
auto pool1 = network->addPooling(*conv1->getOutput(0), PoolingType::kMAX, DimsHW{2, 2});
pool1->setStride(DimsHW{2, 2});
int32_t const batch = input->getDimensions().d[0];
int32_t const mmInputs = input.getDimensions().d[1] * input.getDimensions().d[2] * input.getDimensions().d[3];
auto inputReshape = network->addShuffle(*input);
inputReshape->setReshapeDimensions(Dims{2, {batch, mmInputs}});
IConstantLayer* filterConst = network->addConstant(Dims{2, {nbOutputs, mmInputs}}, mWeightMap["ip1filter"]);
auto mm = network->addMatrixMultiply(*inputReshape->getOutput(0), MatrixOperation::kNONE, *filterConst->getOutput(0), MatrixOperation::kTRANSPOSE);
auto biasConst = network->addConstant(Dims{2, {1, nbOutputs}}, mWeightMap["ip1bias"]);
auto biasAdd = network->addElementWise(*mm->getOutput(0), *biasConst->getOutput(0), ElementWiseOperation::kSUM);
auto relu1 = network->addActivation(*ip1->getOutput(0), ActivationType::kRELU);
auto prob = network->addSoftMax(*relu1->getOutput(0));
prob->getOutput(0)->setName(OUTPUT_BLOB_NAME);
network->markOutput(*prob->getOutput(0));
The network representing the MNIST model has now been fully constructed. Refer to sections Building an Engine and Deserializing a Plan for how to build an engine and run inference with this network.
6.6.2. Python
class ModelData(object):
INPUT_NAME = "data"
INPUT_SHAPE = (1, 1, 28, 28)
OUTPUT_NAME = "prob"
OUTPUT_SIZE = 10
DTYPE = trt.float32
weights = mnist_model.get_weights()
TRT_LOGGER = trt.Logger(trt.Logger.ERROR) builder = trt.Builder(TRT_LOGGER) EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH) network = builder.create_network(EXPLICIT_BATCH)
Refer to the Explicit Versus Implicit Batch section for more information about the kEXPLICIT_BATCH flag.
input_tensor = network.add_input(name=ModelData.INPUT_NAME, dtype=ModelData.DTYPE, shape=ModelData.INPUT_SHAPE)
conv1_w = weights['conv1.weight'].numpy()
conv1_b = weights['conv1.bias'].numpy()
conv1 = network.add_convolution(input=input_tensor, num_output_maps=20, kernel_shape=(5, 5), kernel=conv1_w, bias=conv1_b)
conv1.stride = (1, 1)
pool1 = network.add_pooling(input=conv1.get_output(0), type=trt.PoolingType.MAX, window_size=(2, 2))
pool1.stride = (2, 2)
conv2_w = weights['conv2.weight'].numpy()
conv2_b = weights['conv2.bias'].numpy()
conv2 = network.add_convolution(pool1.get_output(0), 50, (5, 5), conv2_w, conv2_b)
conv2.stride = (1, 1)
pool2 = network.add_pooling(conv2.get_output(0), trt.PoolingType.MAX, (2, 2))
pool2.stride = (2, 2)
batch = input.shape[0] mm_inputs = np.prod(input.shape[1:]) input_reshape = net.add_shuffle(input) input_reshape.reshape_dims = trt.Dims2(batch, mm_inputs)
filter_const = net.add_constant(trt.Dims2(nbOutputs, k), weights["fc1.weight"].numpy()) mm = net.add_matrix_multiply(input_reshape.get_output(0), trt.MatrixOperation.NONE, filter_const.get_output(0), trt.MatrixOperation.TRANSPOSE);
bias_const = net.add_constant(trt.Dims2(1, nbOutputs), weights["fc1.bias"].numpy()) bias_add = net.add_elementwise(mm.get_output(0), bias_const.get_output(0), trt.ElementWiseOperation.SUM)
relu1 = network.add_activation(input=fc1.get_output(0), type=trt.ActivationType.RELU)
fc2_w = weights['fc2.weight'].numpy()
fc2_b = weights['fc2.bias'].numpy()
fc2 = network.add_fully_connected(relu1.get_output(0), ModelData.OUTPUT_SIZE, fc2_w, fc2_b)
fc2.get_output(0).name = ModelData.OUTPUT_NAME
network.mark_output(tensor=fc2.get_output(0))
The network representing the MNIST model has now been fully constructed. Refer to sections Building an Engine and Performing Inference for how to build an engine and run inference with this network.
6.7. Reduced Precision
6.7.1. Network-Level Control of Precision
- C++
if (builder->platformHasFastFp16()) { … };- Python
if builder.platform_has_fp16:
- C++
config->setFlag(BuilderFlag::kFP16);
- Python
config.set_flag(trt.BuilderFlag.FP16)
There are three precision flags: FP16, INT8, and TF32, and they may be enabled independently. Note that TensorRT will still choose a higher-precision kernel if it results in overall lower runtime, or if no low-precision implementation exists.
When TensorRT chooses a precision for a layer, it automatically converts weights as necessary to run the layer.
While using FP16 and TF32 precisions is relatively straightforward, there is additional complexity when working with INT8. Refer to the Working with INT8 chapter for more details.
Note that even if the precision flags are enabled, the input/output bindings of the engine defaults to FP32. Refer to the I/O Formats section about how to set the data types and formats of the input/output bindings.
6.7.2. Layer-Level Control of Precision
- C++
layer->setPrecision(DataType::kFP16)
- Python
layer.precision = trt.fp16
This provides a preferred type (here, DataType::kFP16) for the inputs and outputs.
- C++
layer->setOutputType(out_tensor_index, DataType::kFLOAT)
- Python
layer.set_output_type(out_tensor_index, trt.fp32)
The computation will use the same floating-point type as is preferred for the inputs. Most TensorRT implementations have the same floating-point types for input and output; however, Convolution, Deconvolution, and FullyConnected can support quantized INT8 input and unquantized FP16 or FP32 output, as sometimes working with higher-precision outputs from quantized inputs is necessary to preserve accuracy.
Setting the precision constraint hints to TensorRT that it should select a layer implementation whose inputs and outputs match the preferred types, inserting reformat operations if the outputs of the previous layer and the inputs to the next layer do not match the requested types. Note that TensorRT will only be able to select an implementation with these types if they are also enabled using the flags in the builder configuration.
- C++
config->setFlag(BuilderFlag::kPREFER_PRECISION_CONSTRAINTS)
- Python
config.set_flag(trt.BuilderFlag.PREFER_PRECISION_CONSTRAINTS)
If the constraints are preferred, TensorRT obeys them unless there is no implementation with the preferred precision constraints, in which case it issues a warning and uses the fastest available implementation.
- C++
config->setFlag(BuilderFlag::kOBEY_PRECISION_CONSTRAINTS);
- Python
config.set_flag(trt.BuilderFlag.OBEY_PRECISION_CONSTRAINTS);
sampleINT8API illustrates the use of reduced precision with these APIs.
Precision constraints are optional - you can query to determine whether a constraint has been set using layer->precisionIsSet() in C++ or layer.precision_is_set in Python. If a precision constraint is not set, then the result returned from layer->getPrecision() in C++, or reading the precision attribute in Python, is not meaningful. Output type constraints are similarly optional.
If no constraints are set using ILayer::setPrecision or ILayer::setOutputType API, then BuilderFlag::kPREFER_PRECISION_CONSTRAINTS or BuilderFlag::kOBEY_PRECISION_CONSTRAINTS are ignored. A layer is free to choose from any precision or output types based on allowed builder precisions.
Note that the ITensor::setType() API does not set the precision constraint of a tensor, unless it is one of the input/output tensors of the network. Also, there is a distinction between layer->setOutputType() and layer->getOutput(i)->setType(). The former, is an optional type that constrains the implementation that TensorRT will choose for a layer. The latter, specifies the type of a network input/output and is ignored if the tensor is not a network input/output. If they are different, TensorRT will insert a cast to ensure that both specifications are respected. Thus if you are calling setOutputType() for a layer that produces a network output, you should in general also configure the corresponding network output to have the same type.
6.7.3. TF32
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models that require an HDR (high dynamic range) for weights or activations.
- C++
config->clearFlag(BuilderFlag::kTF32);
- Python
config.clear_flag(trt.BuilderFlag.TF32)
6.8. I/O Formats
You can assemble an optimal data pipeline by profiling the available I/O formats in combination with the formats most efficient for the operations preceding and following TensorRT.
To specify I/O formats, you specify one or more formats in the form of a bitmask.
- C++
auto formats = 1U << TensorFormat::kHWC8; network->getInput(0)->setAllowedFormats(formats); network->getInput(0)->setType(DataType::kHALF);
- Python
formats = 1 << int(tensorrt.TensorFormat.HWC8) network.get_input(0).allowed_formats = formats network.get_input(0).dtype = tensorrt.DataType.HALF
Note that calling setAllowedFormats() or setType() on a tensor that is not a network input/output, has no effect and is ignored by TensorRT.
- The resulting engine might be slower than if TensorRT had been allowed to insert reformatting. Reformatting may sound like wasted work, but it can allow coupling of the most efficient kernels.
- The build will fail if TensorRT cannot build an engine without introducing such reformatting. The failure may happen only for some target platforms, because of what formats are supported by kernels for those platforms.
The flag exists for the sake of users who want full control over whether reformatting happens at I/O boundaries, such as to build engines that run solely on DLA without falling back to the GPU for reformatting.
sampleIOFormats illustrates how to specify I/O formats using C++.
| Format | kINT32 | kFLOAT | kHALF | kINT8 |
|---|---|---|---|---|
| kLINEAR | Only for GPU | Supported | Supported | Supported |
| kCHW2 | Not Applicable | Not Applicable | Only for GPU | Not Applicable |
| kCHW4 | Not Applicable | Not Applicable | Supported | Supported |
| kHWC8 | Not Applicable | Not Applicable | Only for GPU | Not Applicable |
| kCHW16 | Not Applicable | Not Applicable | Supported | Not Applicable |
| kCHW32 | Not Applicable | Only for GPU | Only for GPU | Supported |
| kDHWC8 | Not Applicable | Not Applicable | Only for GPU | Not Applicable |
| kCDHW32 | Not Applicable | Not Applicable | Only for GPU | Only for GPU |
| kHWC | Not Applicable | Only for GPU | Not Applicable | Not Applicable |
| kDLA_LINEAR | Not Applicable | Not Applicable | Only for DLA | Only for DLA |
| kDLA_HWC4 | Not Applicable | Not Applicable | Only for DLA | Only for DLA |
| kHWC16 | Not Applicable | Not Applicable | Only for NVIDIA Ampere Architecture GPUs and later | Not Applicable |
| kDHWC | Not Applicable | Only for GPU | Not Applicable | Not Applicable |
Note that for the vectorized formats, the channel dimension must be zero-padded to the multiple of the vector size. For example, if an input binding has dimensions of [16,3,224,224], kHALF data type, and kHWC8 format, then the actual-required size of the binding buffer would be 16*8*224*224*sizeof(half) bytes, even though the engine->getBindingDimension() API will return tensor dimensions as [16,3,224,224]. The values in the padded part (that is, where C=3,4,…,7 in this example) must be filled with zeros.
Refer to Data Format Descriptions for how the data are actually laid out in memory for these formats.
6.9. Explicit Versus Implicit Batch
In implicit batch mode, every tensor has an implicit batch dimension and all other dimensions must have constant length. This mode was used by early versions of TensorRT, and is now deprecated but continues to be supported for backwards compatibility.
In explicit batch mode, all dimensions are explicit and can be dynamic, that is their length can change at execution time. Many new features, such as dynamic shapes and loops, are available only in this mode. It is also required by the ONNX parser.
- In explicit batch mode, the network specifies [N,3,H,W].
- In implicit batch mode, the network specifies only [3,H,W]. The batch dimension N is implicit.
- reducing across the batch dimension
- reshaping the batch dimension
- transposing the batch dimension with another dimension
The exception is that a tensor can be broadcast across the entire batch, through the ITensor::setBroadcastAcrossBatch method for network inputs, and implicit broadcasting for other tensors.
Explicit batch mode erases the limitations - the batch axis is axis 0. A more accurate term for explicit batch would be "batch oblivious," because in this mode, TensorRT attaches no special semantic meaning to the leading axis, except as required by specific operations. Indeed in explicit batch mode there might not even be a batch dimension (such as a network that handles only a single image) or there might be multiple batch dimensions of unrelated lengths (such as comparison of all possible pairs drawn from two batches).
IBuilder* builder = ...; INetworkDefinition* network = builder->createNetworkV2(1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH)))
For implicit batch, use createNetwork or pass a 0 to createNetworkV2.
builder = trt.Builder(...) builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
For implicit batch, omit the argument or pass a 0.
6.10. Sparsity
For each output channel and for each spatial pixel in the kernel weights, every four input channels must have at least two zeros. In other words, assuming that the kernel weights have the shape [K, C, R, S] and C % 4 == 0, then the requirement is verified using the following algorithm:
hasSparseWeights = True
for k in range(0, K):
for r in range(0, R):
for s in range(0, S):
for c_packed in range(0, C // 4):
if numpy.count_nonzero(weights[k, c_packed*4:(c_packed+1)*4, r, s]) > 2 :
hasSparseWeights = False
- C++
config->setFlag(BuilderFlag::kSPARSE_WEIGHTS); config->setFlag(BuilderFlag::kFP16); config->setFlag(BuilderFlag::kINT8);
- Python
config.set_flag(trt.BuilderFlag.SPARSE_WEIGHTS) config.set_flag(trt.BuilderFlag.FP16) config.set_flag(trt.BuilderFlag.INT8)
[03/23/2021-00:14:05] [I] [TRT] (Sparsity) Layers eligible for sparse math: conv1, conv2, conv3 [03/23/2021-00:14:05] [I] [TRT] (Sparsity) TRT inference plan picked sparse implementation for layers: conv2, conv3
Forcing kernel weights to have structured sparsity patterns can lead to accuracy loss. To recover lost accuracy with further fine-tuning, refer to the Automatic SParsity tool in PyTorch.
To measure inference performance with structured sparsity using trtexec, refer to the trtexec section.
6.11. Empty Tensors
For example, when concatenating two tensors with dimensions [x,y,z] and [x,y,w] along the last axis, the result has dimensions [x,y,z+w], regardless of whether x, y, z, or w is zero.
Implicit broadcast rules remain unchanged since only unit-length dimensions are special for broadcast. For example, given two tensors with dimensions [1,y,z] and [x,1,z], their sum computed by IElementWiseLayer has dimensions [x,y,z], regardless of whether x, y, or z is zero.
If an engine binding is an empty tensor, it still needs a non-null memory address, and different tensors should have different addresses. This is consistent with the C++ rule that every object has a unique address, for example, new float[0] returns a non-null pointer. If using a memory allocator that might return a null pointer for zero bytes, ask for at least one byte instead.
Refer to the NVIDIA TensorRT Operator's Reference for any per-layer special handling of empty tensors.
6.12. Reusing Input Buffers
- C++
context->setInputConsumedEvent(&inputReady);
- Python
context.set_input_consumed_event(inputReady)
6.13. Engine Inspector
- C++
auto inspector = std::unique_ptr<IEngineInspector>(engine->createEngineInspector()); inspector->setExecutionContext(context); // OPTIONAL std::cout << inspector->getLayerInformation(0, LayerInformationFormat::kJSON); // Print the information of the first layer in the engine. std::cout << inspector->getEngineInformation(LayerInformationFormat::kJSON); // Print the information of the entire engine.
- Python
inspector = engine.create_engine_inspector(); inspector.execution_context = context; # OPTIONAL print(inspector.get_layer_information(0, LayerInformationFormat.JSON); # Print the information of the first layer in the engine. print(inspector.get_engine_information(LayerInformationFormat.JSON); # Print the information of the entire engine.
Note that the level of detail in the engine/layer information depends on the ProfilingVerbosity builder config setting when the engine is built. By default, ProfilingVerbosity is set to kLAYER_NAMES_ONLY, so only the layer names will be printed. If ProfilingVerbosity is set to kNONE, then no information will be printed; if it is set to kDETAILED, then detailed information will be printed.
- kLAYER_NAMES_ONLY
"node_of_gpu_0/res4_0_branch2a_1 + node_of_gpu_0/res4_0_branch2a_bn_1 + node_of_gpu_0/res4_0_branch2a_bn_2"
- kDETAILED
{ "Name": "node_of_gpu_0/res4_0_branch2a_1 + node_of_gpu_0/res4_0_branch2a_bn_1 + node_of_gpu_0/res4_0_branch2a_bn_2", "LayerType": "CaskConvolution", "Inputs": [ { "Name": "gpu_0/res3_3_branch2c_bn_3", "Dimensions": [16,512,28,28], "Format/Datatype": "Thirty-two wide channel vectorized row major Int8 format." }], "Outputs": [ { "Name": "gpu_0/res4_0_branch2a_bn_2", "Dimensions": [16,256,28,28], "Format/Datatype": "Thirty-two wide channel vectorized row major Int8 format." }], "ParameterType": "Convolution", "Kernel": [1,1], "PaddingMode": "kEXPLICIT_ROUND_DOWN", "PrePadding": [0,0], "PostPadding": [0,0], "Stride": [1,1], "Dilation": [1,1], "OutMaps": 256, "Groups": 1, "Weights": {"Type": "Int8", "Count": 131072}, "Bias": {"Type": "Float", "Count": 256}, "AllowSparse": 0, "Activation": "RELU", "HasBias": 1, "HasReLU": 1, "TacticName": "sm80_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize256x128x64_stage4_warpsize4x2x1_g1_tensor16x8x32_simple_t1r1s1_epifadd", "TacticValue": "0x11bde0e1d9f2f35d" }
In addition, when the engine is built with dynamic shapes, the dynamic dimensions in the engine information will be shown as -1 and the tensor format information will not be shown because these fields depend on the actual shape at inference phase. To get the engine information for a specific inference shape, create an IExecutionContext, set all the input dimensions to the desired shapes, and then call inspector->setExecutionContext(context). After the context is set, the inspector will print the engine information for the specific shape set in the context.
The trtexec tool provides the --profilingVerbosity, --dumpLayerInfo, and --exportLayerInfo flags that can be used to get the engine information of a given engine. Refer to the trtexec section for more details.
Currently, only binding information and layer information, including the dimensions of the intermediate tensors, precisions, formats, tactic indices, layer types, and layer parameters, are included in the engine information. More information may be added into the engine inspector output as new keys in the output JSON object in future TensorRT versions. More specifications about the keys and the fields in the inspector output will also be provided.
In addition, some subgraphs are handled by a next-generation graph optimizer that is not yet integrated with the engine inspector. Therefore, the layer information within these layers is not currently shown. This will be improved in a future TensorRT version.
6.14. Preview Features
<FEATURE_NAME>_XXYY
Where XX and YY are the TensorRT major and minor versions, respectively, of the TensorRT release which first introduced the feature. The major and minor versions are specified using two digits with leading-zero padding when necessary.
If the semantics of a preview feature change from one TensorRT release to another, the older preview feature is deprecated and the revised feature is assigned a new enumeration value and name.
Deprecated preview features are marked in accordance with the deprecation policy.
For more information about the C++ API, refer to nvinfer1::PreviewFeature, IBuilderConfig::setPreviewFeature, and IBuilderConfig::getPreviewFeature.
The Python API has similar semantics using the PreviewFeature enum and set_preview_feature, and get_preview_feature functions.
7. Working with INT8
7.1. Introduction to Quantization
The quantization scheme includes quantization of activations as well as weights.
The quantization scheme for activations depends on the chosen calibration algorithm to find a scale which best balances rounding error and precision error for specific data.
The quantization scheme for weights is as follows: where and are floating point minimum and maximum values for the weights tensor.
- is quantized value in range [-128,127].
- is a floating point value of the activation.
- is described here.
For DLA on Orin, the quantization scheme is updated to use a different rounding mode: where is described here.
To enable the use of any quantized operations, the INT8 flag must be set in the builder configuration.
7.1.1. Quantization Workflows
Post-training quantization (PTQ) derives scale factors after the network has been trained. TensorRT provides a workflow for PTQ, called calibration, where it measures the distribution of activations within each activation tensor as the network executes on representative input data, then uses that distribution to estimate a scale value for the tensor.
Quantization-aware training (QAT) computes scale factors during training. This allows the training process to compensate for the effects of the quantization and dequantization operations.
TensorRT’s Quantization Toolkit is a PyTorch library that helps produce QAT models that can be optimized by TensorRT. You can also use the toolkit’s PTQ recipe to perform PTQ in PyTorch and export to ONNX.
7.1.2. Explicit Versus Implicit Quantization
In implicitly quantized networks, each quantized tensor has an associated scale. When reading and writing the tensor, the scale is used to implicitly quantize and dequantize values.
When processing implicitly quantized networks, TensorRT treats the model as a floating-point model when applying the graph optimizations, and uses INT8 opportunistically to optimize layer execution time. If a layer runs faster in INT8, then it executes in INT8. Otherwise, FP32 or FP16 is used. In this mode, TensorRT is optimizing for performance only, and you have little control over where INT8 is used - even if you explicitly set the precision of a layer at the API level, TensorRT may fuse that layer with another during graph optimization, and lose the information that it must execute in INT8. TensorRT’s PTQ capability generates an implicitly quantized network.
- adding extra conversions could increase layer precision (for example, choosing an FP16 kernel implementation over an INT8 implementation)
- adding extra conversions results in an engine that executes faster (for example, choosing an INT8 kernel implementation to execute a layer specified as having float precision or vice versa)
ONNX uses an explicitly quantized representation - when a model in PyTorch or TensorFlow is exported to ONNX, each fake-quantization operation in the framework’s graph is exported as Q followed by DQ. Since TensorRT preserves the semantics of these layers, you can expect task accuracy very close to that seen in the framework. While optimizations preserve the placement of quantization and dequantization, they may change the order of floating-point operations in the model, so results will not be bitwise identical.
Note that by contrast with TensorRT’s PTQ, performing either QAT or PTQ in a framework and then exporting to ONNX will result in an explicitly quantized model.
For more background on quantization, refer to the Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation paper.
7.1.3. Per-Tensor and Per-Channel Quantization
- Per-tensor quantization: in which a single scale value (scalar) is used to scale the entire tensor.
- Per-channel quantization: in which a scale tensor is broadcast along the given axis - for convolutional neural networks, this is typically the channel axis.
With explicit quantization, weights can be quantized using per-tensor quantization or they can be quantized using per-channel quantization. In either case, the scale precision is FP32. Activation can only be quantized using per-tensor quantization.
For each k in K:singe
For each c in C:
For each r in R:
For each s in S:
output[k,c,r,s] := clamp(round(input[k,c,r,s] / scale[k]))
One exception is deconvolution (also known as transposed convolution), which must be quantized on the input-channel axis.
The scale is a vector of coefficients and must have the same size as the quantization axis. The quantization scale must consist of all positive float coefficients. The rounding method is rounding-to-nearest ties-to-even and clamping is in the range [-128, 127].
output[k,c,r,s] := input[k,c,r,s] * scale[k]
TensorRT supports only per-tensor quantization for activation tensors, but supports per-channel weight quantization for convolution, deconvolution, fully connected layers, and MatMul where the second input is constant and both input matrices are 2D.
7.2. Setting Dynamic Range
The API allows setting the dynamic range for a tensor using minimum and maximum values. Since TensorRT currently supports only symmetric range, the scale is calculated using max(abs(min_float), abs(max_float)). Note that when abs(min_float) != abs(max_float), TensorRT uses a larger dynamic-range than configured, which may increase the rounding error.
Dynamic range is needed for all floating-point inputs and outputs of an operation that will execute in INT8.
- C++
tensor->setDynamicRange(min_float, max_float);
- Python
tensor.dynamic_range = (min_float, max_float)
sampleINT8API illustrates the use of these APIs in C++.
7.3. Post-Training Quantization Using Calibration
The amount of input data required is application-dependent, but experiments indicate that about 500 images are sufficient for calibrating ImageNet classification networks.
Given the statistics for an activation tensor, deciding on the best scale value is not an exact science - it requires balancing two sources of error in the quantized representation: discretization error (which increases as the range represented by each quantized value becomes larger) and truncation error (where values are clamped to the limits of the representable range.) Thus, TensorRT provides multiple different calibrators that calculate the scale in different ways. Older calibrators also performed layer fusion for GPU to optimize away unneeded Tensors before performing calibration. This can be problematic when using DLA, where fusion patterns may be different, and can be overridden using the kCALIBRATE_BEFORE_FUSION quantization flag.
Calibration batch size can also affect the truncation error for IInt8EntropyCalibrator2 and IInt8EntropyCalibrator. For example, calibrating using multiple small batches of calibration data may result in reduced histogram resolution and poor scale value. For each calibration step, TensorRT updates the histogram distribution for each activation tensor. If it encounters a value in the activation tensor, larger than the current histogram max, the histogram range is increased by a power of two to accommodate the new maximum value. This approach works well unless histogram reallocation occurs in the last calibration step, resulting in a final histogram with half the bins empty. Such a histogram can produce poor calibration scales. This also makes calibration susceptible to the order of calibration batches, that is, a different order of calibration batches can result in the histogram size being increased at different points, producing slightly different calibration scales. To avoid this issue, calibrate with as large a single batch as possible, and ensure that calibration batches are well randomized and have similar distribution.
- IInt8EntropyCalibrator2
- Entropy calibration chooses the tensor’s scale factor to optimize the quantized tensor’s information-theoretic content, and usually suppresses outliers in the distribution. This is the current and recommended entropy calibrator and is required for DLA. Calibration happens before Layer fusion by default. Calibration batch size may impact the final result. It is recommended for CNN-based networks.
- IInt8MinMaxCalibrator
- This calibrator uses the entire range of the activation distribution to determine the scale factor. It seems to work better for NLP tasks. Calibration happens before Layer fusion by default. This is recommended for networks such as NVIDIA BERT (an optimized version of Google's official implementation).
- IInt8EntropyCalibrator
- This is the original entropy calibrator. It is less complicated to use than the LegacyCalibrator and typically produces better results. Calibration batch size may impact the final result. Calibration happens after Layer fusion by default.
- IInt8LegacyCalibrator
- This calibrator is for compatibility with TensorRT 2.0 EA. This calibrator requires user parameterization and is provided as a fallback option if the other calibrators yield poor results. Calibration happens after Layer fusion by default. You can customize this calibrator to implement percentile max, for example, 99.99% percentile max is observed to have best accuracy for NVIDIA BERT and NeMo ASR model QuartzNet.
- Build a 32-bit engine, run it on the calibration set, and record a histogram for each tensor of the distribution of activation values.
- Build from the histograms a calibration table providing a scale value for each tensor.
- Build the INT8 engine from the calibration table and the network definition.
Calibration can be slow; therefore the output of step 2 (the calibration table) can be cached and reused. This is useful when building the same network multiple times on a given platform and is supported by all calibrators.
Before running calibration, TensorRT queries the calibrator implementation to see if it has access to a cached table. If so, it proceeds directly to step 3. Cached data is passed as a pointer and length. A sample calibration table can be found here.
