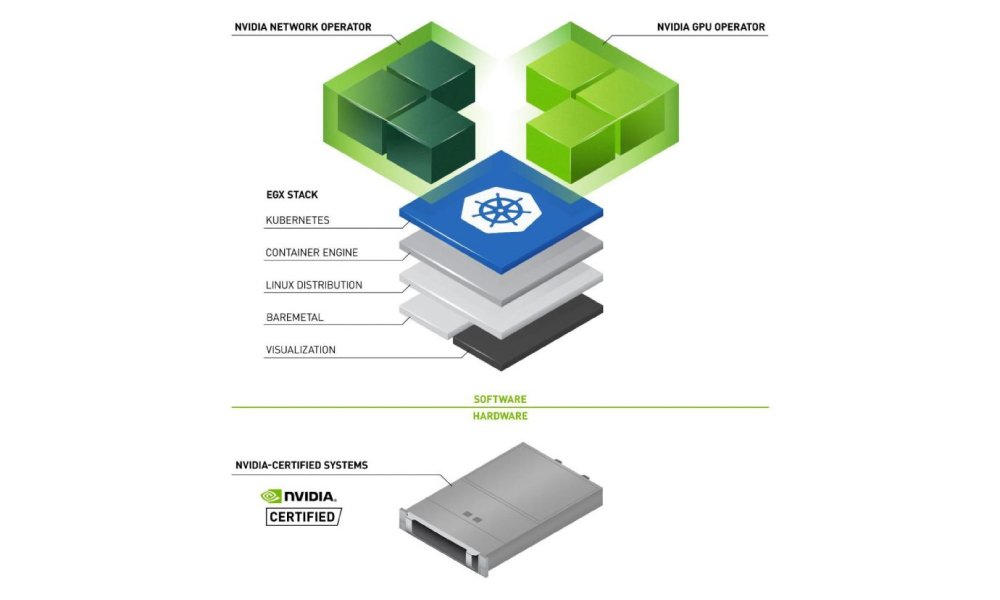
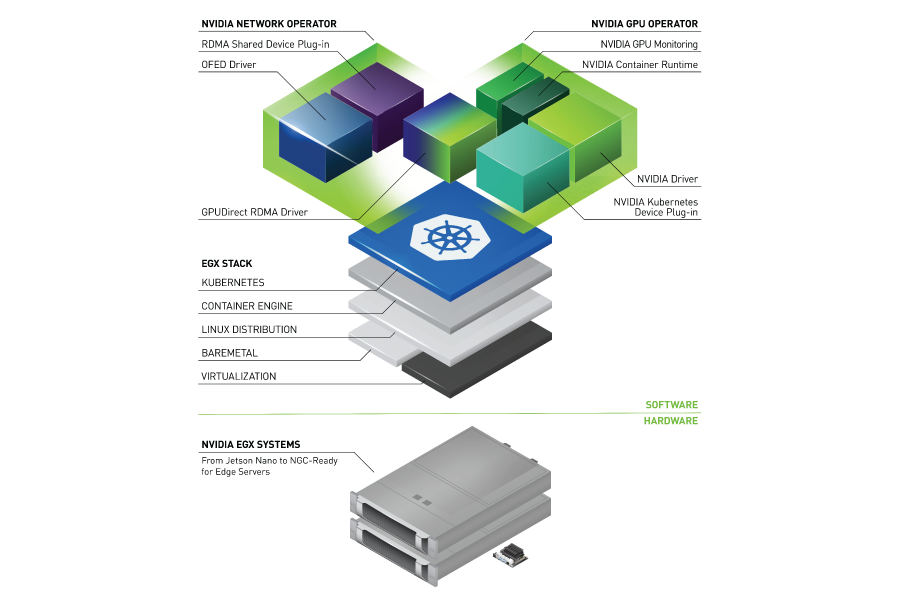
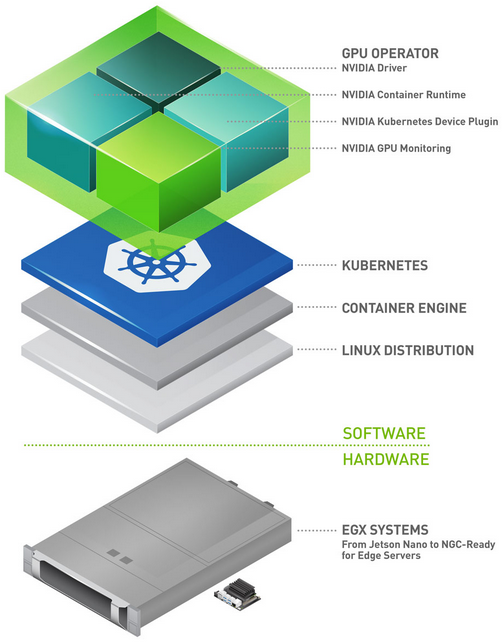
Every AI cluster running on Kubernetes requires a full software stack that works together, from low-level driver and kernel settings to high-level operator and workload configurations. You get one cluster working, and spend days getting the next one to match. Upgrade a component, and something else breaks. Move to a new cloud and start over. AI Cluster Runtime is a new open-source project designed to remove cluster configuration from the critical path. It publishes optimized, validated, and reproducible Kubernetes configurations as recipes you can deploy onto your clusters.
