
The NVIDIA Video Codec SDK consists of GPU hardware-accelerated APIs for the following tasks:
- Video encoding, with the NVENCODE API
- Video decoding, with NVDECODE API (formerly known as nvcuvid)
While writing an application using the NVDECODE or NVENCODE APIs, it is crucial to use video memory in an efficient way. If an application uses multiple decoders or encoder instances in parallel, it’s even more crucial because the application can get bottlenecked by video memory availability. This post serves as a guide to reduce video memory footprint while using NVDECODE API for decoding. This post assumes basic familiarity with the NVDECODE API.

Typical decoding pipeline
A typical NVIDIA GPU-accelerated decoder pipeline consists of three major components:
- Demultiplexing (or demuxing, in short)
- Parsing
- Decoding
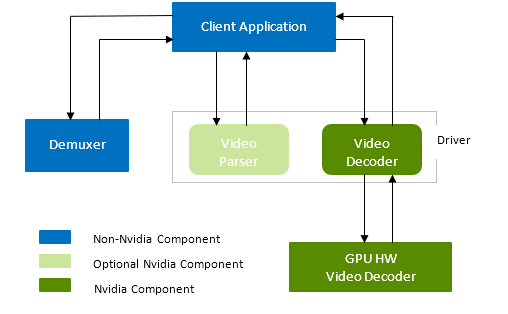
These components are not dependent on each other and hence can be used independently. The demultiplexer is outside the scope of the NVDECODE API, but you can easily integrate the FFmpeg demultiplexer. The sample applications included in the Video Codec SDK demonstrate this. NVDECODE API provides API actions for parsing and decoding. The parser is a pure SW component and doesn’t use GPU acceleration. The decoding stage uses GPU acceleration (on-chip NVDEC hardware). All NVDECODE API actions are exposed in two header-files: cuviddec.h and nvcuvid.h.
Before creating the decoder, I recommend that you query the capabilities of the GPU to ensure that the required functionality is supported. The decoding stage consists of five main steps, excluding retrieving the status of the frame:
- Create a decoder:
cuvidCreateDecoder - Decode a frame:
cuvidDecodePicture - Map frame:
cuvidMapVideoFrame - Unmap frame:
cuvidUnmapVideoFrame - Destroy decoder:
cuvidDestroyDecoder
Tips for optimizing memory
Most video memory allocation happens at the first step—decoder creation, which is done using the cuvidCreateDecoder action. Decoder configuration is set in the CUVIDDECODECREATEINFO structure passed in this action. Setting optimal values in decoder configuration structure is necessary for optimal usage of video memory without impacting the decoder performance. Here are a few configuration parameters that can affect video memory usage, along with hints about how to set them optimally.
ulNumDecodeSurfaces
The NVIDIA video driver creates a ulNumDecodeSurfaces number of surfaces for storing the decoded outputs, also called decode surfaces. The minimum value for ulNumDecodeSurfaces depends upon the video sequence structure. The NVDECODE API sequence callback from the parser provides this minimum value needed for ulNumDecodeSurfaces for correct decoding, using CUVIDEOFORMAT::min_num_decode_surfaces. This implies that the app must wait for the first sequence callback from the parser before creating the decoder object to set the optimal value of ulNumDecodeSurfaces.
For better pipelining between decoder and the remaining downstream functions (for example, display and inference), I recommend setting ulNumDecodeSurfaces to (CUVIDEOFORMAT::min_num_decode_surfaces + 3) or (CUVIDEOFORMAT::min_num_decode_surfaces + 4). The app can update the ulNumDecodeSurfaces value if it changes in the next video sequence, using the cuvidReconfigureDecoder action.
ulNumOutputSurfaces
The application gets the final output in one of the ulNumOutputSurfaces surfaces, also called the output surface. The driver performs an internal copy—and postprocessing if deinterlacing/scaling/cropping is enabled—from decoded surface to output surface. The optimal value of ulNumOutputSurfaces depends upon the number of output buffers needed at a time. A single buffer also suffices if the applications reads—using cuvidMapVideoFrame—one output buffer at a time, that is, releasing the current frame using cuvidUnmapVideoFrame before reading the next frame. The optimal value for ulNumOutputSurfaces, therefore, depends upon how the downstream functions that follow the decoding stage are processing the data.