The calibration cache data is portable across different devices as long as the calibration happens before layer fusion. Specifically, the calibration cache is portable when using the IInt8EntropyCalibrator2 or IInt8MinMaxCalibrator calibrators, or when QuantizationFlag::kCALIBRATE_BEFORE_FUSION is set. This can simplify the workflow, for example by building the calibration table on a machine with a discrete GPU and then reusing it on an embedded platform. Fusions are not guaranteed to be the same across platforms or devices, so calibrating after layer fusion may not result in a portable calibration cache. The calibration cache is in general not portable across TensorRT releases.
7.3.1. INT8 Calibration Using C++
- First, it queries the interface for the batch size and calls getBatchSize() to determine the size of the input batch to expect.
- Then, it repeatedly calls getBatch() to obtain batches of input. Batches must be exactly the batch size by getBatchSize(). When there are no more batches, getBatch() must return false.
config->setInt8Calibrator(calibrator.get());
To cache the calibration table, implement the writeCalibrationCache() and readCalibrationCache() methods.
7.3.2. Calibration Using Python
- Import TensorRT:
import tensorrt as trt
- Similar to test/validation datasets, use a set of input files as a calibration dataset.
Make sure that the calibration files are representative of the overall inference data
files. For TensorRT to use the calibration files, you must create a
batchstream object. A batchstream object is used to
configure the calibrator.
NUM_IMAGES_PER_BATCH = 5 batchstream = ImageBatchStream(NUM_IMAGES_PER_BATCH, calibration_files)
- Create an Int8_calibrator object with input nodes names and batch
stream:
Int8_calibrator = EntropyCalibrator(["input_node_name"], batchstream)
- Set INT8 mode and INT8 calibrator:
config.set_flag(trt.BuilderFlag.INT8) config.int8_calibrator = Int8_calibrator
7.3.3. Quantization Noise Reduction
The heuristic attempts to ensure that INT8 quantization is smoothed out by summation of multiple quantized values. Layers considered to be "smoothing layers" are convolution, deconvolution, a fully connected layer, or matrix multiplication before reaching the network output. For example, if a network consists of a series of (convolution + activation + shuffle) subgraphs and the network output has type FP32, the last convolution will output FP32 precision, even if INT8 is allowed and faster.
- The network output has type INT8.
- An operation on the path (inclusively) from the last smoothing layer to the output is constrained by ILayer::setOutputType or ILayer::setPrecision to output INT8.
- There is no smoothing layer with a path to the output, or said that path has an intervening plugin layer.
- The network uses explicit quantization.
7.4. Explicit Quantization
config->setFlag(BuilderFlag::kINT8);
In explicit-quantization, network changes of representation to and from INT8 are explicit, therefore, INT8 must not be used as a type constraint.
7.4.1. Quantized Weights
7.4.2. ONNX Support
- PyTorch:
- TensorFlow:
PyTorch weights are therefore transposed by TensorRT. The weights are quantized by TensorRT before they are transposed, so GEMM layers originating from ONNX QAT models that were exported from PyTorch use dimension 0 for per-channel quantization (axis K = 0); while models originating from TensorFlow use dimension 1 (axis K = 1).
7.4.3. TensorRT Processing of Q/DQ Networks
Q/DQ layers control the compute and data precision of a network. An IQuantizeLayer instance converts an FP32 tensor to an INT8 tensor by employing quantization, and an IDequantizeLayer instance converts an INT8 tensor to an FP32 tensor by means of dequantization. TensorRT expects a Q/DQ layer pair on each of the inputs of quantizable-layers. Quantizable-layers are deep-learning layers that can be converted to quantized layers by fusing with IQuantizeLayer and IDequantizeLayer instances. When TensorRT performs these fusions, it replaces the quantizable-layers with quantized layers that actually operate on INT8 data using INT8 compute operations.
For the diagrams used in this chapter, green designates INT8 precision and blue designates floating-point precision. Arrows represent network activation tensors and squares represent network layers.
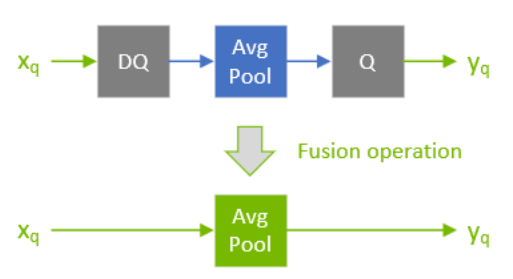
During network optimization, TensorRT moves Q/DQ layers in a process called Q/DQ propagation. The goal in propagation is to maximize the proportion of the graph that can be processed at low precision. Thus, TensorRT propagates Q nodes backwards (so that quantization happens as early as possible) and DQ nodes forward (so that dequantization happens as late as possible). Q-layers can swap places with layers that commute-with-Quantization and DQ-layers can swap places with layers that commute-with-Dequantization.
A layer commutes with quantization if
Similarly, a layer commutes with dequantization if
The following diagram illustrates DQ forward-propagation and Q backward-propagation. These are legal rewrites of the model because Max Pooling has an INT8 implementation and because Max Pooling commutes with DQ and with Q.
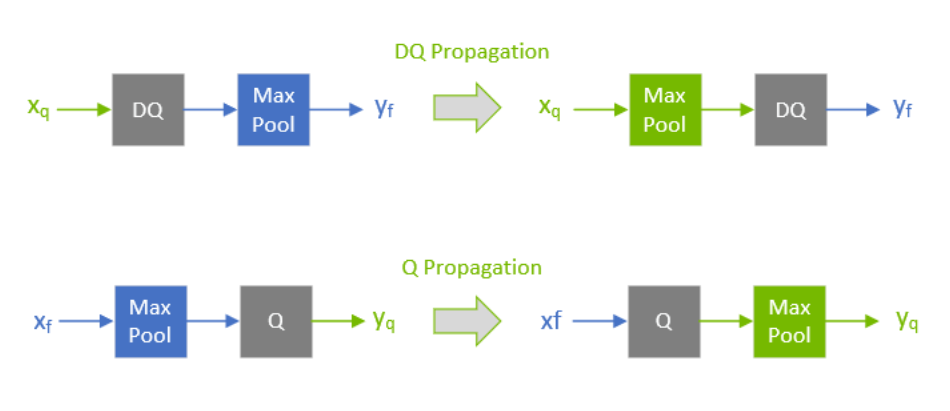
To understand Max Pooling commutation, let us look at the output of the
maximum-pooling operation applied to some arbitrary input. Max Pooling is
applied to groups of input coefficients and outputs the coefficient with the
maximum value. For group i composed of coefficients:
:
It is therefore enough to look at two arbitrary coefficients without loss of
generality (WLOG):
For quantization function
, with
, note that (without providing proof, and using simplified notation):
Therefore:
However, by definition:
Function commutes-with-quantization and so does Max Pooling.
Similarly for dequantization, function
with
we can show that:
There is a distinction between how quantizable-layers and commuting-layers are processed. Both types of layers can compute in INT8, but quantizable-layers also fuse with DQ input layers and a Q output layer. For example, an AveragePooling layer (quantizable) does not commute with either Q or DQ, so it is quantized using Q/DQ fusion as illustrated in the first diagram. This is in contrast to how Max Pooling (commuting) is quantized.
7.4.4. Q/DQ Layer-Placement Recommendations
Quantize all inputs of weighted-operations (Convolution, Transposed Convolution, and GEMM). Quantization of the weights and activations reduces bandwidth requirements and also enables INT8 computation to accelerate bandwidth-limited and compute-limited layers.
SM 7.5 and earlier devices may not have INT8 implementations for all layers. In this case, you will encounter a could not find any implementation error while building your engine. To resolve this, remove the Q/DQ nodes which quantize the failing layers.
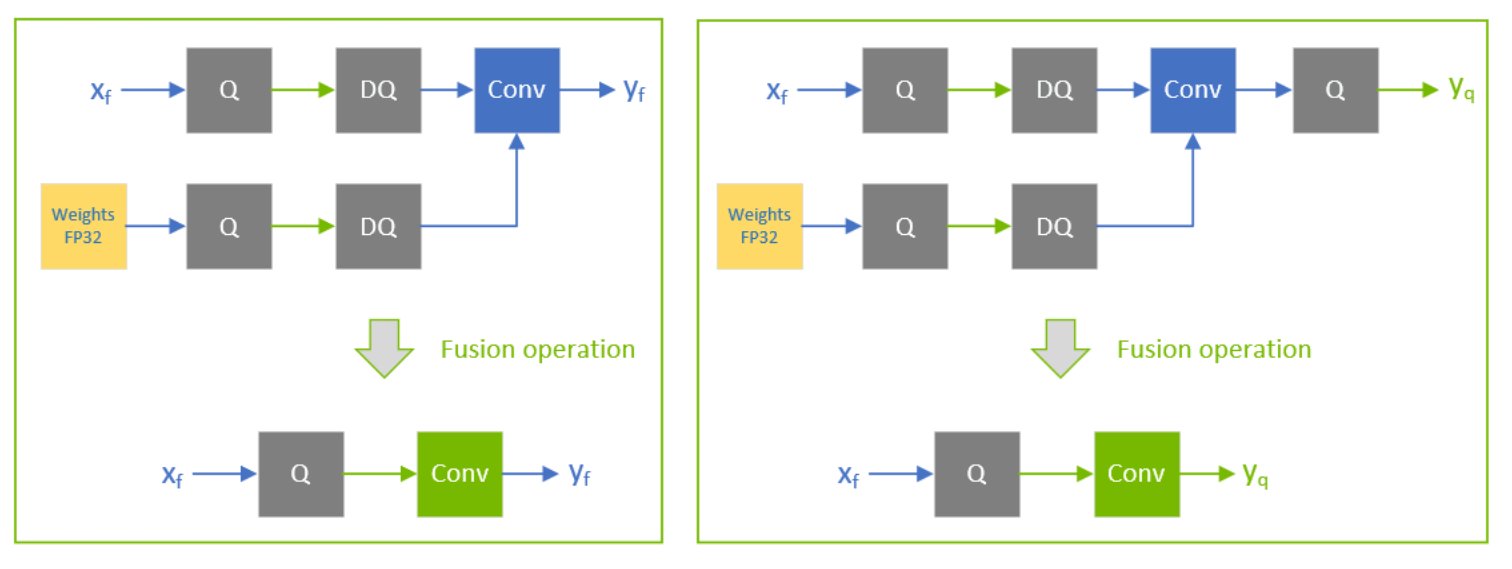
By default, do not quantize the outputs of weighted-operations. It is sometimes useful to preserve the higher-precision dequantized output. For example, if the linear operation is followed by an activation function (SiLU, in the following diagram) that requires higher precision input to produce acceptable accuracy.
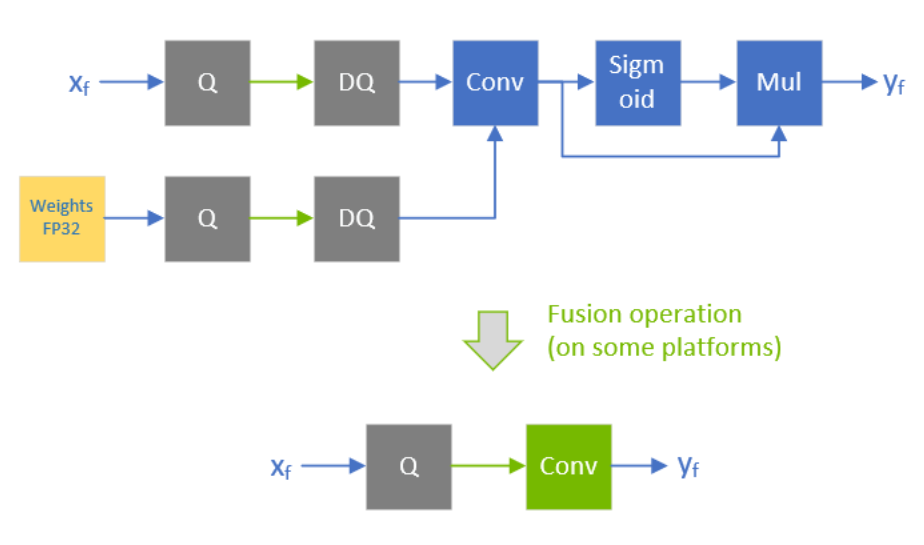
Do not simulate batch-normalization and ReLU fusions in the training framework because TensorRT optimizations guarantee to preserve the arithmetic semantics of these operations.
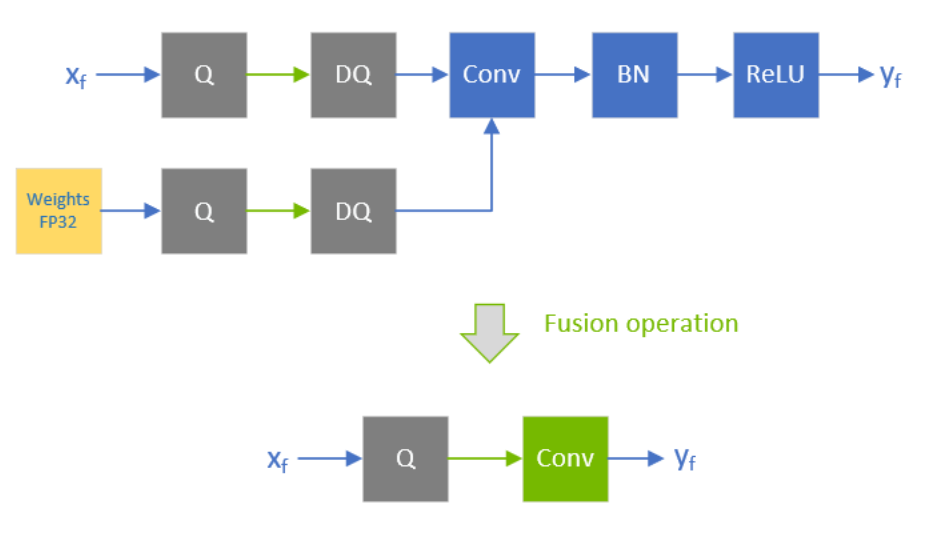
Quantize the residual input in skip-connections. TensorRT can fuse element-wise addition following weighted layers, which are useful for models with skip connections like ResNet and EfficientNet. The precision of the first input to the element-wise addition layer determines the precision of the output of the fusion.
For example, in the following diagram, the precision of xf1 is floating point, so the output of the fused convolution is limited to floating-point, and the trailing Q-layer cannot be fused with the convolution.
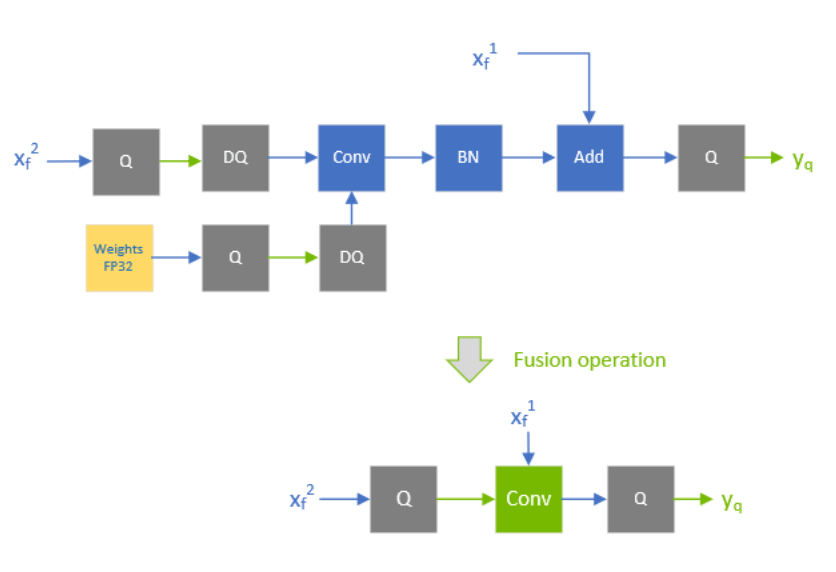
In contrast, when xf1 is quantized to INT8, as depicted in the following diagram, the output of the fused convolution is also INT8, and the trailing Q-layer is fused with the convolution.
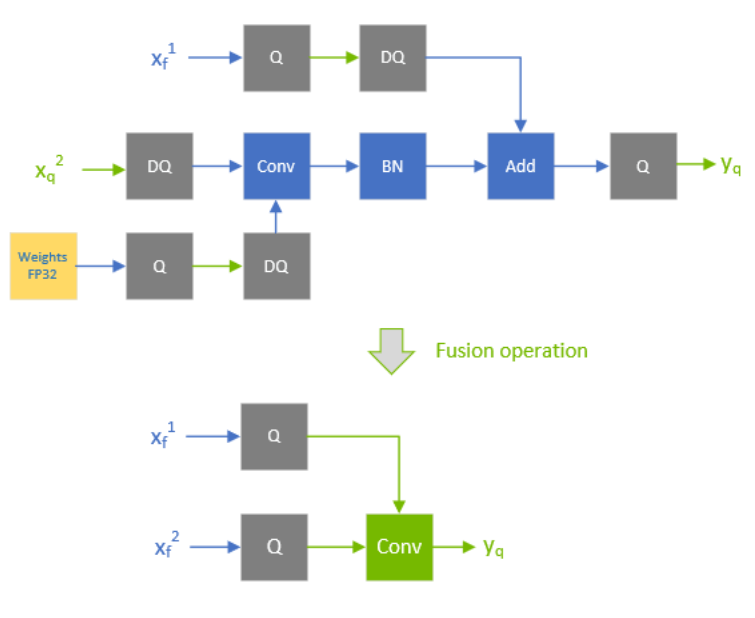
For extra performance, try quantizing layers that do not commute with Q/DQ. Currently, non-weighted layers that have INT8 inputs also require INT8 outputs, so quantize both inputs and outputs.
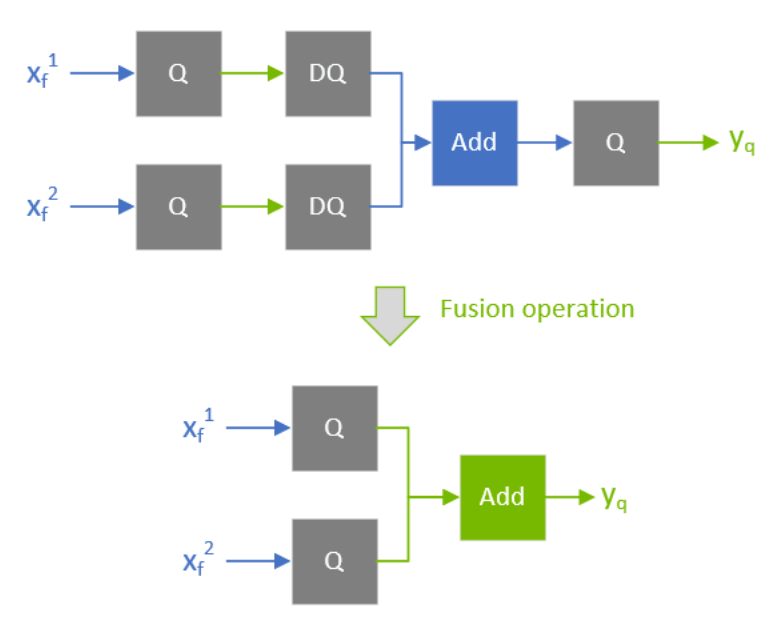
Performance can decrease if TensorRT cannot fuse the operations with the surrounding Q/DQ layers, so be conservative when adding Q/DQ nodes and experiment with accuracy and TensorRT performance in mind.
The following figure is an example of suboptimal fusions (the highlighted light green background rectangles) that can result from extra Q/DQ operations. Contrast the following figure with Figure 7, which shows a more performant configuration. The convolution is fused separately from the element-wise addition because each of them is surrounded by Q/DQ pairs. The fusion of the element-wise addition is shown in Figure 8.
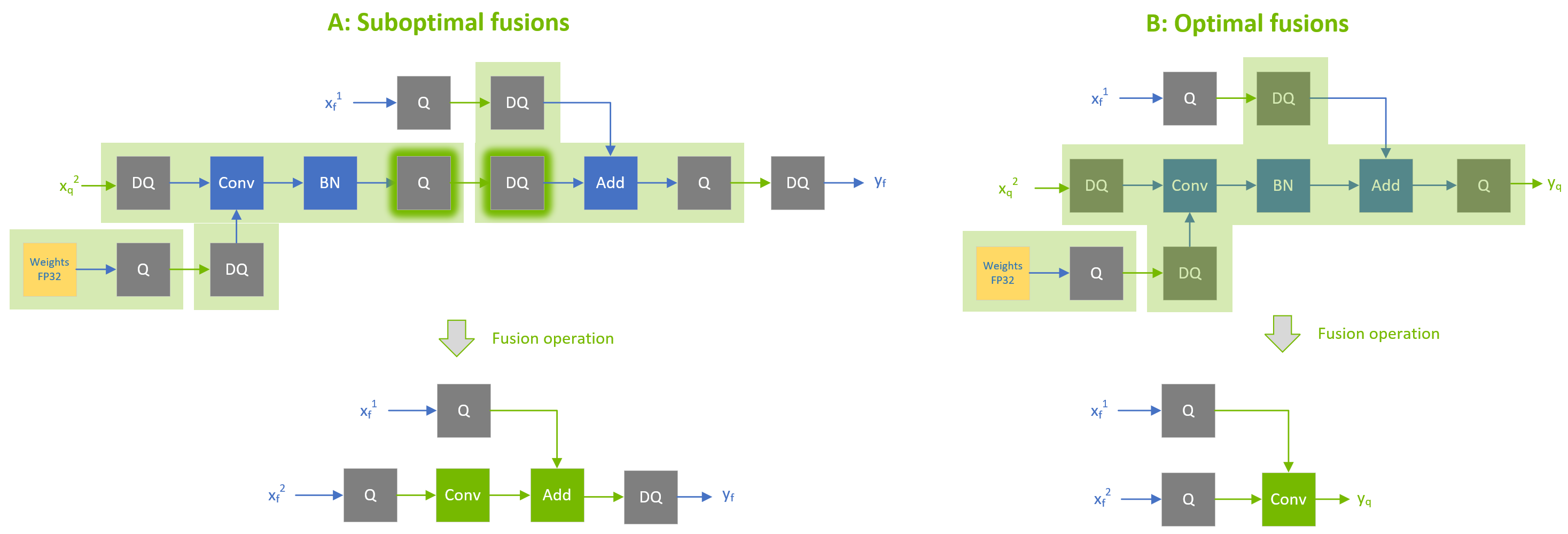
Use per-tensor quantization for activations; and per-channel quantization for weights. This configuration has been demonstrated empirically to lead to the best quantization accuracy.
You can further optimize engine latency by enabling FP16. TensorRT attempts to use FP16 instead of FP32 whenever possible (this is not currently supported for all layer types).
7.4.5. Q/DQ Limitations
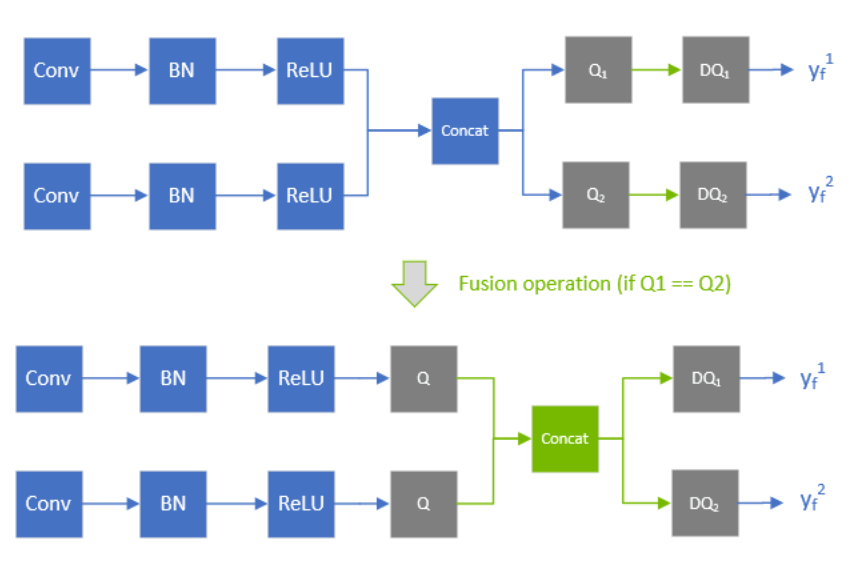
7.4.6. Q/DQ Interaction with Plugins
The same follows for a TensorRT network with Q/DQ layers: when a plugin consumes quantized INT8 inputs and generates quantized INT8 outputs, the input DQ and output Q nodes must be included as part of the plugin and removed from the network.
Input > Q -> DQ > Conv > Q -> DQ_i > MyInt8Plugin > Q_o -> DQ > Conv > OutputThe > arrows indicate activation tensors with FP32 precision and the -> arrows indicate INT8 precision.
Input > Q -> [DQ → Conv → Q] -> DQ_i > MyInt8Plugin > Q_o -> [DQ → Conv] > OutputInput > Q -> DQ > Conv > Q -> MyInt8Plugin -> DQ > Conv > OutputInput > Q -> [DQ → Conv → Q] > MyInt8Plugin -> [DQ → Conv] > OutputWhen "manually fusing" DQ_i, you take the input quantization scale and give it to your plugin, so it will know how to dequantize (if needed) the input. The same follows for using the scale from Q_o in order to quantize your plugin’s output.
7.4.7. QAT Networks Using TensorFlow
TensorFlow 1 does not support per-channel quantization (PCQ). PCQ is recommended for weights in order to preserve the accuracy of the model.
7.4.8. QAT Networks Using PyTorch
7.5. INT8 Rounding Modes
| Backend | Compute Kernel Quantization (FP32 to INT8) | Weights Quantization (FP32 to INT8) | |
|---|---|---|---|
| Quantized Network (QAT) | Dynamic Range API / Calibration | ||
| GPU | round-to-nearest-with-ties-to-even | round-to-nearest-with-ties-to-even | round-to-nearest-with-ties-to-positive-infinity |
| DLA | round-to-nearest-with-ties-away-from-zero | Not Applicable | round-to-nearest-with-ties-away-from-zero |
8. Working with Dynamic Shapes
The following sections provide greater detail; however, here is an overview of the steps for building an engine with dynamic shapes:
- The network definition must not have an implicit batch dimension.
- C++
- Create the INetworkDefinition by calling
IBuilder::createNetworkV2(1U << static_cast<int>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH)) - Python
- Create the tensorrt.INetworkDefinition by calling
create_network(1 << int(tensorrt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
- Specify each runtime dimension of an input tensor by using -1 as a placeholder for the dimension.
- Specify one or more optimization profiles at build time that specify the permitted range of dimensions for inputs with runtime dimensions, and the dimensions for which the auto-tuner will optimize. For more information, refer to Optimization Profiles.
- To use the engine:
- Create an execution context from the engine, the same as without dynamic shapes.
- Specify one of the optimization profiles from step 3 that covers the input dimensions.
