NVIDIA AI Enterprise is an end-to-end, secure, cloud-native suite of AI software. The recent release of NVIDIA AI Enterprise 3.0 introduces new features to help optimize the performance and efficiency of production AI. This post provides details about the new features listed below and how they work.
- Magnum IO GPUDirect Storage
- GPU virtualization with VMware vSphere 8.0
- Red Hat Enterprise Linux (RHEL) KVM 8 and 9
- Fractional multi-vGPU support
- Extended support for NVIDIA AI
Production AI features
New AI workflows in the 3.0 release of NVIDIA AI Enterprise help reduce the development time of production AI. These workflows are reference applications for common AI use cases, including contact center intelligent virtual assistants, audio transcription, and digital fingerprinting.
Unencrypted pretrained models are also included for the first time, ensuring AI explainability and enabling developers to view the weights and biases of a model and understand model bias.
NVIDIA AI Enterprise now supports all NVIDIA AI software published in the NGC catalog. Developers beginning their NGC journey can now seamlessly transition to NVIDIA AI Enterprise subscription and leverage NVIDIA Enterprise Support for over 50 AI frameworks, pretrained models, and SDKs.
Infrastructure performance features
NVIDIA AI Enterprise 3.0 includes many new features that help optimize infrastructure performance, so you can get the most out of your AI investments and maximize cost and time savings. These features are explained in more detail below.
Magnum IO GPUDirect Storage
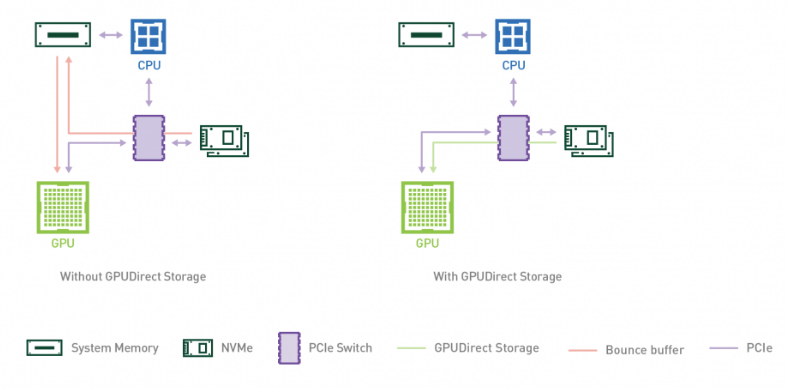
Enterprises can now leverage the performance benefits of Magnum IO GPUDirect Storage with their NVIDIA AI Enterprise 3.0 deployments to accelerate and scale up their AI workloads. GPUDirect Storage 1.4 provides a direct datapath between local or remote storage and GPU memory, delivering unrivaled performance for complex workloads.
GPUDirect Storage streamlines the flow of data between storage and GPU buffers for applications that consume or produce data on the GPU without needing CPU processing. It uses remote direct memory access (RDMA) to move data quickly on a direct path from storage to GPU memory, reducing latency and unburdening the CPU by eliminating extra copying through a bounce buffer.
GPUDirect Storage provides notable performance improvements, with a 7.2x increase in performance in deep learning inference with NVIDIA DALI compared to baseline NumPy. Fore more details, see NVIDIA Magnum IO.
The NASA Mars Lander Demo used NVIDIA IndeX and GPUDirect Storage with more than 27,000 NVIDIA GPUs to simulate retro propulsion, with a 5x bandwidth gain when leveraging PCIe switches and NVLinks with GPUDirect Storage.
To learn more, see the guide for running NVIDIA AI Enterprise with GPUDirect Storage.
GPU virtualization features with VMware vSphere 8.0
NVIDIA AI Enterprise 3.0 introduces support for VMware vSphere 8, which includes several features that accelerate performance and enhance operational efficiency. VMware environments can now add up to eight virtual GPUs to one VM, doubling the number of vGPUs from prior releases. This improves performance of large ML models and provides higher scalability for complex AI and ML workloads.