DeinterlaceMode
DeinterlaceMode should be set to cudaVideoDeinterlaceMode_Weave or cudaVideoDeinterlaceMode_Bob for progressive content and cudaVideoDeinterlaceMode_Adaptive for interlaced content. Choosing cudaVideoDeinterlaceMode_Adaptive results in higher deinterlacing quality but increases memory consumption.
ulIntraDecodeOnly
If the video content is known to contain all intra frames, this flag can be set to notify the driver to avoid internal buffer creation needed for inter frames. This helps the driver to optimize video memory. Using this mode with P and B frames can result in unpredictable behavior.
One potential application of this mode is to speed up video-processing neural network training. In use cases such as intelligent video analytics, it is sufficient to train the neural network using every nth frame from the video. In such cases, it may be beneficial to extract every nth frame and encode the resulting sequence as a separate intra-frame-only (H.264/HEVC) video using NVENC. This intra-only video can be then used for training the neural network, while decoding the streams with ulIntraDecodeOnly = 1. This method results in a significant speed-up of NN training, and with a smaller memory footprint compared to the case when the entire video is being decoded. The support is limited to specific codecs: H264, HEVC, or VP9. The flag is ignored for codecs that are not supported.
ulMaxWidth and ulMaxHeight
All driver buffers are allocated based on ulMaxWidth and ulMaxHeight. It is the dimension of the largest frame in the video content being decoded. You can reconfigure the decoder without destroying and re-creating it, even if the coded frame size changes but the new coded width is less than or equal to ulMaxWidth and the new coded height is less than or equal to ulMaxHeight. If the content has no resolution change, you can set these same as ulWidth or set it to 0 during decoder creation. If set to [MISSING], the driver sets ulMaxWidth and ulMaxHeight to ulWidth, respectively.
The CUDA context also consumes significant video memory. I recommend sharing the CUDA context among multiple decoder objects in case of multi-instance decoding.
Encoding parameters for a low decoder-memory footprint
In some use cases, it may be possible to control the parameters used while encoding the video, so that the decoding becomes memory efficient. For example, in use cases involving neural network training, it may be possible to re-encode the training video dataset with parameters for efficient video memory usage during repeated training iterations. Another example is cameras in a surveillance system that have configurable encoding parameters. The following encoding tips may help in reducing the decoder memory footprint in this case.
- Number of reference frames: The number of reference frames that can be used by each encoded frame directly impacts the memory usage at the decoder as the decoder must allocate the DPB (decode picture buffer). Therefore, a lower number of reference frames helps to reduce decoder memory footprint. However, a reduced number of reference frames generally results in lower quality. To maintain the same quality level, increase the bitrate appropriately. The exact numbers depend on the individual encoder.
- Lower resolution: In some cases, it’s possible to scale the raw, captured video before encoding, or to re-scale the video before encoding. For example, the training dataset used in DNN training can be decoded, scaled, and re-encoded one time for faster training performance. A lower-resolution video naturally requires less memory to decode, allowing for better decoding efficiency in such cases.
Analyzing video memory impact
The following table demonstrates how memory usage changes with the different decoder configuration parameters set during decoder object creation with the cuvidCreateDecoder action.