- Specify the input dimensions for the execution context. After setting input dimensions, you can get the output dimensions that TensorRT computes for the given input dimensions.
- Enqueue work.
- reduce the engine build time,
- reduce runtime, and
- decrease device memory usage and engine size.
Models most likely to benefit from enabling kFASTER_DYNAMIC_SHAPES_0805 are transformer-based models and models containing dynamic control flows.
8.1. Specifying Runtime Dimensions
- C++
networkDefinition.addInput("foo", DataType::kFLOAT, Dims3(3, -1, -1))- Python
network_definition.add_input("foo", trt.float32, (3, -1, -1))
- C++
context.setInputShape"foo", Dims{3, {3, 150, 250}})- Python
context.set_input_shape("foo", (3, 150, 250))
- C++
- engine.getTensorShape("foo") returns a Dims with dimensions {3, -1, -1}..
- Python
- engine.get_tensor_shape("foo") returns (3, -1, -1).
- C++
- context.getTensorShape("foo") returns a Dims with dimensions {3, 150, 250}.
- Python
- context.get_tensor_shape(0) returns (3, 150, 250).
nvinfer1::Dims outDims = context->getTensorShape("bar");
if (outDims.nbDims == -1) {
gLogError << "Invalid network output, this might be caused by inconsistent input shapes." << std::endl;
// abort inference
}
If a dimension k is data-dependent, for example, it depends on the output of INonZeroLayer, outDims.d[k] will be -1. For more information, refer to Dynamically Shaped Output for how to deal with such outputs.
8.2. Named Dimensions
- For runtime dimensions, error messages use the dimension's name. For example, if an input tensor foo has dimensions [n,10,m], it is more helpful to get an error message about m instead of (#2 (SHAPE foo)).
- Dimensions with the same name are implicitly equal, which can help the optimizer generate a more efficient engine, and diagnoses mismatched dimensions at runtime. For example, if two inputs have dimensions [n,10,m] and [n,13], the optimizer knows the lead dimensions are always equal, and accidentally use of the engine with mismatched values for n will be reported as an error.
You can use the same name for both constant and runtime dimensions as long as they are always equal at runtime.
- C++
tensor.setDimensionName(2, "m")
- Python
tensor.set_dimension_name(2, "m")
- C++
tensor.getDimensionName(2) // returns the name of the third dimension of tensor, or nullptr if it does not have a name.
- Python
tensor.get_dimension_name(2) # returns the name of the third dimension of tensor, or None if it does not have a name.
When the input network is imported from an ONNX file, the ONNX parser automatically sets the dimension names using the names in the ONNX file. Therefore, if two dynamic dimensions are expected to be equal at runtime, specify the same name for these dimensions when exporting the ONNX file.
8.3. Dimension Constraint using IAssertionLayer
- Give the dimensions the same name, as described in Named Dimensions.
- Use IAssertionLayer to express the constraint. This technique is more general since it can convey trickier equalities.
- C++
// Assumes A and B are ITensor* and n is a INetworkDefinition&. auto shapeA = n.addShape(*A)->getOutput(0); auto firstDimOfA = n.addSlice(*shapeA, Dims{1, {0}}, Dims{1, {1}}, Dims{1, {1}})->getOutput(0); auto shapeB = n.addShape(*B)->getOutput(0); auto firstDimOfB = n.addSlice(*shapeB, Dims{1, {0}}, Dims{1, {1}}, Dims{1, {1}})->getOutput(0); static int32_t const oneStorage{1}; auto one = n.addConstant(Dims{1, {1}}, Weights{DataType::kINT32, &oneStorage, 1})->getOutput(0); auto firstDimOfBPlus1 = n.addElementWise(*firstDimOfB, *one, ElementWiseOperation::kSUM)->getOutput(0); auto areEqual = n.addElementWise(*firstDimOfA, *firstDimOfBPlus1, ElementWiseOperation::kEQUAL)->getOutput(0); n.addAssertion(*areEqual, "oops");- Python
# Assumes `a` and `b` are ITensors and `n` is an INetworkDefinition shape_a = n.add_shape(a).get_output(0) first_dim_of_a = n.add_slice(shape_a, (0, ), (1, ), (1, )).get_output(0) shape_b = n.add_shape(b).get_output(0) first_dim_of_b = n.add_slice(shape_b, (0, ), (1, ), (1, )).get_output(0) one = n.add_constant((1, ), np.ones((1, ), dtype=np.int32)).get_output(0) first_dim_of_b_plus_1 = n.add_elementwise(first_dim_of_b, one, trt.ElementWiseOperation.SUM).get_output(0) are_equal = n.add_elementwise(first_dim_of_a, first_dim_of_b_plus_1, trt.ElementWiseOperation.EQUAL).get_output(0) n.add_assertion(are_equal, “oops”)
If the dimensions violate the assertion at runtime, TensorRT will throw an error.
8.4. Optimization Profiles
- C++
IOptimizationProfile* profile = builder.createOptimizationProfile(); profile->setDimensions("foo", OptProfileSelector::kMIN, Dims3(3,100,200); profile->setDimensions("foo", OptProfileSelector::kOPT, Dims3(3,150,250); profile->setDimensions("foo", OptProfileSelector::kMAX, Dims3(3,200,300); config->addOptimizationProfile(profile)- Python
profile = builder.create_optimization_profile(); profile.set_shape("foo", (3, 100, 200), (3, 150, 250), (3, 200, 300)) config.add_optimization_profile(profile)
At runtime, you must set an optimization profile before setting input dimensions. Profiles are numbered in the order that they were added, starting at 0. Note that each execution context must use a separate optimization profile.
- C++
- call context.setOptimizationProfileAsync(0, stream)
where stream is the CUDA stream that is used for the subsequent enqueue(), enqueueV2(), or enqueueV3() invocation in this context.
- Python
- set context.set_optimization_profile_async(0, stream)
If the associated CUDA engine has dynamic inputs, the optimization profile must be set at least once with a unique profile index that is not used by other execution contexts that are not destroyed. For the first execution context that is created for an engine, profile 0 is chosen implicitly.
setOptimizationProfileAsync() can be called to switch between profiles. It must be called after any enqueue(), enqueueV2(), or enqueueV3() operations finish in the current context. When multiple execution contexts run concurrently, it is allowed to switch to a profile that was formerly used but already released by another execution context with different dynamic input dimensions.
setOptimizationProfileAsync() function replaces the now deprecated version of the API setOptimizationProfile(). Using setOptimizationProfile() to switch between optimization profiles can cause GPU memory copy operations in the subsequent enqueue() or enqueueV2() operations. To avoid these calls during enqueue, use setOptimizationProfileAsync() API instead.
8.5. Dynamically Shaped Output
If the dimensions of the output are computable from the dimensions of inputs, use IExecutionContext::getTensorShape() to get the dimensions of the output, after providing dimensions of the input tensors and Shape Tensor I/O (Advanced). Use the IExecutionContext::inferShapes() method to check if you forgot to supply the necessary information.
class MyOutputAllocator : nvinfer1::IOutputAllocator
{
public:
void* reallocateOutput(
char const* tensorName, void* currentMemory,
uint64_t size, uint64_t alignment) override
{
// Allocate the output. Remember it for later use.
outputPtr = ... depends on strategy, as discussed later...
return outputPtr;
}
void notifyShape(char const* tensorName, Dims const& dims)
{
// Remember output dimensions for later use.
outputDims = dims;
}
// Saved dimensions of the output
Dims outputDims{};
// nullptr if memory could not be allocated
void* outputPtr{nullptr};
};
std::unordered_map<std::string, MyOutputAllocator> allocatorMap;
for (const char* name : names of outputs)
{
Dims extent = context->getTensorShape(name);
void* ptr;
if (engine->getTensorLocation(name) == TensorLocation::kDEVICE)
{
if (extent.d contains a -1)
{
auto allocator = std::make_unique<MyOutputAllocator>();
context->setOutputAllocator(name, allocator.get());
allocatorMap.emplace(name, std::move(allocator));
}
else
{
ptr = allocate device memory per extent and format
}
}
else
{
ptr = allocate cpu memory per extent and format
}
context->setTensorAddress(name, ptr);
}
- A
- Defer allocation until the size is known. Do not call IExecution::setTensorAddress, or call it with a nullptr for the tensor address.
- B
- Preallocate enough memory, based on what IExecutionTensor::getMaxOutputSize reports as an upper bound. That guarantees that the engine will not fail for lack of sufficient output memory, but the upper bound may be so high as to be useless.
- C
- Preallocate enough memory based on experience, use IExecution::setTensorAddress to tell TensorRT about it. Make reallocateOutput return nullptr if the tensor does not fit, which will cause the engine to fail gracefully.
- D
- Preallocate memory as in C, but have reallocateOutput return a pointer to a bigger buffer if there is a fit problem. This increases the output buffer as needed.
- E
- Defer allocation until the size is known, like A. Then, attempt to recycle that allocation in subsequent calls until a bigger buffer is requested, and then increase it like in D.
class FancyOutputAllocator : nvinfer1::IOutputAllocator
{
public:
void reallocateOutput(
char const* tensorName, void* currentMemory,
uint64_t size, uint64_t alignment) override
{
if (size > outputSize)
{
// Need to reallocate
cudaFree(outputPtr);
outputPtr = nullptr;
outputSize = 0;
if (cudaMalloc(&outputPtr, size) == cudaSuccess)
{
outputSize = size;
}
}
// If the cudaMalloc fails, outputPtr=nullptr, and engine
// gracefully fails.
return outputPtr;
}
void notifyShape(char const* tensorName, Dims const& dims)
{
// Remember output dimensions for later use.
outputDims = dims;
}
// Saved dimensions of the output tensor
Dims outputDims{};
// nullptr if memory could not be allocated
void* outputPtr{nullptr};
// Size of allocation pointed to by output
uint64_t outputSize{0};
~FancyOutputAllocator() override
{
cudaFree(outputPtr);
}
};
8.5.1. Looking up Binding Indices for Multiple Optimization Profiles
In an engine built from multiple profiles, there are separate binding indices for each profile. The names of I/O tensors for the Kth profile have [profile K] appended to them, with K written in decimal. For example, if the INetworkDefinition had the name "foo", and bindingIndex refers to that tensor in the optimization profile with index 3, engine.getBindingName(bindingIndex) returns "foo [profile 3]".
Likewise, if using ICudaEngine::getBindingIndex(name) to get the index for a profile K beyond the first profile (K=0), append "[profile K]" to the name used in the INetworkDefinition. For example, if the tensor was called "foo" in the INetworkDefinition, then engine.getBindingIndex("foo [profile 3]") returns the binding index of Tensor "foo" in optimization profile 3.
Always omit the suffix for K=0.
8.5.2. Bindings For Multiple Optimization Profiles
Each row is a profile. Numbers in the table denote binding indices. The first profile has binding indices 0..4, the second has 5..9, and the third has 10..14.
The interfaces have an "auto-correct" for the case that the binding belongs to the first profile, but another profile was specified. In that case, TensorRT warns about the mistake and then chooses the correct binding index from the same column.
For the sake of backward semi-compatibility, the interfaces have an "auto-correct" in the scenario where the binding belongs to the first profile, but another profile was specified. In this case, TensorRT warns about the mistake and then chooses the correct binding index from the same column.
8.6. Layer Extensions For Dynamic Shapes
IShapeLayer outputs a 1D tensor containing the dimensions of the input tensor. For example, if the input tensor has dimensions [2,3,5,7], the output tensor is a four-element 1D tensor containing {2,3,5,7}. If the input tensor is a scalar, it has dimensions [], and the output tensor is a zero-element 1D tensor containing {}.
IResizeLayer accepts an optional second input containing the desired dimensions of the output.
- C++
auto* reshape = networkDefinition.addShuffle(Y); reshape.setInput(1, networkDefintion.addShape(X)->getOutput(0));- Python
reshape = network_definition.add_shuffle(y) reshape.set_input(1, network_definition.add_shape(X).get_output(0))
ISliceLayer accepts an optional second, third, and fourth input containing the start, size, and stride.
IConcatenationLayer, IElementWiseLayer, IGatherLayer, IIdentityLayer, and
IReduceLayercan
be used to do calculations on shapes and create new shape tensors.8.7. Restrictions For Dynamic Shapes
- IConvolutionLayer and IDeconvolutionLayer require that the channel dimension be a build time constant.
- IFullyConnectedLayer requires that the last three dimensions be build-time constants.
- Int8 requires that the channel dimension be a build time constant.
- Layers accepting additional shape inputs (IResizeLayer, IShuffleLayer, ISliceLayer) require that the additional shape inputs be compatible with the dimensions of the minimum and maximum optimization profiles as well as with the dimensions of the runtime data input; otherwise, it can lead to either a build-time or runtime error.
Values that must be build-time constants do not have to be constants at the API level. TensorRT’s shape analyzer does element by element constant propagation through layers that do shape calculations. It is sufficient that the constant propagation discovers that a value is a build time constant.
For more information regarding layers, refer to the NVIDIA TensorRT Operator’s Reference.
8.8. Execution Tensors Versus Shape Tensors
- Compute the shapes of tensors on the CPU until a shape requiring GPU results is reached.
- Stream work to the GPU until out of work or an unknown shape is reached If the latter, synchronize and go back to step 1.
An execution tensor is a traditional TensorRT tensor. A shape tensor is a tensor that is related to shape calculations. It must have type Int32, Float, or Bool, its shape must be determinable at build time, and it must have no more than 64 elements. Refer to Shape Tensor I/O (Advanced) for additional restrictions for shape tensors at network I/O boundaries. For example, there is an IShapeLayer whose output is a 1D tensor containing the dimensions of the input tensor. The output is a shape tensor. IShuffleLayer accepts an optional second input that can specify reshaping dimensions. The second input must be a shape tensor.
Some layers are “polymorphic” with respect to the kinds of tensors that they handle. For example, IElementWiseLayer can sum two INT32 execution tensors or sum two INT32 shape tensors. The type of tensor depends on its ultimate use. If the sum is used to reshape another tensor, then it is a “shape tensor.”
When TensorRT needs a shape tensor, but the tensor has been classified as an execution tensor, the runtime has to copy the tensor from the GPU to the CPU, which incurs synchronization overhead.
8.8.1. Formal Inference Rules
IActivationLayer: E → Esince it takes an execution tensor as an input and an execution tensor as an output. IElementWiseLayer is polymorphic in this respect, with two signatures:
IElementWiseLayer: S × S → S, E × E → E
IElementWiseLayer: t × t → t
IShuffleLayer (two inputs): t × S → t
IConstantLayer: → t
IShapeLayer: t1 → t2
IAssertionLayer: S → IConcatenationLayer: t × t × ...→ t IIfConditionalInputLayer: t → t IIfConditionalOutputLayer: t → t IConstantLayer: → t IActivationLayer: t → t IElementWiseLayer: t × t → t IFillLayer: S → t IFillLayer: S × E × E → E IGatherLayer: t × t → t IIdentityLayer: t → t IReduceLayer: t → t IResizeLayer (one input): E → E IResizeLayer (two inputs): E × S → E ISelectLayer: t × t × t → t IShapeLayer: t1 → t2 IShuffleLayer (one input): t → t IShuffleLayer (two inputs): t × S → t ISliceLayer (one input): t → t ISliceLayer (two inputs): t × S → t ISliceLayer (three inputs): t × S × S → t ISliceLayer (four inputs): t × S × S × S → t IUnaryLayer: t → t all other layers: E × ... → E × ...
Because an output can be the input of more than one subsequent layer, the inferred "types" are not exclusive. For example, an IConstantLayer might feed into one use that requires an execution tensor and another use that requires a shape tensor. The output of IConstantLayer is classified as both and can be used in both phase 1 and phase 2 of the two-phase execution.
The requirement that the size of a shape tensor be known at build time limits how ISliceLayer can be used to manipulate a shape tensor. Specifically, if the third parameter, which specifies the size of the result, and is not a build-time constant, the length of the resulting tensor is unknown at build time, breaking the restriction that shape tensors have constant shapes. The slice will still work, but will incur synchronization overhead at runtime because the tensor is considered an execution tensor that has to be copied back to the CPU to do further shape calculations.
The rank of any tensor has to be known at build time. For example, if the output of ISliceLayer is a 1D tensor of unknown length that is used as the reshape dimensions for IShuffleLayer, the output of the shuffle would have unknown rank at build time, and hence such a composition is prohibited.
TensorRT’s inferences can be inspected using methods ITensor::isShapeTensor(), which returns true for a shape tensor, and ITensor::isExecutionTensor(), which returns true for an execution tensor. Build the entire network first before calling these methods because their answer can change depending on what uses of the tensor have been added.
For example, if a partially built network sums two tensors, T1 and T2, to create tensor T3, and none are yet needed as shape tensors, isShapeTensor() returns false for all three tensors. Setting the second input of IShuffleLayer to T3 would cause all three tensors to become shape tensors because IShuffleLayer requires that its second optional input be a shape tensor, and if the output of IElementWiseLayer is a shape tensor, its inputs are too.
8.9. Shape Tensor I/O (Advanced)
- At build time: the optimization profile values of the shape tensor.
- At run time: the values of the shape tensor.
The shape of an input shape tensor is always known at build time. It is the values that must be described since they can be used to specify the dimensions of execution tensors.
The optimization profile values can be set using IOptimizationProfile::setShapeValues. Analogous to how min, max, and optimization dimensions must be supplied for execution tensors with runtime dimensions, min, max, and optimization values must be provided for shape tensors at build time.
The corresponding runtime method is IExecutionContext::setTensorAddress, which tells TensorRT where to look for the shape tensor values.
Because the inference of “execution tensor” vs “shape tensor” is based on ultimate use, TensorRT cannot infer whether a network output is a shape tensor. You must tell it using the method INetworkDefinition::markOutputForShapes.
Besides letting you output shape information for debugging, this feature is useful for composing engines. For example, consider building three engines, one each for sub-networks A, B, C, where a connection from A to B or B to C might involve a shape tensor. Build the networks in reverse order: C, B, and A. After constructing network C, you can use ITensor::isShapeTensor to determine if an input is a shape tensor, and use INetworkDefinition::markOutputForShapes to mark the corresponding output tensor in network B. Then check which inputs of B are shape tensors and mark the corresponding output tensor in network A.
Shape tensors at network boundaries must have type Int32. They cannot have type Float or Bool. A workaround for Bool is to use Int32 for the I/O tensor, with zeros and ones, and convert to/from Bool using IIdentityLayer.
At runtime, whether a tensor is an I/O shape tensor can be determined via method ICudaEngine::isShapeInferenceIO().
8.10. INT8 Calibration with Dynamic Shapes
- C++
config->setCalibrationProfile(profile)
- Python
config.set_calibration_profile(profile)
The calibration profile must be valid or be nullptr. kMIN and kMAX values are overwritten by kOPT. To check the current calibration profile, use IBuilderConfig::getCalibrationProfile.
9. Extending TensorRT with Custom Layers
TensorRT contains plugins that can be loaded into your application. For a list of open-source plugins, refer to GitHub: TensorRT plugins.
To use TensorRT plugins in your application, the libnvinfer_plugin.so (nvinfer_plugin.dll on Windows) library must be loaded, and all plugins must be registered by calling initLibNvInferPlugins in your application code. For more information about these plugins, refer to the NvInferPlugin.h file for reference.
If these plugins do not meet your needs, you can write and add your own.
9.1. Adding Custom Layers Using the C++ API
| Introduced in TensorRT version? | Mixed I/O formats/types | Dynamic shapes? | Supports implicit/explicit batch mode? | |
|---|---|---|---|---|
| IPluginV2Ext | 5.1 (deprecated since TensorRT 8.5) | Limited | No | Both implicit and explicit batch modes |
| IPluginV2IOExt | 6.0.1 | General | No | Both implicit and explicit batch modes |
| IPluginV2DynamicExt | 6.0.1 | General | Yes | Explicit batch mode only |
In order to use a plugin in a network, you must first register it with TensorRT’s PluginRegistry. Rather than registering the plugin directly, you register an instance of a factory class for the plugin, derived from PluginCreator. The plugin creator class also provides other information about the plugin: its name, version, and plugin field parameters.
- TensorRT provides a macro REGISTER_TENSORRT_PLUGIN that statically registers the plugin creator with the registry. Note that REGISTER_TENSORRT_PLUGIN always registers the creator under the default namespace ("").
- Dynamically register by creating your own entry-point similar to initLibNvInferPlugins and calling registerCreator on the plugin registry. This is preferred over static registration as it offers a potentially lower memory footprint and allows plugins to be registered under a unique namespace. This ensures that there are no name collisions during build time across different plugin libraries.
Calling IPluginCreator::createPlugin() returns a plugin object of type IPluginV2. You can add a plugin to the TensorRT network using addPluginV2(), which creates a network layer with the given plugin.
// Look up the plugin in the registry auto creator = getPluginRegistry()->getPluginCreator(pluginName, pluginVersion); const PluginFieldCollection* pluginFC = creator->getFieldNames(); // Populate the fields parameters for the plugin layer // PluginFieldCollection *pluginData = parseAndFillFields(pluginFC, layerFields); // Create the plugin object using the layerName and the plugin meta data IPluginV2 *pluginObj = creator->createPlugin(layerName, pluginData); // Add the plugin to the TensorRT network auto layer = network.addPluginV2(&inputs[0], int(inputs.size()), pluginObj); … (build rest of the network and serialize engine) // Destroy the plugin object pluginObj->destroy() … (free allocated pluginData)
- Do not serialize all plugin parameters: only those required for the plugin to function correctly at runtime. Build time parameters can be omitted.
- Serialize and deserialize plugin parameters in the same order. During deserialization, verify that plugin parameters are either initialized to a default value or to the deserialized value. Uninitialized parameters result in undefined behavior.
- If you are an automotive safety user, you must call getSafePluginRegistry() instead of getPluginRegistry(). You must also use the REGISTER_SAFE_TENSORRT_PLUGIN macro instead of REGISTER_TENSORRT_PLUGIN.
9.1.1. Example: Adding a Custom Layer with Dynamic Shape Support Using C++
- The first output is a copy of the second input.
- The second output is the concatenation of both inputs, along the first dimension, and all types/formats must be the same and be linear formats.
class BarPlugin : public IPluginV2DynamicExt
{
...override virtual methods inherited from IPluginV2DynamicExt.
};
- getOutputDimensions
- supportsFormatCombination
- configurePlugin
- enqueue
DimsExprs BarPlugin::getOutputDimensions(int outputIndex,
const DimsExprs* inputs, int nbInputs,
IExprBuilder& exprBuilder)
{
switch (outputIndex)
{
case 0:
{
// First dimension of output is sum of input
// first dimensions.
DimsExprs output(inputs[0]);
output.d[0] =
exprBuilder.operation(DimensionOperation::kSUM,
inputs[0].d[0], inputs[1].d[0]);
return output;
}
case 1:
return inputs[0];
default:
throw std::invalid_argument(“invalid output”);
}
The override for supportsFormatCombination must indicate whether a format combination is allowed. The interface indexes the inputs/outputs uniformly as “connections,” starting at 0 for the first input, then the rest of the inputs in order, followed by numbering the outputs. In the example, the inputs are connections 0 and 1, and the outputs are connections 2 and 3.
bool BarPlugin::supportsFormatCombination(int pos, const PluginTensorDesc* inOut, int nbInputs, int nbOutputs) override
{
assert(0 <= pos && pos < 4);
const auto* in = inOut;
const auto* out = inOut + nbInputs;
switch (pos)
{
case 0: return in[0].format == TensorFormat::kLINEAR;
case 1: return in[1].type == in[0].type &&
in[1].format == TensorFormat::kLINEAR;
case 2: return out[0].type == in[0].type &&
out[0].format == TensorFormat::kLINEAR;
case 3: return out[1].type == in[0].type &&
out[1].format == TensorFormat::kLINEAR;
}
throw std::invalid_argument(“invalid connection number”);
}
void BarPlugin::configurePlugin(
const DynamicPluginTensorDesc* in, int nbInputs,
const DynamicPluginTensorDesc* out, int nbOutputs) override
{
}
If the plugin needs to know the minimum or maximum dimensions it might encounter, it can inspect the field DynamicPluginTensorDesc::min or DynamicPluginTensorDesc::max for any input or output. Format and build-time dimension information can be found in DynamicPluginTensorDesc::desc. Any runtime dimensions appear as -1. The actual dimension is supplied to BarPlugin::enqueue.
Finally, the override BarPlugin::enqueue has to do the work. Since shapes are dynamic, enqueue is handed a PluginTensorDesc that describes the actual dimensions, type, and format of each input and output.
9.1.2. Example: Adding a Custom Layer with INT8 I/O Support Using C++
class PoolPlugin : public IPluginV2IOExt
{
...override virtual methods inherited from IPluginV2IOExt.
};
- supportsFormatCombination
- configurePlugin
- enqueue
bool PoolPlugin::supportsFormatCombination(int pos, const PluginTensorDesc* inOut, int nbInputs, int nbOutputs) const override
{
assert(nbInputs == 1 && nbOutputs == 1 && pos < nbInputs + nbOutputs);
bool condition = inOut[pos].format == TensorFormat::kLINEAR;
condition &= ((inOut[pos].type == DataType::kFLOAT) ||
(inOut[pos].type == DataType::kHALF) ||
(inOut[pos].type == DataType::kINT8));
condition &= inOut[pos].type == inOut[0].type;
return condition;
}
- If INT8 calibration must be used with a network with INT8 I/O plugins, the plugin must support FP32 I/O as TensorRT uses FP32 to calibrate the graph.
- If the FP32 I/O variant is not supported or INT8 calibration is not used, all required INT8 I/O tensors scales must be set explicitly.
- Calibration cannot determine the dynamic range of a plugin internal tensor. Plugins that operate on quantized data must calculate their own dynamic range for internal tensors.
void PoolPlugin::configurePlugin(const PluginTensorDesc* in, int nbInput, const PluginTensorDesc* out, int nbOutput)
{
...
mPoolingParams.mC = mInputDims.d[0];
mPoolingParams.mH = mInputDims.d[1];
mPoolingParams.mW = mInputDims.d[2];
mPoolingParams.mP = mOutputDims.d[1];
mPoolingParams.mQ = mOutputDims.d[2];
mInHostScale = in[0].scale >= 0.0F ? in[0].scale : -1.0F;
mOutHostScale = out[0].scale >= 0.0F ? out[0].scale : -1.0F;
}
Where INT8 I/O scales per tensor can be obtained from PluginTensorDesc::scale.
int PoolPlugin::enqueue(int batchSize, const void* const* inputs, void** outputs, void* workspace, cudaStream_t stream)
{
...
CHECK(cudnnPoolingForward(mCudnn, mPoolingDesc, &kONE, mSrcDescriptor, input, &kZERO, mDstDescriptor, output));
...
return 0;
}
9.2. Adding Custom Layers Using the Python API
You can use the C++ API to create a custom layer, package the layer using pybind11 in Python, then load the plugin into a Python application. For more information, refer to Creating a Network Definition in Python.
The same custom layer implementation can be used for both C++ and Python.