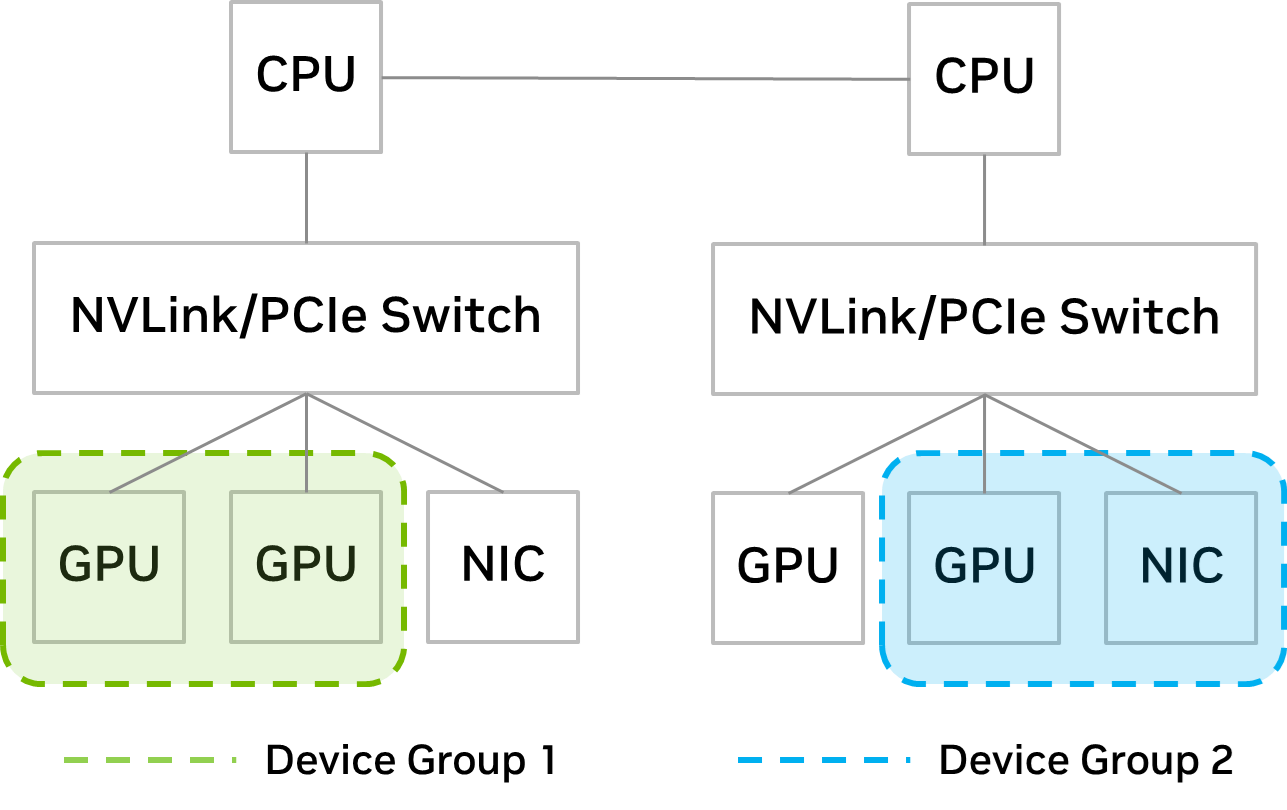
IT admins can now retain more control over VM placement with the introduction of device groups. The Distributed Resource Scheduler (DRS) is a management tool included with vSphere that determines optimal VM placement.
The new device groups feature provides insight on PCIe devices that are paired with each other on the hardware level (through NVLink or PCIe switch) from which the IT admin can choose a subset to present to the VM for DRS placement decisions.