// These configuration parameters are kept fixed while doing the experiment
CUVIDDECODECREATEINFO videoDecodeCreateInfo = { 0 };
videoDecodeCreateInfo.CodecType = cudaVideoCodec_H264;
videoDecodeCreateInfo.ChromaFormat = cudaVideoChromaFormat_420;
videoDecodeCreateInfo.OutputFormat = cudaVideoSurfaceFormat_NV12;
videoDecodeCreateInfo.bitDepthMinus8 = 0;
videoDecodeCreateInfo.ulCreationFlags = cudaVideoCreate_PreferCUVID;
videoDecodeCreateInfo.ulWidth = 1920;
videoDecodeCreateInfo.ulHeight = 1080;
videoDecodeCreateInfo.ulTargetWidth = videoDecodeCreateInfo.ulWidth;
videoDecodeCreateInfo.ulTargetHeight = videoDecodeCreateInfo.ulHeight;
In Table 1, decoder configuration parameters are changed one at a time in each column and the last row shows memory consumed using the cuvidCreateDecoder action. The following formula is used to measure memory consumption of this action:
Memory consumed = total video memory consumed after this action – total video memory consumed before this action
| ulNumDecodeSurfaces | 10 | 10 | 10 | 20 | 20 | 20 |
| ulNumOutputSurfaces | 2 | 2 | 2 | 2 | 10 | 10 |
| DeinterlaceMode (cudaVideoDeinterlaceMode_*) | Weave | Adaptive | Adaptive | Adaptive | Adaptive | Adaptive |
| ulIntraDecodeOnly | 0 | 0 | 1 | 1 | 1 | 1 |
| ulMaxWidth | 1920 | 1920 | 1920 | 1920 | 1920 | 4096 |
| ulMaxHeight | 1080 | 1080 | 1080 | 1080 | 1080 | 4096 |
| Memory used (Windows) | 41.1MB | 68.7MB | 66.2MB | 96.3MB | 121.8MB | 542.1MB |
| Memory used (Linux) | 53.2MB | 87.2MB | 83.2MB | 123.2MB | 155.2MB | 555.2MB |
Windows:
- GPU: NVIDIA GeForce RTX 2070
- OS: Windows 10 Enterprise build 18362
- Driver: 445.75
- Tool used for memory measurement: Windows Task Manager
Linux:
- GPU: NVIDIA Quadro RTX 5000
- OS: Ubuntu 18.04
- Driver: 440.82
- Tool used for memory measurement: nvidia-smi
Video memory consumption on Linux operating system is a bit higher than Windows because of internal architecture differences like page size. Video memory consumption may vary across various GPU architectures, operating systems, and graphics drivers because of various reasons. The differences could be because of different page sizes across OS flavors and versions, decoding hardware architecture differences across GPUs or various SW feature sets and optimizations.
As an example, the CUDA action cuCtxCreate took 84 MB of video memory on the GeForce windows setup and 115 MB on the Quadro Linux setup. Memory consumed by CUDA context may also vary across various GPU architectures, operating systems, and graphics drivers. As CUDA context consumes significant memory, I recommend sharing it across multiple decoders when using multi-instance decoding.
The nvidia-smi tool, installed along with the NVIDIA graphics driver, can be used to retrieve GPU operating parameters. These parameters are also available using APIs exposed in the NVIDIA Management Library (NVML). Most recent versions of Windows 10 have an updated task manager to check video memory usage and hardware video engine usage.
The following sample CLI output from nvidia-smi shows the GPU memory usage as well as hardware decoder (NVDEC) usage when the decoding is running on the system.
(base) test@tu104linux:~/decode_tests$ nvidia-smi Mon Jul 27 14:05:57 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 450.51 Driver Version: 450.51 CUDA Version: 11.0 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Quadro RTX 5000 Off | 00000000:03:00.0 Off | Off | | 33% 33C P2 65W / 230W | 463MiB / 12028MiB | 51% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 4024 G /usr/lib/xorg/Xorg 63MiB | | 0 N/A N/A 58771 C ./appdec 395MiB | +-----------------------------------------------------------------------------+ (base) test@tu104linux:~/regression_test_suite/decode_tests$ nvidia-smi pmon # gpu pid type sm mem enc dec command # Idx # C/G % % % % name 0 59039 C 0 0 - - appdec 0 59039 C 13 1 - 9 appdec 0 59039 C 44 5 - 30 appdec 0 59039 C 49 6 - 33 appdec 0 59039 C 49 6 - 33 appdec 0 59039 C 49 6 - 33 appdec 0 59039 C 49 6 - 33 appdec 0 59039 C 49 6 - 33 appdec 0 59039 C 49 6 - 33 appdec 0 59039 C 49 6 - 33 appdec 0 59039 C 49 6 - 33 appdec 0 59039 C 49 6 - 33 appdec
Conclusion
To use the video memory efficiently, particularly when running multiple instances of NVDEC decoding, it is important to ensure that the decoder is configured for most optimum memory utilization. This post demonstrates which decoder configuration parameters impacts the video memory usage and how to configure them optimally.
If the encoding process is under user control, encoding parameters can be adjusted to improve the NVDEC decoding efficiency.
To download the SDK, see the NVIDIA Video Codec SDK product page. For more information, see the NVIDIA Video Codec SDK v11.1 documentation.