9.2.1. Example: Adding a Custom Layer to a TensorRT Network Using Python
import tensorrt as trt
import numpy as np
TRT_LOGGER = trt.Logger()
trt.init_libnvinfer_plugins(TRT_LOGGER, '')
PLUGIN_CREATORS = trt.get_plugin_registry().plugin_creator_list
def get_trt_plugin(plugin_name):
plugin = None
for plugin_creator in PLUGIN_CREATORS:
if plugin_creator.name == plugin_name:
lrelu_slope_field = trt.PluginField("neg_slope", np.array([0.1], dtype=np.float32), trt.PluginFieldType.FLOAT32)
field_collection = trt.PluginFieldCollection([lrelu_slope_field])
plugin = plugin_creator.create_plugin(name=plugin_name, field_collection=field_collection)
return plugin
def main():
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network()
config = builder.create_builder_config()
config.max_workspace_size = 2**20
input_layer = network.add_input(name="input_layer", dtype=trt.float32, shape=(1, 1))
lrelu = network.add_plugin_v2(inputs=[input_layer], plugin=get_trt_plugin("LReLU_TRT"))
lrelu.get_output(0).name = "outputs"
network.mark_output(lrelu.get_output(0))9.3. Using Custom Layers When Importing a Model with a Parser
In some cases, you might want to modify an ONNX graph before importing it into TensorRT. For example, to replace a set of ops with a plugin node. To accomplish this, you can use the ONNX GraphSurgeon utility. For details on how to use ONNX-GraphSurgeon to replace a subgraph, refer to this example.
For more examples, refer to the onnx_packnet sample.
9.4. Plugin API Description
9.4.1. Migrating Plugins from TensorRT 6.x or 7.x to TensorRT 8.x.x
virtual DimsExprs getOutputDimensions(int outputIndex, const DimsExprs* inputs, int nbInputs, IExprBuilder& exprBuilder) = 0; virtual bool supportsFormatCombination(int pos, const PluginTensorDesc* inOut, int nbInputs, int nbOutputs) = 0; virtual void configurePlugin(const DynamicPluginTensorDesc* in, int nbInputs, const DynamicPluginTensorDesc* out, int nbOutputs) = 0; virtual size_t getWorkspaceSize(const PluginTensorDesc* inputs, int nbInputs, const PluginTensorDesc* outputs, int nbOutputs) const = 0; virtual int enqueue(const PluginTensorDesc* inputDesc, const PluginTensorDesc* outputDesc, const void* const* inputs, void* const* outputs, void* workspace, cudaStream_t stream) = 0;
virtual void configurePlugin(const PluginTensorDesc* in, int nbInput, const PluginTensorDesc* out, int nbOutput) = 0; virtual bool supportsFormatCombination(int pos, const PluginTensorDesc* inOut, int nbInputs, int nbOutputs) const = 0;
- getOutputDimensions implements the expression for output tensor dimensions given the inputs.
- supportsFormatCombination checks if the plugin supports the format and datatype for the specified I/O.
- configurePlugin mimics the behavior of equivalent configurePlugin in IPluginV2Ext but accepts tensor descriptors.
- getWorkspaceSize and enqueue mimic the behavior of equivalent APIs in IPluginV2Ext but accept tensor descriptors.
Refer to the API description in IPluginV2 API Description for more details about the API.
9.4.2. IPluginV2 API Description
- Used to specify the number of output tensors.
- Used to specify the dimensions of output as a function of the input dimensions.
- Used to check if a plugin supports a given data format.
- Used to get the data type of the output at a given index. The returned data type must have a format that is supported by the plugin.
- LINEAR single-precision (FP32), half-precision (FP16), integer (INT8), and integer (INT32) tensors
- CHW32 single-precision (FP32) and integer (INT8) tensors
- CHW2, HWC8,HWC16, and DHWC8 half-precision (FP16) tensors
- CHW4 half-precision (FP16), and integer (INT8) tensors
Plugins that do not compute all data in place and need memory space in addition to input and output tensors can specify the additional memory requirements with the getWorkspaceSize method, which is called by the builder to determine and preallocate scratch space.
- Communicates the number of inputs and outputs, dimensions, and datatypes of
all inputs and outputs, broadcast information for all inputs and outputs,
the chosen plugin format, and maximum batch size. At this point, the plugin
sets up its internal state and selects the most appropriate algorithm and
data structures for the given configuration.
Note: Resource allocation is not allowed in this API because it causes a resource leak.
- The configuration is known at this time, and the inference engine is being created, so the plugin can set up its internal data structures and prepare for execution.
- Encapsulates the actual algorithm and kernel calls of the plugin and provides the runtime batch size, pointers to input, output, and scratch space, and the CUDA stream to be used for kernel execution.
- The engine context is destroyed, and all the resources held by the plugin must be released.
- This is called every time a new builder, network, or engine is created that includes this plugin layer. It must return a new plugin object with the correct parameters.
- Used to destroy the plugin object and other memory allocated each time a new plugin object is created. It is called whenever the builder or network or engine is destroyed.
- This method is used to set the library namespace that this plugin object belongs to (default can be ""). All plugin objects from the same plugin library should have the same namespace.
- canBroadcastInputAcrossBatch
- This method is called for each input whose tensor is semantically broadcast across a batch. If canBroadcastInputAcrossBatch returns true (meaning the plugin can support broadcast), TensorRT does not replicate the input tensor. There is a single copy that the plugin should share across the batch. If it returns false, TensorRT replicates the input tensor so that it appears like a nonbroadcasted tensor.
- isOutputBroadcastAcrossBatch
- This is called for each output index. The plugin should return true the output at the given index and is broadcast across the batch.
- IPluginV2IOExt
- This is called by the builder before initialize(). It provides an opportunity for the layer to make algorithm choices on the basis of I/O PluginTensorDesc and the maximum batch size.
9.4.3. IPluginCreator API Description
- This returns the plugin name and should match the return value of IPluginExt::getPluginType.
- Returns the plugin version. For all internal TensorRT plugins, this defaults to 1.
- To successfully create a plugin, it is necessary to know all the field parameters of the plugin. This method returns the PluginFieldCollection struct with the PluginField entries populated to reflect the field name and PluginFieldType (the data should point to nullptr).
- This method is used to create the plugin using the
PluginFieldCollection argument. The data field of the
PluginField entries should be populated to point to the
actual data for each plugin field entry.
Note: The data passed to the createPlugin function should be allocated by the caller and eventually freed by the caller when the program is destroyed. The ownership of the plugin object returned by the createPlugin function is passed to the caller and must be destroyed as well.
- This method is called internally by the TensorRT engine based on the plugin name and version. It should return the plugin object to be used for inference. The plugin object created in this function is destroyed by the TensorRT engine when the engine is destroyed.
- This method is used to set the namespace that this creator instance belongs to (default can be "").
9.5. Best Practices for Custom Layers Plugin
9.5.1. Coding Guidelines for Plugins
Memory Allocation
Memory allocated in the plugin must be freed to ensure no memory leak. If resources are acquired in the initialize() function, they must be released in the terminate() function. All other memory allocations should be freed, preferably in the plugin class destructor or in the destroy() method. Adding Custom Layers Using the C++ API outlines this in detail and also provides some notes for best practices when using plugins.
Add Checks to Ensure Proper Configuration and Validate Inputs
- createPlugin: Plugin attributes checks
- configurePlugin: Input dimension checks
- enqueue: Input value checks
Return Null at Errors for Methods That Creates a New Plugin Object
createPlugin, clone, and deserializePlugin are expected to create and return new plugin objects. In these methods, make sure a null object (nullptr in C++) is returned in case of any error or failed check. This ensures that non-null plugin objects are not returned when the plugin is incorrectly configured.
Avoid Device Memory Allocations in clone()
Since clone is called multiple times in the builder, device memory allocations could be significantly expensive. A good practice is to do persistent memory allocations in initialize, copy to device when the plugin is ready-to-use (for example, in configurePlugin), and release in terminate.
9.5.2. Using Plugins in Implicit/Explicit Batch Networks
- Plugins implementing IPluginV2DynamicExt can only be added to a network configured in explicit batch mode.
- Non-IPluginV2DynamicExt plugins can be added to a network configured in either implicit or explicit batch mode.
- The leading dimension of the first input (before being passed to the plugin) is inferred to be the batch dimension.
- TensorRT pops this first dimension identified above before inputs are passed to the plugin, and pushes it to the front of any outputs emitted by the plugin. This means that the batch dimension must not be specified in getOutputDimensions.
9.5.3. Communicating Shape Tensors to Plugins
For example, suppose a plugin must know a 2-element 1D shape tensor value [P,Q] to calculate the shape of its outputs, for example, to implement IPluginV2DynamicExt::getOutputDimensions. Instead of passing in the shape tensor [P,Q], design the plugin to have a dummy input that is an execution tensor with dimensions [0,P,Q]. TensorRT will tell the plugin dimensions of the dummy input, from which the plugin can extract [P,Q]. Because the tensor is empty, it will occupy a tiny amount of space, just enough to give it a distinct address.
// Shape tensor of interest. Assume it has the value [P,Q].
ITensor* pq = ...;
// Create an empty-tensor constant with dimensions [0,1,1].
// Since it's empty, the type doesn't matter, but let's assume float.
ITensor* c011 = network.addConstant({3, {0, 1, 1}}, {DataType::kFLOAT, nullptr, 0})->getOutput(0);
// Create shape tensor that has the value [0,P,Q]
static int32_t const intZero = 0;
ITensor* z = network.addConstant({1, {1}}, {DataType::kINT32, &intZero, 1})->getOutput(0);
ITensor* concatInputs[] = {z, pq};
IConcatenationLayer* zpq = network.addConcatenation(concatInputs, 2);
zpq->setAxis(0);
// Create zero-stride slice with output size [0,P,Q]
Dims z3{3, {0, 0, 0}};
ISliceLayer* slice = network.addSlice(*c011, z3, z3, z3);
slice->setInput(2, *zpq->getOutput(0));
Use slice->getOutput(0) as the dummy input to the plugin.
If using IShuffleLayer to create the empty tensor, be sure to turn off special interpretation of zeros in the reshape dimensions, that is, be sure to call setZeroIsPlaceholder(false).
9.6. Plugin Shared Libraries
You can explicitly register custom plugins with TensorRT using the REGISTER_TENSORRT_PLUGIN and registerCreator interfaces (refer to Adding Custom Layers Using the C++ API). However, you may want TensorRT to manage registration of a plugin library, and, in particular, serialize plugin libraries with the plan file so they are automatically loaded when the engine is created. This can be especially useful when you want to include the plugins in a version compatible engine, so that you do not need to manage them after building the engine. In order to take advantage of this, you can build shared libraries with specific entry points recognized by TensorRT.
9.6.1. Generating Plugin Shared Libraries
extern "C" void setLoggerFinder(ILoggerFinder& finder); extern "C" IPluginCreator* const* getPluginCreators(int32_t& nbCreators) const;
Note extern "C" above is only used to prevent name mangling, and the methods themselves should be implemented in C++. Consult your compiler's ABI documentation for more details.
setLoggerFinder() should set a global pointer of ILoggerFinder in the library for logging in the plugin code. getPluginCreators()returns a list of plugin creators your library contains. An example of implementation of these entry points can be found in plugin/common/vfcCommon.h/cpp.
To serialize your plugin libraries with your engine plan, provide the plugin libraries paths to TensorRT using setPluginsToSerialize() in BuilderConfig.
When building version compatible engines, you may also want to package plugins in the plan. The packaged plugins will have the same lifetime as the engine and will be automatically registered/deregistered when running the engine.
9.6.2. Using Plugin Shared Libraries
- C++
for (size_t i = 0; i < nbPluginLibs; ++i) { builder->getPluginRegistry().loadLibrary(pluginLibs[i]); }- Python
for plugin_lib in plugin_libs: builder.get_plugin_registry().load_library(plugin_lib)
- C++
IBuilderConfig *config = builder->createBuilderConfig(); ... config->setPluginsToSerialize(pluginLibs, nbPluginLibs);
- Python
config = builder.create_builder_config() ... config.plugins_to_serialize = plugin_libs
- C++
// In this example, getExternalPluginLibs() is a user-implemented method which retrieves the list of libraries to use with the engine std::vector<std::string> pluginLibs = getExternalPluginLibs(); for (auto const &pluginLib : pluginLibs) { runtime->getPluginRegistry().loadLibrary(pluginLib.c_str()) }- Python
# In this example, get_external_plugin_libs() is a user-implemented method which retrieves the list of libraries to use with the engine plugin_libs = get_external_plugin_libs() for plugin_lib in plugin_libs: runtime.get_plugin_registry().load_library(plugin_lib)
10. Working with Loops
10.1. Defining a Loop
- ITripLimitLayer specifies how many times that the loop iterates.
- IIteratorLayer enables a loop to iterate over a tensor.
- IRecurrenceLayer specifies a recurrent definition.
- ILoopOutputLayer specifies an output from the loop.
Each of the boundary layers inherits from class ILoopBoundaryLayer, which has a method getLoop() for getting its associated ILoop. The ILoop object identifies the loop. All loop boundary layers with the same ILoop belong to that loop.
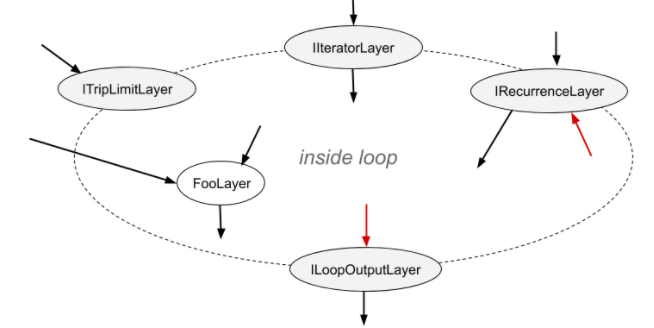
A loop can have multiple IIteratorLayer, IRecurrenceLayer, and ILoopOutputLayer, and at most two ITripLimitLayers as explained later. A loop with no ILoopOutputLayer has no output and is optimized by TensorRT.
Layers For Flow-Control Constructs describes the TensorRT layers that may be used in the loop interior.
Interior layers are free to use tensors defined inside or outside the loop. The interior can contain other loops (refer to Nested Loops) and other conditional constructs (refer to Conditionals Nesting).
To define a loop, first, create an ILoop object with the method INetworkDefinition::addLoop. Then add the boundary and interior layers. The rest of this section describes the features of the boundary layers, using loop to denote the ILoop* returned by INetworkDefinition::addLoop.
- loop->addTripLimit(t,TripLimit::kCOUNT) creates an ITripLimitLayer whose input t is a 0D INT32 tensor that specifies the number of loop iterations.
- loop->addTripLimit(t,TripLimit::kWHILE) creates an ITripLimitLayer whose input t is a 0D Bool tensor that specifies whether an iteration should occur. Typically, t is either the output of an IRecurrenceLayer or a calculation based on said output.
- loop->addIterator(t) adds an
IIteratorLayer that iterates over axis 0 of tensor
t. For example, if the input is the
matrix:
2 3 5 4 6 8
the output is the 1D tensor {2, 3, 5} on the first iteration and {4, 6, 8} for the second iteration. It is invalid to iterate beyond the tensor’s bounds. - loop->addIterator(t,axis) is similar, but the layer iterates over the given axis. For example, if axis=1 and the input is a matrix, each iteration delivers a column of the matrix.
- loop->addIterator(t,axis,reverse) is similar, but the layer produces its output in reverse order if reverse=true.
-
loop->addLoopOutput(t,LoopOutput::kLAST_VALUE) outputs the last value of t, where t must be the output of a IRecurrenceLayer.
-
loop->addLoopOutput(t,LoopOutput::kCONCATENATE,axis) outputs the concatenation of each iteration’s input to t. For example, if the input is a 1D tensor, with value {a,b,c} on the first iteration and {d,e,f} on the second iteration, and axis=0, the output is the matrix:
a b c d e f
If axis=1, the output is:a d b e c f
-
loop->addLoopOutput(t,LoopOutput::kREVERSE,axis) is similar, but reverses the order.
Both the kCONCATENATE and kREVERSE forms of ILoopOutputLayer require a second input, which is a 0D INT32 shape tensor specifying the length of the new output dimension. When the length is greater than the number of iterations, the extra elements contain arbitrary values. The second input, for example u, should be set using ILoopOutputLayer::setInput(1,u).
for (int32_t i = j; ...; i += k) ...could be created by these calls, where j and k are ITensor*.
ILoop* loop = n.addLoop();
IRecurrenceLayer* iRec = loop->addRecurrence(j);
ITensor* i = iRec->getOutput(0);
ITensor* iNext = addElementWise(*i, *k,
ElementWiseOperation::kADD)->getOutput(0);
iRec->setInput(1, *iNext);
The second input to IRecurrenceLayer is the only case where TensorRT allows a back edge. If such inputs are removed, the remaining network must be acyclic.
10.2. Formal Semantics
The formal semantics is based on lazy sequences of tensors. Each iteration of a loop corresponds to an element in the sequence. The sequence for a tensor X inside the loop is denoted ⟨X0, X1, X2, ...⟩. Elements of the sequence are evaluated lazily, meaning, as needed.
The output from IIteratorLayer(X) is ⟨X[0], X[1], X[2], ...⟩ where X[i] denotes subscripting on the axis specified for the IIteratorLayer.
The output from IRecurrenceLayer(X,Y)is ⟨X, Y0, Y1, Y2, ...⟩.
-
kLAST_VALUE: Input is a single tensor X, and output is Xn for an n-trip loop.
-
kCONCATENATE: The first input is a tensor X, and the second input is a scalar shape tensor Y. The result is the concatenation of X0, X1, X2, ... Xn-1 with post padding, if necessary, to the length specified by Y. It is a runtime error if Y < n. Y is a build time constant. Note the inverse relationship with IIteratorLayer. IIteratorLayer maps a tensor to a sequence of subtensors; ILoopOutputLayer with kCONCATENATE maps a sequence of sub tensors to a tensor.
-
kREVERSE: Similar to kCONCATENATE, but the output is in the reverse direction.
-
For counted loops, it is the iteration count, meaning the input to the ITripLimitLayer.
-
For while loops, it is the least n such that Xn is false, where X is the sequence for the ITripLimitLayer’s input tensor.
The output from a non-loop layer is a sequence-wise application of the layer’s function. For example, for a two-input non-loop layer F(X,Y) = ⟨f(X0,Y0), f(X1,Y1), f(X2,Y2)...⟩. If a tensor comes from outside the loop, that is, a loop invariant, then the sequence for it is created by replicating the tensor.
10.3. Nested Loops
TensorRT rejects networks where the loops are not cleanly nested, such as if loop A uses values defined in the interior of loop B and vice versa.
10.4. Limitations
In a loop, memory is allocated as if all dynamic dimensions take on the maximum value of any of those dimensions. For example, if a loop refers to two tensors with dimensions [4,x,y] and [6,y], memory allocation for those tensors is as if their dimensions were [4,max(x,y),max(x,y)] and [6,max(x,y)].
The input to a LoopOutputLayer with kLAST_VALUE must be the output from an IRecurrenceLayer.
The loop API supports only FP32 and FP16 precision.
10.5. Replacing IRNNv2Layer with Loops
Refer to sampleCharRNN for more information.
11. Working with Conditionals
11.1. Defining a Conditional
- IConditionLayer represents the predicate and specifies whether the conditional should execute the true-branch (then-branch) or the false-branch (else-branch).
- IIfConditionalInputLayer specifies an input to one of the two conditional branches.
- IIfConditionalOutputLayer specifies an output from a conditional.
Each of the boundary layers inherits from class IIfConditionalBoundaryLayer, which has a method getConditional() for getting its associated IIfConditional. The IIfConditional instance identifies the conditional. All conditional boundary layers with the same IIfConditional belong to that conditional.
A conditional must have exactly one instance of IConditionLayer, zero, or more instances of IIfConditionalInputLayer, and at least one instance of IIfConditionalOutputLayer.
If condition is true then: output = trueSubgraph(trueInputs); Else output = falseSubgraph(falseInputs); Emit output
Both the true-branch and the false-branch must be defined, similar to the ternary operator in many programming languages.
IIfConditional* simpleIf = network->addIfConditional();
// Create a condition predicate that is also a network input.
auto cond = network->addInput("cond", DataType::kBOOL, Dims{0});
IConditionLayer* condition = simpleIf->setCondition(*cond);
- An IIfConditionalInputLayerabstracts a single input to one or
both of the branch subgraphs of an IIfConditional. The output
of a specific IIfConditionalInputLayercan feed both
branches.
// Create an if-conditional input. // x is some arbitrary Network tensor. IIfConditionalInputLayer* inputX = simpleIf->addInput(*x);
Inputs to the then-branch and the else-branch do not have to be of the same type and shape. Each branch can independently include zero or more inputs.
IIfConditionalInputLayeris optional and is used to control which layers will be part of the branches (refer to Conditional Execution). If all of a branch's outputs do not depend on an IIfConditionalInputLayerinstance, that branch is empty. An empty else-branch can be useful when there are no layers to evaluate when the condition is false, and the network evaluation should proceed following the conditional (refer to Conditional Examples).
- An IIfConditionalOutputLayerabstracts a single output of the
if-conditional. It has two inputs: an output from the true-subgraph (input index
0) and an output from the false-subgraph (input index 1). The output of an
IIfConditionalOutputLayer can be thought of as a
placeholder for the final output that will be determined during
runtime.
IIfConditionalOutputLayer serves a role similar to that of a Φ (Phi) function node in traditional SSA control-flow graphs. Its semantics are: choose either the output of the true-subgraph or the false-subgraph.
// trueSubgraph and falseSubgraph represent network subgraphs IIfConditionalOutputLayer* outputLayer = simpleIf->addOutput( *trueSubgraph->getOutput(0), *falseSubgraph->getOutput(0));All outputs of an IIfConditional must be sourced at an IIfConditionalOutputLayer instance.
An if-conditional without outputs has no effect on the rest of the network, therefore, it is considered ill-formed. Each of the two branches (subgraphs) must also have at least one output. The output of an if-conditional can be marked as the output of the network, unless that if-conditional is nested inside another if-conditional or loop.
The diagram below provides a graphical representation of the abstract model of an if-conditional. The green rectangle represents the interior of the conditional, which is limited to the layer types listed in Layers For Flow-Control Constructs.
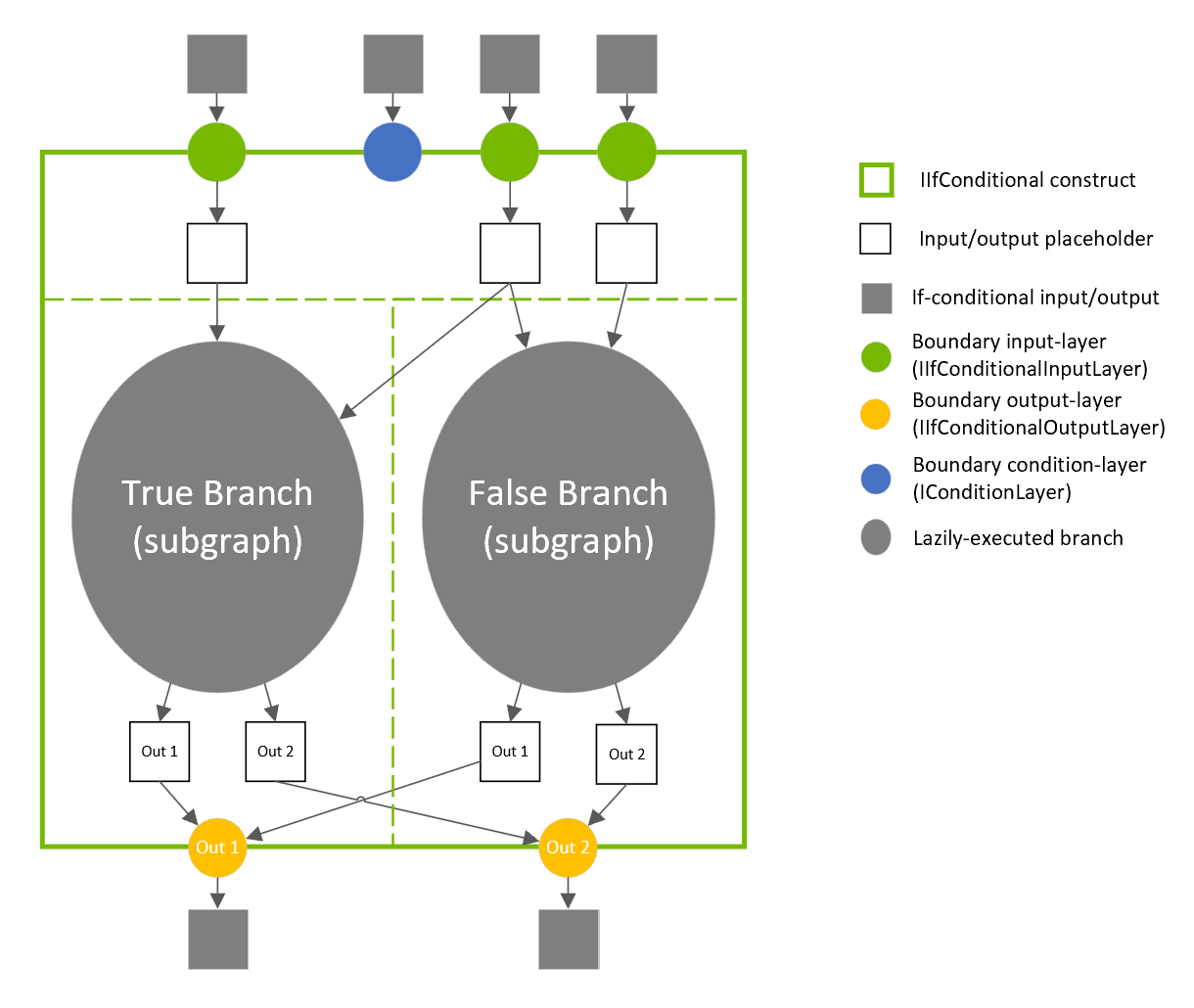
11.2. Conditional Execution
In contrast, in predicated-execution, both the true-branch and the false-branch are executed and only one of these is allowed to change the network evaluation state, depending on the value of the condition predicate (that is, only the outputs of one of the subgraphs is fed into the following layers).
Conditional execution is sometimes called lazy evaluation, and predicated-execution is sometimes referred to as eager evaluation.
Instances of IIfConditionalInputLayer can be used to specify which layers are invoked eagerly and which are invoked lazily. This is done by tracing the network layers backwards, starting with each of the conditional outputs. Layers that are data-dependent on the output of at least one IIfConditionalInputLayer are considered internal to the conditional and are therefore evaluated lazily. In the extreme case that no instances of IIfConditionalInputLayer are added to the conditional, all of the layers are executed eagerly, similarly to ISelectLayer.