How AI Cluster Runtime works
To support GPU clusters across cloud and on-premises AI factories, NVIDIA validates specific combinations of drivers, runtimes, operators, kernel modules, and system settings for AI workloads. AI Cluster Runtime publishes those results as recipes. These version-locked YAML files capture which components were tested, the versions, and the configuration values, for a given environment. Recipes also carry constraints (minimum Kubernetes version, required OS, kernel version) and a computed deployment order based on component dependencies. Every recipe is validated against real clusters and reproducible across environments.
You can browse recipes directly in the repository, query them through a REST API, or use the aicr CLI to generate one for your target environment and render it into Helm charts and manifests ready for deployment.
Capture your cluster state
If you have a running cluster, you can snapshot its state before generating a recipe. This captures OS release, kernel version, GPU hardware and driver, Kubernetes version, and installed operators.
aicr snapshot \
--node-selector nodeGroup=gpu-worker \
--output cm://gpu-operator/aicr-snapshot
This deploys a short-lived Job onto a target node, collects system measurements, and writes the results to a ConfigMap or local file. The snapshot becomes the baseline that the validation checks against.
Generate a recipe
The recipe command takes a description of your target environment and matches it against a library of validated overlays to produce a single recipe with exact component versions and settings.
aicr recipe \
--service eks \
--accelerator h100 \
--intent training \
--os ubuntu \
--platform kubeflow \
--output recipe.yaml
Recipes are composed from layers rather than maintained as monolithic configurations. These include:
- Base layers, which define universal components and default versions.
- Environment layers, which add Kubernetes-specific components—for example, the EBS CSI driver and EFA plugin on Amazon EKS.
- Intent layers, which configure training-optimized component settings and NVIDIA Collective Communications Library (NCCL) tuning parameters.
- Hardware layers, which pin driver versions and enable features such as CDI and GDRCopy for specific accelerators.
Each layer is added in order, with more specific values taking precedence over general ones.
A fully specialized recipe (such as NVIDIA Blackwell + EKS + Ubuntu + training + Kubeflow) carries up to 268 configuration values across 16 components. A generic EKS query returns 200. The delta between training and inference intent can swap 5 components and change 41 configuration values, producing completely different deployment stacks from the same base. This kind of variance is exactly why people end up hand-tuning clusters.
Validate
Validation runs in phases. Prior to deploying anything, a readiness check compares recipe constraints against your snapshot: Kubernetes version, OS, kernel, and GPU hardware.
aicr validate \
--recipe recipe.yaml \
--phase readiness
After deployment, subsequent phases validate component health and conformance. The conformance phase checks against standards like the CNCF’s Certified Kubernetes AI Conformance Program, verifying requirements for dynamic resource allocation (DRA), gang scheduling, and job-level networking.
Create a bundle
The bundler turns a recipe into deployable artifacts.
aicr bundle \
--recipe recipe.yaml \
--system-node-selector nodeGroup=system-pool \
--accelerated-node-selector nodeGroup=gpu-worker \
--accelerated-node-toleration nvidia.com/gpu=present:NoSchedule \
--output ./bundles
The output is a directory with one folder per component, each containing values.yaml, integrity checksums, a README, and optional custom manifests.
Components are ordered by their dependency graph (for example, cert-manager before NVIDIA GPU Operator, and the NVIDIA GPU Operator before Kubeflow Trainer). Deploy using the included deploy.sh script, generate ArgoCD Application manifests with --deployer argocd, or publish bundles as OCI images for air-gapped environments.
Stay current with AI Cluster Runtime recipes
Recipes update as the NVIDIA internal validation pipelines run. New component releases, driver updates, and kernel parameter changes all flow into published recipes as they are tested. When a particular NCCL setting improves Blackwell throughput, that lands in the next recipe version.
Because every recipe is versioned, you can diff your current deployment against the latest validated configuration and see exactly what changed before upgrading.
Contributing recipes
Designed for collaboration from the start, the project enables CSPs, OEMs, platform teams, and individual operators to help validate diverse hardware, OS, and Kubernetes distribution combinations.
Contribute a recipe. Copy an existing overlay, update the criteria and configuration for your environment, run make test, and open a PR. The recipe development guide walks through the process.
Extend privately. The --data flag overlays external recipe directories at runtime, so you can maintain organization-specific configurations alongside public ones without forking.
File issues. Share which environments matter to you. That directly shapes what gets validated next.
Get started with AI Cluster Runtime
AI Cluster Runtime is available on GitHub as an alpha release. It includes the aicr CLI, an API server, a cluster agent, and validated recipes covering training and inference workloads on Kubernetes (e.g., Amazon EKS) with NVIDIA H100 and NVIDIA Blackwell accelerators running Ubuntu 24.04.
Training recipes target Kubeflow Trainer and inference recipes target NVIDIA Dynamo. Every release includes SLSA Level 3 provenance, signed SBOMs, and image attestations.
Projects are in development to expand AI Cluster Runtime across additional platforms, accelerators, and workload types. Tune in to the Operating Cloud AI Factories at Scale session at NVIDIA GTC 2026 to learn more about AI Cluster Runtime and other products that can scale AI operations.