With device groups, IT admins can ensure that the subset of devices is allocated together to the VM. For example, if the user wants to scale up GPUs to accelerate large models, the IT admin can create a device group containing GPUs with NVLinks between them. This is shown in Figure 2 as seen in Device Group 1.
If a user wants to scale out across multiple servers for distributed training, the device group can consist of GPUs and NICs sharing the same PCIe switch. This is shown in Figure 2 as Device Group 2.
Red Hat Enterprise Linux KVM
NVIDIA AI Enterprise 3.0 expands virtualization support to include Red Hat Enterprise Linux 8.4, 8.6, 8.7, 9.0, and 9.1, enabling businesses to extend KVM capabilities to their AI workloads. With RHEL KVM, admins can add up to 16 virtual GPUs to one VM, providing exponentially faster processing for compute-intensive workloads. For more information on deploying NVIDIA AI Enterprise with RHEL KVM, visit the NVIDIA AI Enterprise Documentation Center.
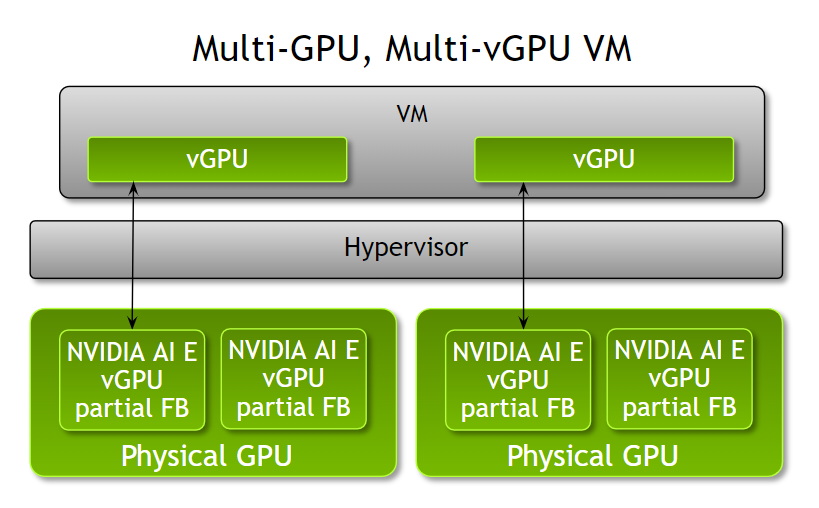
Fractional multi-vGPU support
Admins can now provision multiple fractional vGPUs to a single VM with NVIDIA AI Enterprise 3.0, offering increased flexibility to optimize VM configurations based on workloads. Prior to this release, a VM could only be accelerated by a single fraction of a GPU, a full GPU, or multiple GPUs per VM.
Admins now have increased flexibility and can assign multiple partial vGPU profiles to a VM based on the workload compute needs. For example, when running multiple inference workloads with different compute needs, admins can assign partial profiles of NVIDIA A100 Tensor Core GPUs with different amounts of frame buffer to a VM based on the workload memory requirements.
Note that all partial profiles must be of the same board type and series. These partial vGPU profiles can be assigned from one or multiple physical GPUs. This feature is available on both VMware vSphere 8 and RHEL KVM 8 and 9.