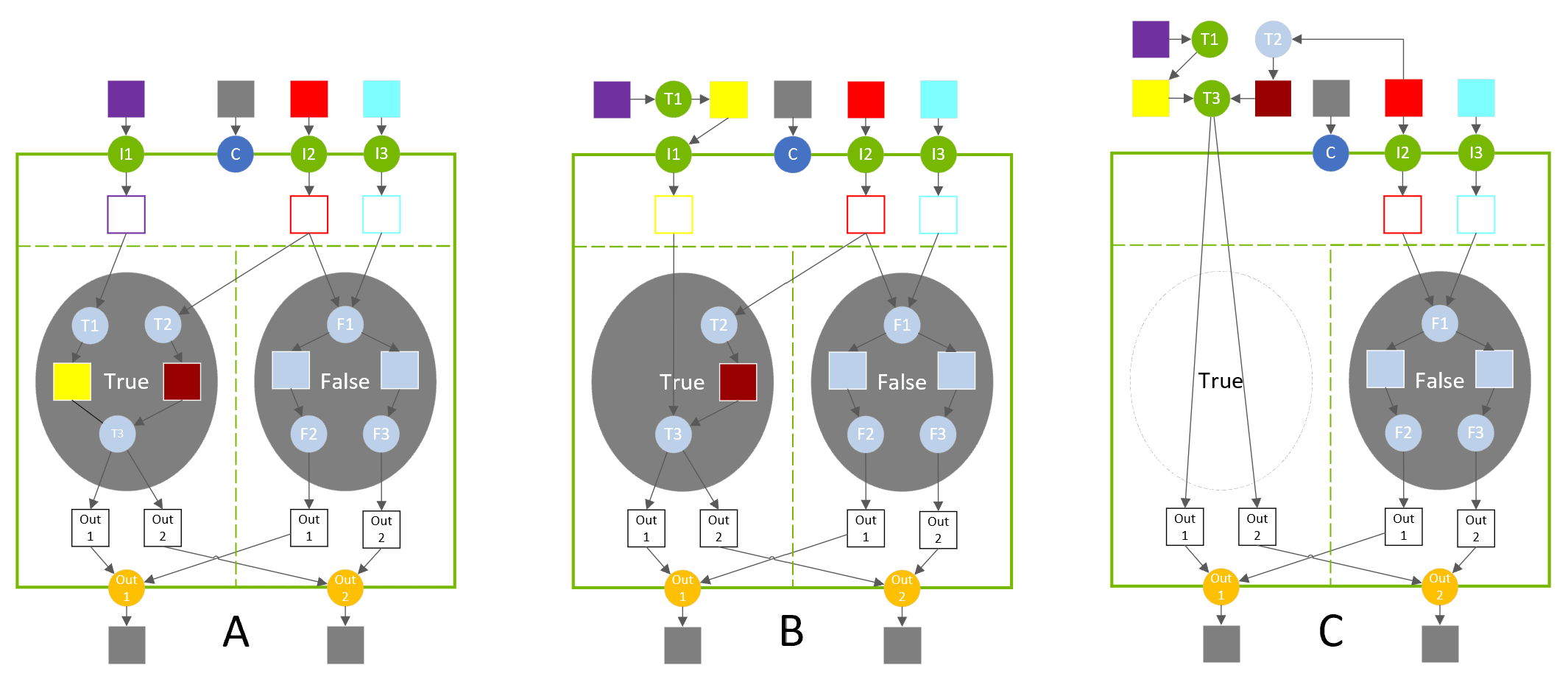
In diagram A, the true-branch is composed of three layers (T1, T2, T3). These layers execute lazily when the condition evaluates to true.
In diagram B, input-layer I1 is placed after layer T1, which moves T1 out of the true-branch. Layer T1 executes eagerly before evaluating the if-construct.
In diagram C, input-layer I1 is removed altogether, which moves T3 outside the conditional. T2’s input is reconfigured to create a legal network, and T2 also moves out of the true-branch. When the condition evaluates to true, the conditional does not compute anything since the outputs have already been eagerly computed (but it does copy the conditional relevant inputs to its outputs).
11.3. Nesting and Loops
There can be no cross-edges connecting layers in the true-branch to layers in the false-branch, and vice versa. In other words, the outputs of one branch cannot depend on layers in the other branch.
For example, refer to Conditional Examples for how nesting can be specified.
11.4. Limitations
Note that this is more constrained than the ONNX specification, which requires that the true/false subgraphs have the same number of outputs and use the same outputs data-types, but allows for different output shapes.
11.5. Conditional Examples
11.5.1. Simple If-Conditional
Example
ITensor* addCondition(INetworkDefinition& n, bool predicate)
{
// The condition value is a constant int32 input that is cast to boolean because TensorRT doesn't support boolean constant layers.
static const Dims scalarDims = Dims{0, {}};
static float constexpr zero{0};
static float constexpr one{1};
float* const val = predicate ? &one : &zero;
ITensor* cond =
n.addConstant(scalarDims, DataType::kINT32, val, 1})->getOutput(0);
auto* cast = n.addIdentity(cond);
cast->setOutputType(0, DataType::kBOOL);
cast->getOutput(0)->setType(DataType::kBOOL);
return cast->getOutput(0);
}
IBuilder* builder = createInferBuilder(gLogger);
INetworkDefinition& n = *builder->createNetworkV2(0U);
auto x = n.addInput("x", DataType::kFLOAT, Dims{1, {5}});
auto y = n.addInput("y", DataType::kFLOAT, Dims{1, {5}});
ITensor* cond = addCondition(n, true);
auto* simpleIf = n.addIfConditional();
simpleIf->setCondition(*cond);
// Add input layers to demarcate entry into true/false branches.
x = simpleIf->addInput(*x)->getOutput(0);
y = simpleIf->addInput(*y)->getOutput(0);
auto* trueSubgraph = n.addElementWise(*x, *y, ElementWiseOperation::kSUM)->getOutput(0);
auto* falseSubgraph = n.addElementWise(*x, *y, ElementWiseOperation::kSUB)->getOutput(0);
auto* output = simpleIf->addOutput(*trueSubgraph, *falseSubgraph)->getOutput(0);
n.markOutput(*output);
11.5.2. Exporting from PyTorch
import torch.onnx
import torch
import tensorrt as trt
import numpy as np
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
@torch.jit.script
def sum_even(items):
s = torch.zeros(1, dtype=torch.float)
for c in items:
if c % 2 == 0:
s += c
return s
class ExampleModel(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, items):
return sum_even(items)
def build_engine(model_file):
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network(EXPLICIT_BATCH)
config = builder.create_builder_config()
parser = trt.OnnxParser(network, TRT_LOGGER)
with open(model_file, 'rb') as model:
assert parser.parse(model.read())
return builder.build_engine(network, config)
def export_to_onnx():
items = torch.zeros(4, dtype=torch.float)
example = ExampleModel()
torch.onnx.export(example, (items), "example.onnx", verbose=False, opset_version=13, enable_onnx_checker=False, do_constant_folding=True)
export_to_onnx()
build_engine("example.onnx")
12. Working with DLA
DLA is useful for offloading CNN processing from the iGPU, and is significantly more power-efficient for these workloads. In addition, it can provide an independent execution pipeline in cases where redundancy is important, for example in mission-critical or safety applications.
For more information about DLA, refer to the DLA developer page and the DLA tutorial Getting started with the Deep Learning Accelerator on NVIDIA Jetson Orin.
When building a model for DLA, the TensorRT builder parses the network and calls the DLA compiler to compile the network into a DLA loadable. Refer to Using trtexec to see how to build and run networks on DLA.
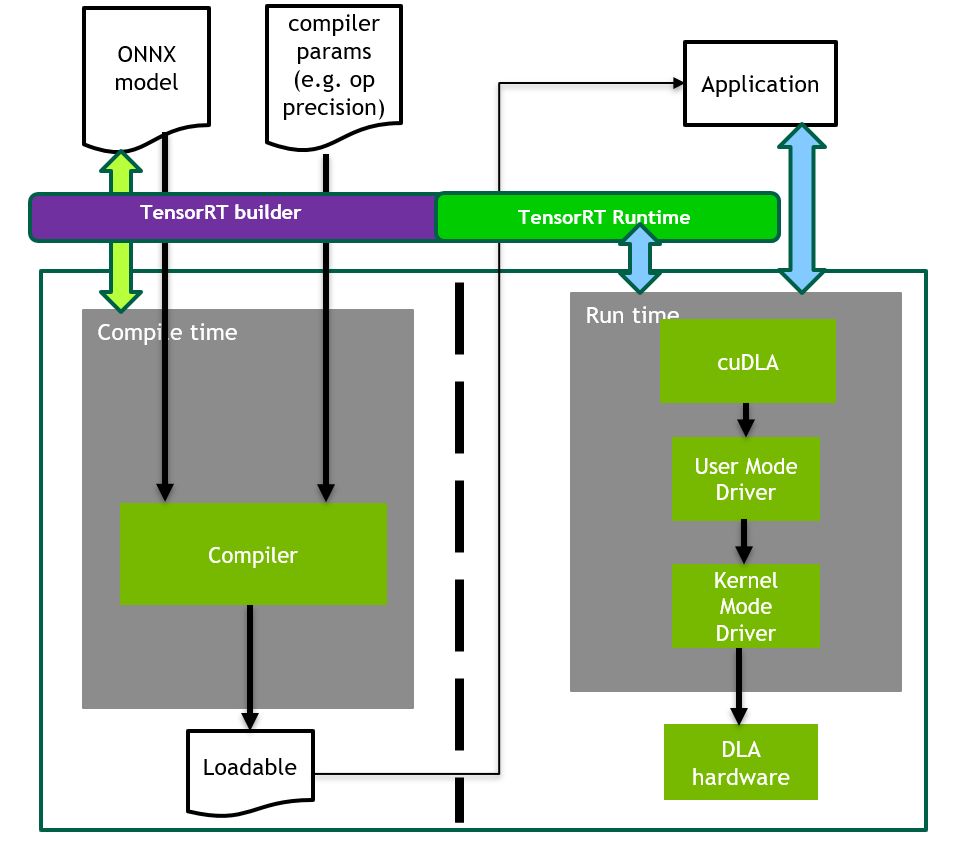
12.1. Building and Launching the Loadable
For generating a standalone DLA loadable to be used outside TensorRT, refer to DLA Standalone Mode.
12.1.1. Using trtexec
./trtexec --onnx=data/resnet50/ResNet50.onnx --useDLACore=0 --fp16 --allowGPUFallback
The trtexec tool has additional arguments to run networks on DLA. For more information, refer to Command-Line Programs.
12.1.2. Using the TensorRT API
12.1.2.1. Running on DLA during TensorRT Inference
- This function can be used to set the deviceType that the layer must execute on.
- This function can be used to return the deviceType that this layer executes on. If the layer is executing on the GPU, this returns DeviceType::kGPU.
- This function can be used to check if a layer can run on DLA.
- This function sets the default deviceType to be used by the builder. It ensures that all the layers that can run on DLA runs on DLA unless setDeviceType is used to override the deviceType for a layer.
- This function returns the default deviceType which was set by setDefaultDeviceType.
- This function checks whether the deviceType has been explicitly set for this layer.
- This function resets the deviceType for this layer. The value is reset to the deviceType that is specified by setDefaultDeviceType or DeviceType::kGPU if none is specified.
- This function notifies the builder to use GPU if a layer that was supposed to run on DLA cannot run on DLA. For more information, refer to GPU Fallback Mode.
- This function can be used to reset the IBuilderConfig state, which sets the deviceType for all layers to be DeviceType::kGPU. After reset, the builder can be reused to build another network with a different DLA config.
- This function returns the maximum batch size DLA can support.
Note: For any tensor, the total volume of index dimensions combined with the requested batch size must not exceed the value returned by this function.
- This function returns the number of DLA cores available to the user.
- This function returns the number of DLA cores that are accessible to the user.
- The DLA core to execute on. Where dlaCore is a value between 0 and getNbDLACores() - 1. The default value is 0.
- The DLA core that the runtime execution is assigned to. The default value is 0.
12.1.2.2. Example: Run Samples with DLA
auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(gLogger)); if (!builder) return false; builder->setMaxBatchSize(batchSize); config->setMaxWorkspaceSize(16_MB);
config->setFlag(BuilderFlag::kGPU_FALLBACK); config->setFlag(BuilderFlag::kFP16); or config->setFlag(BuilderFlag::kINT8);
config->setDefaultDeviceType(DeviceType::kDLA); config->setDLACore(dlaCore);
With these additional changes, sampleMNIST is ready to execute on DLA. To run samples with DLA Core 1, append --useDLACore=0 to the sample command.
12.1.2.3. Example: Enable DLA Mode for a Layer during Network Creation
- Create the builder, builder configuration, and the network:
IBuilder* builder = createInferBuilder(gLogger); IBuilderConfig* config = builder.createBuilderConfig(); INetworkDefinition* network = builder->createNetworkV2(0U);
- Add the Input layer to the network, with the input dimensions.
auto data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{1, INPUT_H, INPUT_W}); - Add the Convolution layer with hidden layer input nodes, strides, and weights for
filter and bias.
auto conv1 = network->addConvolution(*data->getOutput(0), 20, DimsHW{5, 5}, weightMap["conv1filter"], weightMap["conv1bias"]); conv1->setStride(DimsHW{1, 1}); - Set the convolution layer to run on DLA:
if(canRunOnDLA(conv1)) { config->setFlag(BuilderFlag::kFP16); or config->setFlag(BuilderFlag::kINT8); builder->setDeviceType(conv1, DeviceType::kDLA); } - Mark the output:
network->markOutput(*conv1->getOutput(0));
- Set the DLA core to execute on:
config->setDLACore(0)
12.1.3. Using the cuDLA API
Managing shared buffers as well as synchronizing the tasks between GPU and DLA is transparently handled by cuDLA. Refer to the NVIDIA cuDLA documentation on how the cuDLA APIs can be used for these use cases while writing a cuDLA application.
Refer to the DLA Standalone Mode section for more information on how to use TensorRT to build a standalone DLA loadable usable with cuDLA.
12.2. DLA Supported Layers and Restrictions
12.2.2. Layer Support and Restrictions
12.2.3. Inference on NVIDIA Orin
On NVIDIA Orin, DLA stores weights for non-convolution operations (FP16 and INT8) inside a loadable as FP19 values (which use 4 byte containers). The channel dimensions are padded to multiples of either 16 (FP16) or 32 (INT8) for those FP19 values. Especially in the case of large per-element Scale, Add, or Sub operations, this can inflate the size of the DLA loadable, inflating the engine containing such a loadable. Graph optimization may unintentionally trigger this behavior by changing the type of a layer, for example, when an ElementWise multiplication layer with a constant layer as weights is fused into a scale layer.
12.3. GPU Fallback Mode
- The layer operation is not supported on DLA.
- The parameters specified are out of the supported range for DLA.
- The given batch size exceeds the maximum permissible DLA batch size. For more information, refer to DLA Supported Layers and Restrictions.
- A combination of layers in the network causes the internal state to exceed what the DLA is capable of supporting.
- There are no DLA engines available on the platform.
When GPU fallback is disabled, an error is emitted if a layer could not be run on DLA.
12.4. I/O Formats on DLA
For DLA input tensors, kDLA_LINEAR(FP16, INT8), kDLA_HWC4(FP16, INT8), kCHW16(FP16), and kCHW32(INT8) are supported. For DLA output tensors, only kDLA_LINEAR(FP16, INT8), kCHW16(FP16), and kCHW32(INT8) are supported. For kCHW16 and kCHW32 formats, if C is not an integer multiple, then it must be padded to the next 32-byte boundary.
For kDLA_LINEAR format, the stride along the W dimension must be padded up to 64 bytes. The memory format is equivalent to a C array with dimensions [N][C][H][roundUp(W, 64/elementSize)] where elementSize is 2 for FP16 and 1 for Int8, with the tensor coordinates (n, c, h, w) mapping to array subscript [n][c][h][w].
When GPU fallback is enabled, TensorRT may insert reformatting layers to meet the DLA requirements. Otherwise, the input and output formats must be compatible with DLA. In all cases, the strides that TensorRT expects data to be formatted with can be obtained by querying IExecutionContext::getStrides.
12.5. DLA Standalone Mode
12.5.1. Building A DLA Loadable Using C++
- Set the default device type and engine capability to DLA standalone mode.
builderConfig->setDefaultDeviceType(DeviceType::kDLA); builderConfig->setEngineCapability(EngineCapability::kDLA_STANDALONE);
- Specify FP16, INT8, or both. For example:
builderConfig->setFlag(BuilderFlag::kFP16);
- DLA standalone mode disallows reformatting, therefore
BuilderFlag::kDIRECT_IO needs to be set.
builderConfig->setFlag(BuilderFlag::kDIRECT_IO);
- You must set the allowed formats for I/O tensors to one or more of those supported by DLA. See the documentation for the TensorFormat enum for details.
- Finally, build as normal
12.5.1.1. Using trtexec To Generate A DLA Loadable
./trtexec --onnx=model.onnx --saveEngine=model_loadable.bin --useDLACore=0 --fp16 --inputIOFormats=fp16:chw16 --outputIOFormats=fp16:chw16 --skipInference --safe
12.6. Customizing DLA Memory Pools
-
- Behaves like a cache and larger values may improve performance.
- If no managed SRAM is available, DLA can still run by falling back to local DRAM.
- On Orin, each DLA core has 1 MiB of dedicated SRAM. On Xavier, 4 MiB of SRAM is shared across multiple cores including the 2 DLA cores.
-
- Used to store intermediate tensors in the DLA subnetwork. Larger values may allow larger subnetworks to be offloaded to DLA.
-
- Used to store weights in the DLA subnetwork. Larger values may allow larger subnetworks to be offloaded to DLA.
The amount of memory required for each subnetwork may be less than the pool size, in which case the smaller amount will be allocated. The pool size serves only as an upper bound.
Note that all DLA memory pools require sizes that are powers of 2, with a minimum of 4 KiB. Violating this requirement results in a DLA loadable compilation failure.
In multi-subnetwork situations, it is important to keep in mind that the pool sizes apply per DLA subnetwork, not for the whole network, so it is necessary to be aware of the total amount of resources being consumed. In particular, your network can consume at most twice the managed SRAM as the pool size in aggregate.
For NVIDIA Orin, the default managed SRAM pool size is set to 0.5 MiB whereas Xavier has 1 MiB as the default. This is because Orin has a strict per-core limit, whereas Xavier has some flexibility. This Orin default guarantees in all situations that the aggregate managed SRAM consumption of your engine stays below the hardware limit, but if your engine has only a single DLA subnetwork, this would mean your engine only consumes half the hardware limit so you may see a perf boost by increasing the pool size to 1 MiB.
12.6.1. Determining DLA Memory Pool Usage
12.7. Sparsity on DLA
12.7.1. Structured Sparsity
Structured Sparsity has several requirements and limitations.
13. Performance Best Practices
13.1. Measuring Performance
Latency
A performance measurement for network inference is how much time elapses from an input being presented to the network until an output is available. This is the latency of the network for a single inference. Lower latencies are better. In some applications, low latency is a critical safety requirement. In other applications, latency is directly visible to users as a quality-of-service issue. For bulk processing, latency may not be important at all.
Throughput
Another performance measurement is how many inferences can be completed in a fixed unit of time. This is the throughput of the network. Higher throughput is better. Higher throughputs indicate a more efficient utilization of fixed compute resources. For bulk processing, the total time taken will be determined by the throughput of the network.
Another way of looking at latency and throughput is to fix the maximum latency and measure throughput at that latency. A quality-of-service measurement like this can be a reasonable compromise between the user experience and system efficiency.
Before measuring latency and throughput, you must choose the exact points at which to start and stop timing. Depending on the network and application, it might make sense to choose different points.
In many applications, there is a processing pipeline, and the overall system performance can be measured by the latency and throughput of the entire processing pipeline. Because the pre- and post-processing steps depend so strongly on the particular application, this section considers the latency and throughput of the network inference only.
13.1.1. Wall-clock Timing
- C++
#include <chrono> auto startTime = std::chrono::high_resolution_clock::now(); context->enqueueV3(stream); cudaStreamSynchronize(stream); auto endTime = std::chrono::high_resolution_clock::now(); float totalTime = std::chrono::duration<float, std::milli> (endTime - startTime).count()
- Python
import time from cuda import cudart err, stream = cudart.cudaStreamCreate() start_time = time.time() context.execute_async_v3(stream) cudart.cudaStreamSynchronize(stream) total_time = time.time() - start_time
If there is only one inference happening on the device at one time, then this can be a simple way of profiling the time-various operations take. Inference is typically asynchronous, so ensure you add an explicit CUDA stream or device synchronization to wait for results to become available.
13.1.2. CUDA Events
To help with these issues, CUDA provides an Event API. This API allows you to place events into CUDA streams that will be time-stamped by the GPU as they are encountered. Differences in timestamps can then tell you how long different operations took.
- C++
cudaEvent_t start, end; cudaEventCreate(&start); cudaEventCreate(&end); cudaEventRecord(start, stream); context->enqueueV3stream); cudaEventRecord(end, stream); cudaEventSynchronize(end); float totalTime; cudaEventElapsedTime(&totalTime, start, end);
- Python
from cuda import cudart err, stream = cudart.cudaStreamCreate() err, start = cudart.cudaEventCreate() err, end = cudart.cudaEventCreate() cudart.cudaEventRecord(start, stream) context.execute_async_v3(stream) cudart.cudaEventRecord(end, stream) cudart.cudaEventSynchronize(end) err, total_time = cudart.cudaEventElapsedTime(start, end)
13.1.3. Built-In TensorRT Profiling
TensorRT has a Profiler interface, which you can implement in order to have TensorRT pass profiling information to your application. When called, the network will run in a profiling mode. After finishing inference, the profiler object of your class is called to report the timing for each layer in the network. These timings can be used to locate bottlenecks, compare different versions of a serialized engine, and debug performance issues.
The profiling information can be collected from a regular inference enqueueV3() launch or a CUDA graph launch. Refer to IExecutionContext::setProfiler() and IExecutionContext::reportToProfiler() for more information.
Layers inside a loop compile into a single monolithic layer, therefore, separate timings for those layers are not available. Also, some subgraphs (especially with Transformer-like networks) are handled by a next-generation graph optimizer that is not yet integrated with the Profiler APIs. For those networks, use CUDA Profiling Tools to profile per-layer performance.
An example showing how to use the IProfiler interface is provided in the common sample code (common.h).
You can also use trtexec to profile a network with TensorRT given an input network or plan file. Refer to the trtexec section for details.
13.1.4. CUDA Profiling Tools
Nsight Systems can be configured in various ways to report timing information for only a portion of the execution of the program or to also report traditional CPU sampling profile information together with GPU information.
The basic usage of Nsight Systems is to first run the command nsys profile -o <OUTPUT> <INFERENCE_COMMAND>, then, open the generated <OUTPUT>.nsys-rep file in the Nsight Systems GUI to visualize the captured profiling results.
Profile Only the Inference Phase
- First phase: Structure the application to build and then serialize the engines in one phase.
- Second phase: Load the serialized engines and run inference in a second phase and profile this second phase only.
If the application cannot serialize the engines, or if the application must run through the two phases consecutively, you can also add cudaProfilerStart()/cudaProfilerStop() CUDA APIs around the second phase and add -c cudaProfilerApi flag to Nsight Systems command to profile only the part between cudaProfilerStart() and cudaProfilerStop().
Understand Nsight Systems Timeline View
In the Nsight Systems Timeline View, the GPU activities are shown at the rows under CUDA HW and the CPU activities are shown at the rows under Threads. By default, the rows under CUDA HW are collapsed, therefore, you must click on it to expand the rows.
In a typical inference workflow, the application calls the context->enqueueV3() or context->executeV3() APIs to enqueue the jobs and then synchronize on the stream to wait until the GPU completes the jobs. It may appear as if the system is doing nothing for a while in the cudaStreamSychronize() call if you only look at the CPU activities. In fact, the GPU may be busy executing the enqueued jobs while the CPU is waiting. The following figure shows an example timeline of the inference of a query.
The trtexec tool uses a slightly more complicated approach to enqueue the jobs by enqueuing the next query while GPU is still executing the jobs from the previous query. Refer to the trtexec section for more information.
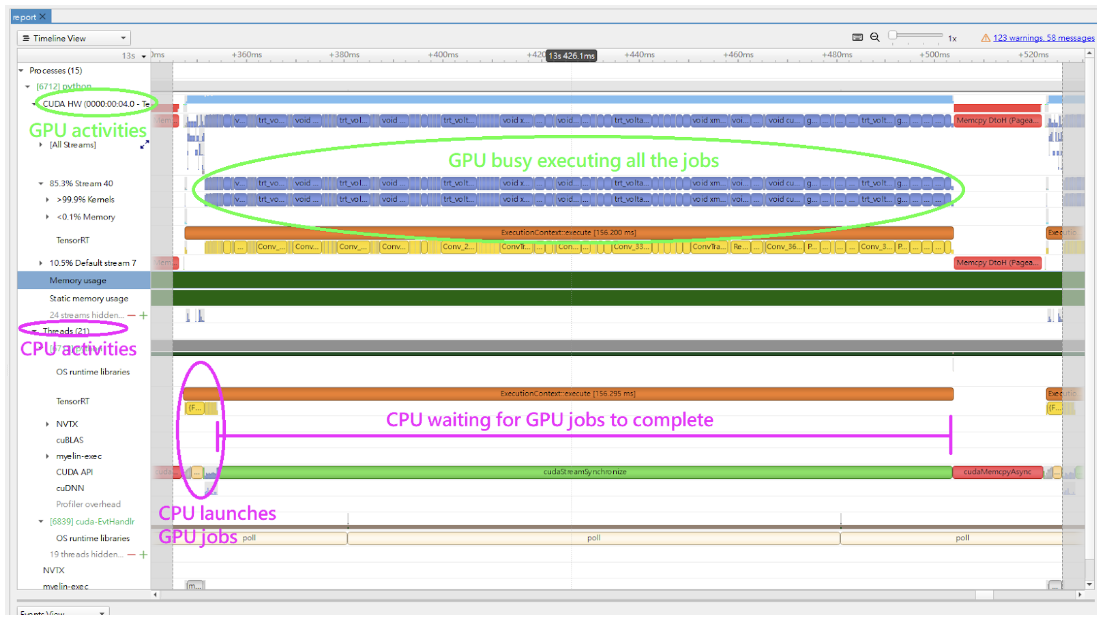
Use the NVTX Tracing in Nsight Systems
Enabling NVIDIA Tools Extension SDK (NVTX) tracing allows Nsight Compute and Nsight Systems to collect data generated by TensorRT applications. NVTX is a C-based API for marking events and ranges in your applications.
Decoding the kernel names back to layers in the original network can be complicated. Because of this, TensorRT uses NVTX to mark a range for each layer, which then allows the CUDA profilers to correlate each layer with the kernels called to implement it. In TensorRT, NVTX helps to correlate the runtime engine layer execution with CUDA kernel calls. Nsight Systems supports collecting and visualizing these events and ranges on the timeline. Nsight Compute also supports collecting and displaying the state of all active NVTX domains and ranges in a given thread when the application is suspended.
In TensorRT, each layer may launch one or more kernels to perform its operations. The exact kernels launched depend on the optimized network and the hardware present. Depending on the choices of the builder, there may be multiple additional operations that reorder data interspersed with layer computations; these reformat operations may be implemented as either device-to-device memory copies or as custom kernels.
