As part of my GDC 2019 session, Optimizing DX12/DXR GPU Workloads using Nsight Graphics: GPU Trace and the Peak-Performance-Percentage (P3) Method, I presented an optimization technique named thread-group tiling, a type of thread-group ID swizzling.
This is an important technique for optimizing 2D, full-screen, compute shader passes that are doing widely spread texture fetches and which are VRAM-limited with a poor L2 hit rate. It is particularly important when doing convolution passes that use wide kernels (such as typical denoisers), or when using NVIDIA DXR1.1 RayQuery instructions in a regular 2D compute shader.
Problem
For launching a 2D compute-shader pass in DirectX, NVIDIA Vulkan, or NVIDIA CUDA, a developer is supposed to settle on some thread-group size (typically 8×8, 16×8, or 16×16) and calculate the number of thread groups to launch in X and Y to fill the whole screen. Then, in the compute shader, a thread is typically mapped to a 2D pixel coordinate based on the SV_DispatchThreadID system variable (that is, SV_GroupID * numthreads + SV_GroupThreadID).
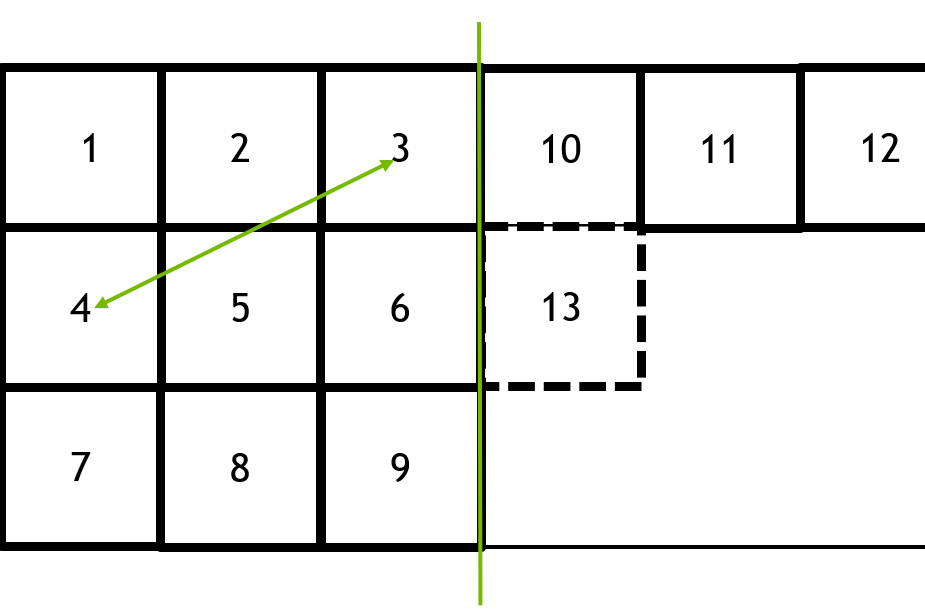
Here’s an example where a screen is filled with NxN thread groups. When you are using SV_DispatchThreadID as pixel coordinates, the order in which the groups of pixels are launched is a row-major order:
Look at the thread groups 10 and 11 on Figure 1. They are launched back-to-back and are likely to execute concurrently on the GPU. If they perform texture samples in a wide kernel, the texture data cached in L2 for thread group 10 is likely not reusable by thread group 11.
A similar issue also happens between thread groups on the same line, such as #1 and #10, which may be executing concurrently on the GPU and not having any overlap in the L2 footprints of their texture samples.
Thread-group tiling
The general idea is to remap the input thread-group IDs of compute-shaders to simulate what would happen if the thread groups were launched in a more L2-friendly order. There are multiple ways to swizzle the thread-group IDs to increase their memory locality.
A well-known way is using a Morton order. However, we’ve found that using a simpler approach works better in practice: tiling the thread groups horizontally or vertically. The thread-group tiling algorithm has two parameters:
- The primary direction (X or Y)
- The maximum number of thread groups that can be launched along the primary direction within a tile.
The 2D dispatch grid is divided into tiles of dimension [N, Dispatch_Grid_Dim.y] for Direction=X and [Dispatch_Grid_Dim.x, N] for Direction=Y.
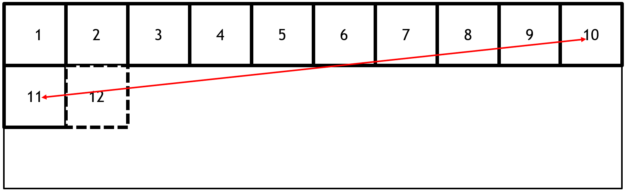
Figure 2 shows what the effective thread-group launch order is with Direction=X and N=3 for the same thread groups as in Figure 1.
The distance between two consecutively launched thread groups from different rows is shown in red on Figure 1 and in green on Figure 2. Clearly, tiling the thread groups is bounding the maximum distance between consecutively launched thread groups, and reducing the footprint of their memory accesses in the L2 cache, which is accessed by all of the thread groups simultaneously executing on the GPU.
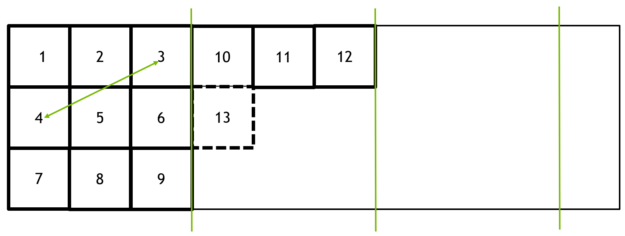
Figure 3 shows an animated view of the thread-group launch order with and without thread-group tiling, with Direction=X and N=16:

Result
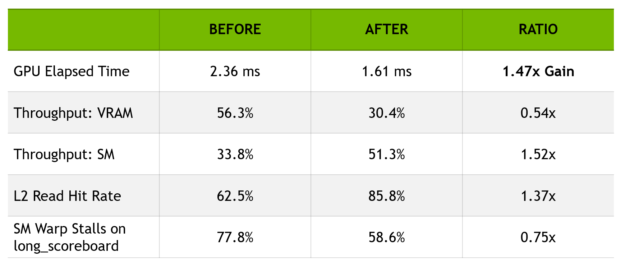
In my GDC 2019 talk, I showed that horizontal thread-group-ID tiling with N=16 produced a 47% gain on a full-screen, denoising, compute shader pass in Battlefield V DXR at 1440p on a RTX 2080 with SetStablePowerState(TRUE).
As expected, the L2 read hit rate has greatly increased (from 63% to 86%) and the workload moved from being VRAM-latency limited (with the top-throughput unit being the VRAM at 56% of its max throughput) to being SM limited.
Conclusion
If you encounter a full-screen, compute-shader pass in which the following attributes are true, then the thread-group ID swizzling technique presented here can produce a significant speedup:
- The VRAM is the top-throughput unit.
- The L2 load hit rate is much lower than 80%.
- There is significant overlap between the texture footprints of adjacent thread groups.
Acknowledgements
I want to thank my colleagues Aditya Ukarande, Suryakant Patidar, and Ram Rangan, who came up with this optimization technique. I’d also like to thank Jiho Choi, who created the animated GIF used in this post and in my GDC 2019 talk.
HLSL snippet
In my GDC talk, I provided a HLSL snippet for doing thread-group tiling horizontally. However, this snippet contained a bug: it worked only if Dispatch_Grid_Dim.x was a multiple of the number of thread groups to be launched in the X direction (N). Sorry about that!
Thankfully, my colleague Aditya Ukarande provided a corrected HLSL snippet for horizontal thread-group tiling.