Extended support for NVIDIA AI
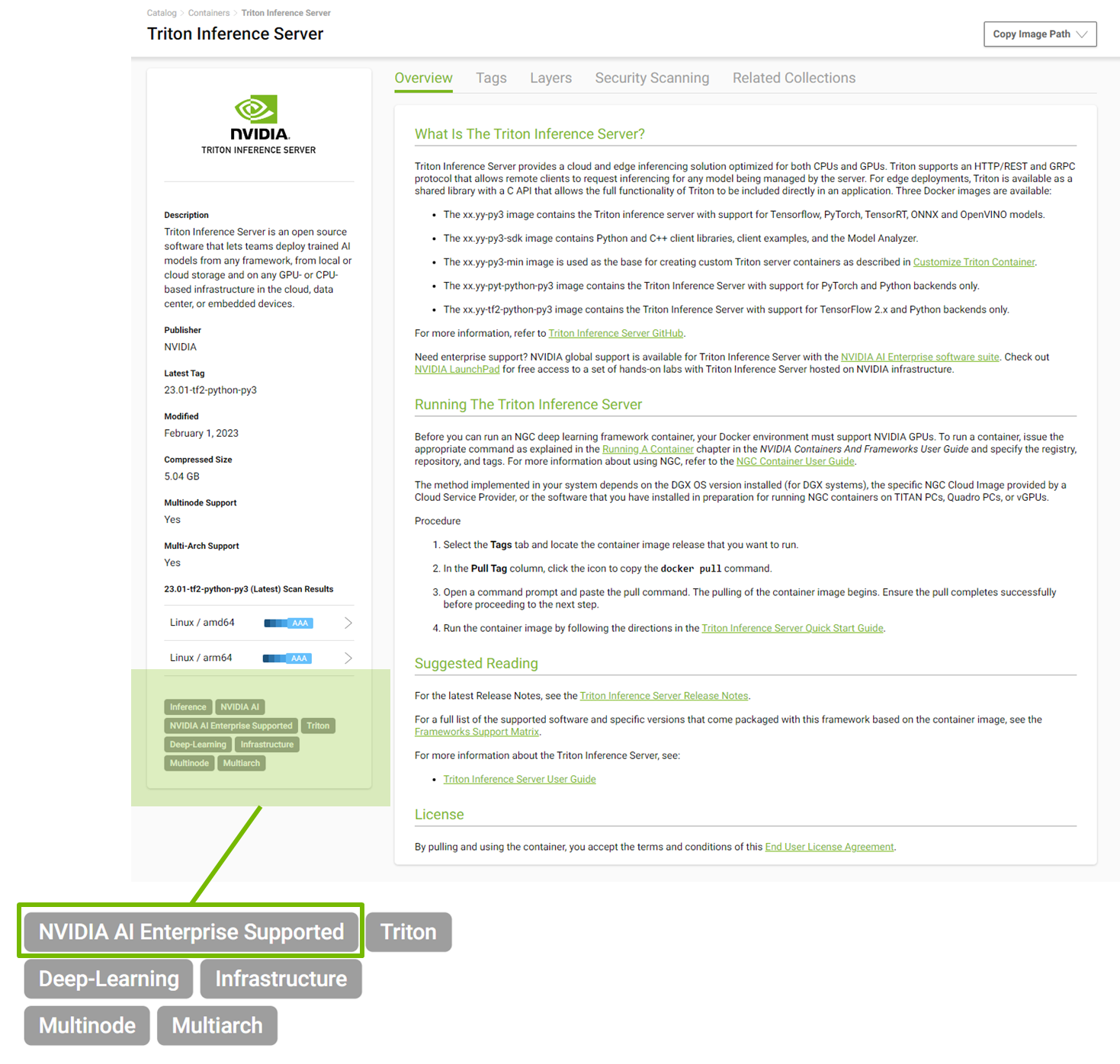
NVIDIA AI Enterprise provides support for all NVIDIA AI software published in the NGC catalog, which now contains over 50 frameworks and models. All supported models are labeled ‘NVIDIA AI Enterprise Supported’ to help users easily identify the supported software.
Conclusion
With the latest 3.0 release of NVIDIA AI Enterprise, organizations can reduce the development time of production AI with the latest performance and efficiency optimizations. Get Started with NVIDIA AI Enterprise on NVIDIA LaunchPad. LaunchPad provides immediate, short-term access to the NVIDIA AI Enterprise software suite in a private accelerated computing environment that includes hands-on labs.
Register for NVIDIA GTC 2023 for free and join us March 20–23 to discover how NVIDIA AI Enterprise and other technologies are used to solve tough AI challenges.