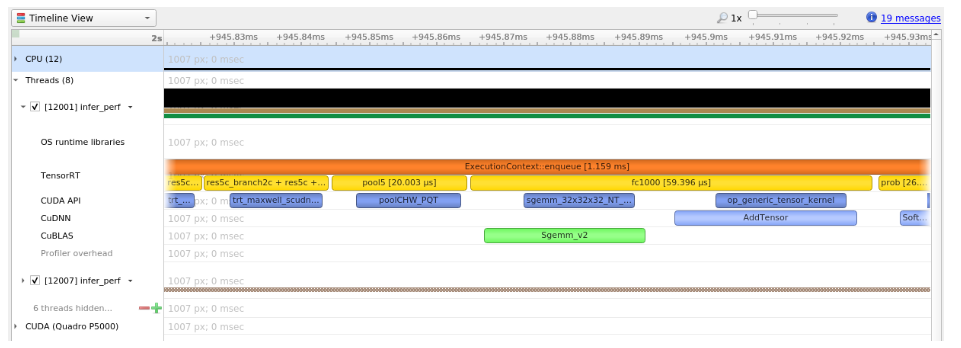
Control the Level of Details in NVTX Tracing
- C++
builderConfig->setProfilingVerbosity(ProfilingVerbosity::kNONE);
- Python
builder_config.profilling_verbosity = trt.ProfilingVerbosity.NONE
- C++
builderConfig->setProfilingVerbosity(ProfilingVerbosity::kDETAILED);
- Python
builder_config.profilling_verbosity = trt.ProfilingVerbosity.DETAILED
Run Nsight Systems with trtexec
trtexec --onnx=foo.onnx --profilingVerbosity=detailed --saveEngine=foo.plan nsys profile -o foo_profile --capture-range cudaProfilerApi trtexec --profilingVerbosity=detailed --loadEngine=foo.plan --warmUp=0 --duration=0 --iterations=50
The first command builds and serializes the engine to foo.plan, and the second command runs the inference using foo.plan and generates a foo_profile.nsys-rep file that can then be opened in the Nsight Systems user interface for visualization.
The --profilingVerbosity=detailed flag allows TensorRT to show more detailed layer information in the NVTX marking, and the --warmUp=0 --duration=0 --iterations=50 flags allow you to control how many inference iterations to run. By default, trtexec runs inference for three seconds, which may result in a very large output nsys-rep file.
nsys profile -o foo_profile --capture-range cudaProfilerApi --cuda-graph-trace=node trtexec --profilingVerbosity=detailed --loadEngine=foo.plan --warmUp=0 --duration=0 --iterations=50 --useCudaGraph
(Optional) Enable GPU Metrics Sampling in Nsight Systems
On discrete GPU systems, add the --gpu-metrics-device all flag to the nsys command to sample GPU metrics, including GPU clock frequencies, DRAM bandwidth, Tensor Core utilization, and so on. If the flag is added, these GPU metrics appear in the Nsight Systems web interface.
13.1.4.1. Profiling for DLA
nsys profile -t cuda,nvtx,nvmedia,osrt --accelerator-trace=nvmedia --show-output=true trtexec --loadEngine=alexnet_int8.plan --warmUp=0 --duration=0 --iterations=20
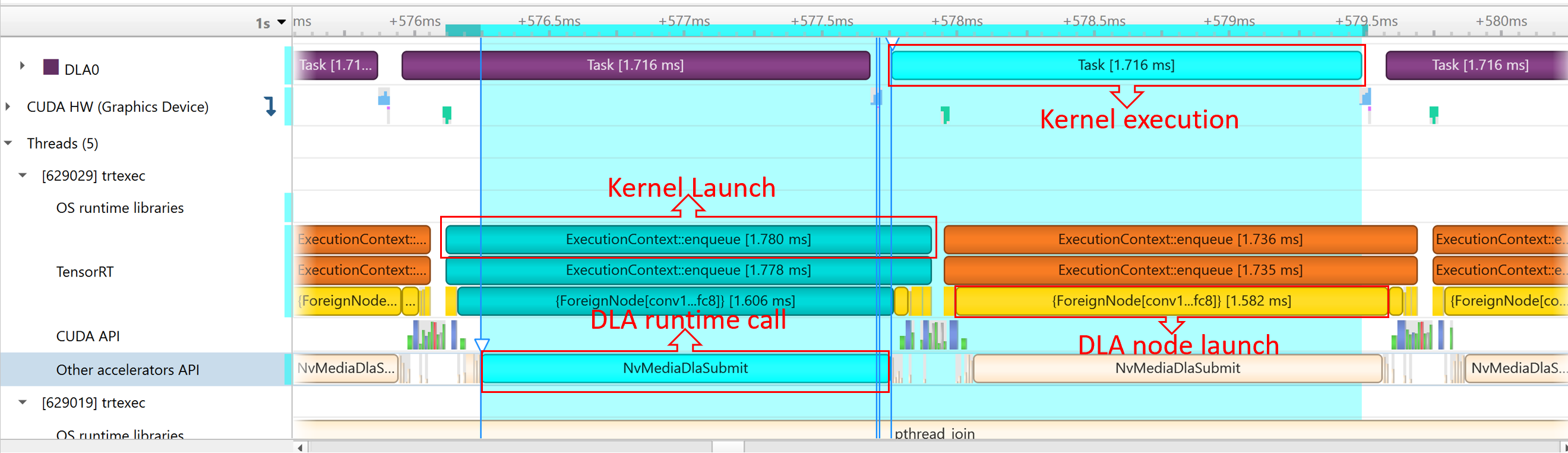
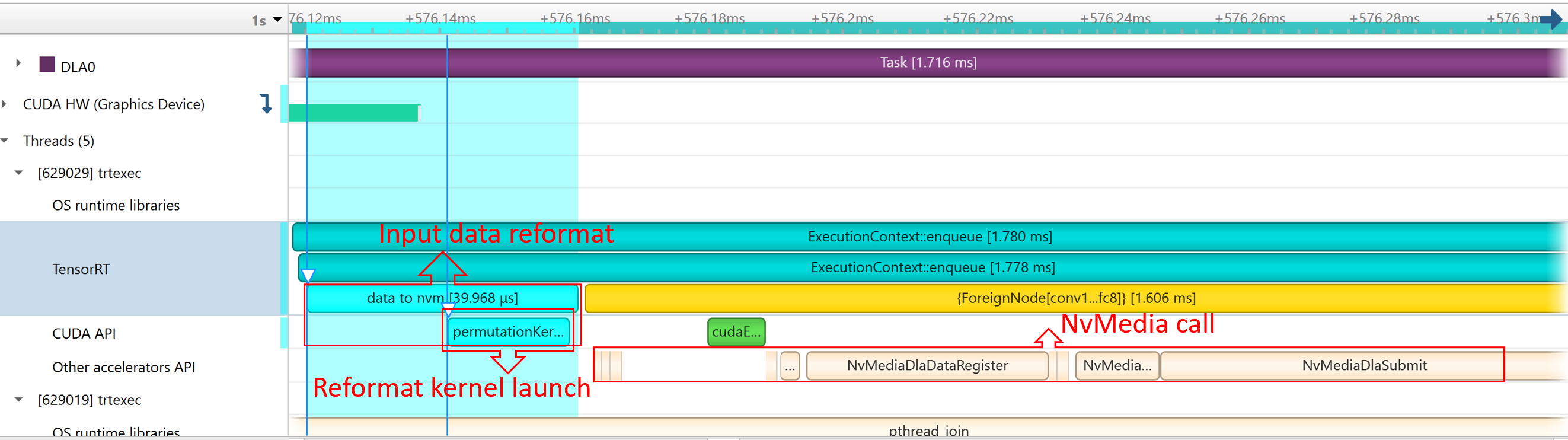
13.1.5. Tracking Memory
A custom GPU allocator can be set for the builder IBuilder for network optimizations, and for IRuntime when deserializing engines using the IGpuAllocator APIs. One idea for the custom allocator is to keep track of the current amount of memory allocated, and to push an allocation event with a timestamp and other information onto a global list of allocation events. Looking through the list of allocation events allows profiling memory usage over time.
echo "######alloc swap######"
if [ ! -e /swapfile ];then
sudo fallocate -l 4G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo /bin/sh -c 'echo "/swapfile \t none \t swap \t defaults \t 0 \t 0" >> /etc/fstab'
sudo swapon -a
fi
13.2. Hardware/Software Environment for Performance Measurements
Note that the items involving nvidia-smi are only supported on dGPU systems and not on the mobile systems.
13.2.1. GPU Information Query and GPU Monitoring
Before the inference starts, call the nvidia-smi -q command to get the detailed information of the GPU, including the product name, power cap, clock settings, and so on. Then, while the inference workload is running, run the nvidia-smi dmon -s pcu -f <FILE> -c <COUNT> command in parallel to print out GPU clock frequencies, power consumption, temperature, and utilization to a file. Call nvidia-smi dmon --help for more options about the nvidia-smi device monitoring tool.
13.2.2. GPU Clock Locking and Floating Clock
Alternatively, you can lock the clock at a specific frequency by calling the sudo nvidia-smi -lgc <freq> command (and conversely, you can let the clock float again with the sudo nvidia-smi -rgc command). The supported clock frequencies can be found by the sudo nvidia-smi -q -d SUPPORTED_CLOCKS command. After the clock frequency is locked, it should stay at that frequency unless power throttling or thermal throttling take place, which will be explained in next sections. When the throttling kicks in, the device behaves as if the clock were floating.
Running TensorRT workloads with floating clocks or with throttling taking place can lead to more non-determinism in tactic selections and unstable performance measurements across inferences because every CUDA kernel may run at slightly different clock frequencies, depending on which frequency the driver boosts or throttles the clock to at that moment. On the other hand, running TensorRT workloads with locked clocks allows more deterministic tactic selections and consistent performance measurements, but the average performance will not be as good as when the clock is floating or is locked at maximum frequency with throttling taking place.
There is no definite recommendation on whether the clock should be locked or which clock frequency to lock the GPU at while running TensorRT workloads. It depends on whether the deterministic and stable performance or the best average performance is desired.
13.2.3. GPU Power Consumption and Power Throttling
Power throttling happens by design and is a natural phenomenon when the GPU clock is not locked or is locked at a higher frequency, especially for the GPUs with lower power limits such as NVIDIA T4 and NVIDIA A2 GPUs. To avoid performance variations caused by power throttling, you can lock the GPU clock at a lower frequency so that the performance numbers become more stable. However, the average performance numbers will be lower than the performance numbers with floating clocks or with the clock locked at a higher frequency even though power throttling would happen in this case.
Another issue with power throttling is that it may skew the performance numbers if there are gaps between inferences in your performance benchmarking applications. For example, if the application synchronizes at each inference, there will be periods of time when the GPU is idle between the inferences. The gaps cause the GPU to consume less power on average such that the clock is throttled less and the GPU can run at higher clock frequencies on average. However, the throughput numbers measured in this way are not accurate because when the GPU is fully loaded with no gaps between inferences, the actual clock frequency will be lower and the actual throughput will not reach the throughput numbers measured using the benchmarking application.
To avoid this, the trtexec tool is designed to maximize GPU execution by leaving nearly no gaps between GPU kernel executions so that it can measure the true throughput of a TensorRT workload. Therefore, if you see performance gaps between your benchmarking application and what trtexec reports, check if the power throttling and the gaps between inferences are the cause.
Lastly, power consumption can be dependent on the activation values, causing different performance measurements for different inputs. For example, if all the network input values are set to zeros or NaNs, GPU tends to consume less power than if the inputs are normal values because of fewer bit-flips in DRAM and in L2 cache. To avoid this discrepancy, always use the input values that best represent the actual value distribution when measuring the performance. The trtexec tool uses random input values by default, but you can specify the input by using the --loadInputs flag. Refer to the trtexec section for more information.
13.2.4. GPU Temperature and Thermal Throttling
If thermal throttling happens on actively cooled GPUs like Quadro A8000, then it is possible that the fans on the GPU are broken, or there are obstacles blocking the airflow.
If thermal throttling happens on passively cooled GPUs like NVIDIA A10, then it is likely that the GPUs are not properly cooled. Passively cooled GPUs require external fans or air conditioning to cool down the GPUs, and the airflow must go through the GPUs for effective cooling. Common cooling problems include installing GPUs in a server that is not designed for the GPUs or installing wrong numbers of GPUs into the server. In some cases, the air flows through the “easy path” (that is, the path with the least friction) around the GPUs instead of going through them. Fixing this requires examination of the airflow in the server and installation of airflow guidance if necessary.
Note that higher GPU temperature also leads to more leakage current in the circuits, which increases the power consumed by the GPU at a specific clock frequency. Therefore, for GPUs that are more likely to be power throttled like NVIDIA T4, poor cooling can lead to lower stabilized clock frequency with power throttling, and thus worse performance, even if the GPU clocks have not been thermally throttled yet.
On the other hand, ambient temperature, that is, the temperature of the environment around the server, does not usually affect GPU performance so long as the GPUs are properly cooled, except for GPUs with lower power limit whose performance may be slightly affected.
13.2.5. H2D/D2H Data Transfers and PCIe Bandwidth
To achieve maximum throughput, the H2D/D2H data transfers should run in parallel to the GPU executions of other inferences so that the GPU does not sit idle when the H2D/D2H copies take place. This can be done by running multiple inferences in different streams in parallel, or by launching H2D/D2H copies in a different stream than the stream used for GPU executions and using CUDA events to synchronize between the streams. The trtexec tool shows as an example for the latter implementation.
When the H2D/D2H copies run in parallel to GPU executions, they can interfere with the GPU executions especially if the host memory is pageable, which is the default case. Therefore, it is recommended that you allocate pinned host memory for the input and output data using cudaHostAlloc() or cudaMallocHost() CUDA APIs.
To check whether the PCIe bandwidth becomes the performance bottleneck, you can check the Nsight Systems profiles and see if the H2D or D2H copies of an inference query have longer latencies than the GPU execution part. If PCIe bandwidth becomes the performance bottleneck, here are a few possible solutions.
First, check whether the PCIe bus configuration of the GPU is correct in terms of which generation (for example, Gen3 or Gen4) and how many lanes (for example, x8 or x16) are used. Next, try reducing the amount of data that must be transferred using the PCIe bus. For example, if the input images have high resolutions and the H2D copies become the bottleneck, then you can consider transmitting JPEG-compressed images over the PCIe bus and decode the image on the GPUs before the inference workflow, instead of transmitting raw pixels. Finally, you can consider using NVIDIA GPUDirect technology to load data directly from/to the network or the filesystems without going through the host memory.
In addition, if your system has AMD x86_64 CPUs, check the NUMA (Non-Uniform Memory Access) configurations of the machine with numactl --hardware command. The PCIe bandwidth between a host memory and a device memory located on two different NUMA nodes is much more limited than the bandwidth between the host/device memory located on the same NUMA node. Allocate the host memory on the NUMA node on which the GPU that the data will be copied to resides. Also, pin the CPU threads that will trigger the H2D/D2H copies on that specific NUMA node.
Note that on mobile platforms, the host, and the device share the same memory, so the H2D/D2H data transfers are not required if the host memory is allocated using CUDA APIs and is pinned instead of being pageable.
By default, the trtexec tool measures the latencies of the H2D/D2H data transfers that tell the user if the TensorRT workload may be bottlenecked by the H2D/D2H copies. However, if the H2D/D2H copies affect the stability of the GPU Compute Time, you can add the --noDataTransfers flag to disable H2D/D2H transfers to measure only the latencies of the GPU execution part.
13.2.6. TCC Mode and WDDM Mode
In TCC mode, the GPU is configured to focus on computation work and the graphics support like OpenGL or monitor display are disabled. This is the recommended mode for GPUs that run TensorRT inference workloads. On the other hand, the WDDM mode tends to cause GPUs to have worse and unstable performance results when running inference workloads using TensorRT.
This is not applicable to Linux-based OS.
13.2.7. Enqueue-Bound Workloads and CUDA Graphs
First, if the workload is very tiny in terms of the amount of computations, such as containing convolutions with small I/O sizes, matrix multiplications with small GEMM sizes, or mostly element-wise operations throughout the network, then the workload tends to be enqueue-bound. This is because most CUDA kernels take the CPU and the driver around 5-15 microseconds to launch per kernel, so if each CUDA kernel execution time is only several microseconds long on average, the kernel launching time becomes the main performance bottleneck.
To solve this, try to increase the amount of the computation per CUDA kernel, such as by increasing the batch size. Or you can use CUDA Graphs to capture the kernel launches into a graph and launch the graph instead of calling enqueueV3().
Second, if the workload contains operations that require device synchronizations, such as loops or if-else conditions, then the workload is naturally enqueue-bound. In this case, increasing the batch size may help improve the throughput without increasing the latency much.
In trtexec, you can tell that a workload is enqueue-bound if the reported Enqueue Time is close to or longer than the reported GPU Compute Time. In this case, it is recommended that you add the --useCudaGraph flag to enable CUDA graphs in trtexec, which will reduce the Enqueue Time as long as the workload does not contain any synchronization operations.
13.2.8. BlockingSync and SpinWait Synchronization Modes
When cudaStreamSynchronize() is called, there are two ways in which the driver waits until the completion of the stream. If the cudaDeviceScheduleBlockingSync flag has been set with cudaSetDeviceFlags() calls, then the cudaStreamSynchornize() uses the blocking-sync mechanism. Otherwise, it uses the spin-wait mechanism.
The similar idea applies to CUDA events. If a CUDA event is created with the cudaEventDefault flag, then the cudaEventSynchronize() call uses the spin-wait mechanism; and if a CUDA event is created with the cudaEventBlockingSync flag, then the cudaEventSynchronize() call will use the blocking-sync mechanism.
When the blocking-sync mode is used, the host thread yields to another thread until the device work is done. This allows the CPUs to sit idle to save power or to be used by other CPU workloads when the device is still executing. However, the blocking-sync mode tends to result in relatively unstable overheads in stream/event synchronizations in some OS, which in terms lead to variations in latency measurements.
On the other hand, when the spin-wait mode is used, the host thread is constantly polling until the device work is done. Using spin-wait makes the latency measurements more stable due to shorter and more stable overhead in stream/event synchronizations, but it consumes some CPU computation resources and leads to more power consumption by the CPUs.
Therefore, if you want to reduce CPU power consumption, or if you do not want the stream/event synchronizations to consume CPU resources (for example, you are running other heavy CPU workloads in parallel), use the blocking-sync mode. If you care more about stable performance measurements, use the spin-wait mode.
In trtexec, the default synchronization mechanism is blocking-sync mode. Add the --useSpinWait flag to enable synchronizations using the spin-wait mode for more stable latency measurements, at the cost of more CPU utilizations and power consumptions.
13.3. Optimizing TensorRT Performance
13.3.1. Batching
Each layer of the network will have some amount of overhead and synchronization required to compute forward inference. By computing more results in parallel, this overhead is paid off more efficiently. In addition, many layers are performance-limited by the smallest dimension in the input. If the batch size is one or small, this size can often be the performance-limiting dimension. For example, the FullyConnected layer with V inputs and K outputs can be implemented for one batch instance as a matrix multiply of an 1xV matrix with a VxK weight matrix. If N instances are batched, this becomes an NxV multiplied by the VxK matrix. The vector-matrix multiplier becomes a matrix-matrix multiplier, which is much more efficient.
Larger batch sizes are almost always more efficient on the GPU. Extremely large batches, such as N > 2^16, can sometimes require extended index computation and so should be avoided if possible. But generally, increasing the batch size improves total throughput. In addition, when the network contains MatrixMultiply layers or FullyConnected layers, batch sizes of multiples of 32 tend to have the best performance for FP16 and INT8 inference because of the utilization of Tensor Cores, if the hardware supports them.
On NVIDIA Ada Lovelace GPUs or later GPUs, it is possible that decreasing the batch size may improve the throughput significantly if the smaller batch sizes happen to help the GPU to cache the input/output values in the L2 cache. Therefore, try various batch sizes to get the batch size for the optimal performance.
Sometimes batching inference work is not possible due to the organization of the application. In some common applications, such as a server that does inference per request, it can be possible to implement opportunistic batching. For each incoming request, wait for a time T. If other requests come in during that time, batch them together. Otherwise, continue with a single instance inference. This type of strategy adds fixed latency to each request but can improve the maximum throughput of the system by orders of magnitude.
The NVIDIA Triton Inference Server provides a simple way to enable dynamic batching with TensorRT engines.
Using batching
If the explicit batch mode is used when the network is created, then the batch dimension is part of the tensor dimensions, and you can specify the range of the batch sizes and the batch size to optimize the engine for by adding optimization profiles. Refer to the Working with Dynamic Shapes section for more details.
If the implicit batch mode is used when the network is created, the IExecutionContext::execute (IExecutionContext.execute in Python) and IExecutionContext::enqueue (IExecutionContext.execute_async in Python) methods take a batch size parameter. The maximum batch size should also be set for the builder when building the optimized network with IBuilder::setMaxBatchSize (Builder.max_batch_size in Python). When calling IExecutionContext::execute or enqueue, the bindings passed as the bindings parameter are organized per tensor and not per instance. In other words, the data for one input instance is not grouped together into one contiguous region of memory. Instead, each tensor binding is an array of instance data for that tensor.
Another consideration is that building the optimized network optimizes for the given maximum batch size. The final result will be tuned for the maximum batch size but will still work correctly for any smaller batch size. It is possible to run multiple build operations to create multiple optimized engines for different batch sizes, then choose which engine to use based on the actual batch size at runtime.
13.3.2. Within-Inference Multi-Streaming
In the context of TensorRT and inference, each layer of the optimized final network will require work on the GPU. However, not all layers will be able to fully use the computation capabilities of the hardware. Scheduling requests in separate streams allows work to be scheduled immediately as the hardware becomes available without unnecessary synchronization. Even if only some layers can be overlapped, overall performance will improve.
Starting in TensorRT 8.6, you can use the IBuilderConfig::setMaxAuxStreams() API to set the maximum number of auxiliary streams that TensorRT is allowed to use to run multiple layers in parallel. The auxiliary streams are in contrast to the “main stream” provided in the enqueueV3() call, and if enabled, TensorRT will run some layers on the auxiliary streams in parallel to the layers running on the mainstream.
- C++
config->setMaxAuxStreams(7)
- Python
config.max_aux_streams = 7
Note that this only sets the maximum number of auxiliary streams, however, TensorRT may end up using fewer auxiliary streams than this number if it determines that using more streams does not help.
- C++
int32_t nbAuxStreams = engine->getNbAuxStreams()
- Python
num_aux_streams = engine.num_aux_streams
- C++
int32_t nbAuxStreams = engine->getNbAuxStreams(); std::vector<cudaStream_t> streams(nbAuxStreams); for (int32_t i = 0; i < nbAuxStreams; ++i) { cudaStreamCreate(&streams[i]); } context->setAuxStreams(streams.data(), nbAuxStreams);- Python
from cuda import cudart num_aux_streams = engine.num_aux_streams streams = [] for i in range(num_aux_streams): err, stream = cudart.cudaStreamCreate() streams.append(stream) context.set_aux_streams(streams)
- At the beginning of the enqueueV3() call, TensorRT will make sure that all the auxiliary streams wait on the activities on the mainstream.
- At the end of the enqueueV3() call, TensorRT will make sure that the main stream waits on the activities on all the auxiliary streams.
Note that enabling auxiliary streams may increase the memory consumption because some activation buffers will no longer be able to be reused.
13.3.3. Cross-Inference Multi-Streaming
Running multiple concurrent streams often leads to situations where several streams share compute resources at the same time. This means that the network may have less compute resources available during inference than when the TensorRT engine was being optimized. This difference in resource availability can cause TensorRT to choose a kernel that is suboptimal for the actual runtime conditions. In order to mitigate this effect, you can limit the amount of available compute resources during engine creation to more closely resemble actual runtime conditions. This approach generally promotes throughput at the expense of latency. For more information, refer to Limiting Compute Resources.
It is also possible to use multiple host threads with streams. A common pattern is incoming requests dispatched to a pool of waiting for worker threads. In this case, the pool of worker threads will each have one execution context and CUDA stream. Each thread will request work in its own stream as the work becomes available. Each thread will synchronize with its stream to wait for results without blocking other worker threads.
13.3.4. CUDA Graphs
- C++
// Call enqueueV3() once after an input shape change to update internal state. context->enqueueV3(stream); // Capture a CUDA graph instance cudaGraph_t graph; cudaGraphExec_t instance; cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal); context->enqueueV3(stream); cudaStreamEndCapture(stream, &graph); cudaGraphInstantiate(&instance, graph, 0); // To run inferences, launch the graph instead of calling enqueueV3(). for (int i = 0; i < iterations; ++i) { cudaGraphLaunch(instance, stream); cudaStreamSynchronize(stream); }- Python
from cuda import cudart err, stream = cudart.cudaStreamCreate() # Call execute_async_v3() once after an input shape change to update internal state. context.execute_async_v3(stream); # Capture a CUDA graph instance cudaStreamBeginCapture(stream, cudart.cudaStreamCaptureModeGlobal) context.execute_async_v3(stream) err, graph = cudart.cudaStreamEndCapture(stream) err, instance = cudart.cudaGraphInstantiate(graph, 0) # To run inferences, launch the graph instead of calling execute_async_v3(). for i in range(iterations): cudart.cudaGraphLaunch(instance, stream) cudart.cudaStreamSynchronize(stream)
Models for which graphs are not supported include those with loops or conditionals. In this case, cudaStreamEndCapture() will return cudaErrorStreamCapture* errors, indicating that the graph capturing has failed, but the context can continue to be used for normal inference without CUDA graphs.
- Update internal state of the model to account for any changes in input size.
- Stream work to the GPU
For models where input size is fixed at build time, the first phase requires no per-invocation work. Otherwise, if the input sizes have changed since the last invocation, some work may be required to update derived properties.
The first phase of work is not designed to be captured, and even if the capture is successful may increase model execution time. Therefore, after changing the shapes of inputs or the values of shape tensors, call enqueueV3() once to flush deferred updates before capturing the graph.
Graphs captured with TensorRT are specific to the input size for which they were captured, and also to the state of the execution context. Modifying the context from which the graph was captured will result in undefined behavior when executing the graph - in particular, if the application is providing its own memory for activations using createExecutionContextWithoutDeviceMemory(), the memory address is also captured as part of the graph. Binding locations are also captured as part of the graph.
Therefore, the best practice is to use one execution context per captured graph, and to share memory across the contexts with createExecutionContextWithoutDeviceMemory().
trtexec allows you to check whether the built TensorRT engine is compatible with CUDA graph capture. Refer to the trtexec section for more information.
13.3.5. Enabling Fusion
13.3.5.1. Layer Fusion
Consider the common case of a convolution followed by ReLU activation. To create a network with these operations, it involves adding a Convolution layer with addConvolution, following it with an Activation layer using addActivation with an ActivationType of kRELU. The unoptimized graph will contain separate layers for convolution and activation. The internal implementation of convolution supports computing the ReLU function on the output in one step directly from the convolution kernel without requiring a second kernel call. The fusion optimization step will detect the convolution followed by ReLU. Verify that the operations are supported by the implementation, then fuse them into one layer.
To investigate which fusions have happened, or have not happened, the builder logs its operations to the logger object provided during construction. Optimization steps are at the kINFO log level. To see these messages, ensure you log them in the ILogger callback.
Fusions are normally handled by creating a new layer with a name containing the names of both of the layers, which were fused. For example, in MNIST, a FullyConnected layer (InnerProduct) named ip1 is fused with a ReLU Activation layer named relu1 to create a new layer named ip1 + relu1.
13.3.5.2. Types of Fusions
Supported Layer Fusions
- An Activation layer performing ReLU followed by an activation performing ReLU will be replaced by a single activation layer.
- The Convolution layer can be of any type and there are no restrictions on values. The Activation layer must be ReLU type.
- The precision of input and output should be the same; with both of them FP16 or INT8. The Activation layer must be GELU type. TensorRT should be running on an NVIDIA Turing or later device with CUDA version 10.0 or later.
- The Convolution layer can be any type and there are no restrictions on values. The Activation layer must be Clip type.
- The Scale layer followed by an Activation layer can be fused into a single Activation layer.
- A Convolution layer followed by a simple sum, min, or max in an ElementWise layer can be fused into the Convolution layer. The sum must not use broadcasting, unless the broadcasting is across the batch size.
- Padding followed by a Convolution or Deconvolution can be fused into a single Convolution/Deconvolution layer if all the padding sizes are non-negative.
- A Shuffle layer without reshape, followed by a Reduce layer can be fused into a single Reduce layer. The Shuffle layer can perform permutations but cannot perform any reshape operation. The Reduce layer must have a keepDimensions set of dimensions.
- Each Shuffle layer consists of a transpose, a reshape, and a second transpose. A Shuffle layer followed by another Shuffle layer can be replaced by a single Shuffle (or nothing). If both Shuffle layers perform reshape operations, this fusion is only allowed if the second transpose of the first shuffle is the inverse of the first transpose of the second shuffle.
- A Scale layer that adds 0, multiplied by 1, or computes powers to the 1 can be erased.
- A Convolution layer followed by a Scale layer that is kUNIFORM or kCHANNEL can be fused into a single convolution by adjusting the convolution weights. This fusion is disabled if the scale has a non-constant power parameter.
- This fusion happens after the pointwise fusion mentioned below. A pointwise with one input and one output can be called as a generic activation layer. A convolution layer followed by a generic activation layer can be fused into a single convolution layer.
- A Reduce layer that performs average pooling will be replaced by a Pooling layer. The Reduce layer must have a keepDimensions set, reduced across H and W dimensions from CHW input format before batching, using the kAVG operation.
- The Convolution and Pooling layers must have the same precision. The Convolution layer may already have a fused activation operation from a previous fusion.
- A depthwise convolution with activation followed by a convolution with activation may sometimes be fused into a single optimized DepSepConvolution layer. The precision of both convolutions must be INT8 and the device's computes capability must be 7.2 or later.
- It can be fused into a single SoftMax layer if the SoftMax has not already been fused with a previous log operation.
- Can be fused into a single layer. The SoftMax may or may not include a Log operation.
- The FullyConnected layer will be converted into the Convolution layer. All fusions for convolution will take effect.
Supported Reduction Operation Fusions
- GELU
- A group of Unary layer and ElementWise layer that represents the following
equations can be fused into a single GELU reduction operation.
Or the alternative representation:
- L1Norm
- A Unary layer kABS operation followed by a Reduce layer kSUM operation can be fused into a single L1Norm reduction operation.
- Sum of Squares
- A product ElementWise layer with the same input (square operation) followed by a kSUM reduction can be fused into a single square Sum reduction operation.
- L2Norm
- A sum of squares operation followed by a kSQRT UnaryOperation can be fused into a single L2Norm reduction operation.
- LogSum
- A Reduce layer kSUM followed by a kLOG UnaryOperation can be fused into a single LogSum reduction operation.
- LogSumExp
- A Unary kEXP ElementWise operation followed by a LogSum fusion can be fused into a single LogSumExp reduction.
13.3.5.3. PointWise Fusion
- Every ActivationType is supported.
- Only constant with a single value (size == 1).
- Every ElementWiseOperation is supported.
- PointWise itself is also a PointWise layer.
- Only support ScaleMode::kUNIFORM.
- Every UnaryOperation is supported.
The size of the fused PointWise layer is not unlimited, therefore, some PointWise layers may not be fused.
Fusion creates a new layer with a name consisting of both of the layers, which were fused. For example, an ElementWise layer named add1 is fused with a ReLU Activation layer named relu1 with a new layer name: fusedPointwiseNode(add1, relu1).
13.3.5.4. Q/DQ Fusion
Q/DQ nodes help convert from FP32 values to INT8 and vice versa. Such a graph would still have weights and bias in FP32 precision.
Weights are followed by a Q/DQ node pair so that they can be quantized/dequantized if required. Bias quantization is performed using scales from activations and weights, thus no extra Q/DQ node pair is required for bias input. Assumption for bias quantization is that .
-
If we have a
[DequantizeLinear (Activations), DequantizeLinear (weights)] > Node > QuantizeLinear( [DQ, DQ] > Node > Q) sequence, then it is fused to the quantized node (QNode).Supporting Q/DQ node pairs for weights requires weighted nodes to support more than one input. Thus we support adding a second input (for weights tensor) and third input (for bias tensor). Additional inputs can be set using setInput(index, tensor) API for Convolution, Deconvolution, and FullyConnected layers where index = 2 for weights tensor and index = 3 for bias tensor.
During fusion with weighted nodes, we would quantize FP32 weights to INT8 and fuse it with the corresponding weighted node. Similarly, FP32 bias would be quantized to INT32 and fused.
- If we have a DequantizeLinear > Node > QuantizeLinear (DQ > Node > Q) sequence, then it is fused to the quantized node (QNode).
-
DequantizeLinear commutation is allowed when . QuantizeLinear commutation is allowed when .
Also, commutation logic also accounts for available kernel implementations such that mathematical equivalence is guaranteed.
- If a node has a missing Q/DQ nodes pair, and ; (for example, MaxPool), missing Q/DQ pairs would be inserted to run more node with INT8 precision.
- It is possible that after applying all the optimizations, the graph still has Q/DQ node pairs that are in itself a no-op. Q/DQ node erasure fusion would remove such redundant pairs.
13.3.6. Limiting Compute Resources
The resulting engine is optimized to the reduced number of compute cores (50% in this example) and provides better throughput when using similar conditions during inference. You are encouraged to experiment with different amounts of streams and different MPS values to determine the best performance for your network.
For more details about nvidia-cuda-mps-control, refer to the nvidia-cuda-mps-control documentation and the relevant GPU requirements here.
13.3.7. Deterministic Tactic Selection
If deterministic tactic selection is desired, the following lists a few suggestions that may help improve the determinism of tactic selection.
Locking GPU Clock Frequency
By default, the clock frequency of the GPU is not locked, meaning that the GPU normally sits at the idle clock frequency and only boosts to the max clock frequency when there are active GPU workloads. However, there is a latency for the clock to be boosted from the idle frequency and that may cause performance variations while TensorRT is running through the tactics and selecting the best ones, resulting in non-deterministic tactic selections.
Therefore, locking the GPU clock frequency before starting to build a TensorRT engine may improve the determinism of tactic selection. You can lock the GPU clock frequency by calling the sudo nvidia-smi -lgc <freq> command, where <freq> is the desired frequency to lock at. You can call nvidia-smi -q -d SUPPORTED_CLOCKS to find the supported clock frequencies by the GPU.
Therefore, locking the GPU clock frequency before starting to build a TensorRT engine may improve the determinism of tactic selection. Refer to the Hardware/Software Environment for Performance Measurements section for more information about how to lock and monitor the GPU clock and the factors that may affect GPU clock frequencies.
Increasing Average Timing Iterations
- C++
builderConfig->setAvgTimingIterations(8);
- Python
Builder_config.avg_timing_iterations = 8
Increasing the number of average timing iterations may improve the determinism of tactic selections, but the required engine building time will become longer.
Using Timing Cache
Timing Cache records the latencies of each tactic for a specific layer configuration. The tactic latencies are reused if TensorRT encounters another layer with an identical configuration. Therefore, by reusing the same timing cache across multiple engine buildings runs with the same INetworkDefinition and builder config, you can make TensorRT select an identical set of tactics in the resulting engines.
Refer to the Timing Cache section for more information.
13.3.8. Overhead of Shape Change and Optimization Profile Switching
Optimizing the cost of shape/profile switching is an active area of development. However, there are still a few cases where the overhead can influence the performance of the inference applications. For example, some convolution tactics for NVIDIA Volta GPUs or older GPUs have much longer shape/profile switching overhead, even if their inference performance is the best among all the available tactics. In this case, disabling kEDGE_MASK_CONVOLUTIONS tactics from tactic sources when building the engine may help reduce the overhead of shape/profile switching.
13.4. Optimizing Layer Performance
- If using an implicit batch dimension, the main consideration with the Concatenation layer is that if multiple outputs are concatenated together, they cannot be broadcasted across the batch dimension and must be explicitly copied. Most layers support broadcasting across the batch dimension to avoid copying data unnecessarily, but this will be disabled if the output is concatenated with other tensors.
- To get the maximum performance out of a Gather layer, use an axis of 0. There are no fusions available for a Gather layer.
- To get the maximum performance out of a Reduce layer, perform the reduction across the last dimensions (tail reduce). This allows optimal memory to read/write patterns through sequential memory locations. If doing common reduction operations, express the reduction in a way that will be fused to a single operation if possible.
-
If possible, opt to use the newer RNNv2 interface in preference to the legacy RNN interface. The newer interface supports variable sequence lengths and variable batch sizes, as well as having a more consistent interface. To get maximum performance, larger batch sizes are better. In general, sizes that are multiples of 64 achieve highest performance. Bidirectional RNN-mode prevents wavefront propagation because of the added dependency, therefore, it tends to be slower.
In addition, the newly introduced Loop-based API provides a much more flexible mechanism to use general layers within recurrence without being limited to a small set of predefined RNNv2 interface. The ILoopLayer recurrence enables a rich set of automatic loop optimizations, including loop fusion, unrolling, and loop-invariant code motion, to name a few. For example, significant performance gains are often obtained when multiple instances of the same MatrixMultiply or FullyConnected layer are properly combined to maximize machine utilization after loop unrolling along the sequence dimension. This works best if you can avoid a MatrixMultiply or FullyConnected layer with a recurrent data dependence along the sequence dimension.
- Shuffle operations that are equivalent to identity operations on the underlying data are omitted if the input tensor is only used in the shuffle layer and the input and output tensors of this layer are not input and output tensors of the network. TensorRT does not execute additional kernels or memory copies for such operations.
- To get the maximum performance out of a TopK layer, use small values of K reducing the last dimension of data to allow optimal sequential memory accesses. Reductions along multiple dimensions at once can be simulated by using a Shuffle layer to reshape the data, then reinterpreting the index values appropriately.
For more information about layers, refer to the NVIDIA TensorRT Operator's Reference.
13.5. Optimizing for Tensor Cores
- In Convolution and Deconvolution layers the alignment requirement is on I/O channel dimension.
- In MatrixMultiply and FullyConnected layers the alignment requirement is on matrix dimensions K and N in a MatrixMultiply that is M x K times K x N.
When using Tensor Core implementations in cases where these requirements are not met, TensorRT implicitly pads the tensors to the nearest multiple of alignment rounding up the dimensions in the model definition instead to allow for extra capacity in the model without increasing computation or memory traffic.
TensorRT always uses the fastest implementation for a layer, and thus in some cases may not use a Tensor Core implementation even if available.
To check if Tensor Core is used for a layer, run Nsight Systems with the --gpu-metrics-device all flag while profiling the TensorRT application. The Tensor Core usage rate can be found in the profiling result in the Nsight Systems user interface under the SM instructions/Tensor Active row. Refer to the CUDA Profiling Tools for more information about how to use Nsight Systems to profile TensorRT applications.
Note that it is not practical to expect a CUDA kernel to reach 100% Tensor Core usage since there are other overheads such as DRAM reads/writes, instruction stalls, other computation units, and so on. In general, the more computation-intensive an operation is, the higher the Tensor Core usage rate the CUDA kernel can achieve.

13.6. Optimizing Plugins
All TensorRT plugins are automatically registered once the plugin library is loaded. For more information about custom plugins, refer to Extending TensorRT with Custom Layers.
The performance of plugins depends on the CUDA code performing the plugin operation. Standard CUDA best practices apply. When developing plugins, it can be helpful to start with simple standalone CUDA applications that perform the plugin operation and verify correctness. The plugin program can then be extended with performance measurements, more unit testing, and alternate implementations. After the code is working and optimized, it can be integrated as a plugin into TensorRT.
To get the best performance possible, it is important to support as many formats as possible in the plugin. This removes the need for internal reformat operations during the execution of the network. Refer to the Extending TensorRT with Custom Layers section for examples.
13.7. Optimizing Python Performance
Setting up the input buffers in the Python API involves using pycuda or another CUDA Python library, like cupy, to transfer the data from the host to device memory. The details of how this works will depend on where the host data is coming from. Internally, pycuda supports the Python Buffer Protocol which allows efficient access to memory regions. This means that if the input data is available in a suitable format in numpy arrays or another type that also has support for the buffer protocol, this allows efficient access and transfer to the GPU. For even better performance, ensure that you allocate a page-locked buffer using pycuda and write your final preprocessed input there.
For more information about using the Python API, refer to NVIDIA TensorRT 8.6.11 API Reference for DRIVE OS.
13.8. Improving Model Accuracy
- Validate layer outputs:
- Use Polygraphy to dump layer outputs and verify that there are no NaNs or Infs. The --validate option can check for NaNs and Infs. Also, we can compare layer outputs with golden values from, for example, ONNX runtime.
- For FP16, it is possible that a model might require retraining to ensure that intermediate layer output can be represented in FP16 precision without overflow/underflow.
- For INT8, consider recalibrating with a more representative calibration data set. If your model comes from PyTorch, we also provide NVIDIA's Quantization Toolkit for PyTorch for QAT in the framework besides PTQ in TensorRT. You can try both approaches and choose the one with more accuracy.
- Manipulate layer precision:
- Sometimes running a layer in certain precision results in incorrect output. This can be due to inherent layer constraints (for example, LayerNorm output should not be INT8), model constraints (output gets diverged resulting in poor accuracy), or report a TensorRT bug.
- You can control layer execution precision and output precision.
- An experimental debug precision tool can help automatically find layers to run in high precision.
- Use an Algorithm Selection and Reproducible Builds to disable flaky tactics:
- When accuracy changes between build+run to build+run, it might be due to a selection of a bad tactic for a layer.
- Use an algorithm selector to dump tactics from both good and bad runs. Configure the algorithm selector to allow only a subset of tactics (that is, just allow tactics from a good run, and so on).
- You can use Polygraphy to automate this process.
Accuracy from run-to-run variation should not change; once the engine is built for a specific GPU, it should result in bit accurate outputs in multiple runs. If not, file a TensorRT bug.
13.9. Optimizing Builder Performance
13.9.1. Timing Cache
If there are other layers with the same IO tensor configuration and layer parameters, the TensorRT builder skips profiling and reuses the cached result for the repeated layers. If a timing query misses in the cache, the builder times the layer and updates the cache.
ITimingCache* cache = config->createTimingCache(cacheFile.data(), cacheFile.size());
Setting the buffer size to 0 creates a new empty timing cache.
config->setTimingCache(*cache, false);
IHostMemory* serializedCache = cache->serialize();
If there is no timing cache attached to a builder, the builder creates its own temporary local cache and destroys it when it is done.
config->setFlag(BuilderFlag::kDISABLE_TIMING_CACHE);
13.9.2. Tactic Selection Heuristic
config->setFlag(BuilderFlag::kENABLE_TACTIC_HEURISTIC);
13.10. Builder Optimization Level
- C++
config->setOptimizationLevel(0);
- Python
config.optimization_level = 0
14. Troubleshooting
14.1. FAQs
Q: How do I create an engine that is optimized for several different batch sizes?
A: While TensorRT allows an engine optimized for a given batch size to run at any smaller size, the performance for those smaller sizes cannot be as well optimized. To optimize for multiple different batch sizes, create optimization profiles at the dimensions that are assigned to OptProfilerSelector::kOPT.
Q: Are calibration tables portable across TensorRT versions?
A: No. Internal implementations are continually optimized and can change between versions. For this reason, calibration tables are not guaranteed to be binary compatible with different versions of TensorRT. Applications must build new INT8 calibration tables when using a new version of TensorRT.
Q: Are engines portable across TensorRT versions?
A: By default, no. Refer to Version Compatibility for how to configure engines for forward compatibility.
Q: How do I choose the optimal workspace size?
A: Some TensorRT algorithms require additional workspace on the GPU. The method IBuilderConfig::setMemoryPoolLimit() controls the maximum amount of workspace that can be allocated and prevents algorithms that require more workspace from being considered by the builder. At runtime, the space is allocated automatically when creating an IExecutionContext. The amount allocated is no more than is required, even if the amount set in IBuilderConfig::setMemoryPoolLimit() is much higher. Applications should therefore allow the TensorRT builder as much workspace as they can afford; at runtime, TensorRT allocates no more than this and typically less.
Q: How do I use TensorRT on multiple GPUs?
A: Each ICudaEngine object is bound to a specific GPU when it is instantiated, either by the builder or on deserialization. To select the GPU, use cudaSetDevice() before calling the builder or deserializing the engine. Each IExecutionContext is bound to the same GPU as the engine from which it was created. When calling execute() or enqueue(), ensure that the thread is associated with the correct device by calling cudaSetDevice() if necessary.
Q: How do I get the version of TensorRT from the library file?
$ nm -D libnvinfer.so.* | grep tensorrt_version 00000000abcd1234 B tensorrt_version_#_#_#_#
Q: What can I do if my network is producing the wrong answer?
- Turn on VERBOSE level messages from the log stream and check what TensorRT is reporting.
- Check that your input preprocessing is generating exactly the input format required by the network.
- If you are using reduced precision, run the network in FP32. If it produces the correct result, it is possible that lower precision has an insufficient dynamic range for the network.
- Try marking intermediate tensors in the network as outputs, and verify if
they match what you are expecting.
Note: Marking tensors as outputs can inhibit optimizations, and therefore, can change the results.
You can use NVIDIA Polygraphy to assist you with debugging and diagnosis.
Q: How do I implement batch normalization in TensorRT?
adjustedScale = scale / sqrt(variance + epsilon) batchNorm = (input + bias - (adjustedScale * mean)) * adjustedScale
Q: Why does my network run slower when using DLA compared to without DLA?
A: DLA was designed to maximize energy efficiency. Depending on the features supported by DLA and the features supported by the GPU, either implementation can be more performant. Which implementation to use depends on your latency or throughput requirements and your power budget. Since all DLA engines are independent of the GPU and each other, you could also use both implementations at the same time to further increase the throughput of your network.
Q: Is INT4 quantization or INT16 quantization supported by TensorRT?
A: Neither INT4 nor INT16 quantization is supported by TensorRT at this time.
Q: When will TensorRT support layer XYZ required by my network in the UFF parser?
A: UFF is deprecated. We recommend users switch their workflows to ONNX. The TensorRT ONNX parser is an open source project.
Q: Can I use multiple TensorRT builders to compile on different targets?
A: TensorRT assumes that all resources for the device it is building on are available for optimization purposes. Concurrent use of multiple TensorRT builders (for example, multiple trtexec instances) to compile on different targets (DLA0, DLA1 and GPU) can oversubscribe system resources causing undefined behavior (meaning, inefficient plans, builder failure, or system instability).
It is recommended to use trtexec with the --saveEngine argument to compile for different targets (DLA and GPU) separately and save their plan files. Such plan files can then be reused for loading (using trtexec with the --loadEngine argument) and submitting multiple inference jobs on the respective targets (DLA0, DLA1, GPU). This two-step process alleviates over-subscription of system resources during the build phase while also allowing execution of the plan file to proceed without interference by the builder.
Q: Which layers are accelerated by Tensor Cores?
A: Most math-bound operations will be accelerated with tensor cores - convolution, deconvolution, fully connected, and matrix multiply. In some cases, particularly for small channel counts or small group sizes, another implementation may be faster and be selected instead of a tensor core implementation.
Q: Why are reformatting layers observed although there is no warning message no implementation obeys reformatting-free rules ...?
A: Reformat-free network I/O does not mean that there are no reformatting layers inserted in the entire network. Only that the input and output network tensors have a possibility not to require reformatting layers. In other words, reformatting layers can be inserted by TensorRT for internal tensors to improve performance.
14.2. Understanding Error Messages
UFF Parser Error Messages
| Error Message | Description |
|---|---|
The input to the Scale Layer is required to have a minimum of 3 dimensions. |
This error message can occur due to incorrect input dimensions. In UFF, input dimensions should always be specified with the implicit batch dimension not included in the specification. |
Invalid scale mode, nbWeights: <X> |
|
kernel weights has count <X> but <Y> was expected |
|
<NODE> Axis node has op <OP>, expected Const. The axis must be specified as a Const node. |
As indicated by the error message, the axis must be a build time constant in order for UFF to parse the node correctly. |
ONNX Parser Error Messages
| Error Message | Description |
|---|---|
<X> must be an initializer! |
These error messages signify that an ONNX node
input tensor is expected to be an initializer in TensorRT. A
possible fix is to run constant folding on the model using
TensorRT’s Polygraphy
tool:polygraphy surgeon sanitize model.onnx --fold-constants --output model_folded.onnx |
!inputs.at(X).is_weights() |
|
getPluginCreator() could not find Plugin <operator name> version
1 |
This is an error stating that the ONNX parser does not have an import function defined for a particular operator, and did not find a corresponding plugin in the loaded registry for the operator. |
TensorRT Core Library Error Messages
| Error Message | Description | |
|---|---|---|
| Installation Errors | Cuda initialization failure with error <code>. Please check cuda installation: http://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html. |
This error message can occur if the CUDA or NVIDIA driver installation is corrupt. Refer to the URL for instructions on installing CUDA and the NVIDIA driver on your OS. |
| Builder Errors | Internal error: could not find any implementation for node <name>. Try increasing the workspace size with IBuilderConfig::setMemoryPoolLimit(). |
This error message occurs because there is no layer implementation for the given node in the network that can operate with the given workspace size. This usually occurs because the workspace size is insufficient but could also indicate a bug. If increasing the workspace size as suggested does not help, report a bug (refer to Reporting TensorRT Issues). |
<layer-name>: (kernel|bias) weights has non-zero count but null values <layer-name>: (kernel|bias) weights has zero count but non-null values |
This error message occurs when there is a mismatch between the values and count fields in a Weights data structure passed to the builder. If the count is 0, then the values field must contain a null pointer; otherwise, the count must be non-zero, and values must contain a non-null pointer. | |
Builder was created on device different from current device. |
This error message can show up if you:
|
|
| You can encounter error messages indicating that the tensor dimensions do not match the semantics of the given layer. Carefully read the documentation on NvInfer.h on the usage of each layer and the expected dimensions of the tensor inputs and outputs to the layer. | ||
| INT8 Calibration Errors | Tensor <X> is uniformly zero. |
This warning occurs and should be treated as an error when data distribution for a tensor is uniformly zero. In a network, the output tensor distribution can be uniformly zero under the following scenarios: |
Could not find scales for tensor <X>. |
This error message indicates that a calibration failure occurred with no scaling factors detected. This could be due to no INT8 calibrator or insufficient custom scales for network layers. | |
| Engine Compatibility Errors | The engine plan file is not compatible with this version of TensorRT, expecting (format|library) version <X> got <Y>, please rebuild. |
This error message can occur if you are running TensorRT using an engine PLAN file that is incompatible with the current version of TensorRT. Ensure you use the same version of TensorRT when generating the engine and running it. |
The engine plan file is generated on an incompatible device, expecting compute <X> got compute <Y>, please rebuild. |
This error message can occur if you build an engine on a device of a different compute capability than the device that is used to run the engine. | |
Using an engine plan file across different models of devices is not recommended and is likely to affect performance or even cause errors. |
This warning message can occur if you build an engine on a device with the same compute capability but is not identical to the device that is used to run the engine. As indicated by the warning, it is highly recommended to use a device of the same model when generating the engine and deploying it to avoid compatibility issues. |
|
| Out Of Memory Errors | GPU memory allocation failed during initialization of (tensor|layer): <name> GPU memory |
These error messages can occur if there is insufficient GPU memory available to instantiate a given TensorRT engine. Verify that the GPU has sufficient available memory to contain the required layer weights and activation tensors. |
Allocation failed during deserialization of weights. |
||
GPU does not meet the minimum memory requirements to run this engine … |
||
| FP16 Errors | Network needs native FP16 and platform does not have native FP16 |
This error message can occur if you attempt to deserialize an engine that uses FP16 arithmetic on a GPU that does not support FP16 arithmetic. You either must rebuild the engine without FP16 precision inference or upgrade your GPU to a model that supports FP16 precision inference. |
| Plugin Errors | Custom layer <name> returned non-zero initialization |
This error message can occur if the initialize() method of a given plugin layer returns a non-zero value. Refer to the implementation of that layer to debug this error further. For more information, refer to the NVIDIA TensorRT Operator's Reference. |
14.3. Code Analysis Tools
14.3.1. Compiler Sanitizers
14.3.1.1. Issues with dlopen and Address Sanitizer
14.3.1.2. Issues with dlopen and Thread Sanitizer
race::dlopen
export TSAN_OPTIONS=”suppressions=tsan.supp”
14.3.1.3. Issues with CUDA and Address Sanitizer
On CUDA 11.4, there is a known bug that can trigger mismatched allocation-and-free errors in the address sanitizer. Add alloc_dealloc_mismatch=0 to ASAN_OPTIONS to disable these errors.
14.3.1.4. Issues with Undefined Behavior Sanitizer
14.3.2. Valgrind
{
Memory leak errors with dlopen
Memcheck:Leak
match-leak-kinds: definite
...
fun:*dlopen*
...
}
On CUDA 11.4, there is a known bug that can trigger mismatched allocation-and-free errors in valgrind. Add the option --show-mismatched-frees=no to the valgrind command line to suppress these errors.
14.3.3. Compute Sanitizer
14.4. Understanding Formats Printed in Logs
Half(60,1:8,12,3)
((half*)base_address) + (60*n + 1*floor(c/8) + 12*h + 3*w) * 8 + (c mod 8)
Int8(105,15:4,3,1)
(int8_t*)base_address + (105*n + 15*floor(c/4) + 3*h + w) * 4 + (c mod 4)
Scalar formats have a vector size of 1. For brevity, printing omits the :1.
(type*)base_address + (vec_coordinate · strides) * vec_size + vec_modWhere:
- the dot denotes an inner product
- strides are the printed strides, that is, strides in units of vectors
- vec_size is the number of elements per vectors
- vec_coordinate is the original coordinate with the coordinate along the vectorized axis divided by vec_size
- vec_mod is the original coordinate along the vectorized axis modulo vec_size
14.5. Reporting TensorRT Issues
polygraphy surgeon sanitize model.onnx --fold-constants --output
model_folded.onnx
In addition, it is highly recommended that you first try our latest TensorRT release before filing an issue if you have not done so, since your issue may have been fixed in the latest release.
14.5.1. Channels for TensorRT Issue Reporting
- Register for the NVIDIA Developer website.
- Log in to the developer site.
- Click on your name in the upper right corner.
- Click My account > My Bugs and select Submit a New Bug.
- Fill out the bug reporting page. Be descriptive and if possible, provide the steps to reproduce the problem.
- Click Submit a bug.
- Environment information:
- OS or Linux distro and version
- GPU type
- NVIDIA driver version
- CUDA version
- cuDNN version
- Python version (if Python is used).
- TensorFlow, PyTorch, and ONNX version (if any of them is used).
- TensorRT version
- NGC TensorRT container version (if TensorRT container is used).
- Jetson (if used), include OS and hardware versions
- Thorough description of the issue.
- Steps to reproduce the issue:
- ONNX file (if ONNX is used).
- Minimal commands or scripts to trigger the issue
- Verbose logs by enabling kVERBOSE in ILogger
Depending on the type of the issue, providing more information listed below can expedite the response and debugging process.
14.5.2. Reporting a Functional Issue
Since the TensorRT engine is specific to a specific TensorRT version and a specific GPU type, do not build the engine in one environment and use it to run it in another environment with different GPUs or dependency software stack, such as TensorRT version, CUDA version, cuDNN version, and so on. Also, ensure that the application is linked to the correct TensorRT and cuDNN shared object files by checking the environment variable LD_LIBRARY_PATH (or %PATH% on Windows).
14.5.3. Reporting an Accuracy Issue
The Polygraphy tool can be used to debug the accuracy issue and produce a minimal failing case. Refer to the Debugging TensorRT Accuracy Issues documentation for the instructions. Having a Polygraphy command that shows the accuracy issue or having the minimal failing case expedites the time it takes for us to debug your accuracy issue.
Note that it is not practical to expect bitwise identical results between TensorRT and other frameworks like PyTorch, TensorFlow, or ONNX-Runtime even in FP32 precision since the order of the computations on the floating-point numbers can result in slight differences in output values. In practice, small numeric differences should not significantly affect the accuracy metric of the application, such as the mAP score for object-detection networks or the BLEU score for translation networks. If you do see a significant drop in the accuracy metric between using TensorRT and using other frameworks such as PyTorch, TensorFlow, or ONNX-Runtime, it may be a genuine TensorRT bug.
- Ensuring that network weights and inputs are restricted to a reasonably narrow
range (such as [-1, 1] instead of [-100, 100]). This may require making changes
to the network and retraining.
- Consider pre-processing input by scaling or clipping it to the restricted range before passing it to the network for inference.
- Overriding precision for individual layers vulnerable to overflows (for example, Reduce and Element-Wise Power ops) to FP32.
Polygraphy can help you diagnose common problems with using reduced precision. Refer to Polygraphy's Working with Reduced Precision how-to guide for more details.
Refer to the Improving Model Accuracy section for some possible solutions to accuracy issues, and the Working with INT8 section for instructions about using INT8 precision.
14.5.4. Reporting a Performance Issue
trtexec --onnx=<onnx_file> <precision_and_shape_flags> --verbose --profilingVerbosity=detailed --dumpLayerInfo --dumpProfile --separateProfileRun --useCudaGraph --noDataTransfers --useSpinWait --duration=60
trtexec --onnx=<onnx_file> <precision_and_shape_flags> --verbose --profilingVerbosity=detailed --dumpLayerInfo --saveEngine=<engine_path> nsys profile --cuda-graph-trace=node -o <output_profile> trtexec --loadEngine=<engine_path> <precision_and_shape_flags> --useCudaGraph --noDataTransfers --useSpinWait --warmUp=0 --duration=0 --iterations=20
Refer to the trtexec section for more instructions about how to use the trtexec tool and the meaning of these flags.
If you do not use trtexec to measure performance, provide the scripts and the commands that you use to measure the performance. If possible, compare the performance measurement from your script with that from the trtexec tool. If the two numbers differ, there may be some issues about the performance measurement methodology in your scripts.
Refer to the Hardware/Software Environment for Performance Measurements section for some environment factors that may affect the performance.
A. Appendix
A.1. Data Format Descriptions
Data Type Format
The data type is the representation of each individual value. Its size determines the range of values and the precision of the representation, which are FP32 (32-bit floating point, or single precision), FP16 (16-bit floating point or half precision), INT32 (32-bit integer representation), and INT8 (8-bit representation).
Layout Format
The layout format determines the ordering in which values are stored. Typically, batch dimensions are the leftmost dimensions, and the other dimensions refer to aspects of each data item, such as C is channel, H is height, and W is width, in images. Ignoring batch sizes, which are always preceding these, C, H, and W are typically sorted as CHW (refer to Figure 22) or HWC (refer to Figure 23).
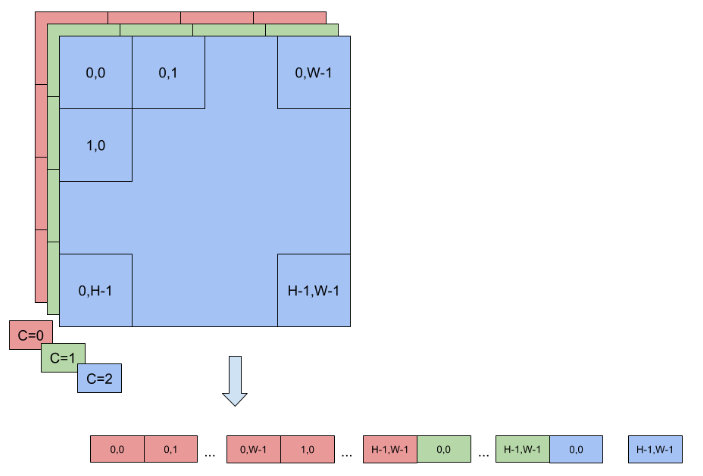
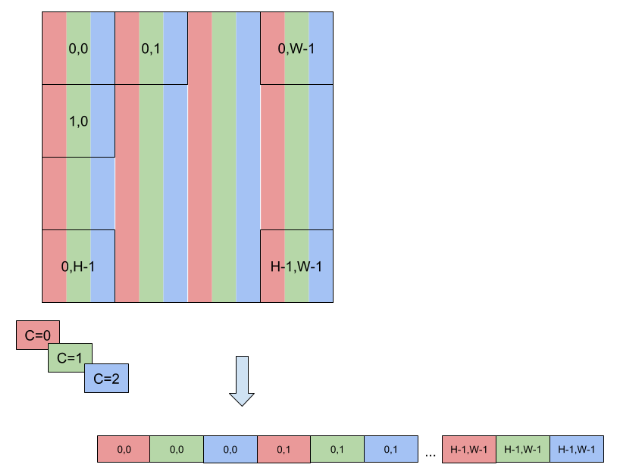
To enable faster computations, more formats are defined to pack together channel values and use reduced precision. For this reason, TensorRT also supports formats like NC, 2HW2 and NHWC8.
In NC, 2HW2 (TensorFormat::kCHW2), pairs of channel values are packed together in each HxW matrix (with an empty value in the case of an odd number of channels). The result is a format in which the values of ⌈C/2⌉ HxW matrices are pairs of values of two consecutive channels (refer to Figure 24); notice that this ordering interleaves dimension as values of channels that have stride 1 if they are in the same pair and stride 2xHxW otherwise.
![Values of [C/2] HxW Matrices are Pairs of Values of Two Consecutive Channels](graphics/fig3.PNG)
In NHWC8 (TensorFormat::kHWC8), the entries of an HxW matrix include the values of all the channels (refer to Figure 25). In addition, these values are packed together in ⌈C/8⌉ 8-tuples, and C is rounded up to the nearest multiple of 8.
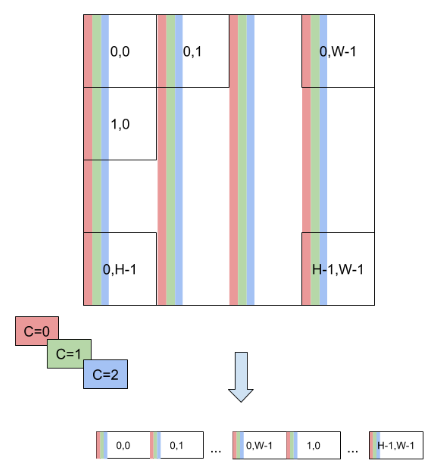
Other TensorFormat follow similar rules to TensorFormat::kCHW2 and TensorFormat::kHWC8 mentioned previously.
A.2. Command-Line Programs
A.2.1. trtexec
A.2.1.1. Benchmarking Network
enqueue batch 0 -> enqueue batch 1 -> wait until batch 0 is done -> enqueue batch 2 -> wait until batch 1 is done -> enqueue batch 3 -> wait until batch 2 is done -> enqueue batch 4 -> ...
If cross-inference multi-stream (--infStreams=N flag) is used, then trtexec follows this pattern on each stream separately.
- The observed throughput is computed by dividing the number of inferences by the Total Host Walltime. If this is significantly lower than the reciprocal of GPU Compute Time, the GPU may be underutilized because of host-side overheads or data transfers. Using CUDA graphs (with --useCudaGraph) or disabling H2D/D2H transfers (with --noDataTransfer) may improve GPU utilization. The output log provides guidance on which flag to use when trtexec detects that the GPU is underutilized.
- The summation of H2D Latency, GPU Compute Time, and D2H Latency. This is the latency to infer a single inference.
- The host latency to enqueue an inference, including calling H2D/D2H CUDA APIs, running host-side heuristics, and launching CUDA kernels. If this is longer than GPU Compute Time, the GPU may be underutilized and the throughput may be dominated by host-side overhead. Using CUDA graphs (with --useCudaGraph) may reduce enqueue time.
- The latency for host-to-device data transfers for input tensors of a single inference. Add --noDataTransfer to disable H2D/D2H data transfers.
- The latency for device-to-host data transfers for output tensors of a single inference. Add --noDataTransfer to disable H2D/D2H data transfers.
- The GPU latency to execute the CUDA kernels for an inference.
- The host walltime from when the first inference (after warm-ups) is enqueued to when the last inference was completed.
- The summation of the GPU Compute Time of all the inferences. If this is significantly shorter than Total Host Walltime, the GPU may be under utilized because of host-side overheads or data transfers.
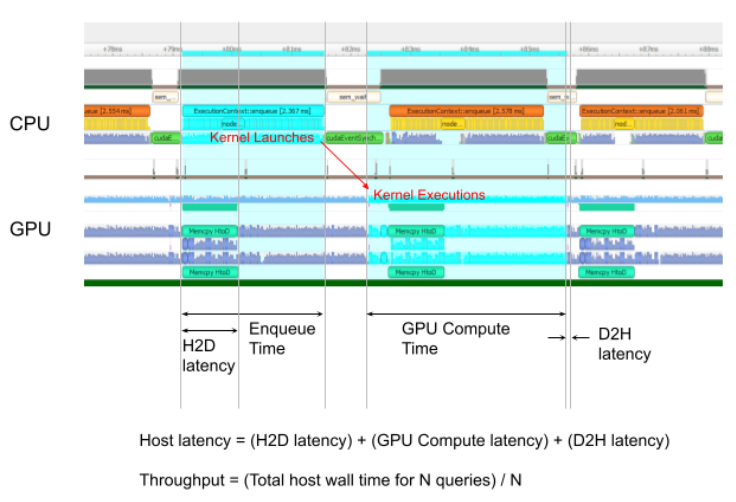
Add the --dumpProfile flag to trtexec to show per-layer performance profiles, which allows users to understand which layers in the network take the most time in GPU execution. The per-layer performance profiling works with launching inference as a CUDA graph as well. In addition, build the engine with the --profilingVerbosity=detailed flag and add the --dumpLayerInfo flag to show detailed engine information, including per-layer detail and binding information. This allows you to understand which operation each layer in the engine corresponds to and their parameters.
A.2.1.2. Serialized Engine Generation
A.2.1.3. Serialized Timing Cache Generation
A.2.1.4. Commonly Used Command-line Flags
Flags for the Inference Phase
Refer to trtexec --help for all the supported flags and detailed explanations.
Refer to the GitHub: trtexec/README.md file for detailed information about how to build this tool and examples of its usage.
A.3. Glossary
- A tensor shape with a dynamic dimension that is not calculated solely from network input dimensions and network input shape tensors.
- A specific GPU. Two GPUs are considered identical devices if they have the same model name and same configuration.
- A tensor shape that depends on the dimensions of an output of INonZeroLayer or INMSLayer.
- A tensor shape with a dynamic dimension that is calculated from data other than network input dimensions, network input shape tensors, and INonZeroLayer or INMSLayer. For example, a shape with a dimension calculated from data output by a convolution.
- A combination of architecture and OS. Example platforms are Linux on x86 and QNX Standard on Aarch64. Platforms with different architectures or different OS are considered different platforms.
A.4. ACKNOWLEDGEMENTS
Google Protobuf
- Atomicops support for generic gcc, located in src/google/protobuf/stubs/atomicops_internals_generic_gcc.h. This file is copyrighted by Red Hat Inc.
- Atomicops support for AIX/POWER, located in src/google/protobuf/stubs/atomicops_internals_power.h. This file is copyrighted by Bloomberg Finance LP.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
- Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
- Neither the name of Google Inc. nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
Code generated by the Protocol Buffer compiler is owned by the owner of the input file used when generating it. This code is not standalone and requires a support library to be linked with it. This support library is itself covered by the above license.
Google Flatbuffers
Apache License Version 2.0, January 2004 http://www.apache.org/licenses/
- Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
- Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
- Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
- Redistribution. You may reproduce and distribute copies of the Work or
Derivative Works thereof in any medium, with or without modifications, and
in Source or Object form, provided that You meet the following
conditions:
- You must give any other recipients of the Work or Derivative Works a copy of this License; and
- You must cause any modified files to carry prominent notices stating that You changed the files; and
- You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
- If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained within
such NOTICE file, excluding those notices that do not pertain to any
part of the Derivative Works, in at least one of the following
places: within a NOTICE text file distributed as part of the
Derivative Works; within the Source form or documentation, if
provided along with the Derivative Works; or, within a display
generated by the Derivative Works, if and wherever such third-party
notices normally appear. The contents of the NOTICE file are for
informational purposes only and do not modify the License. You may
add Your own attribution notices within Derivative Works that You
distribute, alongside or as an addendum to the NOTICE text from the
Work, provided that such additional attribution notices cannot be
construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
- Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
- Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
- Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
- Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
- Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright 2014 Google Inc.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at: http://www.apache.org/licenses/LICENSE-2.0.
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
BVLC caffe
COPYRIGHT
All contributions by the University of California:
Copyright (c) 2014, 2015, The Regents of the University of California (Regents)
All rights reserved.
All other contributions:
Copyright (c) 2014, 2015, the respective contributors
All rights reserved.
Caffe uses a shared copyright model: each contributor holds copyright over their contributions to Caffe. The project versioning records all such contribution and copyright details. If a contributor wants to further mark their specific copyright on a particular contribution, they should indicate their copyright solely in the commit message of the change when it is committed.
LICENSE
- Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
CONTRIBUTION AGREEMENT
By contributing to the BVLC/caffe repository through pull-request, comment, or otherwise, the contributor releases their content to the license and copyright terms herein.
half.h
Copyright (c) 2012-2017 Christian Rau <rauy@users.sourceforge.net>
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
jQuery.js
jQuery.js is generated automatically under doxygen.
In all cases TensorRT uses the functions under the MIT license.
CRC
TensorRT includes CRC routines from FreeBSD.
# $FreeBSD: head/COPYRIGHT 260125 2013-12-31 12:18:10Z gjb $
# @(#)COPYRIGHT 8.2 (Berkeley) 3/21/94
The compilation of software known as FreeBSD is distributed under the following terms:
Copyright (c) 1992-2014 The FreeBSD Project. All rights reserved.
- Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE AUTHOR AND CONTRIBUTORS ``AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE AUTHOR OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
The 4.4BSD and 4.4BSD-Lite software is distributed under the following terms:
All of the documentation and software included in the 4.4BSD and 4.4BSD-Lite Releases is copyrighted by The Regents of the University of California.
Copyright 1979, 1980, 1983, 1986, 1988, 1989, 1991, 1992, 1993, 1994 The Regents of the University of California. All rights reserved.
- Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
- All advertising materials mentioning features or use of this software must display the following acknowledgement: This product includes software developed by the University of California, Berkeley and its contributors.
- Neither the name of the University nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS ``AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE REGENTS OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
The Institute of Electrical and Electronics Engineers and the American National Standards Committee X3, on Information Processing Systems have given us permission to reprint portions of their documentation.
In the following statement, the phrase ``this text'' refers to portions of the system documentation.
Portions of this text are reprinted and reproduced in electronic form in the second BSD Networking Software Release, from IEEE Std 1003.1-1988, IEEE Standard Portable Operating System Interface for Computer Environments (POSIX), copyright C 1988 by the Institute of Electrical and Electronics Engineers, Inc. In the event of any discrepancy between these versions and the original IEEE Standard, the original IEEE Standard is the referee document.
In the following statement, the phrase ``This material'' refers to portions of the system documentation.
This material is reproduced with permission from American National Standards Committee X3, on Information Processing Systems. Computer and Business Equipment Manufacturers Association (CBEMA), 311 First St., NW, Suite 500, Washington, DC 20001-2178. The developmental work of Programming Language C was completed by the X3J11 Technical Committee.
July 22, 1999
To All Licensees, Distributors of Any Version of BSD:
As you know, certain of the Berkeley Software Distribution ("BSD") source code files require that further distributions of products containing all or portions of the software, acknowledge within their advertising materials that such products contain software developed by UC Berkeley and its contributors.
Specifically, the provision reads:
" * 3. All advertising materials mentioning features or use of this software
* must display the following acknowledgement:
* This product includes software developed by the University of
* California, Berkeley and its contributors."
Effective immediately, licensees and distributors are no longer required to include the acknowledgement within advertising materials. Accordingly, the foregoing paragraph of those BSD Unix files containing it is hereby deleted in its entirety.
William Hoskins
Director, Office of Technology Licensing
University of California, Berkeley
getopt.c
$OpenBSD: getopt_long.c,v 1.23 2007/10/31 12:34:57 chl Exp $
$NetBSD: getopt_long.c,v 1.15 2002/01/31 22:43:40 tv Exp $
Copyright (c) 2002 Todd C. Miller <Todd.Miller@courtesan.com>
Permission to use, copy, modify, and distribute this software for any purpose with or without fee is hereby granted, provided that the above copyright notice and this permission notice appear in all copies.
THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
Sponsored in part by the Defense Advanced Research Projects Agency (DARPA) and Air Force Research Laboratory, Air Force Materiel Command, USAF, under agreement number F39502-99-1-0512.
Copyright (c) 2000 The NetBSD Foundation, Inc.
All rights reserved.
This code is derived from software contributed to The NetBSD Foundation by Dieter Baron and Thomas Klausner.
- Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE NETBSD FOUNDATION, INC. AND CONTRIBUTORS ``AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE FOUNDATION OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
ONNX Model Zoo
MIT License
Copyright (c) ONNX Project Contributors
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE
RESNET-50 Caffe models
The MIT License (MIT)
Copyright (c) 2016 Shaoqing Ren
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
OpenSSL
Apache License Version 2.0
Copyright (c) OpenSSL Project Contributors
Apache License
Version 2.0, January 2004
https://www.apache.org/licenses/
- Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
- Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
- Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
- Redistribution. You may reproduce and distribute copies of the Work or
Derivative Works thereof in any medium, with or without modifications, and
in Source or Object form, provided that You meet the following
conditions:
- You must give any other recipients of the Work or Derivative Works a copy of this License; and
- You must cause any modified files to carry prominent notices stating that You changed the files; and
- You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
- If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained within
such NOTICE file, excluding those notices that do not pertain to any
part of the Derivative Works, in at least one of the following
places: within a NOTICE text file distributed as part of the
Derivative Works; within the Source form or documentation, if
provided along with the Derivative Works; or, within a display
generated by the Derivative Works, if and wherever such third-party
notices normally appear. The contents of the NOTICE file are for
informational purposes only and do not modify the License. You may
add Your own attribution notices within Derivative Works that You
distribute, alongside or as an addendum to the NOTICE text from the
Work, provided that such additional attribution notices cannot be
construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
- Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
- Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
- Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
- Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
- Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
Boost Beast
Copyright (c) 2016-2017 Vinnie Falco (vinnie dot falco at gmail dot com)
Boost Software License - Version 1.0 - August 17th, 2003
Permission is hereby granted, free of charge, to any person or organization obtaining a copy of the software and accompanying documentation covered by this license (the "Software") to use, reproduce, display, distribute, execute, and transmit the Software, and to prepare derivative works of the Software, and to permit third-parties to whom the Software is furnished to do so, all subject to the following:
The copyright notices in the Software and this entire statement, including the above license grant, this restriction and the following disclaimer, must be included in all copies of the Software, in whole or in part, and all derivative works of the Software, unless such copies or derivative works are solely in the form of machine-executable object code generated by a source language processor.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE AND NON-INFRINGEMENT. IN NO EVENT SHALL THE COPYRIGHT HOLDERS OR ANYONE DISTRIBUTING THE SOFTWARE BE LIABLE FOR ANY DAMAGES OR OTHER LIABILITY, WHETHER IN CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Notice
Notice
This document is provided for information purposes only and shall not be regarded as a warranty of a certain functionality, condition, or quality of a product. NVIDIA Corporation (“NVIDIA”) makes no representations or warranties, expressed or implied, as to the accuracy or completeness of the information contained in this document and assumes no responsibility for any errors contained herein. NVIDIA shall have no liability for the consequences or use of such information or for any infringement of patents or other rights of third parties that may result from its use. This document is not a commitment to develop, release, or deliver any Material (defined below), code, or functionality.
NVIDIA reserves the right to make corrections, modifications, enhancements, improvements, and any other changes to this document, at any time without notice.
Customer should obtain the latest relevant information before placing orders and should verify that such information is current and complete.
NVIDIA products are sold subject to the NVIDIA standard terms and conditions of sale supplied at the time of order acknowledgement, unless otherwise agreed in an individual sales agreement signed by authorized representatives of NVIDIA and customer (“Terms of Sale”). NVIDIA hereby expressly objects to applying any customer general terms and conditions with regards to the purchase of the NVIDIA product referenced in this document. No contractual obligations are formed either directly or indirectly by this document.
NVIDIA products are not designed, authorized, or warranted to be suitable for use in medical, military, aircraft, space, or life support equipment, nor in applications where failure or malfunction of the NVIDIA product can reasonably be expected to result in personal injury, death, or property or environmental damage. NVIDIA accepts no liability for inclusion and/or use of NVIDIA products in such equipment or applications and therefore such inclusion and/or use is at customer’s own risk.
NVIDIA makes no representation or warranty that products based on this document will be suitable for any specified use. Testing of all parameters of each product is not necessarily performed by NVIDIA. It is customer’s sole responsibility to evaluate and determine the applicability of any information contained in this document, ensure the product is suitable and fit for the application planned by customer, and perform the necessary testing for the application in order to avoid a default of the application or the product. Weaknesses in customer’s product designs may affect the quality and reliability of the NVIDIA product and may result in additional or different conditions and/or requirements beyond those contained in this document. NVIDIA accepts no liability related to any default, damage, costs, or problem which may be based on or attributable to: (i) the use of the NVIDIA product in any manner that is contrary to this document or (ii) customer product designs.
No license, either expressed or implied, is granted under any NVIDIA patent right, copyright, or other NVIDIA intellectual property right under this document. Information published by NVIDIA regarding third-party products or services does not constitute a license from NVIDIA to use such products or services or a warranty or endorsement thereof. Use of such information may require a license from a third party under the patents or other intellectual property rights of the third party, or a license from NVIDIA under the patents or other intellectual property rights of NVIDIA.
Reproduction of information in this document is permissible only if approved in advance by NVIDIA in writing, reproduced without alteration and in full compliance with all applicable export laws and regulations, and accompanied by all associated conditions, limitations, and notices.
THIS DOCUMENT AND ALL NVIDIA DESIGN SPECIFICATIONS, REFERENCE BOARDS, FILES, DRAWINGS, DIAGNOSTICS, LISTS, AND OTHER DOCUMENTS (TOGETHER AND SEPARATELY, “MATERIALS”) ARE BEING PROVIDED “AS IS.” NVIDIA MAKES NO WARRANTIES, EXPRESSED, IMPLIED, STATUTORY, OR OTHERWISE WITH RESPECT TO THE MATERIALS, AND EXPRESSLY DISCLAIMS ALL IMPLIED WARRANTIES OF NONINFRINGEMENT, MERCHANTABILITY, AND FITNESS FOR A PARTICULAR PURPOSE. TO THE EXTENT NOT PROHIBITED BY LAW, IN NO EVENT WILL NVIDIA BE LIABLE FOR ANY DAMAGES, INCLUDING WITHOUT LIMITATION ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, PUNITIVE, OR CONSEQUENTIAL DAMAGES, HOWEVER CAUSED AND REGARDLESS OF THE THEORY OF LIABILITY, ARISING OUT OF ANY USE OF THIS DOCUMENT, EVEN IF NVIDIA HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. Notwithstanding any damages that customer might incur for any reason whatsoever, NVIDIA’s aggregate and cumulative liability towards customer for the products described herein shall be limited in accordance with the Terms of Sale for the product.
Arm
Arm, AMBA and Arm Powered are registered trademarks of Arm Limited. Cortex, MPCore and Mali are trademarks of Arm Limited. "Arm" is used to represent Arm Holdings plc; its operating company Arm Limited; and the regional subsidiaries Arm Inc.; Arm KK; Arm Korea Limited.; Arm Taiwan Limited; Arm France SAS; Arm Consulting (Shanghai) Co. Ltd.; Arm Germany GmbH; Arm Embedded Technologies Pvt. Ltd.; Arm Norway, AS and Arm Sweden AB.
HDMI
HDMI, the HDMI logo, and High-Definition Multimedia Interface are trademarks or registered trademarks of HDMI Licensing LLC.
Blackberry/QNX
Copyright © 2020 BlackBerry Limited. All rights reserved.
Trademarks, including but not limited to BLACKBERRY, EMBLEM Design, QNX, AVIAGE, MOMENTICS, NEUTRINO and QNX CAR are the trademarks or registered trademarks of BlackBerry Limited, used under license, and the exclusive rights to such trademarks are expressly reserved.
Trademarks
NVIDIA, the NVIDIA logo, and CUDA, DALI, DGX-1, DRIVE, JetPack, Orin, Pegasus, TensorRT, Triton and Xavier are trademarks and/or registered trademarks of NVIDIA Corporation in the United States and other countries. Other company and product names may be trademarks of the respective companies with which they are associated.